用 Seaborn 做数据可视化(1)——绘图功能(1)可视化统计关系:sns.relplot()
目录
- 0. 介绍
- 0.1 概论
- 0.2 可视化统计关系 relplot( )
- 2.1 两个方法
- scatterplot()
- lineplot()
- 2.2 几个参数
- kind
- ci
- hue
- style
- size
- row、 col
- 1. relplot(kind='scatter' ) 散点图
- 二维散点图
- 三维散点图—— hue/style/size
- 四维散点图—— hue + style
- 2. relplot(kind='line' )线图
- 2.1 聚合和表示不确定性——参数ci
- 2.2 绘制语义映射数据子集——参数 hue, size, and style
- 2.3 绘制时间序列
- 3. 分面图(facets):展示多变量关系
- 小结
- 参数 hue、style、size
- 参数 row、col
0. 介绍
0.1 概论
统计分析是理解数据集中的变量如何互相关联以及这些关系如依赖其他变量的一个过程。而可视化则是这个过程的一个核心部分,因为只有数据被正确的可视化,人们才能看到主导关系的趋势和模式。
0.2 可视化统计关系 relplot( )
relplot( ),(即:relational plots )是绘制统计关系最常见的函数。
seaborn.relplot(x=None, y=None,
hue=None, size=None, style=None,
data=None,
row=None, col=None,
col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend='brief',
kind='scatter',
height=5, aspect=1, facet_kws=None, **kwargs)
relplot() 主要使用以下两种方法:
2.1 两个方法
scatterplot()
(with kind=“scatter”; the default)
即 relplot( )默认是绘制散点图
lineplot()
(with kind=“line”)
2.2 几个参数
说明:
- 可以通过输入 hue 、style、size 三个参数来增加变量;或者改变相应颜色、样式、大小(若输入相同的变量)
- 通过 row、col 两个参数可以按照行和列展开多个子图;
kind
- kind=“scatter”(默认):绘制散点图 scatterplot()
- kind=“line” :绘制线图 lineplot()
ci
ci:通过设置参数 ci (confidence interval) 来控制阴影部分。
- 默认使用 ci;
- ci=None 取消;
- ci=“sd” 使用标准偏差而不是置信区间
hue
hue:在某一维度上, 用颜色区分(增加变量/维度/特征数量)
style
style:在某一维度上, 线的表现形式不同, 如 点线, 虚线等(增加变量/维度/特征数量)
size
size:控制数据点大小或者线条粗细(增加变量/维度/特征数量)
