总结四——使用pandas进行数据清洗,规整、聚合与分组
前面的总结三介绍了pandas入门的知识,本文将进一步总结pandas在数据分析中常见的操作。
一、数据清洗与准备
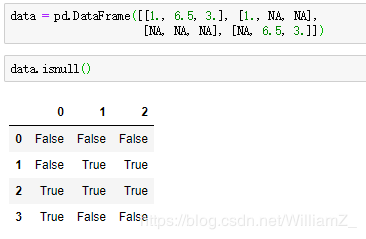
(1)缺失值的检测
isnull():
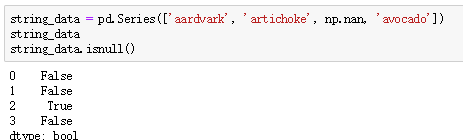
使用any函数直接检测是否存在缺失值,如any(df.isnull()),返回True or False。
notnull:不是缺失值检测,

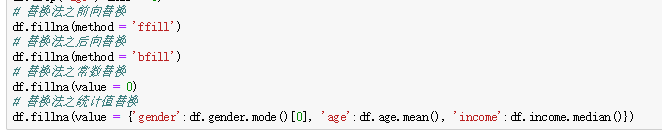
(2)处理缺失值
一般而言,遇到缺失值时,可采用的三种方法:删除法、替换法、插补法。
删除法: 当缺失的观测比例非常低(如5%以内),直接删除存在缺失值的观测,或者某些变量的缺失比例非常高时(如85%以上),直接删除这些变量。
替换法: 用某种常数直接替换那些缺失值,对于连续变量,可以使用均值或中位数替换,对于离散变量,可以使用众数替换。
插补法: 插补法是根据其他非缺失的变量或观测来预测缺失值,常见的插补法有回归插补法、K近邻插补法、拉格朗日插补法。
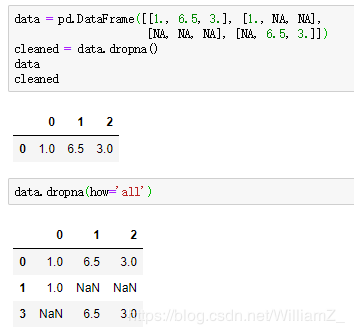
dropna:
subset参数指定需要删除的观测中哪列包含缺失值,若指定的列没有缺失值,没有指定的列存在缺失值的观测不会删除。
how参数为’all’时,删除所有值均为缺失值的行
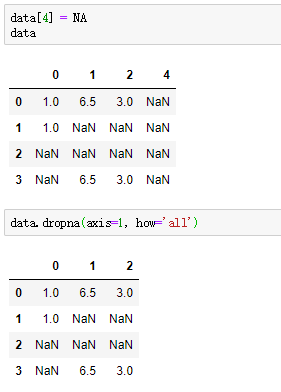
axis参数默认为0,删除缺失值行,设置为1则删除列
inplace参数默认为False,操作不反映到原数据集,设置为True才生效
例:

fillna:缺失值填充
inplace参数设置为True才对原数据集生效
limit参数用于前向后向填充时最大的填充范围
(3)重复观测的检测
duplicated:

![]()
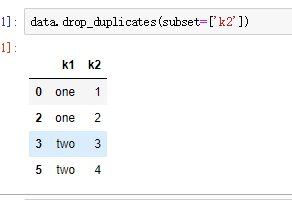
(4)重复观测删除
drop_duplicates()
subset参数指定需要删除的观测是关于哪列存在重复值的情况下,默认为全部列
keep参数指定保留第几条重复观测,默认保留第一条,keep='last’则保留最后一条
inplace参数默认为False,设置True才对数据集操作生效


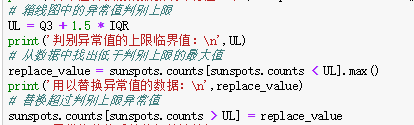
(5)异常值处理
异常值处理一般采用2种方法,一种是n个标准差法,另一种是箱线图判别法。
标准差判断公式为outlinear>|样本均值±n*样本标准差|,当n=2时,为异常值,n=3时为极端异常值。箱线图判断公式outliear>Q3+n*IQR或者outliear
两种方法选择的标准:如果数据近似正态分布,优先选标准差法,否则选箱线图法
存在异常时,一般使用删除法删除异常值(异常观测比例不大)
替换法:使用低于判别上限的最大值或高于判别下限的最小值替换、使用均值、中位数替换等。
例:

(6)使用函数或映射进行数据转换
利用Series的map方法接受一个函数或者包含映射关系的字典型对象,例:
传递字典:
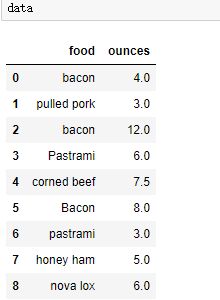
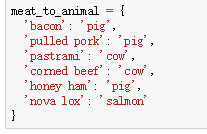
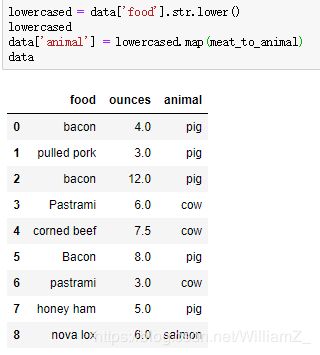
传递函数:

(7)分箱
pd.cut()返回一个categorical对象,此categorical对象的categories属性值默认右边封闭,可通过right=False设置为左边封闭右边开放。

可设置labels参数自定义箱名

当传递给cut函数正整数时,将根据数据的最小值最大值均匀计算出等长的箱,precision参数为精确到几位小数

(8)计算指标/虚拟变量
Pandas的get_dummies函数,多用于建模时非数值型数据处理。一列有n个不同的值,则生成n列,例:
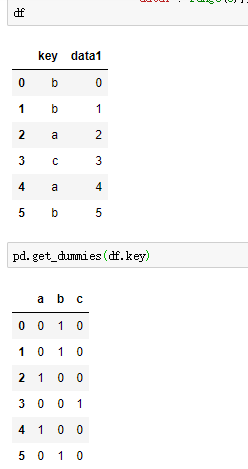
若某一列中每个值包含多个类别,则先创建一个空列表用以存储类别,遍历每个值,利用split方法分隔开每个类别,把分割后得到的列表extend到存储类别的列表,再求唯一值,新建一个o矩阵,行列数分别为处理列的长度和类别数,例:
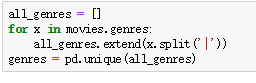
![]()

二、数据规整:
(1)多层索引:
以嵌套列表作为索引创建序列;

索引:
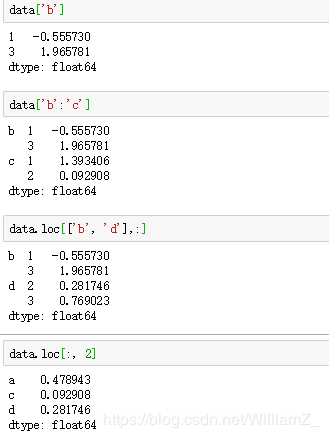
其中使用loc时,逗号左边是外层的索引,右边是内层的索引。
创建分层索引的数据框,每个轴都可以有分层索引:
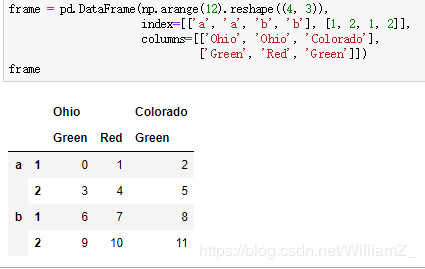
每个层级可以有名称:
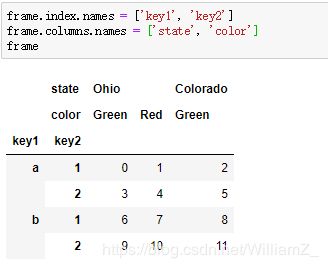
set_index:
指定哪些列作为索引,默认情况下这些列作为索引后,原数据框中这些列会移除,除非设置drop参数为False
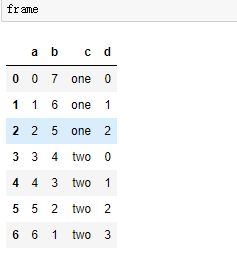
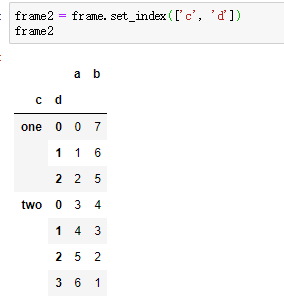

