Selenium 的使用
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
好处:不用再分析网站复杂的通信流程了
坏处:效率低
一般用在登录环节。
1、准备工作
安装Chrome浏览器
配置ChromeDriver
另外安装Python的Selenium库
2、基本使用
Selenium一些功能,示例如下:
from selenium import webdriver #用来驱动浏览器驱动 from selenium.webdriver import ActionChains #滑动验证码的时候用。拖拽滑动验证码进行移动 from selenium.webdriver.common.by import By #指定查找的方式 提交请求的过程当中,定位到页面中某一个标签。比如输入,就要找到输入的标签,往输入标签丢一些值给它, from selenium.webdriver.common.keys import Keys #键盘操作,比如回车操作 from selenium.webdriver.support import expected_conditions as EC #跟WebDriverWait连在一起用 from selenium.webdriver.support.wait import WebDriverWait #跟EC连在一起用 等页面加载
程序运行关掉了,浏览器也要关掉,不然后台会运行一堆浏览器。
也有可能用驱动发起请求的时候遇到错误了,出错可能在某一行抛异常了,就执行不到关掉浏览器的那行代码。所以try把爬取的逻辑放到里面去。示例如下:
from selenium import webdriver #用来驱动浏览器驱动 import time brower = webdriver.Chrome() try: brower.get('https://baidu.com') time.sleep(6) finally: brower.close()
基本使用演示:
from selenium import webdriver #用来驱动浏览器驱动 from selenium.webdriver import ActionChains #滑动验证码的时候用。拖拽滑动验证码进行移动 from selenium.webdriver.common.by import By #指定查找的方式 提交请求的过程当中,定位到页面中某一个标签。比如输入,就要找到输入的标签,往输入标签丢一些值给它, from selenium.webdriver.common.keys import Keys #键盘操作,比如回车操作 from selenium.webdriver.support import expected_conditions as EC #跟WebDriverWait连在一起用 from selenium.webdriver.support.wait import WebDriverWait #跟EC连在一起用 等页面加载 import time browser = webdriver.Chrome() try: wait = WebDriverWait(browser,4) # #发请求 browser.get('https://baidu.com') #获取输入框 input_tag = wait.until(EC.presence_of_element_located((By.ID,'kw'))) #输入内容 input_tag.send_keys('种花') #键盘操作回车 input_tag.send_keys(Keys.ENTER) time.sleep(6) finally: browser.close()
运行代码后发现,会自动弹出一个Chrome浏览器。浏览器首先会跳到百度,然后在搜索框中输入种花,接着跳转到搜索结果页,如图
在控制台分别会输出当前的URL、当前的Cookies和网页源代码,然后发现跟浏览器中的一模一样。
print(browser.current_url) print(browser.get_cookies()) print(browser.page_source)
所以说,如果用Selenium 来驱动浏览器加载网页的话,就可以直接拿到JavaScript渲染的效果了,不用担心使用的什么加密系统。
下面来详细介绍Selenium 的用法:
3、声明浏览器对象
Selenium 支持非常多的浏览器。如Chrome,Firefox,Edge等,还有Android,BlackBerry等手机端的浏览器。另外还支持无界面浏览器PhantomJS。
此外,我们可以用如下方式初始化:
from selenium import webdriver
browser=webdriver.Chrome() browser=webdriver.Firefox() browser=webdriver.PhantomJS() browser=webdriver.Safari() browser=webdriver.Edge()
这样就完成了浏览器对象的初始化并将其赋值为browser对象。接下来,我们要做的就是调用browser对象,让其执行各个动作以模拟浏览器操作。
4、访问页面
我们可以用get()方法来请求网页,参数传入链接URL 即可。比如,在这里用get()方法访问京东,然后打印出源代码,代码如下:
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.jd.com') print(browser.page_source) browser.close()
运行后发现,弹出了Chorme浏览器并且自动访问了京东,然后控制台输出了京东页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们可以实现浏览器的驱动并获取网页源码,非常便捷。
5、查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在那里吧?而Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
5.1、单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如下图所示:
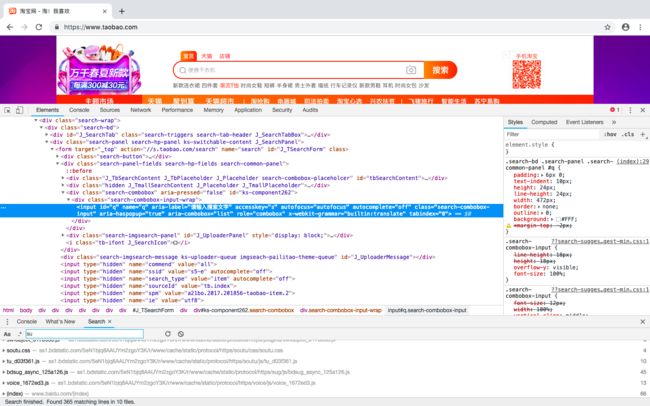
可以发现,它的id是q,name也是q。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_elemene_by_name()是根据 name 值获取,find_element_by_id()是根据id获取。另外,还有根据XPath、CSS选择器等获取的方式。
我们用代码实现一下:
from selenium import webdriver import time browser = webdriver.Chrome() try: browser.get('https://www.taobao.com') input_tag_first = browser.find_element_by_id('q') input_tag_second = browser.find_element_by_css_selector('#q') input_tag_third = browser.find_element_by_xpath('//*[@id="q"]') time.sleep(6) print(input_tag_first, input_tag_second, input_tag_third) finally: browser.close()
