linux学习笔记
文章目录
- 文件结构
- 文件描述符
- inode
- 文件描述符概念
- 命令学习
- vim
- 光标定位
- 插入
- :
- 删除
- 复制和剪切
- 替换
- 查找
- 退出
- 查看日志
- tail:
- head:
- cat:
- vim:
- more/less/grep
- more
- less
- 查看日志应用场景一:按行号查看:过滤出关键字附近的日志
- 查看日志应用场景二:根据日期查询日志
- 查看日志应用场景三:日志内容特别多,打印在屏幕上不方便查看,分页/保存文件查看
- 进程
- (1)top命令:
- (2)free命令:
- (3)grep命令:
- (4)ps命令:
- (5)kill命令:
cd / 根目录(就一个)
cd ~ /usr/local
文件结构
在 Linux 世界里,一切皆文件。



文件描述符
inode
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
文件描述符概念
一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。
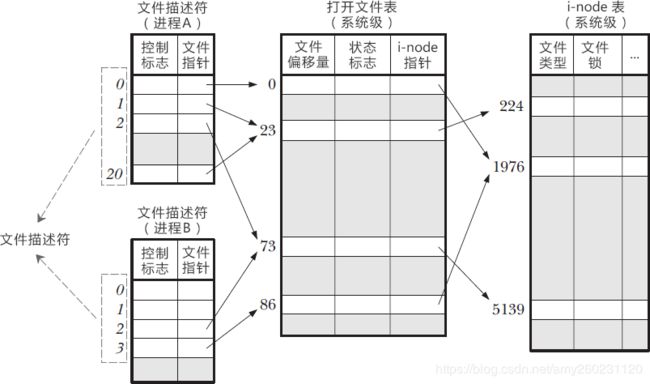
文件描述符只不过是一个数组下标!
命令学习
vim
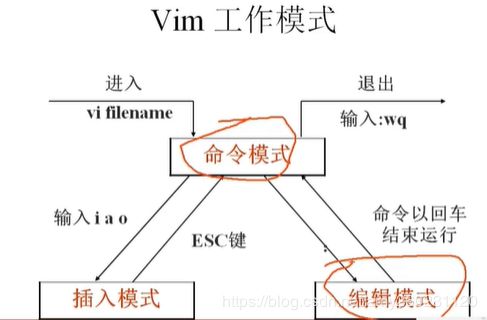
光标定位
home - end
啥模式下都行
插入
命令模式
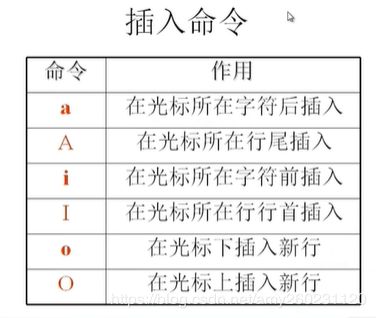
:
命令模式
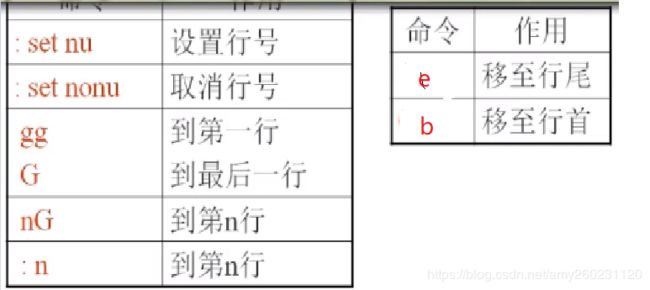
删除
命令模式

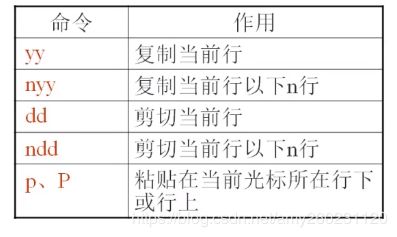
复制和剪切
命令模式
yy+p | dd + p
替换

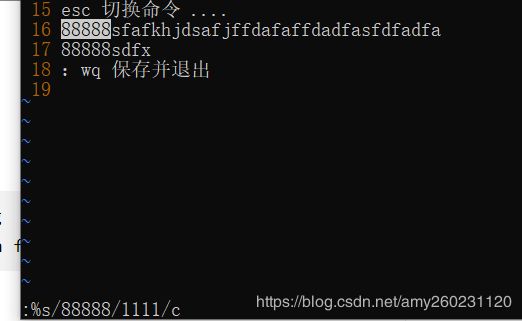
查找

替换时询问 : %s/old/new/c
不询问:%s/old/new/g

退出
查看日志
·实时日志:tail -f XXX.log
·搜索关键字附近日志:cat -n filename | grep "关键字"