reset_index:
将索引转化为列

(2)多层索引重塑
1、层级交换
swaplevel
swaplevel接受两个层级序号或层级名称,返回一个层级变更的新对象

2、按多层索引的某一层排序

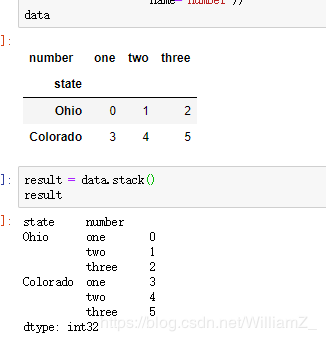
3、重塑
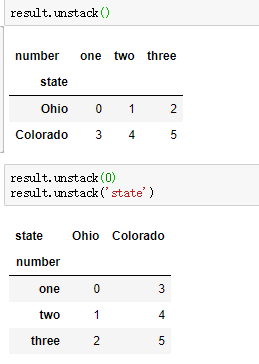
stack(堆叠)、unstack(拆堆):两者都是默认对最内层操作,若要对外层操作,则传入外层的层号或名称
(3)合并数据集
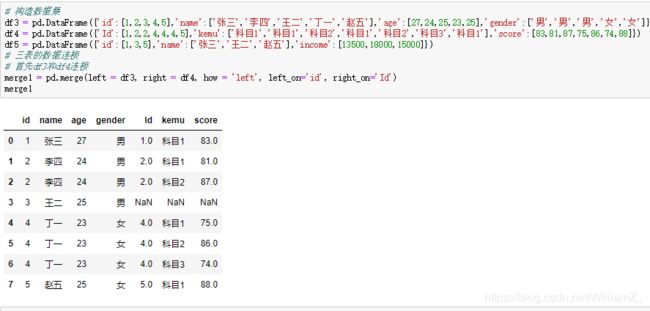
1、merge函数
部分merge函数参数:
| 参数 | 描述 |
|---|---|
| left | 指定合并操作左边的dataframe |
| right | …右边的dataframe |
| how | 指定连接方式,默认为’inner’两者观测的交集,‘left’保留左边数据框中右边数据框没有的观测、'right’保留右边数据框中左边没有的观测、'outer’两者观测并集 |
| on | 指定连接的共同字段,必须是两边都存在的列名 |
| left_on | 左边用于连接的列 |
| right_on | 右边用于连接的列 |
| left_index | 左边数据框的索引用于连接 |
| right_index | 右边数据框的索引用于连接 |
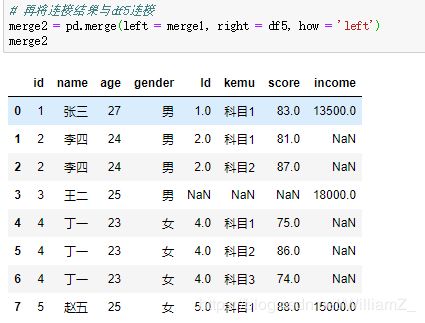
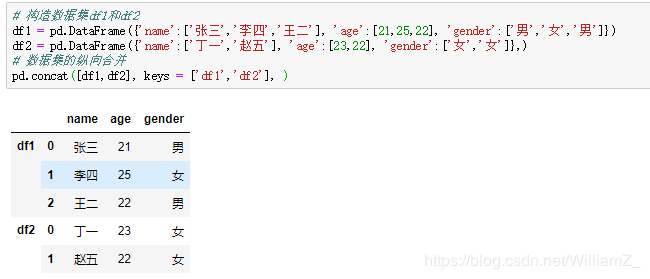
2、concat函数
concat函数部分参数
| 参数 | 描述 |
|---|---|
| objs | 指定合并的对象,可以是序列,数据框,或面板数据构成的列表 |
| axis | 默认为0,合并后增加行数,设置为1,合并多个数据的列,列数增加 |
| join | 指定合并方式,默认为outer,并集;inner则合并公共部分,交集。 |
| ignore_index | 默认为False,忽略原数据集的索引,True则为重新生成新索引 |
| keys | 为合并后的数据添加新索引,区分各个部分,将变成多层索引 |
| names | 传入keys后,该参数用于给出层级名称 |
例:

三、数据聚合与分组操作
拆分组——>应用数学、统计方法聚合;数值数据可以聚合,非数值数据将被过滤。
groupby:groupby方法进行分组,by参数接受用于分组的键,axis默认为0,将行分组,axis为1时将列分组
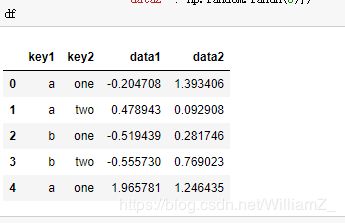
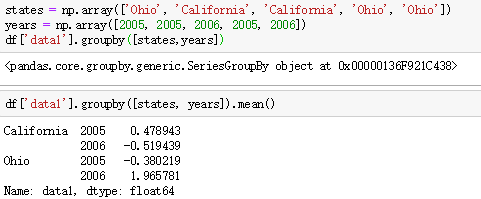
(1)确定分组键:
1、与需要分组的轴向长度一致的值列表或值数组
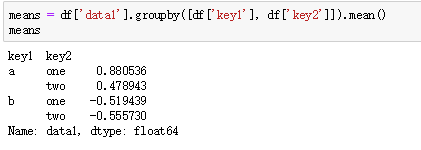
2、DataFrame某一列或多列的值
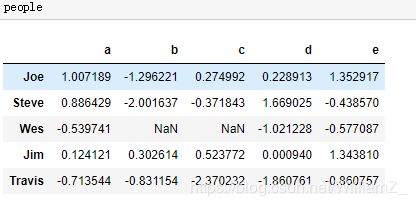
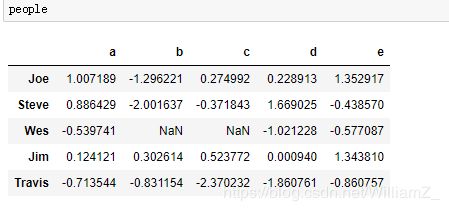
3、将分组轴向上的值和分组名称相匹配的字典或序列
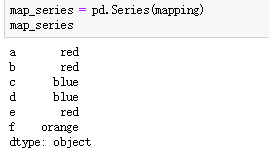
对于字典,键为数据集的行名/列名,值为属于所在分组的组名,对于序列,索引为数据集的行名/列名,值为属于所在分组的组名。
![]()
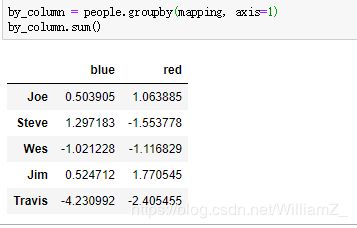
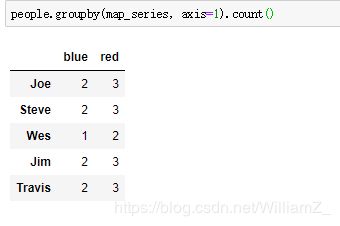
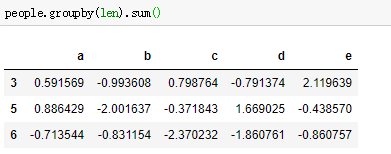
4、使用函数分组
函数将每个索引值调用一次,返回值被用作分组名称

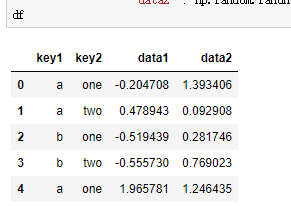
(2)遍历各个分组
groupby对象支持迭代,会生成包含组名和数据块的二维元组序列