这里我们使用三种方式获取输入框,分别是根据ID、CSS选择器和XPath获取,它们返回结果完全一致。运行结构如下:
"2972957e8503390420728c4a4168e46b", element="0.45122930131287853-1")> "2972957e8503390420728c4a4168e46b", element="0.45122930131287853-1")> "2972957e8503390420728c4a4168e46b", element="0.45122930131287853-1")>
可以看到,这三个节点都是WebElement类型,是完全一致的。
这里列出所有获取单个节点的方法:
find_element意思是寻找元素,
find_element_by_id 通过id找
find_element_by_name 按照name属性找
find_element_by_xpath
find_element_by_link_text 通过链接的文本内容找(完全匹配)
find_element_by_pqrtial_link_text 通过链接的文本内容查找(部分匹配)
find_element_by_tag_name 通过标签名找
find_element_by_class_name 通过类名找
find_element_by_css_selector 通过css选择器.id#class
另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID,id),二者得到的结果完全一致。我们用代码实现以下:
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() try: browser.get('https://www.taobao.com') input_first = browser.find_element(By.ID,'q') input_second = browser.find_element_by_id('q') print(input_first) print(input_second) finally: browser.close()
"e7d7f0eb547ed6c0d5f38a8101ce1d50", element="0.3574977265796484-1")> "e7d7f0eb547ed6c0d5f38a8101ce1d50", element="0.3574977265796484-1")>
实际上,这两种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
5.2、多个节点
如果查找的目标在网页中只有一个,那么完全可以用find_element()方法。但如果有多个节点,再用find_element()方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用find_elements()这样的方法。注意,在这个方法的名称中,element多了个s,注意区分。
比如,要查找淘宝左侧导航条的所有条目,如下图所示:

就可以这样来实现:
from selenium import webdriver browser = webdriver.Chrome() # 多个节点 try: browser.get('https://www.taobao.com') list = browser.find_elements_by_css_selector('.service-bd li') print(list) finally: browser.close()
运行结果如下:
[
]
可以看到,得到的内容变成了列表类型,列表中的每个节点都是WebElement类型。
也就是说,如果我们用find_element()方法,只能获取匹配的第一个节点,结果是WebElement类型。如果用find_elements()方法,则结果是列表类型,列表中的每个节点是WebElement类型。
这里列出所有获取多个节点的方法:
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_pqrtial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
当然,我们也可以直接用find_elements()方法来选择,这时可以这样写:
list = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
6、节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮时使用click()方法。示例如下:
from selenium import webdriver import time browser = webdriver.Chrome() # 节点交互 browser.get('https://www.taobao.com') input_tag = browser.find_element_by_id('q') input_tag.send_keys('手机壳') time.sleep(1) input_tag.clear() input_tag.send_keys('多肉') button = browser.find_element_by_class_name('btn-search') button.click()
这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用senf_keys()方法输入手机壳文字,等待一秒后用clear()方法清空输入框,再次调用senf_keys()方法输入多肉文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。
通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
7、动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字的方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖拽。键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖拽动作,将某个节点从一处拖拽到另外一处,可以这样实现:
