仅供参考,还未运行程序,理解部分有误,请参考英文原版。
绿色部分非文章内容,是个人理解。
转载请注明:http://blog.csdn.net/raby_gyl/article/details/17471617
Chapter 4:Exploring Structure from Motion Using OpenCV
在这一章,我们将讨论来至运动结构(Structure from Motion,SfM)的概念,或者从一个运动的相机拍摄到的图像中更好的推测提取出来的几何结构,使用OpenCV的API函数可以帮助我们完成这个任务。首先,让我们将我们使用的冗长的方法约束为使用单个摄像机,通常称为单目方法,并且是一组分离的和稀疏的视频帧而不是连续的视频流。这两个约束在很大程度上简化了系统,这个系统我们将在接下来的页码中进行描述,并且帮助我们理解任何SfM方法的原理。为了实现我们的方法,我们将跟随Hartley和Zisserman的脚步(后面称作H和Z),伴随着他们有创意的书——《计算机视觉中的多视觉几何》的第9章到第12章的记录。
在这一章,我们将涉及到以下内容:
1、来至运动结构的概念
2、从一对图像中估计摄像机的运动
3、重构场景
4、从多个视图中重构
5、重构提纯(Refinement of the reconstruction)
6、可视化3D点云
本章自始自终假定使用一个标定过的相机——预先标定的相机。在计算机视觉中标定是一个普遍存在的操作,在OpenCV中得到了很好的支持,我们可以使用在前一章讨论的命令行工具来完成标定。因此,我们假定摄像机内参数存在,并且具体化到K矩阵中,K矩阵为摄像机标定过程的一个结果输出。
为了在语言方面表达的清晰,从现在开始我们将单个摄像机称为场景的单个视图而不是光学和获取图像的硬件。一个摄像机在空间中有一个位置,一个观察的方向。在两个摄像机中,有一个平移成分(空间运动)和一个观察方向的旋转。我们同样对场景中的点统一一下术语,世界(world),现实(real),或者3D,意思是一样的,即我们真实世界存在的一个点。这同样适用于图像中的点或者2D,这些点在图像坐标系中,是在这个位置和时间上一些现实的3D点投影到摄像机传感器上形成的。
在这一章的代码部分,你将注意参考《计算视觉中的多视觉几何》(Multiple View Geometry in Computer Vision),例如,//HZ9.12,这指的是这本书的第9章第12个等式。同样的,文本仅包括代码的摘录,而完整的代码包含在伴随着这本书的材料中。
来至运动结构的概念——Structure from Motion concepts
第一个我们应当区别的是立体(Stereo or indeed any multiview),使用标准平台的三维重建和SfM之间的差异。在两个或多个摄像机的平台中,假定我们已经知道了两个摄像机之间的运动,而在SfM中,我们实际上不知道这个运动并且我们希望找到它。标准平台,来至观察的一个过分简单的点,可以得到一个更加精确的3D几何的重构,因为在估计多个摄像机间距离和旋转时没有误差(距离和旋转已知)。实现一个SfM系统的第一步是找到相机之间的运动。OpenCV可以帮助我们在许多方式上获得这个运动,特别地,使用findFundamentalMat函数。
让我们想一下选择一个SfM算法背后的目的。在很多情况下,我们希望获得场景的几何。例如,目标相对于相机的位置和他们的形状是什么。假定我们知道了捕获同一场景的摄像机之间的运动,从观察的一个合理的相似点,现在我们想重构这个几何。在计算视觉术语中称为三角测量(triangulation),并且有很多方法可以做这件事。它可以通过 射线相交的方法完成,这里我们构造两个射线:来至于每个摄像机投影中心的点和每一个图像平面上的点。理想上,这两个射线在空间中将相交于真实世界的一个3D点(这个3D点在每个摄像机中成像),如下面图表展示:
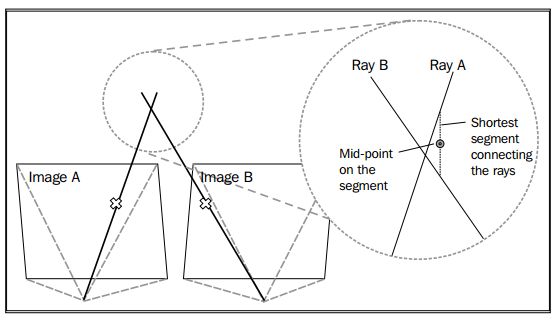
实际上,射线相交非常不可靠。H和Z推荐不使用它。这是因为两个射线通常不能相交,让我们回到使用连接两个射线的最短线段上的中间点。相反,H和Z建议一些方法来三角化3D点(trianglulate 3D points,三角化3D点就是计算3D点的坐标,可以通过后面的内容加以理解),这些方法中我们将在重构场景部分讨论两个。OpenCV现在的版本没有包含三角测量(triangulation)的API,因此,这部分我们将自己编写代码。
学习完如何从两个视图恢复3D几何之后,我们将看到我们是怎么样加入更多的同一个场景的视图来获得更丰富的重构。在那时,大部分的SfM方法试图依靠束调整(Bundle Adjustment)来优化我们的摄像机和3D点一束估计位置(the bundle of estimated positon),这部分内容在重构提纯部分(Refinement of the reconstruction section)。OpenCV在新的图像拼接的工具箱内包含了用来束调整的方法。然而,使OpenCV和C++完美结合的工作是丰富的外部工具,这些工具可以很容易地整合到一起。因此,我们将看到如何如何整合一个外部的束调节器——灵巧的SSBA库。
既然我们已经描述了使用OpenCV实现我们的SfM方法的一个概括,我们将看到每个分成是如何实现的。
从一对图像中估计摄像机的运动——Estimating the camera motion from a pair of images
事实上,在我们开始着手两个摄像机之间的运动之前,让我们检查一下我们手边用来执行这个操作的输入和工具。首先,我们有来至(希望并不是非常)不同空间位置的同一场景的两个图像。这是一个强大的资产,并且我们将确保使用它。现在工具都有了,我们应当看一下数学对象,来对我们的图像,相机和场景施加约束。
两个非常有用的数学对象是基础矩阵(用F表示)和本征矩阵(用E表示)。除了本征矩阵是假设使用的标定的相机,它们非常相似。这种情况针对我们,所以我们将选着它。OpenCV函数仅允许我们通过findFundamentalMat函数找到基础矩阵。然而,我们非常简单地使用标定矩阵(calibration matrix)K从本征矩阵中获得基础矩阵,如下:
Mat_ E = K.t() * F * K; //according to HZ (9.12) 本征矩阵,是一个3×3大小的矩阵,使用x’Ex=0在图像中的一点和另外一个图像中的一点之间施加了一个约束,这里x是图像一中的的一点,x’是图像二中与之相对应的一点。这非常有用,因为我们将要看到。我们使用的另一个重要的事实是本征矩阵是我们用来为我们的图像恢复两个相机的所有需要,尽管只有尺度,但是我们以后会得到。因此,如果我们获得了本征矩阵,我们知道每一个相机在空间中的位置,并且知道它们的观察方向,如果我们有足够这样的约束等式,那么我们可以简单地计算出这个矩阵。简单的因为每一个等式可以用来解决矩阵的一小部分。事实上,OpenCV允许我们仅使用7个点对来计算它,但是我们希望获得更多的点对来得到一个鲁棒性的解。
使用丰富的特征描述子进行点匹配——Point matching using rich feature descriptors
