JAVA实现用户协同算法计算用户喜爱相似度
原创文章,转载请注明出处https://blog.csdn.net/FRYAN28/article/details/90474141
基于用户的协同过滤算法是指通过分析用户对商品的行为,计算出兴趣相似的用户,并向被推荐用户推荐其兴趣相同的用户感兴趣的商品。
土话说大概就是,我跟你看的东西,基本上一样,那就可以判定我们有相似的喜好,那么我浏览的其他的东西,就可以推荐给你
我记录用户的浏览行为,并将用户对于每个商品的浏览行为的评分赋值为1.0。浏览1次为1分,多次浏览分值能够累加,通过皮尔逊公式计算用户喜爱相似度
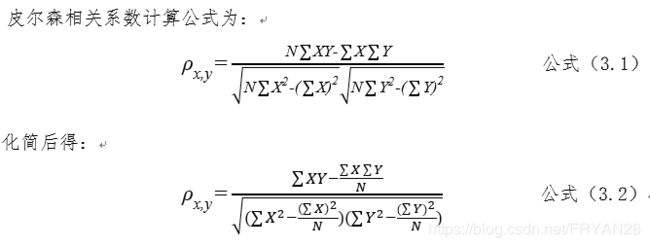
这里贴上核心方法源码
/**
* @Author Swallow
* @Date 2019/4/21
**/
public List CFUserUtil(String Id){
//存放所有用户数据
Map> allUsers = new HashMap>();
//查询所有的数据
List users = userDao.queryAllUser();
List goodsInfos = myGoodsDao.queryAll();
//遍历每个用户,定义值
for (User user : users) {
/**
* 通过sql语句查询获取用户浏览记录,以及对应的浏览次数
*/
List goodsValues = browseDao.queryGoodsValue(user.getPhoneId());
logger.info("goodsValues"+goodsValues.toString());
if (goodsValues.size()>0){//有浏览记录的用户进行相似度计算
Map u = new HashMap();//存放商品ID 评分值
for (GoodsInfo goodsInfo:goodsInfos) {
String GId = String.valueOf(goodsInfo.getId());//商品列表中的商品ID
for (GoodsValue value:goodsValues){
String browseGId = String.valueOf(value.getGoodsId());//浏览记录中的商品ID
if (browseGId.equals(GId)){
u.put(String.valueOf(GId), Double.valueOf(value.getValue()));
break;
}else {
u.put(String.valueOf(GId),0.0);
}
}
}
allUsers.put(user.getPhoneId(),u);
logger.info("userID:"+user.getPhoneId()+",:"+u.toString());
}
}
Map simUserSimMap = new HashMap();//存放相似度集合
Map per=allUsers.get(Id);//获取当前用户
//遍历每个用户
for (Map.Entry> userPerfEn : allUsers.entrySet()){
String perId = userPerfEn.getKey();
if(!Id.equals(perId)){//遍历到的用户非当前用户
double sim = getUserSimilar(per, userPerfEn.getValue());
logger.info(Id+"与"+perId+"的相似度为:"+String.valueOf(sim));
simUserSimMap.put(perId,sim);
}
}
//获取相似度最高的用户,对simUserSimMap中的数据进行排序
List> wordMap = new ArrayList<>(simUserSimMap.entrySet());
Collections.sort(wordMap, new Comparator>() {// 根据value排序
public int compare(Map.Entry o1, Map.Entry o2) {
double result = o2.getValue() - o1.getValue();
if (result > 0)
return 1;
else if (result == 0)
return 0;
else
return -1;
}
});
/*ArrayList hashMaps = new ArrayList<>();
for (HashMap h : hashMaps) {
Integer integer = (Integer) h.get("");
}*/
for(Map.Entry set:wordMap){
logger.info("map:"+set.getKey() +" "+set.getValue());
}
String maxID = wordMap.get(0).getKey();
logger.info("maxID"+maxID);
List browses = browseDao.queryBrowseByUser(maxID);
List goodsInfoList = new ArrayList<>();
//根据每条浏览记录的商品ID查询商品信息
//获取推荐商品的集合
for (Browse browse:browses){
Integer goodsId = browse.getGoodsid();
logger.info("browse,goodsId"+String.valueOf(goodsId));
