Hive中分组取前几名及行列转换的方法
row_number()、rank()和dense_rank()这三个是hive内置的分析函数,这三个函数可以用于分组取前几名,下面我们来看看他们的区别和具体的使用案例。
首先创建一个文件test:
A,1
B,3
C,2
D,3
E,4
F,5
G,6
然后创建hive表:
create table test_rank(a string,b int) row format delimited fields terminated by ',' stored as textfile;
load数据到表中
load data local inpath '/usr/java/test' overwrite into table test_rank;
执行下面的语句
select a,row_number() over(order by b) row_number,rank() over(order by b) rank,
dense_rank() over(order by b) dense_rank from lijie.test_rank;
结果为:
a row_number rank dense_rank
A 1 1 1
C 2 2 2
D 3 3 3
B 4 3 3
E 5 5 4
F 6 6 5
G 7 7 6
由此可见:
row_number:不管排名是否有相同的,都按照顺序1,2,3…..n
rank:排名相同的名次一样,同一排名有几个,后面排名就会跳过几次
dense_rank:排名相同的名次一样,且后面名次不跳跃
实际使用:
现在有一个需求: 需要加工一张表M 其中要求要A表,B表,C表的数据加工,A和B表连接字段都是唯一值,但是和C表连接的字段不唯一,如果A join B,然后再Join C 这样加工出来的表数据会不准确,这里需求是需要最新的C表中关联字段的数据。
可以按照如下方法解决(c2是C表的关联字段,通过update_time的降序取最新的那条数据):
select
A.xxx,
B.xxx,
C.xxx,
....
from
A
left outer join B
on A.c1 = B.c1
left outer join
(
select
cc.*,row_number() over(distribute by cc.c2 sort by cc.update_time desc) as rownum
from
C cc
) C on A.c2 = C.c2 and C.rownum = 1;
-- ------------------- 加油网点偏好-----------------------------
-- 高频加油网点 近6个月在所有加油站加油频次最高的网点
insert overwrite table oil_label1
SELECT CardNo,
collect_list(NodeNo)[0],
collect_list(NodeTag)[0],
collect_list(gasTimes)[0]
FROM (SELECT CardNo, NodeNo, NodeTag, COUNT(CardNo) AS gasTimes
FROM bjsy_gasdetails_6month
GROUP BY CardNo,NodeNo,NodeTag
ORDER BY CardNo,gasTimes DESC,nodeno ASC) a
GROUP BY CardNo;
-- insert overwrite table oil_label1
-- select b.CardNo, b.NodeNo as HighFreqNodeNo, b.NodeTag as HighFreqNode, b.gasTimes
-- from
-- (select * , row_number() OVER (PARTITION BY CardNo ORDER BY gasTimes desc, NodeNo asc) as rank from
-- (select CardNo, NodeNo, NodeTag, COUNT(CardNo) as gasTimes
-- from bjsy_gasdetails_6month
-- group by CardNo, NodeNo, NodeTag
-- order by CardNo, gasTimes DESC
-- ) as a
-- ) as b
-- where rank = 1
-- ORDER BY b.gasTimes DESC
-- ;
hive sql 行转列 collect_set,collect_list 有序化展示
1、collect_set去除重复元素;collect_list不去除重复元素;需要进行group by
select phone,collect_list(user_id) ,collect_set(user_id)
from a
group by phone
123456789 [1,3,2,1,2] [1,3,2]
2、collect_list 展示子表排序后结果,collect_set 不受子表排序影响
select phone,collect_list(user_id) ,collect_set(user_id)
(select * from a order by order_time asc)b
group by phone
结果:123456789 [1,1,3,2,2] [1,3,2]
a表数据如下
phone user_id order_time
123456789 1 2018/8/23
123456789 3 2018/8/24
123456789 2 2018/8/25
123456789 1 2018/8/22
123456789 2 2018/8/26
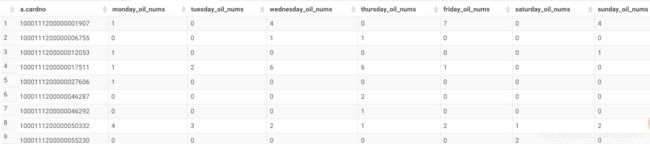
hive sql 行转列 使用case when 结合sum()、count()、max()等函数
将周一到周日加油的情况,由行转换成列,大多数在做用户标签的时候,经常会需要用到这种方法。
select a.cardno,
sum(case a.week_oil when '周一加油' then 1 else 0 end) as Monday_oil_nums,
sum(case a.week_oil when '周二加油' then 1 else 0 end) as Tuesday_oil_nums,
sum(case a.week_oil when '周三加油' then 1 else 0 end) as Wednesday_oil_nums,
sum(case a.week_oil when '周四加油' then 1 else 0 end) as Thursday_oil_nums,
sum(case a.week_oil when '周五加油' then 1 else 0 end) as Friday_oil_nums,
sum(case a.week_oil when '周六加油' then 1 else 0 end) as Saturday_oil_nums,
sum(case a.week_oil when '周日加油' then 1 else 0 end) as Sunday_oil_nums
from
(select cardno,
case pmod(datediff(to_date(opetime),'2017-12-31'),7)
when 1 then '周一加油'
when 2 then '周二加油'
when 3 then '周三加油'
when 4 then '周四加油'
when 5 then '周五加油'
when 6 then '周六加油'
else '周日加油' end as week_oil
from tjsy_gasdetails_6month) as a
group by a.cardno
;