from selenium import webdriver from selenium.webdriver import ActionChains import time browser = webdriver.Chrome() try: url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser._switch_to.frame('iframeResult') source = browser.find_element_by_css_selector('#draggable') target = browser.find_element_by_css_selector('#droppable') # 方式一 # actions = ActionChains(browser) # actions.drag_and_drop(source,target) # actions.perform() # 方式二 distance = target.location['x']-source.location['x'] ActionChains(browser).click_and_hold(source).perform() s = 0 while s < distance: ActionChains(browser).move_by_offset(xoffset=2,yoffset=0).perform() # time.sleep(0.2) s+=2 ActionChains(browser).release().perform() time.sleep(4) finally: browser.close()
首先,打开网页中的一个拖拽实例,然后依次选中要拖拽的节点和拖拽的目标节点,接着声明ActionChains 对象并将其赋值为actions 变量,然后通过调用actions变量的drag_and_drop()方法,再调用perform()方法来执行操作,此时就完成了拖拽操作。
更多的动作连操作可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
8、执行JavaScript
执行某些操作,Selenium API并没有提供。比如。下拉进度条,它可以直接模拟运行JavaScript,此时使用execute_script()方法即可实现,代码如下:
from selenium import webdriver browser = webdriver.Chrome() try: browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') browser.execute_script('alert("To Bittom")') finally: browser.close()
这里利用了excute_script()方法将进度条下拉到最底部,然后弹出alert提示框。
所以说有了这个方法,基本上API没有提供的所用功能都可以用JavaScript的方式来实现了。
9、获取节点信息
前面说过,通过page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取消息了。
不过,既然Selenium 已经提供了了选择节点的方法,返回的是WebElement类型,那么它也有相关的方法和属性来直接提取节点信息,比如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取消息了,非常方便。
接下来,就看看通过怎样的方式获取节点信息吧。
9.1 获取属性
我们可以使用get_attribute()方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver import time browser = webdriver.Chrome() try: url = 'https://www.zhihu.com/explore' browser.get(url) zh_logo = browser.find_element_by_id('zh-top-link-logo') print(zh_logo) print(zh_logo.get_attribute('class')) time.sleep(4) finally: browser.close()
运行之后,程序便会驱动浏览器打开知乎页面,然后获取知乎的logo节点,最后打印出它的class。
控制台的输出结果为:
"a014d9de06bbb4bebeb1d6bf50cdfab9", element="0.6635784736572936-1")> zu-top-link-logo
通过get_attribute()方法,然后传入想要获取的属性名,就可以得到它的值了。
9.2 获取文本值
每个WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息,这相当于Beautiful Soup的get_text()方法、pyquery的text()方法,示例如下:
from selenium import webdriver import time browser = webdriver.Chrome() # 获取文本值 try: url = 'https://www.zhihu.com/explore' browser.get(url) input_tag = browser.find_element_by_class_name('zu-top-add-question') print(input_tag.text) time.sleep(4) finally: browser.close()
这里依然是先打开知乎页面,然后获取‘提问’按钮这个节点,再将其文本内容值打印出来。
控制台显示结果如下:

9.3 获取id、位置、标签名和大小
另外,WebElement 节点还有一些其他属性,比如id属性可以获取节点id,location 属性可以获取该节点在页面的相对位置,tag_name 属性可以获取标签名称,size属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的。示例如下:
from selenium import webdriver import time browser = webdriver.Chrome() try: url = 'https://www.zhihu.com/explore' browser.get(url) input_tag = browser.find_element_by_class_name('zu-top-add-question') print(input_tag.id) print(input_tag.location) print(input_tag.tag_name) print(input_tag.size) finally: browser.close()
这里依然先打开知乎页面,然后获取 ‘提问’按钮这个节点,然后调用其id、liocation、tag_name、size属性来获取对赢得属性值。
10、切换Frame
我们知道网页中有一种节点叫做iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开页面后,它默认是在父集Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到 子Frame里面节点的。这时就需要使用switch_to.frame()方法来切换Frame。示例如下:
import time from selenium import webdriver from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome() try: url = 'http://www.runoob.com/try/try/.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') try: logo = browser.find_element_by_class_name('logo') except NoSuchElementException: print('NO LOGO') browser.switch_to.parent_frame() logo = browser.find_element_by_class_name('logo') print(logo) print(logo.text) finally: browser.close()
这里还是以前面演示动作链操作的网页为实例,首先通过switch_to.frame()方法切换到子Frame里面,然后尝试获取子Frame里的logo节点(这是不能找到的),如果找不到的话,就会抛出NoSuchElementException异常,异常被捕捉之后,就会输出NO LOGO,接下来,重新切换到父级Frame,然后再次重新获取节点,发现此时可以成功获取了。
所以,当页面包含子Frame时,想要获取子Frame中的节点,需要调用switch_to.frame()方法切换到对应的,然后在进行操作。
11、延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是;浏览器完全加载完成的页面,如果某些页面有额外的Ajax 请求,我们在网页代码中也不一定能获取成功。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待的方式有两种:一种是隐式等待,一种是显式等待。
11.1、隐式等待
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认时间是0。示例如下:
from selenium import webdriver browser = webdriver.Chrome() browser.implicitly_wait(10) browser.get('https://www.zhihu.com/explore') button_tag = browser.find_element_by_class_name('zu-top-add-question') print(button_tag)
这里我们用implicitly_wait(10)方法实现了隐式等待。
11.2、显式等待
隐式等待的效果并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一个更合适的显式等待方法,它指定要查找的节点,然后制定一个最长等待时间。如果在规定时间内加载出来这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() try: browser.get('https://www.taobao.com/') wait = WebDriverWait(browser,10) input_tag = wait.until(EC.presence_of_element_located((By.ID,'q'))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search'))) print(input_tag,button) finally: browser.close()
这里首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。比如,这里传入了presence_of_element_located这个条件,代表节点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
这样可以做到的效果就是,在10秒内如果ID为q的节点(即搜索框)成功加载出来。就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为element_to_be_clickable,也就是可点击,所以查找按钮时查找CSS选择器为的按钮,如果10秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过10秒还没有加载出来,就抛出异常。
运行代码,在网速较佳的情况下是可以成功加载出来的。
控制台的输出如下:
"7d8b894316bbc39ff3a124a2976202eb", element="0.004489568003788413-1")> "7d8b894316bbc39ff3a124a2976202eb", element="0.004489568003788413-2")>
可以看到,控制台成功输出了两个节点,它们都是WebElement类型。
如果失败的话会抛出异常。
12、前进和后退
平常使用浏览器时都有前进和后退功能,Selenium也可以完成这个操作,它使用back()方法后退,使用forward()方法前进。示例如下:
import time from selenium import webdriver browser = webdriver.Chrome() try: browser.get('https://www.baidu.com/') browser.get('https://www.taobao.com/') browser.get('https://www.jd.com/') browser.back() time.sleep(2) browser.forward() finally: browser.close()
这里我们连续访问三个页面,然后调用back()方法回到第二个页面,接下来再调用forward()方法又可以前进到第三个页面内。
13、Cookies
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
from selenium import webdriver browser = webdriver.Chrome() try: browser.get('https://www.zhihu.com/explore') print(browser.get_cookies()) browser.add_cookie({'name':'name','domain':'www.zhihu.com','value':'germey'}) print(browser.get_cookies()) print(browser.delete_all_cookies()) print(browser.get_cookies()) finally: browser.close()