List goodList = myGoodsDao.querybyId(goodsId);
GoodsInfo goods = goodList.get(0);
logger.info(String.valueOf(goods.getId()));
goodsInfoList.add(goods);
}
return goodsInfoList;
}
//皮尔森公式 计算用户相似度
private double getUserSimilar(Map pm1, Map pm2) {
int n = pm1.size();// 数量n
Double sxy = 0.0;// Σxy=x1*y1+x2*y2+....xn*yn
Double sx = 0.0;// Σx=x1+x2+....xn
Double sy = 0.0;// Σy=y1+y2+...yn
Double sx2 = 0.0;// Σx2=(x1)2+(x2)2+....(xn)2
Double sy2 = 0.0;// Σy2=(y1)2+(y2)2+....(yn)2
for (Map.Entry pme : pm1.entrySet()) {
String key = pme.getKey();
logger.info("key:"+key);
Double x = pme.getValue();
Double y = pm2.get(key);
logger.info("x:"+String.valueOf(x)+",y:"+String.valueOf(y));
if (x != null && y != null) {
sxy += x * y;//x*y求和
sx += x;//x求和
sy += y;//y求和
sx2 += Math.pow(x, 2.0);//x的平方求和
sy2 += Math.pow(y, 2.0);//y的平方求和
logger.info(":sxy:"+sxy+",sx:"+sx+",sy"+",sx2:"+sx2+",sy2:"+sy2);
}
}
double sd = sxy - (sx * sy) / n;
double sm = Math.sqrt((sx2 - (Math.pow(sx, 2) / n)) * (sy2 - (Math.pow(sy, 2) / n)));
logger.info("sd:"+sd+",sm:"+sm);
return Math.abs(sm == 0 ? 1 : sd / sm);
}
获取浏览记录的时候我用sql语句做了一个处理,通过count函数和group by直接得出浏览某一商品的次数,这样在使用算法时可以直接赋予分值

对应的java查询方法源码
public List queryGoodsValue(String userid){
List goodsValues = new ArrayList<>();
String sql = "select userid,goodsid,count(goodsid) as value from browse where userId=? group by goodsid";
RowMapper rowMapper=new BeanPropertyRowMapper(GoodsValue.class);
goodsValues = jdbcTemplate.query(sql,rowMapper,userid);
return goodsValues;
}
/**
* @Author Swallow
* @Date 2019/5/21
**/
public class GoodsValue {
private String userId;
private String goodsId;
private Integer value;
public GoodsValue() {
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getGoodsId() {
return goodsId;
}
public void setGoodsId(String goodsId) {
this.goodsId = goodsId;
}
public Integer getValue() {
return value;
}
public void setValue(Integer value) {
this.value = value;
}
@Override
public String toString() {
return "GoodsValue{" +
"userId='" + userId + '\'' +
", goodsId='" + goodsId + '\'' +
", value=" + value +
'}';
}
}
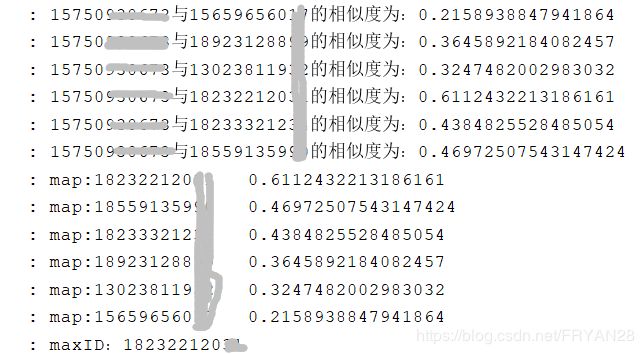
然后可以看一下运行结果,前面一段是计算的时候输出的相似度,中间是排序过程,最后输出最相似用户是哪个
总结:这部分代码参考别人的,目前写得还比较简单,用来做推荐的,还有一些不足部分
比如说用户协同过滤,过滤部分就还没实现
再比如说,我只有浏览行为的评分,没有其他购买、收藏也赋予行为分值
emmmm后续再继续研究吧
不过最近发现了一个框架有更专业的协同过滤算法的接口,里面还有其他各种相关接口,可以去试试他的接口:Mahout框架
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。(引用自百度百科)
其他参考资料:
https://www.jb51.net/article/129181.htm
https://blog.csdn.net/xj6591073/article/details/79049469