seaborn之统计关系可视化
统计分析是了解数据集中的变量如何相互关联以及这些关系如何依赖于其他变量的过程。 可视化可以是此过程的核心组件,因为当数据可视化时,人类视觉系统可以看到指示关系的趋势和模式。
我们将在本教程中讨论三个seaborn函数。 我们最常用的是relplot()。 这是一个图形级函数,用于使用两种常见方法可视化统计关系:散点图和线图。 relplot()将FacetGrid与两个轴级函数之一组合在一起:
- scatterplot()(with kind =“scatter”;默认值)
- lineplot()(with kind=“line”)
正如我们将要看到的,这些函数可能非常有启发性,因为它们使用简单且易于理解的数据表示,但仍然可以表示复杂的数据集结构。 他们可以这样做,因为他们绘制二维图形,可以通过使用色调,大小和样式的语义映射多达三个附加变量来增强。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
使用散点图关联变量
散点图是统计可视化的支柱。 它描绘了使用点云的两个变量的联合分布,其中每个点代表数据集中的观察。 这种描述允许眼睛推断出关于它们之间是否存在任何有意义关系的大量信息。
有几种方法可以在seaborn中绘制散点图。 当两个变量都是数字时应该使用的最基本的是scatterplot()函数。 在分类可视化教程中,我们将看到使用散点图可视化分类数据的专用工具。 scatterplot()是relplot()中的默认类型(也可以通过设置kind ="scatter"强制它):
tips = sns.load_dataset("tips")
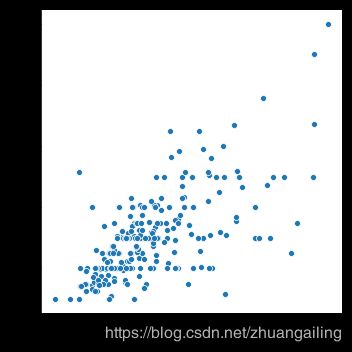
sns.relplot(x="total_bill", y="tip", data=tips)
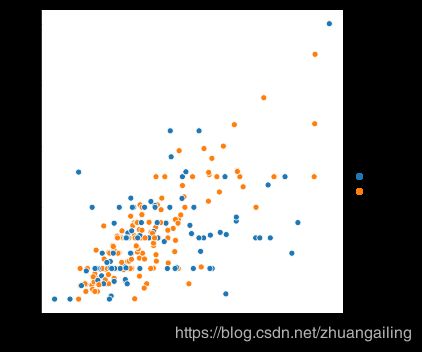
虽然这些点是以二维绘制的,但可以通过根据第三个变量对点进行着色来将另一个维度添加到绘图中。 在seaborn中,这被称为使用“色调语义”,因为该点的颜色获得了意义:
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)
虽然这些点是以二维绘制的,但可以通过根据第三个变量对点进行着色来将另一个维度添加到绘图中。 在seaborn中,这被称为使用“色调语义”,因为该点的颜色获得了意义:
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)
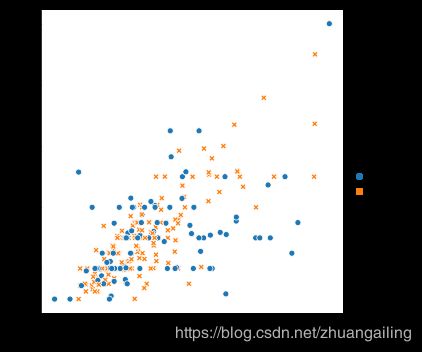
要强调类之间的差异并改善可访问性,可以为每个类使用不同的标记样式:
sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker",data=tips)
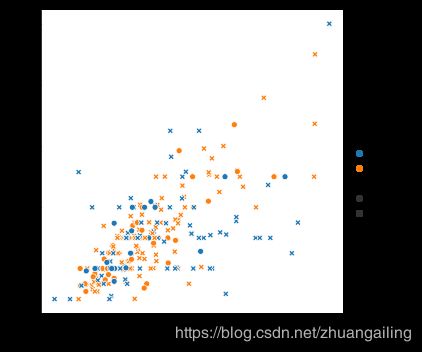
通过独立地改变每个点的色调和样式,也可以表示四个变量。 但这应该仔细进行,因为眼睛对形状的敏感性要小于颜色:
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips)
在上面的示例中,色调语义是分类的,因此应用了默认的定性调色板。 如果色调语义是数字的(具体来说,如果它可以转换为浮动),则默认着色切换到顺序调色板:
sns.relplot(x="total_bill", y="tip", hue="size", data=tips)
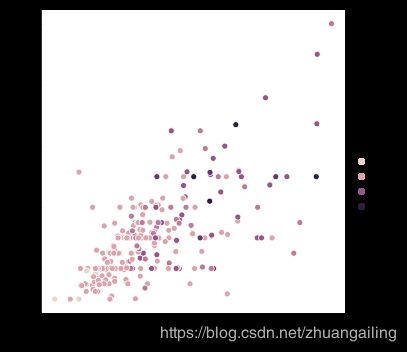
在这两种情况下,您都可以自定义调色板。 这样做有很多选择。 在这里,我们使用cubehelix_palette()()的字符串接口自定义顺序调色板。
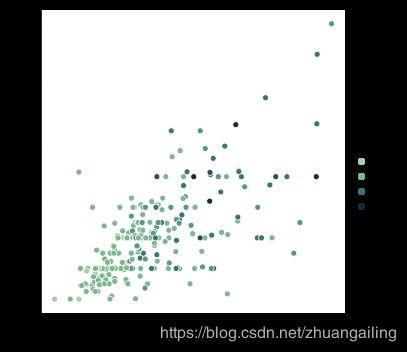
sns.relplot(x="total_bill", y="tip", hue="size", palette="ch:r=-.5,l=.75", data=tips)
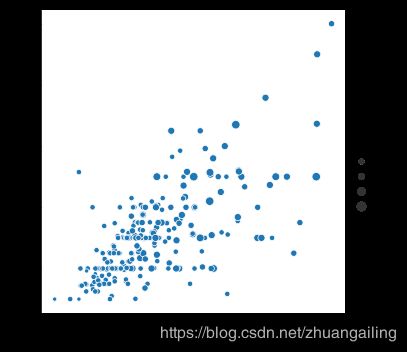
第三种语义变量改变了每个点的大小:
sns.relplot(x="total_bill", y="tip", size="size", data=tips)
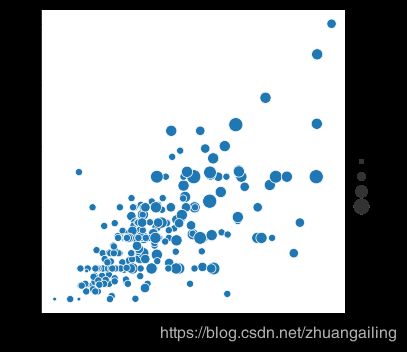
不像使用matplotlib.pyplot.scatte,变量的字面值不用于选择点的区域。 相反,数据单元中的值范围被归一化为面积单位的范围。 这个范围可以定制:
sns.relplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips)
scatterplot()API示例中显示了用于自定义如何使用不同语义来显示统计关系的更多示例。
强调线图的连续性
散点图非常有效,但没有普遍优化的可视化类型。 相反,视觉表示应该适应数据集的细节以及您试图用图表回答的问题。
对于某些数据集,您可能希望了解一个变量中的变化作为时间的函数,或者类似的连续变量。 在这种情况下,一个很好的选择是绘制线图。 在seaborn中,这可以通过lineplot()函数直接完成,也可以通过设置kind ="line"与relplot()完成:
import pandas as pd
import numpy as np
import seaborn as sns