row、 col
显示分面图
1. relplot(kind=‘scatter’ ) 散点图
散点图(scatter plot):相关关系(两个变量)
散点图是统计可视化的中流砥柱。它使用点云来描述两个变量的联合分布。散点图的描述可以让我们直接看到大量的信息,帮我们判断出它们之间是否存在有意义的关系。
在 Seaborn 中有许多方法可以绘制散点图,但是最基本的是使用 scatterplot()。记住,当两个变量是数值型的时候,只能使用这种方式。
scatterplot() 是 relplot( ) 的默认种类,当然也可以手动设置 kind=“scatter”。
代码示例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
数据导入
tips = sns.load_dataset('tips')
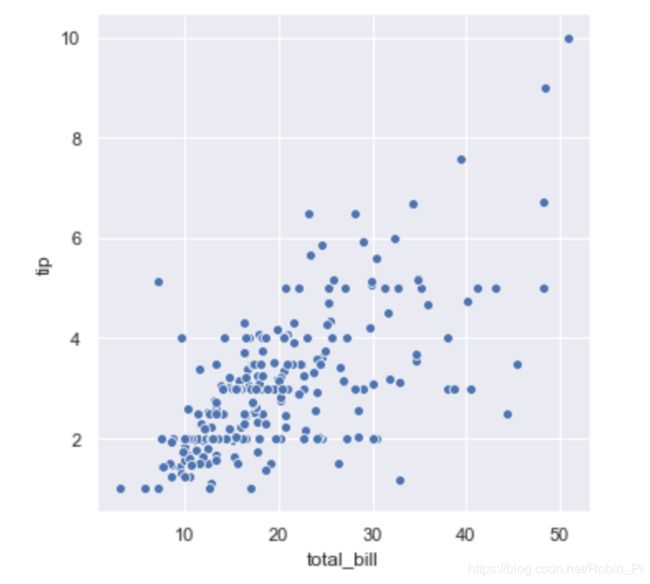
二维散点图
# 绘制二维散点图(两个变量)
sns.relplot(x='total_bill', y='tip', data=tips) # 发现其自带坐标轴名称
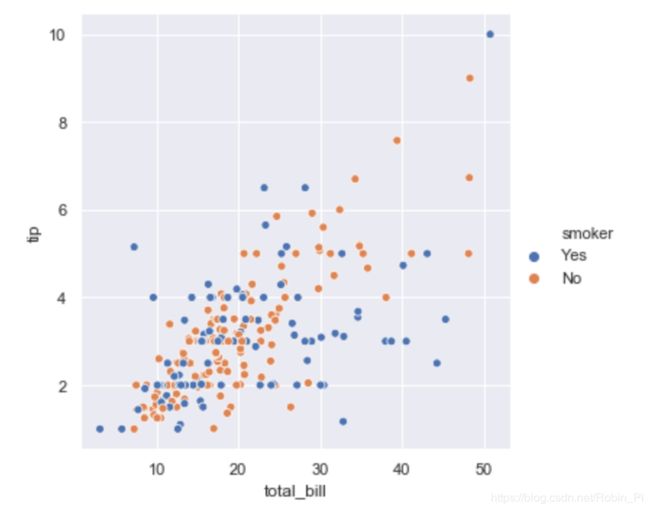
三维散点图—— hue/style/size
可以通过不同的参数传入不同的变量,从而增加了维度。
# 绘制三维散点图(使用参数 hue 增加了一个变量,用不同颜色进行区分。联想到用气泡图表示三维数据)
sns.relplot(x='total_bill', y='tip', hue='smoker', data=tips)
变量也可以是连续值
# 其中一变量是连续值的情况
sns.relplot(x="total_bill", y="tip", hue="size", data=tips);

通过不同的参数(style、zize),输入相同的变量,则可以在该变量的维度上进行相应的线条(样式、大小)改变
# 改变变量’smoker‘的样式
sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker",
data=tips);

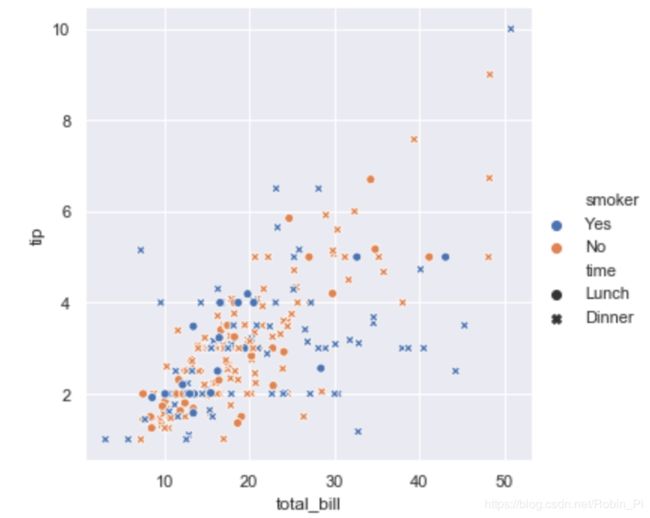
四维散点图—— hue + style
# 四变量/四维散点图
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips);
2. relplot(kind=‘line’ )线图
线图(line plot):展示连续性(单变量)
散点图非常有用,但却无法做单变量分析。
一个有效的方法是使用线图。
在 Seaborn 中可以使用 lineplot( )函数,或者直接使用 relplot( ),并设置 kind=‘line’
2.1 聚合和表示不确定性——参数ci
聚合和表示不确定性——设置参数 ci (confidence interval)
设置参数 ci (confidence interval) 来控制阴影部分
注:阴影部分是由于纵坐标上多个值导致的, 取值为均值, 阴影部分是置信区间.