现在我们将使用我们的约束等式来计算本征矩阵。为了获得我们的约束,记住对于图像A中的每一个点我们必须在图像B中找到一个与之相对应的点。我们怎样完成这个匹配呢?简单地通过使用OpenCV的广泛的特征匹配框架,这个框架在过去的几年了已经非常成熟。
在计算机视觉中,特征提取和描述子匹配是一个基础的过程,并且用在许多方法中来执行各种各样的操作。例如,检测图像中一个目标的位置和方向,或者通过给出一个查询图像在大数据图像中找到相似的图像。从本质上讲,提取意味着在图像中选择点,使得获得好的特征,并且为它们计算一个描述子。一个描述子是含有多个数据的向量,用来描述在一个图像中围绕着特征点的周围环境。不同的方法有不同的长度和数据类型来表示描述子矢量。匹配是使用它的描述子从另外一个图像中找到一组与之对应的特征。OpenCV提供了非常简单和有效的方法支持特征提取和匹配。关于特征匹配的更多信息可以在Chapter 3少量(无)标记增强现实中找到。
让我们检查一个非常简单特征提取和匹配方案:
// detectingkeypoints
SurfFeatureDetectordetector();
vector keypoints1, keypoints2;
detector.detect(img1, keypoints1);
detector.detect(img2, keypoints2);
// computing descriptors
SurfDescriptorExtractor extractor;
Mat descriptors1, descriptors2;
extractor.compute(img1, keypoints1, descriptors1);
extractor.compute(img2, keypoints2, descriptors2);
// matching descriptors
BruteForceMatcher> matcher;
vector matches;
matcher.match(descriptors1, descriptors2, matches); 你可能已经看到类似的OpenCV代码,但是让我们快速的回顾一下它。我们的目的是获得三个元素:两个图像的特征点,特征点的描述子,和两个特征集的匹配。OpenCV提供了一组特征检测器、描述子提取器和匹配器。在这个简单例子中,我们使用SurfFeatureDetector函数来获得SURF(Speeded-Up-Robust Features)特征的2D位置,并且使用SurfDescriptorExtractor函数来获得SURF描述子。我们使用一个brute-force匹配器来获得匹配,这是一个最直接方式来匹配两个特征集,该方法是通过比较第一个集中的每一个特征和第一个集的每一个特征并且获得最好的匹配来实现的。
在下一个图像中,我们将看到两个图像上的特征点的匹配:(这两个图像来至于the Fountain-P11 sequence,可以在网址中找到:http://cvlab.epfl.ch/~strecha/multiview/denseMVS.html.)

实际上,像我们执行的原始匹配(raw matching),只有到达某一程度时执行效果才比较好并且许多匹配可能是错误的。因此,大多数SfM方法对原始匹配进行一些滤波方式来确保正确和减少错误。一种滤波方式叫做交叉检验滤波,它内置于OpenCV的brute-force匹配器中。也就是说,如果第一个图像的一个特征匹配第二个图像的一个特征,并且通过反向检查,第二个图像的特征也和第一个图像的特征匹配,那么这个匹配被认为是正确的。另一个常见的滤波机制(该机制用在提供的代码中)是基于同一场景的两个图像并且在他们之间存在某一种立体视觉关系,这样的一个事实基础之上来滤波的。在实践中,这个滤波器尝试采用鲁棒性的算法来计算这个基础矩阵,我们将会在寻找相机矩阵(Finding camera matrices)部分学习这种计算方法,并且保留由该计算得到的带有小误差的特征对。
使用光流进行点匹配——Point matching using optical flow
一个替代使用丰富特征(如SURF)匹配的方法,是使用optical flow(OF光流)进行匹配。下面的信息框提供了光流的一个简短的概述。最近的OpenCV为从两个图像获得流场扩展了API,并且现在更快,更强大。我们将尝试使用它作为匹配特征的一个替代品。
【注释:
光流是匹配来至一幅图像选择的点到另外一幅图像选着点的过程,假定这两个图像是一个视频序列的一部分并且它们彼此非常相近。大多数的光流方法比较一个小的区域,称为搜索窗口或者块,这些块围绕着图像A中的每一点和同样区域的图像B中的每一点。遵循计算机视觉中一个非常普通的规则,称为亮度恒定约束(brightness constancy constraint)(和其他名字),图像中的这些小块从一个图像到另外一个图像不会有太大的变化,因此,他们的幅值差接近于0。除了匹配块,更新的光流方法使用一些额外的方法来获得更好的结果。其中一个方法就是使用图像金字塔,它是图像越来越小的尺寸(大小)版本,这考虑到了工作的从粗糙到精致——计算机视觉中一个非常有用的技巧。另外一个方法是定义一个流场上的全局约束,假定这些点相互靠近,向同一方向一起运动。在OpenCV中,一个更加深入的光流方法可以在Chapter Developing Fluid Wall Using the Microsoft Kinect中找到,这个书可以在出版社网站上访问到。】
在OpenCV中,使用光流相当的简单,可以通过调用calcOpticalFlowPyrLK函数来实现。我们想要保存光流的结果匹配,像使用丰富的特征那样,在未来,我们希望两种方法可以互换。为了这个目标,我们必须安装一个特殊的匹配方法——可以与基于特征的方法互换,这将在下面的代码中看到:
Vectorleft_keypoints,right_keypoints;
// Detect keypoints in the left and right images
FastFeatureDetectorffd;
ffd.detect(img1, left_keypoints);
ffd.detect(img2, right_keypoints);
vectorleft_points;
KeyPointsToPoints(left_keypoints,left_points);
vectorright_points(left_points.size());
// making sure images are grayscale
Mat prevgray,gray;
if (img1.channels() == 3) {
cvtColor(img1,prevgray,CV_RGB2GRAY);
cvtColor(img2,gray,CV_RGB2GRAY);
} else {
prevgray = img1;
gray = img2;
}
// Calculate the optical flow field:
// how each left_point moved across the 2 images
vectorvstatus; vectorverror;
calcOpticalFlowPyrLK(prevgray, gray, left_points, right_points,
vstatus, verror);
// First, filter out the points with high error
vectorright_points_to_find;
vectorright_points_to_find_back_index;
for (unsigned inti=0; iright_features; // detected features
KeyPointsToPoints(right_keypoints,right_features);
Mat right_features_flat = Mat(right_features).reshape(1,right_
features.size());
// Look around each OF point in the right image
// for any features that were detected in its area
// and make a match.
BFMatchermatcher(CV_L2);
vector>nearest_neighbors;
matcher.radiusMatch(
right_points_to_find_flat,
right_features_flat,
nearest_neighbors,
2.0f);
// Check that the found neighbors are unique (throw away neighbors
// that are too close together, as they may be confusing)
std::setfound_in_right_points; // for duplicate prevention
for(inti=0;i1) {
// 2 neighbors – check how close they are
double ratio = nearest_neighbors[i][0].distance /
nearest_neighbors[i][1].distance;
if(ratio < 0.7) { // not too close
// take the closest (first) one
_m = nearest_neighbors[i][0];
} else { // too close – we cannot tell which is better
continue; // did not pass ratio test – throw away
}
} else {
continue; // no neighbors... :(
}
// prevent duplicates
if (found_in_right_points.find(_m.trainIdx) == found_in_right_points.
end()) {
// The found neighbor was not yet used:
// We should match it with the original indexing
// ofthe left point
_m.queryIdx = right_points_to_find_back_index[_m.queryIdx];
matches->push_back(_m); // add this match
found_in_right_points.insert(_m.trainIdx);
}
}
cout<<"pruned "<< matches->size() <<" / "< 函数KeyPointsToPoints和PointsToKeyPoints是用来进行cv::Point2f和cv::KeyPoint结构体之间相互转换的简单方便的函数。从先前的代码片段我们可以看到一些有趣的事情。第一个注意的事情是,当我们使用光流时,我们的结果表明,一个特征从左手边图像的一个位置移动到右手边图像的另外一个位置。但是我们有一组在右手边图像中检测到的新的特征,在光流中从这个图像到左手边图像的特征不一定是对齐的。我们必须使它们对齐。为了找到这些丢失的特征,我们使用一个k邻近(KNN)半径搜索,这给出了我们两个特征,即感兴趣的点落入了2个像素半径范围内。
我们可以看得到另外一个事情是用来测试KNN的比例的实现,在SfM中这是一种常见的减少错误的方法。实质上,当我们对左手边图像上的一个特征和右手边图像上的一个特征进行匹配时,它作为一个滤波器,用来移除混淆的匹配。如果右手边图像中两个特征太靠近,或者它们之间这个比例(the rate)太大(接近于1.0),我们认为它们混淆了并且不使用它们。我们也安装一个双重防御滤波器来进一步修剪匹配。
下面的图像显示了从一幅图像到另外一幅图像的流场。左手边图像中的分红色箭头表示了块从左手边图像到右手边图像的运动。在左边的第二个图像中,我们看到一个放大了的小的流场区域。粉红色箭头再一次表明了块的运动,并且我们可以通过右手边的两个原图像的片段看到它的意义。在左手边图像上可视的特征正在向左移动穿过图像,粉红色箭头的方向在下面的图像中展示:

使用光流法代替丰富特征的优点是这个过程通常更快并且可以适应更多的点,使重构更加稠密。在许多光流方法中也有一个块整体运动的统一模型,在这个模型中,丰富的特征匹配通常不考虑。使用光流要注意的是对于从同一个硬件获取的连续图像,它处理的很快,然而丰富的特征通常不可知。它们之间的差异源于这样的一个事实:光流法通常使用非常基础的特征,像围绕着一个关键点的图像块,然而,高阶丰富特征(例如,SURF)考虑每一个特征点的较高层次的信息。使用光流或者丰富的特征是设计师根据应用程序的输入所做的决定。
找到相机矩阵——Finding camera matrices
既然我们获得了两个关键点之间的匹配,我们可以计算基础矩阵并且从中获得本征矩阵。然而,我们必须首先调整我们的匹配点到两个数组,其中数组中的索引对应于另外一个数组中同样的索引。这需要通过findFundametalMat函数获得。我们可能也需要转换KeyPoint 结构到Point2f结构。我们必须特别注意DMatch的queryIdx和trainIdx成员变量,在OpenCV中DMatch是容纳两个关键点匹配的结构,因为它们必须匹配我们使用matche.match()函数的方式。下面的代码部分展示了如何调整一个匹配到两个相应的二维点集,以及如何使用它们来找到基础矩阵:
vectorimgpts1,imgpts2;
for( unsigned inti = 0; i E = K.t() * F * K; //according to HZ (9.12) 稍后我们可能使用status二值向量来修剪这些点,使这些点和恢复的基础矩阵匹配。看下面的图像:用来阐述使用基础矩阵修剪后的点匹配。红色箭头表示特征匹配在寻找基础矩阵的过程中被移除了,绿色箭头表示被保留的特征匹配。