df = pd.DataFrame(dict(time=np.arange(500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
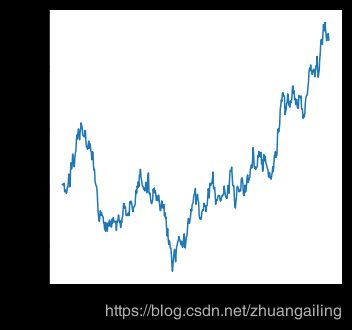
因为lineplot()假设您最常尝试将y绘制为x的函数,所以默认行为是在绘制之前按x值对数据进行排序。 但是,这可以被禁用:
df = pd.DataFrame(np.random.randn(500, 2).cumsum(axis=0), columns=["x", "y"])
sns.relplot(x="x", y="y", sort=False, kind="line", data=df)

聚合与置信
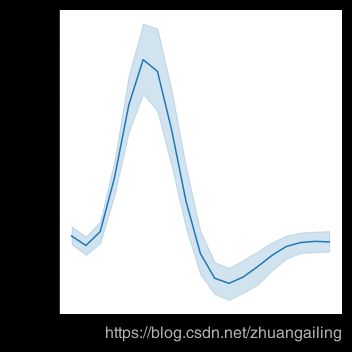
更复杂的数据集将对x变量的相同值进行多次测量。 seaborn中的默认行为是通过绘制平均值周围的平均值和95%置信区间来聚合每个x值的多个测量值:
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri)
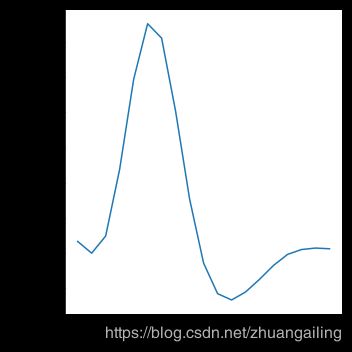
使用自举来计算置信区间,对于较大的数据集,这可能是时间密集的。 因此可以禁用它们:
sns.relplot(x="timepoint", y="signal", ci=None, kind="line", data=fmri)
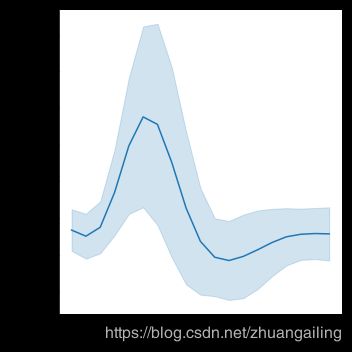
另一个好的选择,特别是对于较大的数据,是通过绘制标准偏差而不是置信区间来表示每个时间点的分布范围:
sns.relplot(x="timepoint", y="signal", kind="line", ci="sd", data=fmri)
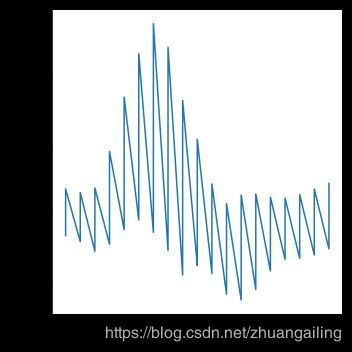
要完全关闭聚合,请将estimator参数设置为None。当数据在每个点上有多个观察值时,这可能会产生奇怪的效果。
sns.relplot(x="timepoint", y="signal", estimator=None, kind="line", data=fmri)
使用语义映射绘制数据子集
lineplot()函数与scatterplot()具有相同的灵活性:它可以通过修改绘图元素的色调,大小和样式来显示最多三个附加变量。 它使用与scatterplot()相同的API,这意味着我们不需要停止并考虑控制matplotlib中线条与点的外观的参数。
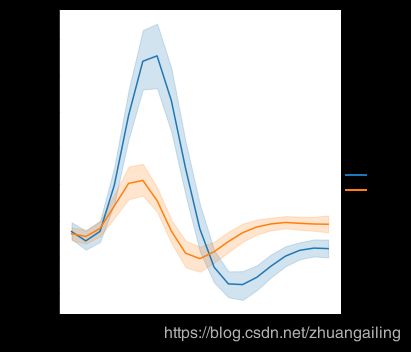
在lineplot()中使用语义还将确定数据如何聚合。 例如,添加具有两个级别的色调语义将绘图分成两行和错误带,每个都着色以指示它们对应于哪个数据子集。
