书荒了,不如用代码分析小说吧(一)
用代码分析小说吧
- 书荒了,不如用代码分析小说吧(一)
- 关键词
- 功能效果、思路
- 效果
- 思路
- 代码
- java类
- pom.xml依赖
- 调用
- 使用pyechart生成图表文件
- 效果图
- 生成人物统计文件
- pyechart生成的饼状图
- 小结
书荒了,不如用代码分析小说吧(一)
一个老书虫了,看书的状态已经从精度变成扫描仪,继而变成看目录、看简介、看书名就结束的读法。。。嗯,既然如此,干脆没有情怀的用机器读去吧!
关键词
- 中文文本分析(hanlp java版本)
- spark (java版本)
- 数据可视化(pyecharts)
功能效果、思路
效果
- 选择制定的小说文件,统计人名出现的次数,保存为文件
- 可视化人名统计信息
思路
- 通过hanlp提取小说文件的人名(精度需要提高)
- 使用spark进行数据清洗、统计。
- 使用pyecharts处理人名数据,生成html图表文件
代码
java类
package hanlplearn;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.model.crf.CRFLexicalAnalyzer;
import com.hankcs.hanlp.tokenizer.NLPTokenizer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.io.FileWriter;
import java.io.IOException;
import java.util.*;
import java.util.stream.Collectors;
public class FictionAnalysis {
// 文件路径(非utf8编码的文件使用sc.textFile(this.bookPath)会出现编码问题,试了网上的写法,报错,暂时用notepad++将小说文件转为utf8编码)
private String bookPath;
// 人名统计输出文件名
private String outPutFileName;
// 分词方式
private String analyerType;
public final static String BASE = "BASE";
public final static String NLP = "NLP";
public final static String CRF = "CRF";
private FictionAnalysis() {
}
public FictionAnalysis(String bookPath, String outPutFileName, String analyerType) {
this.bookPath = bookPath;
this.outPutFileName = outPutFileName;
this.analyerType = analyerType;
}
public void writeRoleNamesToFile() throws IOException {
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setMaster("local").setAppName(this.outPutFileName));
JavaRDD<String> bookData = sc.textFile(this.bookPath).cache();
String type = this.analyerType;
// 使用spark批处理数据、统计分析数据
JavaPairRDD<String, Integer> words = bookData.mapPartitionsToPair(par -> {
CRFLexicalAnalyzer crf = new CRFLexicalAnalyzer();
List<Tuple2<String, Integer>> tuple2List = new ArrayList<>();
System.out.println(type);
// 使用hanlp分词识别中文人名
while (par.hasNext()) {
String str = par.next();
if (Objects.equals(type, FictionAnalysis.NLP)) {
// NLP感知机分词,速度慢,准确度高
tuple2List.addAll(NLPTokenizer.analyze(str).toSimpleWordList().stream().map(seg -> new Tuple2<String, Integer>(seg.toString().trim(), 1)).collect(Collectors.toList()));
} else if (Objects.equals(type, FictionAnalysis.CRF)) {
// CRF分词,速度慢,准确度高,适合大量新词(目前感觉没NLP适合小说人名分析)
tuple2List.addAll(crf.analyze(str).toSimpleWordList().stream().map(seg -> new Tuple2<String, Integer>(seg.toString().trim(), 1)).collect(Collectors.toList()));
} else {
// 基础分词,速度快,精度低,但很多时候比NLP和CRF看起来更准
tuple2List.addAll(HanLP.segment(str).stream().map(seg -> new Tuple2<String, Integer>(seg.toString(), 1)).collect(Collectors.toList()));
}
}
return tuple2List.iterator();
})
.filter(t -> {
