Python爬虫(二)——urllib库,Post与Get数据传送区别,设置Headers,urlopen方法,简单爬虫
一、urllib2概念
urllib2是一个Python模块,可以用来获取URL资源(fetching URLs),它定义了函数和类,用以协助URL操作(actions),如基本身份验证和摘要式身份验证(basic and digest authentication)、重定向、cookies等
二、urllib2和urllib区别
两个模块都是完成URL的请求,但还是有所区别
1、urllin2可以接受一个Request对象,用来设置URL request的头部信息(headers),urllib仅可以接受URL,这意味你不可以通过urllib模块伪装你的User-Agent等字符串(伪装浏览器)
2、urllib提供urlencode方法(urlencode只能对字典编码)用来GET查询字符串的产生,而vrllib2没有,所以很多时候urllib和urllib2一起用
3、urllib2很重要的一个好处就是urllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部
三、最简单的爬虫
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://www.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
print RES
运行结果(因为学校网站反爬机制不会去怎么做,所以比较好爬):
当然如果你想把网页趴下来,存到本地,可以通过文件方法如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://www.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES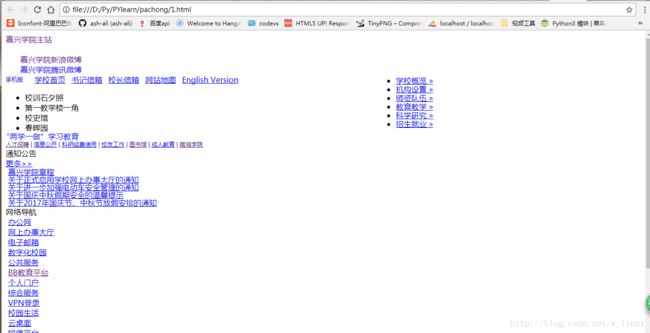
Request方法是对URL的请求
.read()方法返回获取到的网页内容(即读取获取到的网页内容)
urlopen方法执行之后是返回一个RES对象,返回的网页信息便保存在RES中
理解urlopen
urlopen一般接受三个参数,urlopen(url,data,timeout)
1.url即URL
2.data是访问URL是要传送的数据
3.timeout是设置超时时间
2和3参数可以部传送,data默认为空None。timeout默认为socket_GLOBAL_DEFAULT_TIMEOUT
四、Post与GET数据传送区别
最重要的区别就是:
GET方式是直接以链接形式访问,链接中包含了所有的参数(例如百度中搜索百度二字,会在链接中把一些搜索参数显示出来:https://www.baidu.com/s?ie=UTF-8&wd=%E7%99%BE%E5%BA%A6)这里ie指编码格式,wd代表搜索的关键字。所以很明显,安全性不如Post方法高,但Post的话如果你想查看提交了什么,就不太方便了……
下面有两个demo来做个对比(虽然是不成功,但看看区别就好)
Post方式
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
import urllib
#post类型
value={"username":"11111","password":"11111"}
data=urllib.urlencode(value)
url="https://passport.hupu.com/login"
request=urllib2.Request(url,data)
RES=urllib2.urlopen(request)
print RES.read()
定义字典类型value,保存username和password,通过urlencode对字典编码返回给data,将数据和url通过Request方法来申请访问,然后再显示出来,当然这里一般的话会显示出登入后的页面,不过这里失败了,应该是有流水等
GET方式
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
import urllib
#get类型
value={"uesrname":"111111","password":"11111"}
data=urllib.urlencode(value)
url="https://passport.hupu.com/login"
geturl=url+"?"+data #https://passport.hupu.com/login?password=11111&uesrname=111111
request=urllib2.Request(geturl)
RES=urllib2.urlopen(request)
print geturl
print RES.read()
可以看到通过将url+”?”+data拼接起来赋值给geturl,输出geturl值为:
https://passport.hupu.com/login?password=11111&uesrname=111111
五、设置Headers
目的是为了完全模拟浏览器工作,因为有些网站不会同意这么简单的程序就能直接访问,所以要设置一下Headers属性
下面步骤是找到Headers
打开检查页面元素

下拉就能找到User-Agent这些
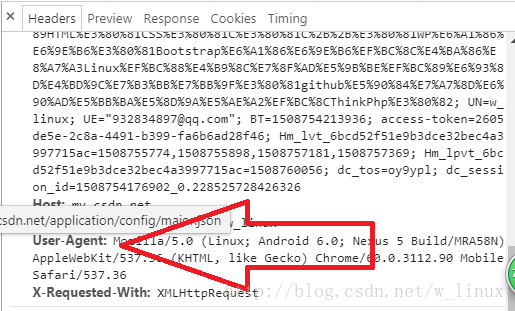
下面是demo
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/23
import urllib2
url=r'http://my.csdn.net/w_linux'
headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Mobile Safari/537.36"}
request=urllib2.Request(url,headers=headers)#Request参数有三个,url,data,headers,如果没有data参数,那就得按我这样的写法
RES=urllib2.urlopen(request).read()
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES将爬取的页面保存到自本地的html中,效果如下

常常用来头部包装的数据
User-Agent :这个头部可以携带如下几条信息:浏览器名和版本号、操作系统名和版本号、默认语言
Referer:可以用来防止盗链,有一些网站图片显示来源http://*.com,就是检查Referer来鉴定的
Connection:表示连接状态,记录Session的状态。
- Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
- application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
- application/json : 在 JSON RPC 调用时使用
- application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
六、timeout参数设置
该参数是urlopen方法的第三个参数,可以设置等待多久超时,为了解决某些网站反应慢造成影响,
注意:
假如第二个参数data为空那么需要特别指明timeout为多少,写明参数,如果data已经传入那就不必声明了
import urllib2
RES=urllib2.urlopen(r'http://my.csdn.net/w_linux',timeout=8)
或
import urllib2
RES=urllib2.urlopen(r'http://my.csdn.net/w_linux',data,8)