局部敏感哈希(Locality sensitive hash) —— 代码篇
我们在之前的文章中Locality Sensitive Hashing(局部敏感哈希)中已经详细的说了这个算法的基本核心思想,现在我们就来一点一点的把这个算法的每一步都来实现了。
首先我们至少得构建出我们能够比较的样本的特征值,设计出我们的布尔矩阵(Boolean Matrix)。局部敏感哈希的一个优点就是避免两两比较(pairwise comparison),主要的方法就是看最后的band 被映射 同一个bucket的话我们就一般认为这两个特征值其实是相似的,或者说在某个概率下是相同的。
首先我们先构建一个数据集,比如说把它叫做dataSet,这个里面有一些特征向量,我们就用之前我们说的下图这个例子来写我们的代码吧。
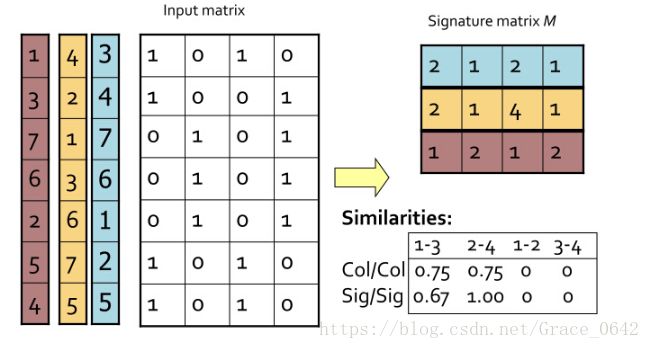
我们可以设计我们的dataSet 为一个二维的数组,设计我们需要查询的(或者说找到我们的这个待查询的这个数组为它找到和它相似的数据集)数组为一维数组。我们可以给这个查询的数据叫做query. 我们把这个查询的数组设置为一维数组。
我们可以这么来构建我们的数据结构:
dataSet = [[1,1,0,0,0,1,1],[0,0,1,1,1,0,0],[1,0,0,0,0,1,1]]
query = [0,1,1,1,1,0,0]
dataSet.append(query)
#把这个查询的数组加入到我们的整个数据集当中,并且将它转换成矩阵的形式
matrix = np.array(dataSet).T
如果要写成代码,我们可以像下面这样操作。把我们的这些要操作的数据集设置为我们的输入参数来做:
def get_data(dataSet,query):
dataSet.append(query)
matrix = np.array(dataSet).T得到我们的数据之后,当然就是生成我们的signature matrix ,这个时候当然就是用到我们的minhash 这个函数,对我们的原始矩阵进行一个行的置换,这个时候找到某列的第一个元素为1 的行号作为我们的signature matrix 的特征值。
我们肯定不会直接把这个矩阵放到内存里面排序进行行置换的操作,这样实在是太占内存了,我们介绍过几种方法,对我们的行号进行置换。依次查询即可。
如果我们按照我们之前章节里面的算法的思路就是对行号进行排序,或者说是置换,这个时候我们来查找置换后的行得到的列中第一次出现1的那个行的行号。
#!/usr/bin/env python
# coding=utf-8
from random import shuffle
import numpy as np
import hashlib
def generateSig(matrix):
"""
generate the signature value for the signature matrix
param matrix: input matrix
"""
# 在这里我们得到原始矩阵的行号
rowSeries= [i for i in range(matrix.shape[0])]
#在这里我们设置我们的signature签名矩阵的初始值
result = [-1 for i in range(matrix.shape[1])]
colcount = 0
# 对行号重新排序
shuffle(rowSeries)
for i in range(len(rowSeries)):
rowIndex = rowSeries.index(i)
for j in range(matrix.shape[1]):
if result[j]==-1 and matrix[rowIndex][j]!=0:
result[j]=rowIndex
colcount += 1
if colcount == matrix.shape[1]:
break
return result
def genSigMatrix(matrix,k):
'''
generate the signature matrix
:param matrix : the input matrix
:param k : k =n*r n is the number of band
r is the number of row in each band
'''
sigMatrix = []
for i in range(k):
sig = generateSig(matrix)
sigMatrix.append(sig)
return np.array(sigMatrix)
当然我们还有其他的解决办法,比如我们随机选取一行,而不用对我们的整个行进行重拍我们可以向下面这样做。
这个算法的主要思想就是利用随机行数,抽取一行,然后逐列查询,如果改行的这一列元素刚好是1,那么我们就把对应的签名矩阵的列填上我们抽取的行号,不是1的元素的列继续对行遍历,当然我们会删除之前抽取的行号
import numpy as np
import random
import hashlib