现在我们已经准备好寻找相机矩阵。这个过程在H和Z书的第九章进行了详细的描述。然而,我们将使用一个直接和简单的方法来实现它,并且OpenCV很容易的为我们做这件事。但是首先,我们将简短地检查我们将要使用的相机矩阵的结构:

我们的相机使用该模型,它由两个成分组成,旋转(表示为R)和平移(表示为t)。关于它的一个有趣的事情是它容纳一个非常基本的等式:x=PX,这里x是图像上的二维点,X是空间上的三维点。还有更多,但是这个矩阵给我们一个非常重要的关系,即图像中点和场景中点之间的关系。因此,既然我们有了寻找摄像机矩阵的动机,那么我们将看到这个过程是怎么完成的。下面的的代码部分展示了如何将本征矩阵分解为旋转和平移成分。
SVD svd(E);
Matx33d W(0,-1,0,//HZ 9.13
1,0,0,
0,0,1);
Mat_ R = svd.u * Mat(W) * svd.vt; //HZ 9.19
Mat_ t = svd.u.col(2); //u3
Matx34d P1( R(0,0),R(0,1), R(0,2), t(0),
R(1,0),R(1,1), R(1,2), t(1),
R(2,0),R(2,1), R(2,2), t(2));
非常简单。我们需要做的工作仅是对我们先前获得的本征矩阵进行奇异值分解(SVD),并且乘以一个特殊的矩阵W。对于我们所做的数学上的操作不进行过深地阐述,我们可以说SVD操作将我们的矩阵E分解成为两部分,一个旋转成分和一个平移成分。实时上,本征矩阵起初是通过这两个成分相乘构成的。完全地是满足我们的好奇心,我们可以看下面的本征矩阵的等式,它在字面意义上表现为:E=[t]xR(x是t的下标)。我可以看到它是由一个平移成分和一个旋转成分组成。
我们注意到,我们所做的仅是得到了一个相机矩阵,因此另外一个相机矩阵呢?好的,我们在假定一个相机矩阵是固定的并且是标准的(没有旋转和平移)情况下进行这个操作。下一个矩阵(这里的下一个矩阵表示相对于上面的P)也是标准的:
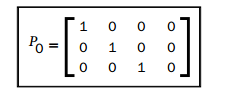
我们从本征矩阵恢复的另外一个相机相对于固定的相机进行了移动和旋转。这同样意味着我们从这两个相机矩阵中恢复的任何三维点都是拥有第一个相机在世界坐标系中的原点(0,0,0)。
然而,这不是一个完全解。H和Z在他们的书中展示了如何和为什么这样的分解有四个可能的相机矩阵,但是仅有一个是正确的。正确的相机矩阵将产生带有一个正Z值(点在摄像机的前面)的重构点。但是我们仅有当学了下一步将要讨论的三角测量和3维重建之后才能理解。
还有一个我们可以考虑添加到我们的方法中的事情是错误检测。多次从点的匹配中计算基础矩阵是错误的,并影响相机矩阵。带有错误相机矩阵的进行三角测量是毫无意义的。我们可以安装一个检查来检测是否旋转成分是一个有效的旋转矩阵。牢记旋转矩阵必须是一个行列式值为1(或者-1),我们可以简单地进行如下做法:
bool CheckCoherentRotation(cv::Mat_& R) {
if(fabsf(determinant(R))-1.0 > 1e-07) {
cerr<<"det(R) != +-1.0, this is not a rotation matrix"<& imgpts1,
const vector& imgpts2,
Matx34d& P,
Matx34d& P1,
vector& matches,
vector& outCloud
)
{
//Find camera matrices
//Get Fundamental Matrix
Mat F = GetFundamentalMat(imgpts1,imgpts2,matches);
//Essential matrix: compute then extract cameras [R|t]
Mat_ E = K.t() * F * K; //according to HZ (9.12)
//decompose E to P' , HZ (9.19)
SVD svd(E,SVD::MODIFY_A);
Mat svd_u = svd.u;
Mat svd_vt = svd.vt;
Mat svd_w = svd.w;
Matx33d W(0,-1,0,//HZ 9.13
1,0,0,
0,0,1);
Mat_ R = svd_u * Mat(W) * svd_vt; //HZ 9.19
Mat_ t = svd_u.col(2); //u3
if (!CheckCoherentRotation(R)) {
cout<<"resulting rotation is not coherent\n";
P1 = 0;
return;
}
P1 = Matx34d(R(0,0),R(0,1),R(0,2),t(0),
R(1,0),R(1,1),R(1,2),t(1),
R(2,0),R(2,1),R(2,2),t(2));
}
此时,我们拥有两个我们需要用来重建场景的相机。第一个相机是标准的,存储在P变量中,第二个相机是我们计算得到的,构成基础矩阵,存储在P1变量中。下一部分我们将揭示如何使用这些相机来获得场景的三维重建。
重构场景——Reconstructing the scene
接下来我们看一下从我们已经获得的信息中恢复场景的3D结构的事情。像先前所做的,我们应当看一下,用来完成这个事情我们手边所拥有的工具和信息。在前一部分,我们从本征矩阵和矩阵矩阵中获得了两个相机矩阵。我们已经讨论了这些工具用来获得空间中一点的3D位置是如何的有用。那么,我可以返回我们的匹配点来用数据填充等式。点对同样对于计算我们获得的近似计算的误差有用。
现在我们看一些如何使用OpenCV执行三角测量。这次我们将会按照Tartley和Strum的三角测量的文章的步骤,文章中他们实现和比较了一些三角剖分的方法。我们将实现他们的线性方法的一种,因为使用OpenCv非常容易编程。
回忆一下,我们有两个由2D点匹配和P矩阵产生的关键等式:x=PX和x’=P’X,x和x’是匹配的二维点,X是两个相机进行拍照的真实世界三维点。如果我们重写这个等式,我们可以公式化为一个线性方程系统,该系统可以解出X的值,X正是我们所期望寻找的值。假定X=(x,y,z,1)t(一个合理的点的假设,这些点离相机的中心不太近或者不太远)产生一个形式为AX=B的非齐次线性方程系统。我们可以编码和解决这个问题,如下:
Mat_ LinearLSTriangulation(
Point3d u,//homogenous image point (u,v,1)
Matx34d P,//camera 1 matrix
Point3d u1,//homogenous image point in 2nd camera
Matx34d P1//camera 2 matrix
)
{
//build A matrix
Matx43d A(u.x*P(2,0)-P(0,0),u.x*P(2,1)-P(0,1),u.x*P(2,2)-P(0,2),