# 默认使用的是围绕平均值的95%置信区间
fmri = sns.load_dataset('fmri')
sns.relplot(x='timepoint', y='signal', kind='line', data=fmri)
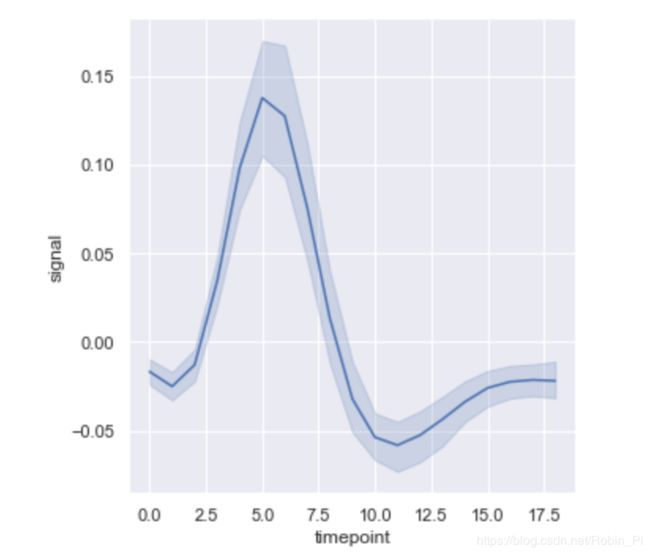
# 置信区间是使用自举,也可以将其禁用
sns.relplot(x="timepoint", y="signal", ci=None, kind="line", data=fmri);
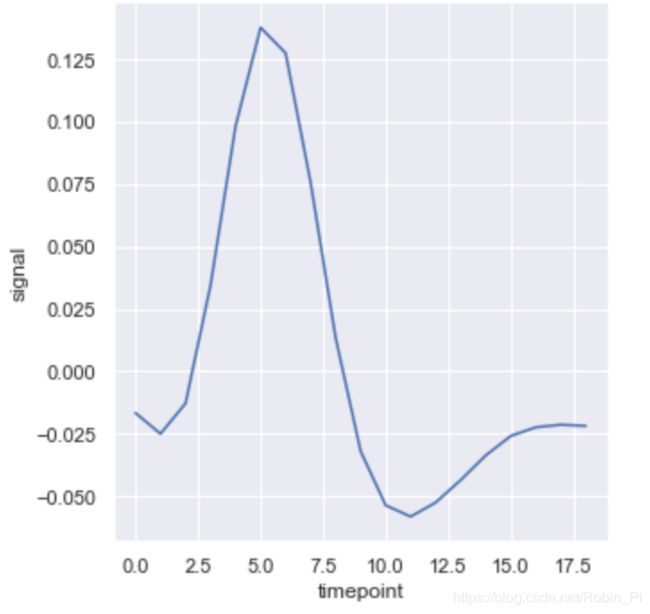
# 使用标准偏差而不是置信区间
sns.relplot(x="timepoint", y="signal", kind="line", ci="sd", data=fmri);
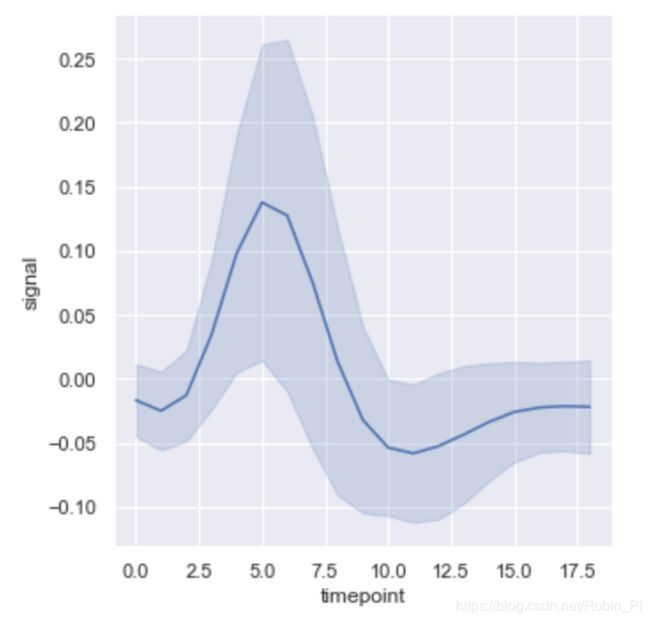
2.2 绘制语义映射数据子集——参数 hue, size, and style
绘制语义映射数据子集——其它三个参数 hue, size, and style
sns.relplot(x="timepoint", y="signal", hue="event", kind="line", data=fmri);