tail:
-n 是显示行号;相当于nl命令;例子如下:
tail -100f test.log 实时监控100行日志
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
head:
跟tail是相反的,tail是看后多少行日志,而head是查看日志文件的头多少行,例子如下:
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
cat:
tac是倒序查看,是cat单词反写;例子如下:
cat -n test.log |grep "debug" 查询关键字的日志(常用!~)
vim:
1、进入vim编辑模式:vim filename
2、输入“/关键字”,按enter键查找
3、查找下一个,按“n”即可
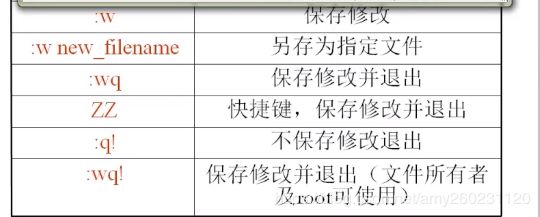
退出:按ESC键后,接着再输入:号时,vi会在屏幕的最下方等待我们输入命令
wq! 保存退出
q! 不保存退出
more/less/grep
more和less可用于日志内容过多时候分页
more
只能向下翻页
回车 一页页翻
空格 一行行显示
less
能上下翻页 空格/回车–向下 b–向上
/---- 向下查找 按 n 键可以跳转到下一个匹配的字符串
?— 向上查找
more 文件名
less 文件名
grep 文件名 | less
grep -c 文件名 输出行数
grep "text" . -r -n 多级文件递归搜索 # .表示当前目录。
查看日志应用场景一:按行号查看:过滤出关键字附近的日志
(1) cat -n test.log |grep "debug" 得到关键日志的行号
(2) cat -n test.log |tail -n +92|head -n 20 选择关键字所在的中间一行. 然后查看这个关键字前10行和后10行的日志:
tail -n +92表示查询92行之后的日志
head -n 20 则表示在前面的查询结果里再查前20条记录
查看日志应用场景二:根据日期查询日志
(1) sed -n '/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p' test.log
特别说明:
上面的两个日期必须是日志中打印出来的日志,否则无效
先 grep '2014-12-17 16:17:20' test.log 来确定日志中是否有该时间点
查看日志应用场景三:日志内容特别多,打印在屏幕上不方便查看,分页/保存文件查看
(1)使用more和less命令,
如: cat -n test.log |grep "debug" |more 这样就分页打印了,通过点击空格键翻页
(2)使用 >xxx.txt 将其保存到文件中,到时可以拉下这个文件分析
如:cat -n test.log |grep "debug" >debug.txt
进程
(1)top命令:
top命令经常用来监控Linux的系统状况,比如cpu、内存的使用。(但是该命令占用的CPU过大,因为需要时常更新)
(2)free命令:
查看内存使用情况(-h选项将内存以G单位显示,不够1G就以M为单位。-m选项以M为单位显示)
total(总量大小),used(已使用的),free(除了buff/cache剩余的内存),shared(共享内存),buff/cache(缓冲、缓存区内存数),available(真实剩余的可用内存数)。

(3)grep命令:
用于选择筛选出文件内容或命令返回结果。
grep “筛选条件/正则表达式” 文件内容
常用选项有:-v 筛选出除条件以外的其他内容,相当于取反
-i 忽略大小写差别
grep -n '2019-10-24 00:01:11' *.log 查找含有该时间文本的文件

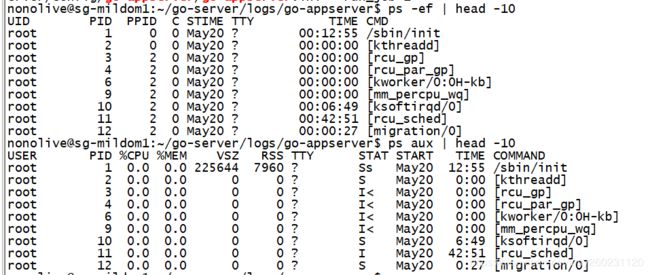
(4)ps命令:
显示进程信息。
1、ps aux:显示当前所有进程的详细信息。(a,u,x都为相应选项)
2、ps aux | grep “user”
USER => 用户名
%CPU => 进程占用的CPU百分比
%MEM => 占用内存的百分比
VSZ => 该进程使用的虚拟內存量(KB)
RSS => 该进程占用的固定內存量(KB)(驻留中页的数量)
STAT => 进程的状态
START => 该进程被触发启动时间
TIME => 该进程实际使用CPU运行的时间
3、ps -ef 标准格式显示进程
UID => 用户ID、但输出的是用户名
PID => 进程的ID
PPID => 父进程ID
C => 进程占用CPU的百分比
STIME => 进程启动到现在的时间
TTY => 该进程在那个终端上运行,若与终端无关,则显示? 若为pts/0等,则表示由网络连接主机进程。
CMD => 命令的名称和参数
(5)kill命令:
杀死进程。
1、kill 进程id/名称/编号
2、kill -9 进程id:彻底杀死进程
(6)pstree命令:以树状形式显示所有进程之间父进程与子进程关系。

1、pstree -up:树状形式显示进程信息。(u选项表示同时列出每个进程的PID,u选项表示同时列出每个进程的所属账号名称)
在这里插入图片描述
2、pstree 进程号 | wc -l:可查询当前某进程的线程或进程数(wc命令可计算某个文件的字数,行数等信息,-l就是显示行数)