u.y*P(2,0)-P(1,0),u.y*P(2,1)-P(1,1),u.y*P(2,2)-P(1,2),
u1.x*P1(2,0)-P1(0,0), u1.x*P1(2,1)-P1(0,1),u1.x*P1(2,2)-P1(0,2),
u1.y*P1(2,0)-P1(1,0), u1.y*P1(2,1)-P1(1,1),u1.y*P1(2,2)-P1(1,2)
);
//build B vector
Matx41d B(-(u.x*P(2,3)-P(0,3)),
-(u.y*P(2,3)-P(1,3)),
-(u1.x*P1(2,3)-P1(0,3)),
-(u1.y*P1(2,3)-P1(1,3)));
//solve for X
Mat_ X;
solve(A,B,X,DECOMP_SVD);
return X;
}
我们将获得由两个2维点产生的3D点的一个近似。还有一个要注意的事情是,2D点用齐次坐标表示,意味着x和y的值后面追加一个1。我们必须确保这些点在标准化的坐标系中,这意味着它们必须乘以先前的标定矩阵K.我们可能注意到我们简单地利用KP矩阵来替代k矩阵和每一个点相乘(每一点乘以KP),就是H和Z遍及第9章的做法那样。我们现在可以写一个关于点匹配的循环语句来获得一个完整的三角测量,如下:
double TriangulatePoints(
const vector& pt_set1,
const vector& pt_set2,
const Mat&Kinv,
const Matx34d& P,
const Matx34d& P1,
vector& pointcloud)
{
vector reproj_error;
for (unsigned int i=0; i um = Kinv * Mat_(u);
u = um.at(0);
Point2f kp1 = pt_set2[i].pt;
Point3d u1(kp1.x,kp1.y,1.0);
Mat_ um1 = Kinv * Mat_(u1);
u1 = um1.at(0);
//triangulate
Mat_ X = LinearLSTriangulation(u,P,u1,P1);
//calculate reprojection error
Mat_ xPt_img = K * Mat(P1) * X;
Point2f xPt_img_(xPt_img(0)/xPt_img(2),xPt_img(1)/xPt_img(2));
reproj_error.push_back(norm(xPt_img_-kp1));
//store 3D point
pointcloud.push_back(Point3d(X(0),X(1),X(2)));
}
//return mean reprojection error
Scalar me = mean(reproj_error);
return me[0];
}
在下面的图像中我们将看到一个两个图像三角测量的结果。这两个图像来至于P-11序列:
http://cvlab.epfl.ch/~strecha/multiview/denseMVS.html.
上面的两个图像是原始场景的两个视图,下面的一对图像是从两个视图重构得到的点云视图,包含着估计相机朝向喷泉。我们可以看到右手边红色砖块墙部分是如何重构的,并且也可以看到突出于墙的喷泉。

然而,像我们前面提到的那样,关于重构存在着这样的一个问题:重构仅能达到尺度上的。我们应当花一些时间来理解达到尺度(up-to-scale)的意思。我们获得的两个摄像机之间的运动存在一个随意测量的单元,也就是说,它不是用厘米或者英寸,而是简单地给出尺度单位。我们重构的相机将是尺度单元距离上的分开。这在很大程度上暗示我们应当决定过会重新获得更多的相机,因为每一对相机都拥有各自的尺度单元,而不是一个一般的尺度。
现在我们将讨论我们建立的误差测量是如何可能的帮助我们来找到一个更加鲁棒性的重构。首先,我们需要注意重投影意味着我们简单地利用三角化的3D点并且将这些点重塑到相机上以获得一个重投影的2D点。如果这个距离很大,这意味着我们在三角测量中存在一个误差,因此,在最后的结果中,我们可能不想包含这个点。我们的全局测量是平均重投影距离并且可能提供一个暗示——我们的三角剖分总体执行的怎么样。高的重投影率可能表明P矩阵存在问题,因此该问题可能是存在于本征矩阵的计算或者匹配特征点中。
我们应当简短地回顾一下在前一部分我们讨论的相机矩阵。我们提到相机矩阵P1的分解可以通过四个不同的方式进行分解,但是仅有一个分解是正确的。既然,我们知道如何三角化一个点,我们可以增加一个检测来看四个相机矩阵中哪一个是有效地的。我们应当跳过在一点实现上的细节,因为它们是本书随书实例代码中的精选(专题)。
下一步,我们将要看一下重新获得直视场景的更多的相机,并且组合这些3D重建的结果。
从多视图中重建——Reconstruction from many views
既然我们知道了如何从两个相机中恢复运动和场景几何,简单地应用相同的过程获得额外相机的参数和更多场景点似乎不重要。事实上,这件事并不简单因为我们仅可以获得一个达到尺度的重构,并且每对图像给我们一个不同的尺度。
有一些方法可以正确的从多个视场中重构3D场景数据。一个方法是后方交会(resection)或者相机姿态估计(camera pose estimation),也被称为PNP(Perspective-N-Point),这里我们将使用我们已经找到的场景点来解决一个新相机的位置。另外一个方法是三角化更多的点并且看它们是如何适应于我们存在的场景几何的。凭借ICP(Iterative Closest Point )我们可以获得新相机的位置。在这一章,我们将讨论使用OpenCV的sovlePnP函数来完成第一个方法。
第一步我们选择这样的重构类型即使用相机后方交会的增加的3D重构,来获得一个基线场景结构。因为我们将基于一个已知的场景结构来寻找任何相机的位置,我们需要找到要处理的一个初始化的结构和一条基线。我们可以使用先前讨论的方法——例如,在第一个视频帧和第二个视频帧之间,通过寻找相机矩阵(使用FindCameraMatrices函数)来获得一条基线并且三角化几何(使用TriangulatePoints函数)。
发现一个基础结构后,我们可以继续。然而,我们的方法需要相当多的数据记录。首先,我们需要注意solvePnP函数需要两个对齐的3D和2D点的矢量。对齐的矢量意味着一个矢量的第i个位置与另外一个矢量的第i位置对齐。为了获得这些矢量,我们需要在我们早前恢复的3D点中找到这些点,这些点与在我们新视频帧下的2D点是对齐的。完成这个的一个简单的方式是,对于云中的每一个3D点,附加一个来至2D点的矢量。然后我们可以使用特征匹配来获得一个匹配对。
让我们为一个3D点引入一个新的结构,如下:
struct CloudPoint {
cv::Point3d pt;
std::vectorindex_of_2d_origin;
};
它容纳,3D点和一个容器,容器内的元素为每帧图像上2D点的索引值,这些2D点用来计算3D点。当三角化一个新的3D点时,index_of_2d_origin的信息必须被初始化,来记录在三角化中哪些相机涉及到。然而,我们可以使用它来从我们的3D点云追溯到每一帧上的2D点,如下:
std::vector pcloud; //our global 3D point cloud
//check for matches between i'th frame and 0'th frame (and thus the
current cloud)
std::vector ppcloud;
std::vector imgPoints;
vector pcloud_status(pcloud.size(),0);
//scan the views we already used (good_views)
for (set::iterator done_view = good_views.begin(); done_view !=
good_views.end(); ++done_view)
{
int old_view = *done_view; //a view we already used for
reconstrcution
//check for matches_from_old_to_working between
'th frame and 'th frame (and thus
the current cloud)
std::vector matches_from_old_to_working =
matches_matrix[std::make_pair(old_view,working_view)];
//scan the 2D-2D matched-points
for (unsigned int match_from_old_view=0;
match_from_old_view
int idx_in_old_view =
matches_from_old_to_working[match_from_old_view].queryIdx;
//scan the existing cloud to see if this point from
exists for (unsigned int pcldp=0; pcldp contributed to this 3D
point in the cloud
if (idx_in_old_view == pcloud[pcldp].index_of_2d_origin[old_view]
&& pcloud_status[pcldp] == 0) //prevent duplicates
{
//3d point in cloud
ppcloud.push_back(pcloud[pcldp].pt);
//2d point in image
Point2d pt_ = imgpts[working_view][matches_from_old_to_
working[match_from_old_view].trainIdx].pt;
imgPoints.push_back(pt_);
pcloud_status[pcldp] = 1;
break;
}
}
}
}
cout<<"found "<
现在,我们有一个场景中3D点到一个新视频帧中2D点水平对齐对,我们可以使用他们重新得到相机的位置,如下:
cv::Mat_ t,rvec,R;
cv::solvePnPRansac(ppcloud, imgPoints, K, distcoeff, rvec, t, false);
//get rotation in 3x3 matrix form
Rodrigues(rvec, R);
P1 = cv::Matx34d(R(0,0),R(0,1),R(0,2),t(0),
R(1,0),R(1,1),R(1,2),t(1),
R(2,0),R(2,1),R(2,2),t(2));
既然我们正在使用sovlePnPRansac函数而不是sovlePnP函数,因为它对于异常值有更好的鲁棒性。既然我们获得了一个新的P1矩阵,我们可以简单的再次使用我们早先定义的TriangualtePoints函数并且用更多的3D点来填充我们的3D点云。
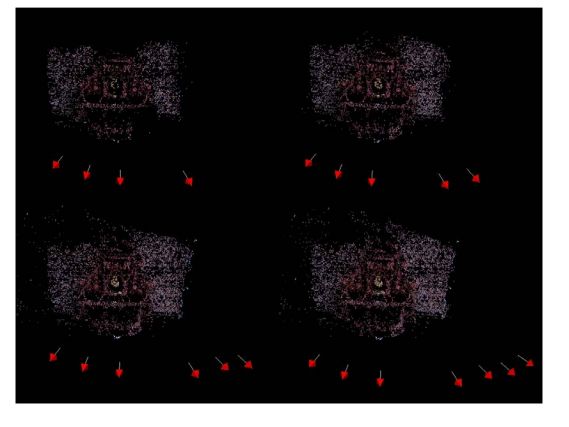
在下面的图像中,我们看到一个增加的喷泉场景的重构(访问:http://cvlab.epfl.ch/~strecha/multiview/denseMVS.html,),从第四个图像。左上角的图像是使用了4个图像的重构;参加拍摄的相机用带有白线的红色简单表示,箭头表示了方向。其他的图像展示了更多 的相机来添加更多的点到点云中。
重构提纯——Refinement of the reconstruction
SfM方法中最重要的一个部分是提纯和最优化重构场景,通常被称作BA过程(Bundle Adjustment)。这是一个优化步骤,这里我们获得的所有数据适应于一个统一的模型。3D点的位置和相机的位置都得到了最优化,因此重投影误差最小(也就是说估计的3D点重投影到图像上接近于起源的2D点的位置)。这个过程通常需要解决带有几十千个参数指令的巨大的线性方程。这个过程可能会有些费力,但是我们前面采取的步骤允许带有一个束调节(bundle adjuster)的简单的整合。前面看起来奇怪的事情变的清晰了。例如,我们保留为点云中的每一个3D点保存原始的2D点的理由。
束调节的一个实现算法是简单稀疏束条调节SSBA(Simple Sparse Bundle Adjustment)库。我们将选择它作为我们的BA优化器, 因为它拥有简单的API。它仅需要少量的输入参数,这些输入参数我们可以相当简单的从我们的数据结构中创建。SSBA中我们使用的关键对象是CommonInternasMetricBundleOptimizer函数,这个函数执行最优化。它需要相机参数,3D点云,点云中每一个点相对应的2D图像点,以及直视场景的相机。到现在为止,利用这些参数应该很直接。我们应当注意这个BA方法假定所有图像通过同样的硬件获取,因此共同的内部,其他操作模式可能不需要假定这样的情况。我们可以执行束调节(Bundle Adjustment),如下:
voidBundleAdjuster::adjustBundle(
vector&pointcloud,
const Mat&cam_intrinsics,
conststd::vector>&imgpts,
std::map&Pmats
)
{
int N = Pmats.size(), M = pointcloud.size(), K = -1;
cout<<"N (cams) = "<< N <<" M (points) = "<< M <<" K (measurements) =
"<< K <(0,0);
KMat[0][1] = cam_intrinsics.at(0,1);
KMat[0][2] = cam_intrinsics.at(0,2);
KMat[1][1] = cam_intrinsics.at(1,1);
KMat[1][2] = cam_intrinsics.at(1,2);
...