def sigGen(matrix):
"""
* generate the signature vector
:param matrix: a ndarray var
:return a signature vector: a list var
"""
# the row sequence set
seqSet = [i for i in range(matrix.shape[0])]
# initialize the sig vector as [-1, -1, ..., -1]
result = [-1 for i in range(matrix.shape[1])]
count = 0
while len(seqSet) > 0:
# choose a row of matrix randomly
randomSeq = random.choice(seqSet)
for i in range(matrix.shape[1]):
if matrix[randomSeq][i] != 0 and result[i] == -1:
result[i] = randomSeq
count += 1
if count == matrix.shape[1]:
break
seqSet.remove(randomSeq)
# return a list
return result此处代码可以参考这里:
https://github.com/guoziqingbupt/Locality-sensitive-hashing/edit/master/min_hash.py
通过这一步之后我们得到了我们的signature matrix ,这个时候我们要计算这些signature 是不是能够被映射到同一个bucket 里面。
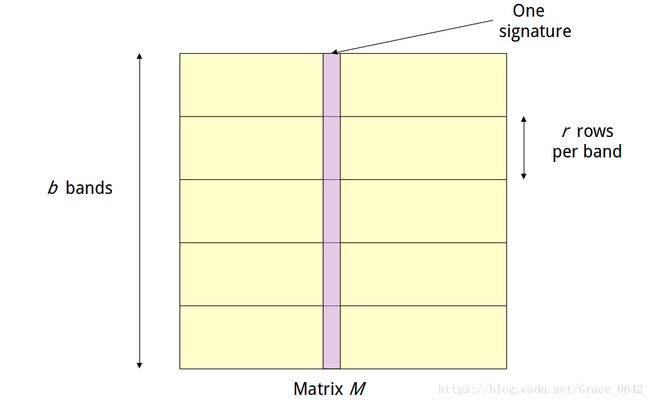
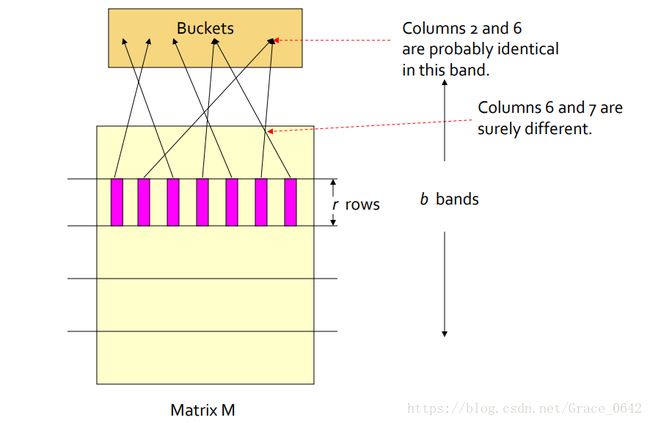
我们需要把我们的matrix 划分成不同的bands , 每一个band 里面包含有r 行。然后映射到不同的buckets 里面,经过我们的分析,我们知道如果两个签名是相似的,那么他们会被映射到同一个buckets 里面。这个时候我们LSH避免了两两比较,这个时候LSH极大的提高了运算的效率。
def minHash(input_matrix, b, r):
"""
map the sim vector into same hash bucket
:param input_matrix:
:param b: the number of bands
:param r: the row number of a band
:return the hash bucket: a dictionary, key is hash value, value is column number
"""
hashBuckets = {}
# permute the matrix for n times
n = b * r
# generate the sig matrix
sigMatrix = sigMatrixGen(input_matrix, n)
# begin and end of band row
begin, end = 0, r
# count the number of band level
count = 0
while end <= sigMatrix.shape[0]:
count += 1
# traverse the column of sig matrix
for colNum in range(sigMatrix.shape[1]):
# generate the hash object, we used md5
hashObj = hashlib.md5()
# calculate the hash value
band = str(sigMatrix[begin: begin + r, colNum]) + str(count)
hashObj.update(band.encode())
# use hash value as bucket tag
tag = hashObj.hexdigest()
# update the dictionary
if tag not in hashBuckets:
hashBuckets[tag] = [colNum]
elif colNum not in hashBuckets[tag]:
hashBuckets[tag].append(colNum)
begin += r
end += r
# return a dictionary
return hashBuckets这里我们有一个技巧,我们可以把我们的桶设置为一般的hash 函数,比如说md5,sha256 等等。
这个时候我们记录列号,我们把hash 值作为我们字典的键,把列号作为值来计算。
一个字典里面如果,一个键对应的元素是大于两个的,我们则认为找到了相似的样本。
感觉CSDN在写到一定的长度就会卡的不行,不知