首先,我们访问了知乎。加载完成后,浏览器实际上已经生成了Cookies了。接着我们调用get_cookies()方法获取所有的Cookies。然后我们添加一个Cookies,这里传入一个字典,有name、domain和value等内容。接下来,再次获取所有的Cookies。可以发现,结果就多了这一项新加的Cookie。最后调用delete_all_cookies()方法删除所有的Cookies。重新获取,发现结果就为空了。
控制台输出结果如下:
[{'domain': '.zhihu.com', 'expiry': 1567877193, 'httpOnly': False, 'name': '__utmz', 'path': '/', 'secure': False, 'value': '51854390.1552109194.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)'}, {'domain': '.zhihu.com', 'expiry': 1552110993, 'httpOnly': False, 'name': '__utmb', 'path': '/', 'secure': False, 'value': '51854390.0.10.1552109194'}, {'domain': '.zhihu.com', 'expiry': 1646717185.745797, 'httpOnly': False, 'name': 'q_c1', 'path': '/', 'secure': False, 'value': 'c1be5730838e4961a9c0ea0af241acf3|1552109185000|1552109185000'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '_zap', 'path': '/', 'secure': False, 'value': '329f49a1-d78e-4e05-9bd6-54e78fcc8b1a'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745947, 'httpOnly': False, 'name': 'l_cap_id', 'path': '/', 'secure': False, 'value': '"NzhlMjcyNjg0OTUyNDk2NmEwZjAzNzNmNDZjNGUwZjQ=|1552109185|4cd1bcfd1b23d2e8478b9a6ee1cc61386e586841"'}, {'domain': 'www.zhihu.com', 'expiry': 1552110085.745695, 'httpOnly': False, 'name': 'tgw_l7_route', 'path': '/', 'secure': False, 'value': '060f637cd101836814f6c53316f73463'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745898, 'httpOnly': False, 'name': 'cap_id', 'path': '/', 'secure': False, 'value': '"NWUxZGQzZTEwMjU4NGIwMmJmMDliMzVlMTc2Zjg5Yjg=|1552109185|ba3e32ca8fcf86e0cc39c4822b3998afdd05c7e8"'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '__utmv', 'path': '/', 'secure': False, 'value': '51854390.000--|3=entry_date=20190309=1'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'n_c', 'path': '/', 'secure': False, 'value': '1'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '__utma', 'path': '/', 'secure': False, 'value': '51854390.1872266721.1552109194.1552109194.1552109194.1'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': '__utmc', 'path': '/', 'secure': False, 'value': '51854390'}, {'domain': '.zhihu.com', 'expiry': 1646717192.357061, 'httpOnly': False, 'name': 'd_c0', 'path': '/', 'secure': False, 'value': '"ADAiXVxOGA-PTnrcZaT_2bgcCujQ0Jzk-bY=|1552109192"'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745854, 'httpOnly': False, 'name': 'r_cap_id', 'path': '/', 'secure': False, 'value': '"Y2E5NmY2MzdmOWU4NDI2ZGFhZTBhMTgxNDBkYWIxOGM=|1552109185|4f456af38fccd5e4920de3751616d1fcfb604ad8"'}, {'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '_xsrf', 'path': '/', 'secure': False, 'value': 'ffa701e12b2e436beef359522f1283dc'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'l_n_c', 'path': '/', 'secure': False, 'value': '1'}]