// 3D point cloud
vectorXs(M);
for (int j = 0; j < M; ++j)
{
Xs[j][0] = pointcloud[j].pt.x;
Xs[j][1] = pointcloud[j].pt.y;
Xs[j][2] = pointcloud[j].pt.z;
}
cout<<"Read the 3D points."< cams(N);
for (inti = 0; i< N; ++i)
{
intcamId = i;
Matrix3x3d R;
Vector3d T;
Matx34d& P = Pmats[i];
R[0][0] = P(0,0); R[0][1] = P(0,1); R[0][2] = P(0,2); T[0] = P(0,3);
R[1][0] = P(1,0); R[1][1] = P(1,1); R[1][2] = P(1,2); T[1] = P(1,3);
R[2][0] = P(2,0); R[2][1] = P(2,1); R[2][2] = P(2,2); T[2] = P(2,3);
cams[i].setIntrinsic(Knorm);
cams[i].setRotation(R);
cams[i].setTranslation(T);
}
cout<<"Read the cameras."< measurements;
vector correspondingView;
vector correspondingPoint;
// 2D corresponding points
for (unsigned int k = 0; k = 0) {
int view = i, point = k;
Vector3d p, np;
Point cvp = imgpts[i][pointcloud[k].imgpt_for_img[i]].pt;
p[0] = cvp.x;
p[1] = cvp.y;
p[2] = 1.0;
// Normalize the measurements to match the unit focal length.
scaleVectorIP(1.0/f0, p);
measurements.push_back(Vector2d(p[0], p[1]));
correspondingView.push_back(view);
correspondingPoint.push_back(point);
}
}
} // end for (k)
K = measurements.size();
cout<<"Read "<< K <<" valid 2D measurements."<
使用PCL可视化3D点云——Visualizing 3D point clouds with PCL
当操作3D数据时,通过简单地观察重投影误差测量或原始点信息很难快速的理解结果是否正确。另一方面,如果我们观察点云(itself),我们可以立即的检查这个点是否有意义或者存在误差。为了可视化,我们将使用一个很有前途的OpenCV的姊妹工程,称为点云库(Point Cloud Librar)(PCL)。它带有许多可视化和分析点云的工具,例如找到一个平面,匹配点云,分割目标以及排除异常值。如果我们的目标不是一个点云,而是一些高级信息例如3D模型,这些工具将非常有用。
首先,我们需要在PCL的数据结构中表示我们的点云(本质上是3D点的列表)。可以通过如下的做法实现:
pcl::PointCloud::Ptr cloud;
void PopulatePCLPointCloud(const vector& pointcloud,
const std::vector& pointcloud_RGB
)
//Populate point cloud
{
cout<<"Creating point cloud...";
cloud.reset(new pcl::PointCloud);
for (unsigned int i=0; i= i) {
rgbv = pointcloud_RGB[i];
}
// check for erroneous coordinates (NaN, Inf, etc.)