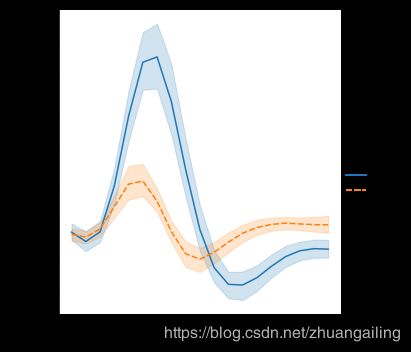
sns.relplot(x="timepoint", y="signal", hue="event", kind="line", data=fmri)
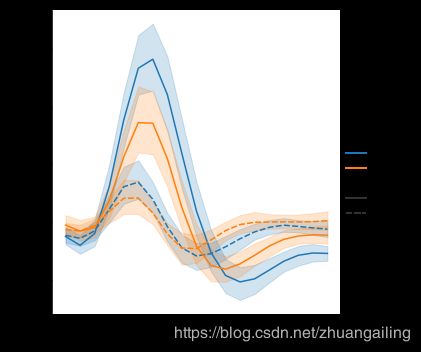
在线图中添加样式语义会默认更改行中的破折号模式:
sns.relplot(x="timepoint", y="signal", hue="region", style="event", kind="line", data=fmri)
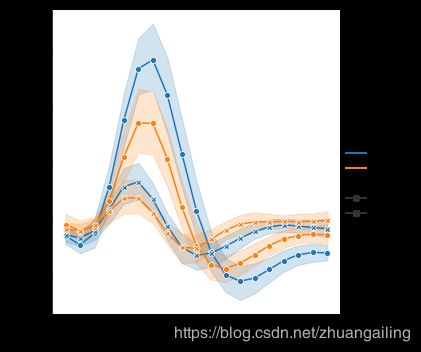
但您可以通过每次观察时使用的标记识别子集,或者使用短划线或代替它们:
sns.relplot(x="timepoint", y="signal", hue="region", style="event",dashes=False, markers=True, kind="line", data=fmri)
与散点图一样,要谨慎使用多个语义制作线图。 虽然有时提供信息,但它们也很难解析和解释。 但即使您只检查一个附加变量的变化,更改线条的颜色和样式也很有用。 当打印成黑白或有色盲的人观看时,这可以使绘图更容易访问:
sns.relplot(x="timepoint", y="signal",
hue="event", style="event",
kind="line", data=fmri)
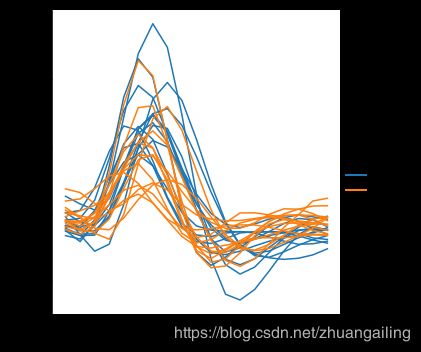
当您使用重复测量数据(即,您有多次采样的单位)时,您还可以单独绘制每个采样单位,而无需通过语义区分它们。 这样可以避免使图例混乱:
sns.relplot(x="timepoint", y="signal", hue="region",
units="subject", estimator=None,
kind="line", data=fmri.query("event == 'stim'"))
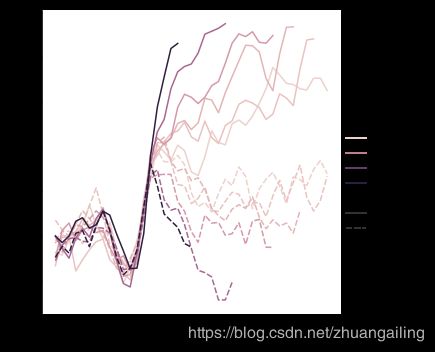
lineplot()中默认的色彩映射和图例处理还取决于色调语义是分类还是数字:
dots = sns.load_dataset("dots").query("align == 'dots'")
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
kind="line", data=dots)
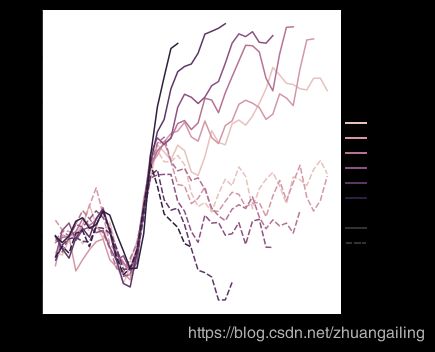
可能会发生这样的情况:即使hue变量是数字,它也很难用线性色标表示。 这就是这种情况,其中hue变量的级别以对数方式缩放。 您可以通过传递列表或字典为每一行提供特定的颜色值:
palette = sns.cubehelix_palette(light=.8, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
palette=palette,
kind="line", data=dots)
或者您可以更改色彩映射的规范化方式:
from matplotlib.colors import LogNorm
palette = sns.cubehelix_palette(light=.7, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
hue_norm=LogNorm(),
kind="line", data=dots)
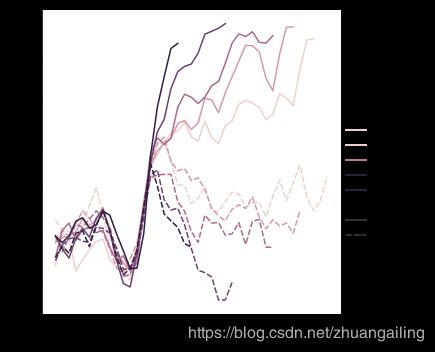
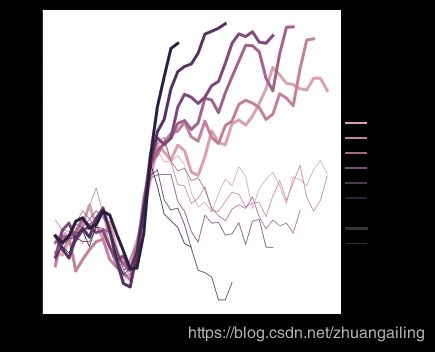
第三个语义,大小,改变线的宽度:
sns.relplot(x="time", y="firing_rate",
size="coherence", style="choice",
kind="line", data=dots)
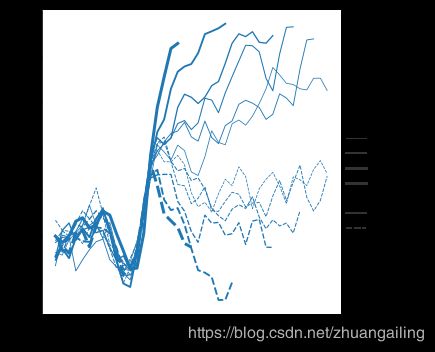
虽然size变量通常是数字,但也可以使用行的宽度映射分类变量。 这样做时要小心,因为很难区分“厚”和“薄”线。 但是,当线条具有高频可变性时,破折号很难被察觉,因此在这种情况下使用不同的宽度可能更有效:
sns.relplot(x="time", y="firing_rate",
hue="coherence", size="choice",
palette=palette,
kind="line", data=dots)
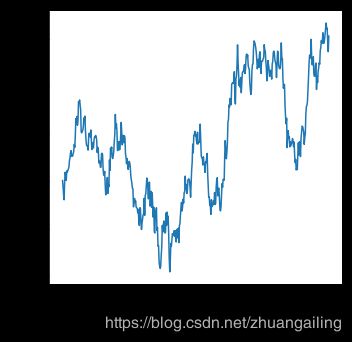
用日期数据绘图
线图通常用于可视化与实际日期和时间相关的数据。 这些函数以原始格式将数据传递给底层的matplotlib函数,因此他们可以利用matplotlib在tick标签中设置日期格式的功能。 但是所有这些格式化都必须在matplotlib层进行,你应该参考matplotlib文档来看看它是如何工作的:
df = pd.DataFrame(dict(time=pd.date_range("2019-1-1", periods=500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
用facets显示多组关系
我们在本教程中强调,虽然这些函数可以同时显示多个语义变量,但这样做并不总是有效。 但是,当你想要了解两个变量之间的关系如何依赖于多个其他变量时呢?
