Python数据分析—— pandas统计分析基础 (二)
Python数据分析—— pandas统计分析基础 (二)
数据的排序
Pandas库的数据排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序。
.sort_index(axis=0,ascending=True)
例:
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[4]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
b.sort_index()
Out[5]:
0 1 2 3 4
a 5 6 7 8 9
b 15 16 17 18 19
c 0 1 2 3 4
d 10 11 12 13 14
b.sort_index(ascending=False)
Out[6]:
0 1 2 3 4
d 10 11 12 13 14
c 0 1 2 3 4
b 15 16 17 18 19
a 5 6 7 8 9
- .sort_values()方法在指定轴上根据数值进行排序,默认升序。
Series.sort_values(axis=0,ascending=True)
DataFrame.sprt_values(by,axis=0,ascending=True)
- by:axis轴上的某个索引或索引列表
例:
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[8]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
c = b.sort_values(2,ascending=False)
c
Out[10]:
0 1 2 3 4
b 15 16 17 18 19
d 10 11 12 13 14
a 5 6 7 8 9
c 0 1 2 3 4
c = c.sort_values('a',axis=1,ascending=False)
c
Out[12]:
4 3 2 1 0
b 19 18 17 16 15
d 14 13 12 11 10
a 9 8 7 6 5
c 4 3 2 1 0
数据的基本统计分析
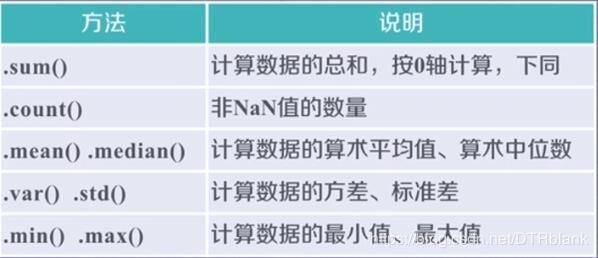
基本的统计分析函数
- 适用于Series和DataFrame类型
- 适用于Series类型

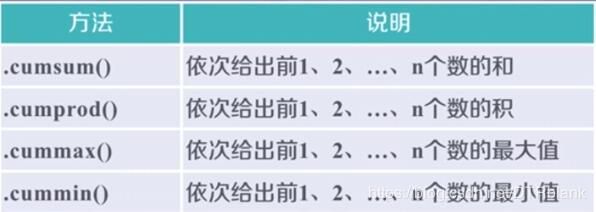
数据的累计统计分析
- 适用于Series和DataFrame类型
例:
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[14]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
b.cumsum()
Out[15]:
0 1 2 3 4
c 0 1 2 3 4
a 5 7 9 11 13
d 15 18 21 24 27
b 30 34 38 42 46
b.cumprod()
Out[16]:
0 1 2 3 4
c 0 1 2 3 4
a 0 6 14 24 36
d 0 66 168 312 504
b 0 1056 2856 5616 9576
b.cummin()
Out[17]:
0 1 2 3 4
c 0 1 2 3 4
a 0 1 2 3 4
d 0 1 2 3 4
b 0 1 2 3 4
b.cummax()
Out[18]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
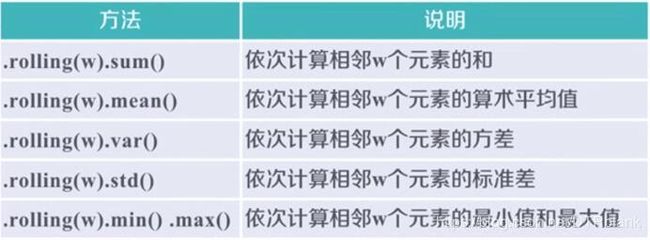
- 适用于Series和DataFrame类型,滚动计算(窗口计算)
转换字符串时间为标准时间
pandas时间相关的类
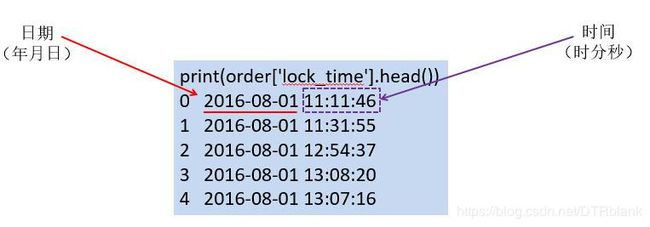
- 在多数情况下,对时间类型数据进行分析的前提就是将原本为字符串的时间转换为标准时间类型。pandas继承了NumPy库和datetime库的时间相关模块:

Timestamp类型
- Timestamp作为时间类中最基础的,也是最为常用的。在多数情况下,时间相关的字符串都会转换成为Timestamp。
- Timestamp表示时刻的时间类型数据
Timestamp类常用属性
- 在多数涉及时间相关的数据处理,统计分析的过程中,需要提取时间中的年份,月份等数据。使用对应的Timestamp类属性就能够实现这一目的。
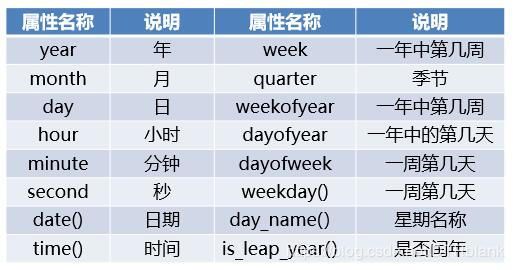
例:
order = pd.read_csv('meal_order_info.csv',encoding = 'gbk')
order['use_start_time'] = pd.to_datetime(order['use_start_time'])
ts=order['use_start_time'][0]
(year,month,day)=(ts.year,ts.month,ts.day)
(hour,minute,second)=(ts.hour,ts.minute,ts.second)
date=ts.date()
time=ts.time()
week=ts.week
weekday=ts.day_name()
Timedelta类
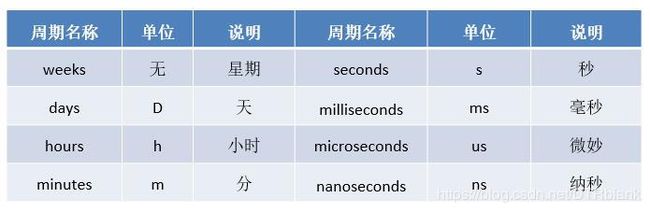
- Timedelta是时间相关的类中的一个异类,不仅能够使用正数,还能够使用负数表示单位时间,例如1秒,2分钟,3小时等。使用Timedelta类,配合常规的时间相关类能够轻松实现时间的算术运算。目前Timedelta函数中时间周期中没有年和月。所有周期名称,对应单位及其说明如下表所示:
使用groupby方法拆分数据
groupby方法的参数及其说明
- 该方法提供的是分组聚合步骤中的拆分功能,能根据索引或字段对数据进行分组
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False,
**kwargs)

例:
import pandas as pd
import numpy as np
detail = pd.read_excel('meal_order_detail.xlsx')
detailGroup = detail[['order_id','counts','amounts']].groupby(by = 'order_id')
print('分组后的订单详情表为:',detailGroup)
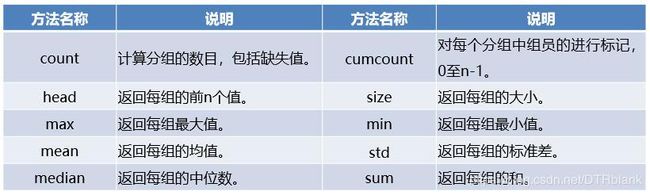
GroupBy对象常用的描述性统计方法
- 用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。实际上分组后的数据对象GroupBy类似Series与DataFrame,是pandas提供的一种对象。GroupBy对象常用的描述性统计方法如下。
例:
import pandas as pd
import numpy as np
detail = pd.read_excel('meal_order_detail.xlsx')
detailGroup = detail[['order_id','counts','amounts']].groupby(by = 'order_id')
print('分组后的订单详情表为:',detailGroup)
print('订单详情表分组后前5组每组的均值为:\n', detailGroup.mean().head())
print('订单详情表分组后前5组每组的标准差为:\n', detailGroup.std().head())
print('订单详情表分组后前5组每组的大小为:','\n', detailGroup.size().head())