if (pointcloud[i].x != pointcloud[i].x || isnan(pointcloud[i].x) ||
pointcloud[i].y != pointcloud[i].y || isnan(pointcloud[i].y) ||
pointcloud[i].z != pointcloud[i].z || isnan(pointcloud[i].z) ||
fabsf(pointcloud[i].x) > 10.0 ||
fabsf(pointcloud[i].y) > 10.0 ||
fabsf(pointcloud[i].z) > 10.0) {
continue;
}
pcl::PointXYZRGB pclp;
// 3D coordinates
pclp.x = pointcloud[i].x;
pclp.y = pointcloud[i].y;
pclp.z = pointcloud[i].z;
// RGB color, needs to be represented as an integer
uint32_t rgb = ((uint32_t)rgbv[2] << 16 | (uint32_t)rgbv[1] << 8 |
(uint32_t)rgbv[0]);
pclp.rgb = *reinterpret_cast(&rgb);
cloud->push_back(pclp);
}
cloud->width = (uint32_t) cloud->points.size(); // number of points
cloud->height = 1; // a list of points, one row of data
}
为了可视化有一个好的效果,我们也可以提供彩色数据如同图像中的RGB值。我们同样也可以对原始点云应用一个滤波器,这将消除可能是异常值的点,使用统计移除移除(statistical outlier removal)(SOR)工具如下:
Void SORFilter() {
pcl::PointCloud::Ptr cloud_filtered (new pcl::PointC
loud);
std::cerr<<"Cloud before SOR filtering: "<< cloud->width * cloud->height <<" data points"<sor;
sor.setInputCloud (cloud);
sor.setMeanK (50);
sor.setStddevMulThresh (1.0);
sor.filter (*cloud_filtered);
std::cerr<<"Cloud after SOR filtering: "<width *
cloud_filtered->height <<" data points "<
然后,我们可以使用PCL的API来运行一个简单的点云的可视化器,如下:
Void RunVisualization(const vector& pointcloud,
const std::vector& pointcloud_RGB) {
PopulatePCLPointCloud(pointcloud,pointcloud_RGB);
SORFilter();
copyPointCloud(*cloud,*orig_cloud);
pcl::visualization::CloudViewer viewer("Cloud Viewer");
// run the cloud viewer
viewer.showCloud(orig_cloud,"orig");
while (!viewer.wasStopped ())
{
// NOP
}
}
下面的图像展示了统计移除移除工具(statistical outlier removal tool)使用之后的输出结果。左手边的图像是SfM的原始结果点云。右手边的图像展示经过SOR操作滤波之后的点云。我们能够注意到一些离群的点被移除了,剩下了一个更干净的点云。

使用实例代码——Using the example code
我们可以在这本书提供的材料中找到SfM的实例代码。我们现在看一些怎么样编译,运行和利用它。代码使用CMake,一个交叉编译环境,类似于Maven或者SCons。我们同样应当确保我们有下面的所有前提条件来编译我们的应用程序:
• OpenCV v2.3 or highe
• PCL v1.6 or higher
• SSBA v3.0 or higher
首先,我们必须建立编译环境。为此,我们可能创建一个文件夹,命名为build,我们将所有编译相关的文件存储在这里。现在我们将假定所有的命令行操作都是在build/文件夹内,虽然这个过程是类似的(取决于文件的位置),即使没有使用build文件夹。
我们应当确保CMake可以找到SSBA和PCL,如果PCL正确的安装了,那没有问题。然而,我们必须通过-DSSBA_LIBRARY_DIR=...编译参数设置正确的位置来找到SSBA的预编译库。如果我们正在使用Windows操作系统,我们可以使用Microsoft Visual Studio来编译,因此,我们应当运行下面的的命令:
cmake –G "Visual Studio 10" -DSSBA_LIBRARY_DIR=../3rdparty/SSBA-3.0/
build/ ..
如果我们使用Linux,Mac Os,或者其他Unix-Like操作系统,我们执行下面的命令:
cmake –G "Unix Makefiles" -DSSBA_LIBRARY_DIR=../3rdparty/SSBA-3.0/build/
..
如果我们喜欢使用MacOS上的XCode,执行下面的命令:
cmake –G Xcode -DSSBA_LIBRARY_DIR=../3rdparty/SSBA-3.0/build/ ..
CMake同样可以为Eclipse,Codeblocks,和更多的环境编译宏命令。CMake完成创建编译环境之后,我们准备编译。如果我们正在使用一个Unix-like系统,我们可以简单地执行这个生成工具(the make utility),否则我们应当使用我们开发环境的编译过程。
编译完成之后,我们应当获得了一个执行程序名为ExploringSfMExex,这用来运行SfM过程。不带参数运行这个程序会导致如下的显示: USAGE: ./ExploringSfMExec
为了在图像集上执行这个过程,我们应当提供位置作为驱动来找到图像文件。如果提供了有效的位置,过程开始,我应当看到这个进程和屏幕上的调试信息。程序的结束将显示源于图像的点云。按1和2键,可以切换到调整的(adjusted)点云和非调整的(non-adjusted)点云。
总结——Summary
在这一章,我们已经看到了OpenCV是怎样用一个既简单编码又好理解的方式来帮助我们处理来至运动的结构。OpenCV的API包含了一些有用的函数和数据结构,这使得我们生活的更加轻松,同样地协助我们有一个更清洁的实现。
然而,最先进的SfM方法更复杂。那里存在很多问题,我们选择忽略,喜欢简单化,以及在这些地方通常有更多的错误检查。对于不同的SfM成分,我们选择的方法同样可以再次访问。例如,H和Z提出了一个高精度的三角测量方法,甚至使用N-视图三角测量,曾经他们利用多个图像理解特征之间的关系。
如果我们想延伸和深化熟悉SfM,当然,我们将从观察其他开源SfM库中收益。一个特别感兴趣的工程是libMV,它实现了大量的SfM成分,通过互换,这可能获得最好的结果。华盛顿大学有一个伟大的作品,为很多类型SfM(Bundler and Visual SfM)提供了工具。这项作品的灵感来至于微软的在线产品,称作PhotoSynth。网上有很多容易访问到的SfM的实现,并且一个人仅需来找到更多的SfM的实现。
我们没有深入讨论的另外一个重要的关系是SfM和可视化定位以及映射,更好的称为同步定位和映射(SLAM)方法。在这一章,我们已经处理给出的图像集和一个视频序列,并且在这些情况下,使用SfM是可行的。然而,一些应用没有预记录的数据集并且必须动态时引导重建。这个过程被成为映射,并且当我们正在使用特征匹配和2D跟踪以及三角测量后来创建世界的3D映射时,这个过程被完成。
在下一章,我们将看到如何使用机器学习中的各种技术利用OpenCV从图像中提出车牌数字。
参考——References
• Multiple View Geometry in Computer Vision,Richard Hartley and Andrew
Zisserman,Cambridge University Press
• Triangulation, Richard I. Hartley and Peter Sturm, Computer vision and image
understanding, Vol. 68, pp. 146-157
• http://cvlab.epfl.ch/~strecha/multiview/denseMVS.html
• On Benchmarking Camera Calibration and Multi-View Stereo for High Resolution
Imagery,C. Strecha, W. von Hansen, L. Van Gool, P. Fua,and U. Thoennessen,
CVPR
• http://www.inf.ethz.ch/personal/chzach/opensource.html
• http://www.ics.forth.gr/~lourakis/sba/
• http://code.google.com/p/libmv/
• http://www.cs.washington.edu/homes/ccwu/vsfm/
• http://phototour.cs.washington.edu/bundler/
• http://photosynth.net/
• http://en.wikipedia.org/wiki/Simultaneous_localization_and_
mapping
• http://pointclouds.org
• http://www.cmake.org