最好的方法可能是制作一个以上的情节。 因为relplot()基于FacetGrid,所以这很容易做到。 要显示附加变量的影响,而不是将其分配给绘图中的一个语义角色,请使用它来“构思”可视化。 这意味着您可以创建多个轴并在每个轴上绘制数据的子集:
sns.relplot(x="total_bill", y="tip", hue="smoker",col="time", data=tips)
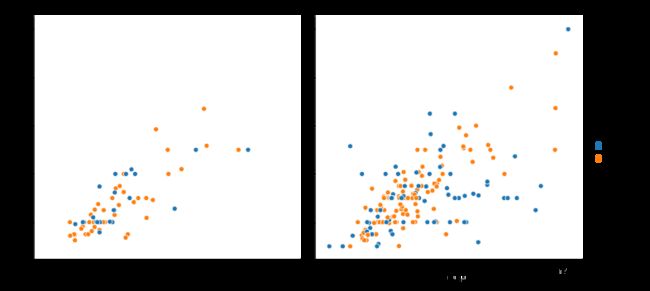
您还可以通过这种方式显示两个变量的影响:一个是通过在列上分面而另一个是在行上分面。 当您开始向网格添加更多变量时,您可能希望减小数字大小。 请记住,FacetGrid的大小由每个分面的高度和纵横比参数化:
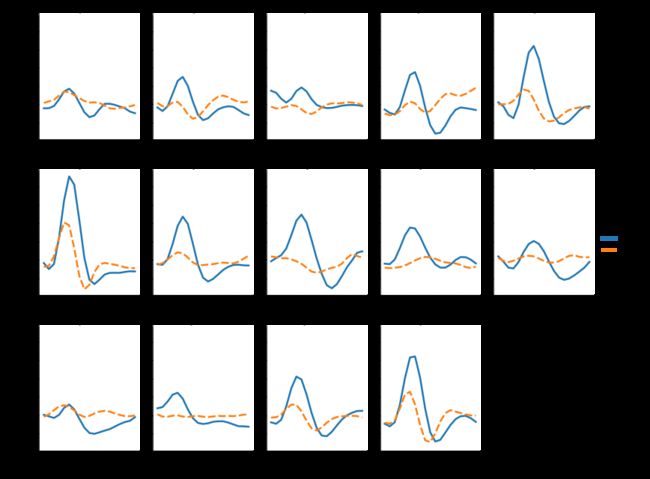
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
kind="line", estimator=None, data=fmri)
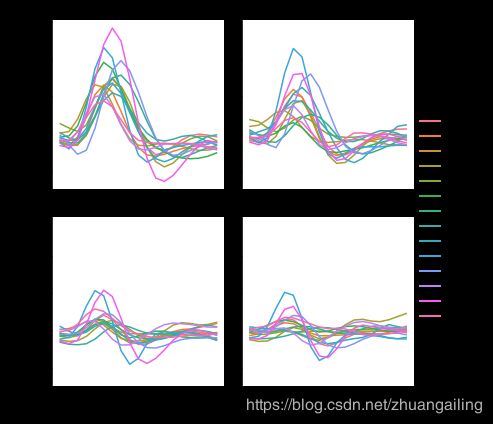
当你想要检查变量的多个级别的效果时,最好在列上该变量分组,然后将facet到分面行中:
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"))
这些可视化通常被称为“点阵”图或“small-multiples”,它们非常有效,因为它们以一种格式呈现数据,使肉眼易于检测整体模式和与这些模式的偏差。 虽然你应该利用scatterplot()和relplot()提供的灵活性,但总是要记住,几个简单的图通常比一个复杂的图更有效。
每天坚持学习 seaborn ,加油!
Visualizing statistical relationships原文链接