// 暂时没有使用hanlp提供的方法训练模型,先简单的过滤一下数据(张无忌竟然也识别不成人名,主角都整没了),/nr为hanlp识别的中文人名
if (!((t._1.endsWith("/nr") || t._1.contains("虚竹") || t._1.contains("张无忌")) && t._1.split("/")[0].length() > 1))
return false;
for (String c : t._1.split("/")[0].split("")) {
// 中文字符unicode范围
if (c.codePointAt(0) < 19967 || t._1.codePointBefore(1) > 40944) {
return false;
}
}
return true;
})
.mapToPair(t -> new Tuple2<String, Integer>(t._1.split("/")[0], t._2))
// 根据人名计数
.reduceByKey((v1, v2) -> v1 + v2);
List<Tuple2<String, Integer>> names = new ArrayList<>(words.map(tup -> tup).collect());
// 根据人名出现次数排序
names.sort((a, b) -> b._2 - a._2);
// 保存到文件(还是数据库好,目前数据不太准确,暂时使用文件保存)
FileWriter fw = new FileWriter(this.outPutFileName + "_" + type + ".txt");
for (Tuple2<String, Integer> name : names) {
fw.append(name._1 + ":" + name._2 + "\n");
}
fw.flush();
fw.close();
sc.stop();
}
}
pom.xml依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.8</version>
</dependency>
调用
new FictionAnalysis("小说文件路径", "输出文件名", FictionAnalysis.BASE).writeRoleNamesToFile();
使用pyechart生成图表文件
# -*- coding: utf-8 -*-
from pyecharts import Pie
from tkinter import filedialog
def generateVisul(filename):
name = str(filename).split("/")[-1].replace('.txt', '')
with open(filename, 'r', encoding='utf-8') as f:
content = f.read()
ls = list(map(lambda item: item.split(':'), content.split("\n")))
ls.remove([''])
print(ls[0:20])
showls = ls[0:20]
attrs = list(map(lambda item: item[0], showls))
values = list(map(lambda item: int(item[1]), showls))
pie = Pie(name + "图")
pie.add("", attrs, values, center=[50, 50], is_random=False, radius=[30, 75], rosetype='radius',
is_legend_show=False, is_label_show=True, legend_orient='vertical')
pie.render(name + '图.html')
if __name__ == '__main__':
filename = filedialog.askopenfilename()
generateVisul(filename)
注:代码、JVM、spark未经优化,电脑cpu入门级(好像没入门),内存16G+
基础文本分析运行时间:70M的超级兵王在30s内完成
NPL文本分析运行时间:3M的金庸小说大概30s,70M的超级兵王需要数分钟
效果图
生成人物统计文件
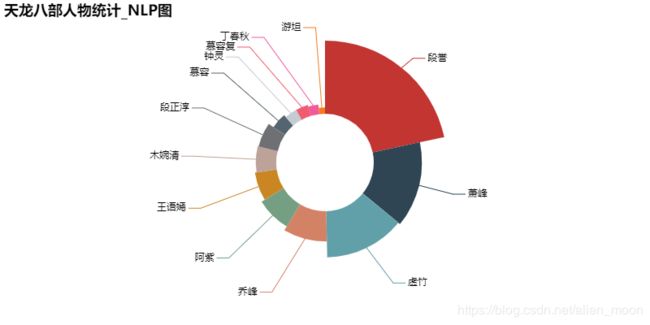
段誉:2498
萧峰:1647
虚竹:1578
乔峰:1033
阿紫:879
王语嫣:753
木婉清:698
段正淳:667
慕容:474
钟灵:386
慕容复:385
丁春秋:324
游坦:212
朱丹臣:193
叶二娘:188
鸠摩智:181
王夫人:163
李秋水:154
马夫人:147
邓百川:141
星宿:140
钟万仇:131
秦红棉:106
阮星竹:103
游坦之:101
慕容博:100
崔百泉:99
阿朱:98
司马林:95
段郎:88
黄眉僧:81
…
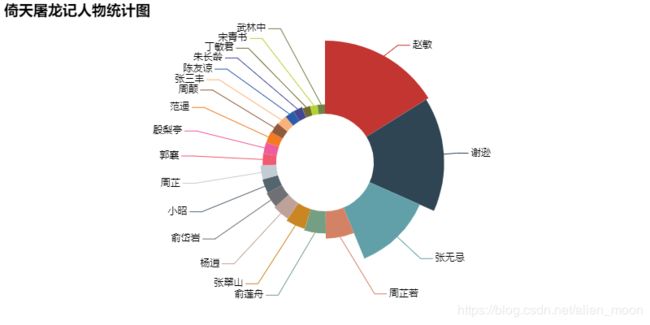
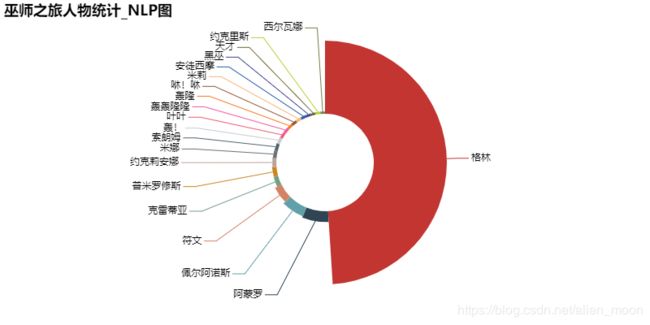
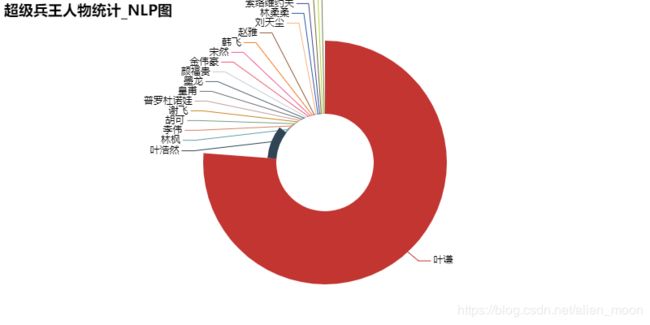
pyechart生成的饼状图

小结
哈哈,感觉张无忌不是主角啊,不对。。可能是剧情任务都叫“无忌哥哥”,文本分析没统计出来,想通此点,作为一个单身狗遭到暴击!!!
最近想搞大数据+深度学习,一回头发现过去用过的东西,加上现学现卖,也能凑合着先做点简陋的东西,作为一个书荒的老书虫,干脆通过分析小说来切入了。
目前只是简陋的版本,后续打算先提升准确度,增加几个新的有意义的分析方式(好点子在哪里?),然后提升效率(spark尚未跑出优势),再然后总结成小说可视化分析放到个人网站上耍耍。
呃……我最初的想法好像是结合深度学习,训练一个小说推荐模型(小说分析模型),然后就能筛选小说看了。。。
写个博客,督促学习