sns.relplot(x="timepoint", y="signal", hue="region", style="event",
kind="line", data=fmri);
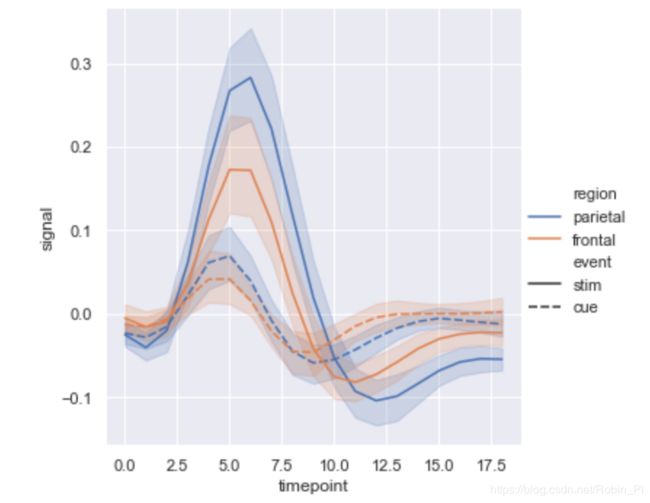
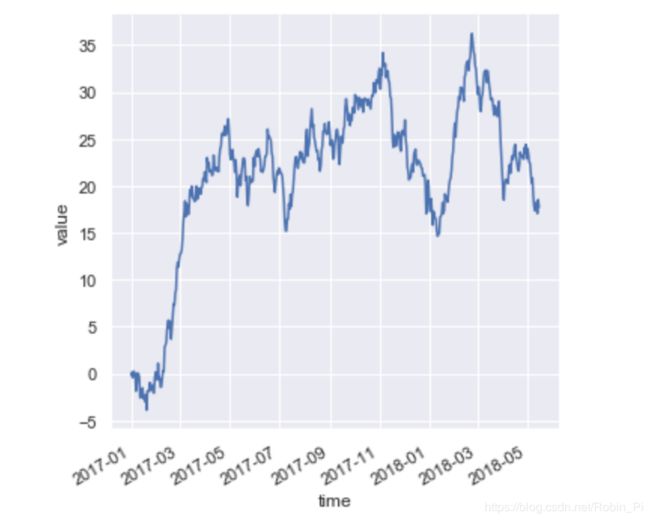
2.3 绘制时间序列
线图通常用于显示与实际日期和时间相关的数据。
df = pd.DataFrame(dict(time=pd.date_range("2017-1-1", periods=500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
# relplot() 默认 y 是 x 的函数
3. 分面图(facets):展示多变量关系
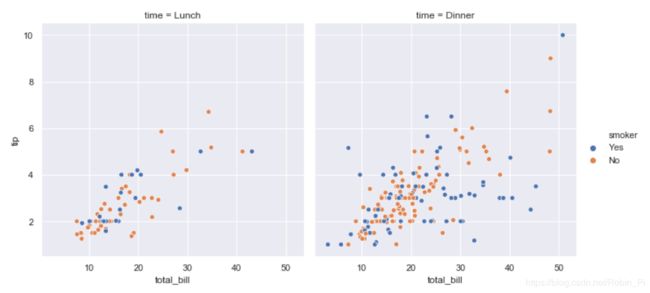
有时候我们并不想将其它的变量也放入到同一张图中,这时我们就使用分面图去进行可视化。
这表示,我们将针对这个变量,建立多个坐标系和多张子图。(数量与变量的种类数有关)
- 使用 col
- 使用 row
tips.time
0 Dinner
1 Dinner
2 Dinner
3 Dinner
4 Dinner
...