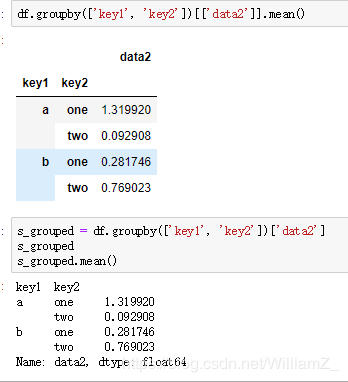
(3)选择一列或者所有列的子集
df.groupby(‘key1’)[‘data1’]等价于df[‘data1’].groupby(df[‘key1’]) #聚合后获得series形式的结果
df.groupby(‘key1’)[[‘data1’]]等价df[[‘data1’]].groupby(df[‘key1’]) #聚合后获得DataFrame形式的结果
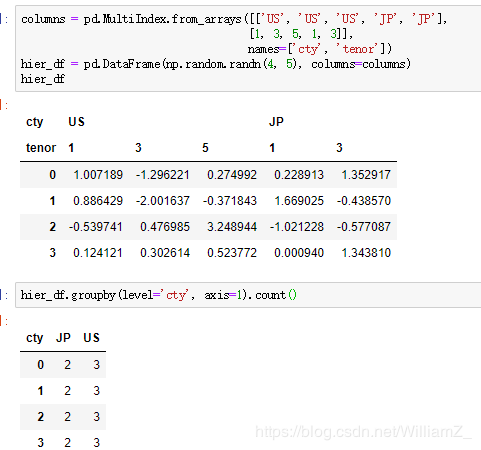
(4)根据索引层级分组
传递层级数值或层级名称给level关键字,并且设置相应axis参数值
(5)数据聚合
优化的groupby方法
count:分组中非NA值数量
sum:非NA值累和
mean:非NA值均值
median:非NA值的算术中位数
std,var : 标准差,方差
prod:累乘
first、last 非NA值第一个和最后一个值
使用agg方法时,可以以字符串形式直接传递上述描述性统计的方法名,如df.groupby(‘key1’).agg(‘mean’)
除了这些groupby对象的聚合方法,还可以自行制定聚合函数,但使用时需要将函数传递给aggregate或agg方法;类似quantile这些方法,虽然不是显式地为groupby对象实现的,但它是series的方法,也可以用于聚合,例:
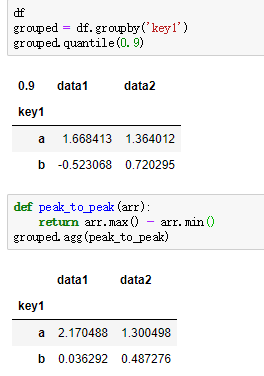
(6)逐列及多函数应用
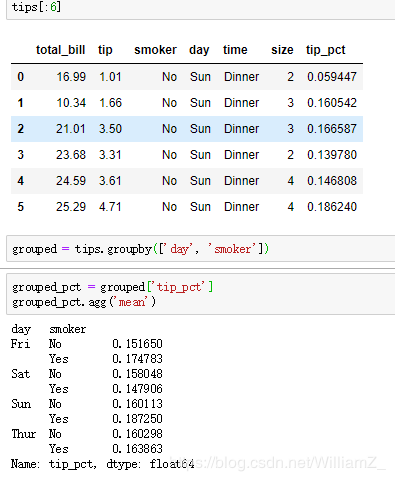
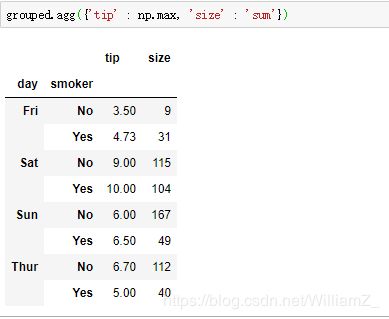
传递一个包含函数名的列表给agg方法,生成数据框,列名为各函数名:
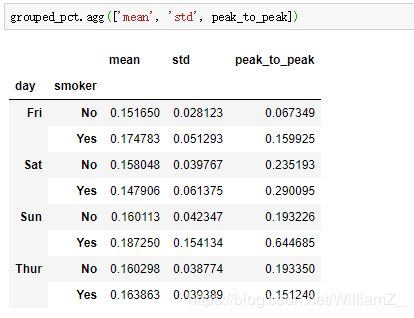
也可以给聚合后每列重命名,传递元组列表给agg方法,每个列表的元素元组中,第一个元素为聚合后的列名,第二个为聚合函数方法。
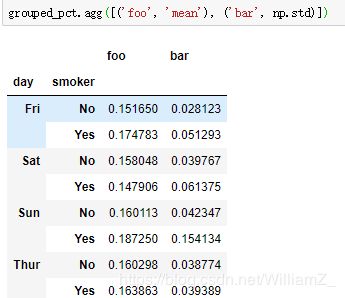
计算多列的聚合结果,其中多个函数应用于至少一列时,生成多层列索引数据框:
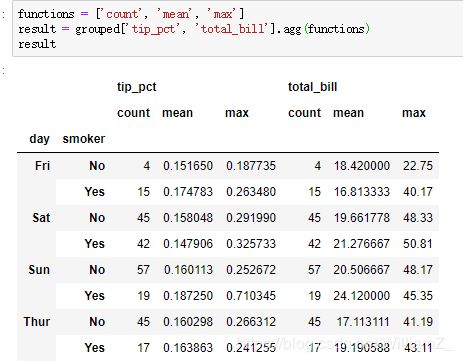
通过字典指定每列应用的函数:

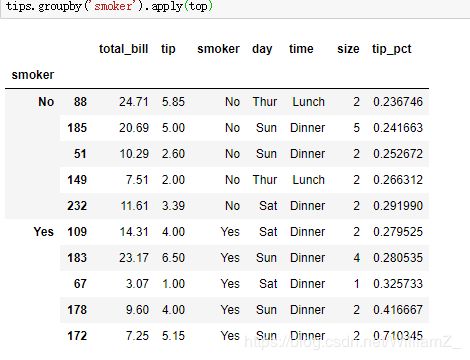
(7)apply方法与agg/aggregate方法
agg/aggregate方法聚合分组对象,使用的聚合函数返回标量值,而apply则可以返回更多不同情况,例:
根据somoker分组,返回各组中tip-pct值最高的五条记录:

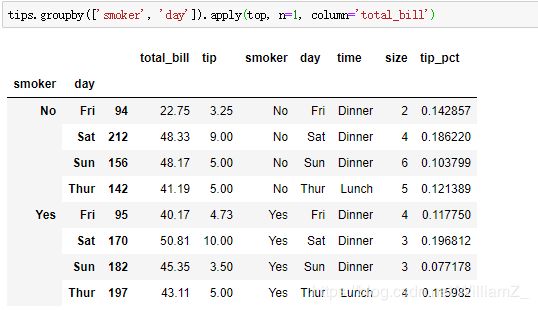
根据smoker、day分组,返回每组中total_bill值最高的观测
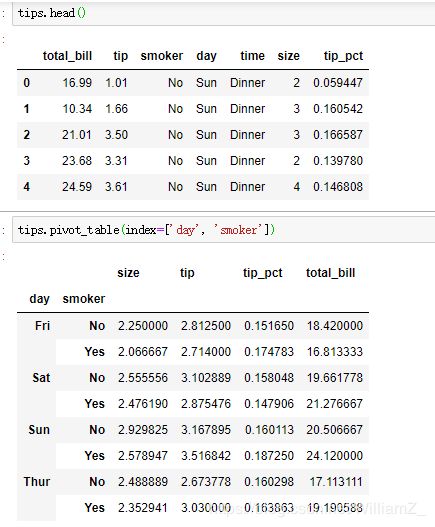
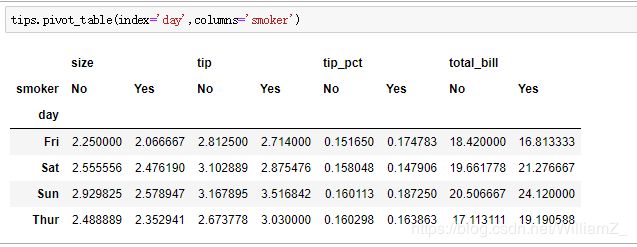
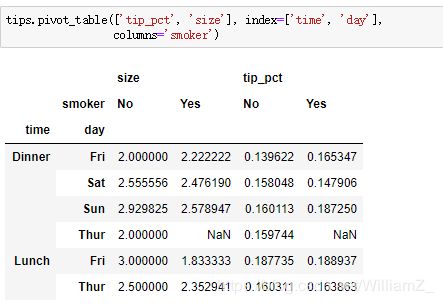
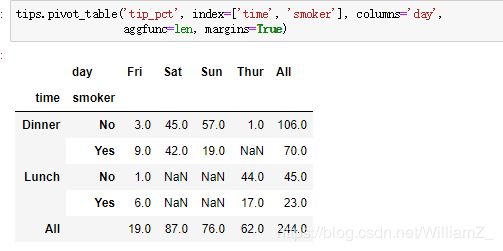
(8)透视表
pd.pivot_table():
部分参数:
data:指定需要构造透视表的数据集
values:指定需要拉入数值框的字段列表,默认除index/columns指定的列外的所有列值应用函数统计
index:行标签的字段列表
columns:列标签的字段列表
aggfunc:指定数值的统计函数,也可以使用numpy模块中的其他统计函数
fill_value:指定一个标量,用于填充缺失值
margins:是否需要显示行或列的总计值,默认为False
drop:是否需要删除整列为缺失值的字段,默认为True
margins_name:指定列或行的总计名称,默认为All