Mybatis 延迟加载和缓存
一、延迟加载简介
(1)概念:
延迟加载,也称为懒加载(LazyLoding)。
当代码中执行到查询语句时,并不是直接到DB中执行select语句进行查询,而是在需要它的时候才加载,不需要的话就不加载。
其实简单来说Mybatis的延迟加载就是分多次执行SQL语句,这样就实现了延迟加载的机制,并且第一次执行的结果值可能是接下来执行的SQL语句的参数值,Mybatis实现执行接下来的SQL的原理机制是通过代理类来实现的,就是第一次执行的结果对象其实已经是一个代理对象,当执行接下来相关的对象时会执行其他SQL语句,这样就实现了延迟加载的机制。
(2)延迟加载优点
懒加载主要是为了提高效率。假如说有一张用户表,还有一张聊天记录表。一个用户可能关联了 1000 条聊天记录。如果关联查询一次性就把这 1000 条数据查出来了,但是查出来这 1000 条数据,可能并没有用到聊天记录数据,只用到用户信息数据。懒加载的目的就是在用户真正需要查询数据的时候才去查询数据库,而不是第一次查询就查询出来。
(3)MyBatis的延迟加载
resultMap中的association和collection标签具有延迟加载的功能。
1)只能对关联对象进行查询时,使用延迟加载策略。对于主加载对象,均采用直接加载。
2)要应用延迟加载查询,只能使用多表单独查询,而不能使用多表连接查询。因为多表连接查询的本质是查询一张表,将多张表首先连接为了一张表后,再进行的查询。 查询一个信息,就会将所有信息全部查询到。
二、Mybatis延迟加载使用
(1)将mybaits配置文件的延迟加载开关打开,具体是在
(2)配置映射文件
业务需求是:输入班级id查询班级信息,懒加载该班级所有学生的信息
测试结果:
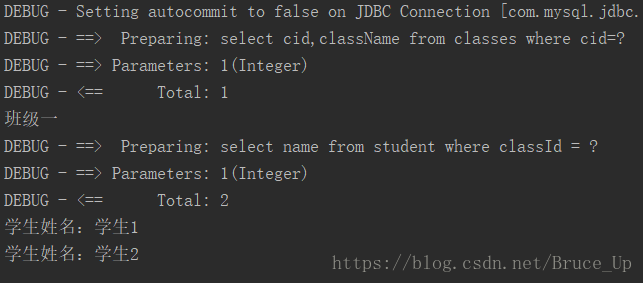
说明:
- 一对一延迟加载时,把collection 换成association即可
- 延迟加载不能用表连接进行查询
- select:指定关联的查询语句
- collection 标签里的column:指定主语句中的哪个字段的值作为参数传递给从sql语句,通常为数据库表的外键值
- fetchType设置是否懒加载,lazy代表懒加载
注意:
1. lazyLoadingEnabled与aggressiveLazyLoading必须全部设置,且lazyLoadingEnabled为true,aggressiveLazyLoading为false才能让延迟加载真正生效
2. toString与重载方法过滤:
通常我们在测试时会在实体类加入toString,或者存在了一些重载方法,这些MyBatis会对其进行过滤,但是过滤会调 用cglib与asm指定包,因此要将两个包添加到buildpath。以下为两个包的maven依赖:
cglib
cglib
3.1
asm
asm
3.3.1
三、缓存
客户端向数据库服务器发送同样的sql查询语句,如果每次都去访问数据库,会导致性能的降低,这是就用到了缓存。
(1)一级缓存
Mybatis的一级缓存是指SqlSession。一级缓存的作用域是一个SqlSession。Mybatis默认开启一级缓存。
在同一个SqlSession中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。
SqlSession的缓存清空三种方式:
- 当执行SQL时两次查询中间发生了增删改操作
- session.commit()
- session.clearCache()
例子:执行两次查询,发现只执行一次select语句,执行session.clearCache()语句,清空缓存,则会执行两次select语句

(2)二级缓存
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同 namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二 次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。Mybatis默认是没有开启二级缓存。

说明:
第一次调用mapper下的SQL去查询用户信息。查询到的信息会存到该mapper对应的二级缓存区域内。
第二次调用相同namespace下的mapper映射文件中相同的SQL去查询用户信息。会去对应的二级缓存内取结果。
如果调用相同namespace下的mapper映射文件中的增删改SQL,并执行了commit操作。此时会清空该namespace下的二级缓存。
应用场景:
对于访问多的查询请求且用户对查询结果实时性要求不高的,可以使用mybatis的二级缓存,降低数据库访问量,提高访问速度,例如:耗时较高的统计分析sql,电话账单查询,前一个月的消费查询等。
使用二级缓存
(1)setting全局参数设置
(2)配置sql映射文件
表示把此SQL映射文件的mapper对象的二级缓存功能打开
如果这样配置的话,很多其他的配置就会被默认进行,如:
- 映射文件所有的select 语句会被缓存
- 映射文件的所有的insert、update和delete语句会刷新缓存
- 缓存会使用默认的Least Recently Used(LRU,最近最少使用原则)的算法来回收缓存空间
- 根据时间表,比如No Flush Interval,(CNFI,没有刷新间隔),缓存不会以任何时间顺序来刷新
- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
- 缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以很安全的被调用者修改,不干扰其他调用者或县城所作的潜在修改
手动配置:
各个属性意义如下:
- eviction:缓存回收策略
- LRU:最少使用原则,移除最长时间不使用的对象
- FIFO:先进先出原则,按照对象进入缓存顺序进行回收
- SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK:弱引用,更积极的移除移除基于垃圾回收器状态和弱引用规则的对象- flushInterval:刷新时间间隔,单位为毫秒,这里配置的100毫秒。如果不配置,那么只有在进行数据库修改操作才会被动刷新缓存区
- size:引用额数目,代表缓存最多可以存储的对象个数
- readOnly:是否只读,如果为true,则所有相同的sql语句返回的是同一个对象(有助于提高性能,但并发操作同一条数据时,可能不安全),如果设置为false,则相同的sql,后面访问的是cache的clone副本。
(3)实现序列化
由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,所以需要给缓存的对象执行序列化。
如果该类存在父类,那么父类也要实现序列化。
禁用二级缓存