239 Dinner
240 Dinner
241 Dinner
242 Dinner
243 Dinner
Name: time, Length: 244, dtype: category
Categories (2, object): [Lunch, Dinner]
这里 time 含有 [Lunch, Dinner] 两个种类
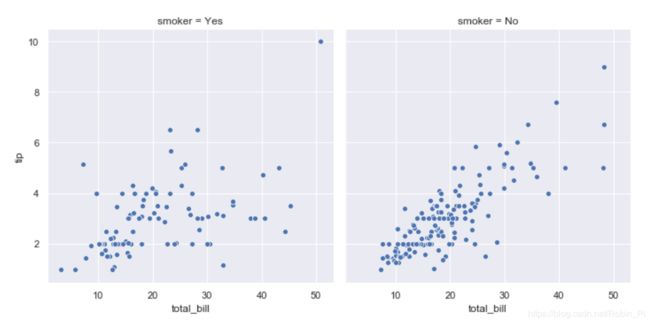
sns.relplot(x="total_bill", y="tip", hue="smoker",
col="time", data=tips);
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
kind="line", estimator=None, data=fmri);
col=“region” :region 有几类,就有几列图(2种 parietal 和 frontal,2列图)
row=“event” :event 有几类,就有几行图

sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"));

小结
sns.relplot( )
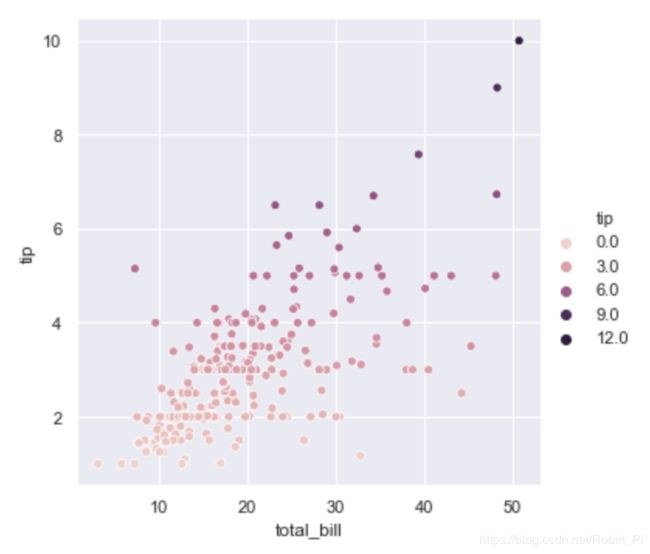
参数 hue、style、size
- 输入参数 x 和 y:分析x 和 y 两个变量的关系;
- 输入参数 x、y 再加上 hue、style、size 并和 x 或者 y 的变量对应,则可以改变相应的属性;
- 输入参数 x、y 再加上 hue、style、size 但传入的新的变量 z,则增加了维度,并附其相应的属性;
图示如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
tips = sns.load_dataset('tips')
①
sns.relplot(x='total_bill', y='tip',data=tips)
 ②
②
sns.relplot(x='total_bill', y='tip', hue='tip', data=tips)
# sns.relplot(x='total_bill', y='tip', hue='total_bill, data=tips) # 也可以传入 x的变量
 ③
③
sns.relplot(x='total_bill', y='tip', hue='smoker', data=tips)

参数 row、col
与上述通过不同属性的表现方式不同,这里通过参数 row 或者 col,使用多张子图的方式展现第三个变量与 x 和 y 的关系。
sns.relplot(x='total_bill', y='tip', col='smoker', data=tips)