[{'domain': 'www.zhihu.com', 'expiry': 2182829193, 'httpOnly': False, 'name': 'name', 'path': '/', 'secure': True, 'value': 'germey'}, {'domain': '.zhihu.com', 'expiry': 1567877193, 'httpOnly': False, 'name': '__utmz', 'path': '/', 'secure': False, 'value': '51854390.1552109194.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)'}, {'domain': '.zhihu.com', 'expiry': 1552110993, 'httpOnly': False, 'name': '__utmb', 'path': '/', 'secure': False, 'value': '51854390.0.10.1552109194'}, {'domain': '.zhihu.com', 'expiry': 1646717185.745797, 'httpOnly': False, 'name': 'q_c1', 'path': '/', 'secure': False, 'value': 'c1be5730838e4961a9c0ea0af241acf3|1552109185000|1552109185000'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '_zap', 'path': '/', 'secure': False, 'value': '329f49a1-d78e-4e05-9bd6-54e78fcc8b1a'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745947, 'httpOnly': False, 'name': 'l_cap_id', 'path': '/', 'secure': False, 'value': '"NzhlMjcyNjg0OTUyNDk2NmEwZjAzNzNmNDZjNGUwZjQ=|1552109185|4cd1bcfd1b23d2e8478b9a6ee1cc61386e586841"'}, {'domain': 'www.zhihu.com', 'expiry': 1552110085.745695, 'httpOnly': False, 'name': 'tgw_l7_route', 'path': '/', 'secure': False, 'value': '060f637cd101836814f6c53316f73463'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745898, 'httpOnly': False, 'name': 'cap_id', 'path': '/', 'secure': False, 'value': '"NWUxZGQzZTEwMjU4NGIwMmJmMDliMzVlMTc2Zjg5Yjg=|1552109185|ba3e32ca8fcf86e0cc39c4822b3998afdd05c7e8"'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '__utmv', 'path': '/', 'secure': False, 'value': '51854390.000--|3=entry_date=20190309=1'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'n_c', 'path': '/', 'secure': False, 'value': '1'}, {'domain': '.zhihu.com', 'expiry': 1615181193, 'httpOnly': False, 'name': '__utma', 'path': '/', 'secure': False, 'value': '51854390.1872266721.1552109194.1552109194.1552109194.1'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': '__utmc', 'path': '/', 'secure': False, 'value': '51854390'}, {'domain': '.zhihu.com', 'expiry': 1646717192.357061, 'httpOnly': False, 'name': 'd_c0', 'path': '/', 'secure': False, 'value': '"ADAiXVxOGA-PTnrcZaT_2bgcCujQ0Jzk-bY=|1552109192"'}, {'domain': '.zhihu.com', 'expiry': 1554701185.745854, 'httpOnly': False, 'name': 'r_cap_id', 'path': '/', 'secure': False, 'value': '"Y2E5NmY2MzdmOWU4NDI2ZGFhZTBhMTgxNDBkYWIxOGM=|1552109185|4f456af38fccd5e4920de3751616d1fcfb604ad8"'}, {'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '_xsrf', 'path': '/', 'secure': False, 'value': 'ffa701e12b2e436beef359522f1283dc'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'l_n_c', 'path': '/', 'secure': False, 'value': '1'}]
None
[]
14、选项卡管理
在访问网页的时候,会开启一个个选项卡。在Selenium中,我们也可以对选项卡进行操作。示例如下:
15、异常处理
爬京东信息


from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 import time def get_goods(driver): try: goods=driver.find_elements_by_class_name('gl-item') for good in goods: detail_url=good.find_element_by_tag_name('a').get_attribute('href') p_name=good.find_element_by_css_selector('.p-name em').text.replace('\n','') price=good.find_element_by_css_selector('.p-price i').text p_commit=good.find_element_by_css_selector('.p-commit a').text msg = ''' 商品 : %s 链接 : %s 价钱 :%s 评论 :%s ''' % (p_name,detail_url,price,p_commit) print(msg,end='\n\n') button=driver.find_element_by_partial_link_text('下一页') button.click() time.sleep(1) get_goods(driver) except Exception: pass def spider(url,keyword): driver = webdriver.Chrome() driver.get(url) driver.implicitly_wait(3) # 使用隐式等待 try: input_tag=driver.find_element_by_id('key') input_tag.send_keys(keyword) input_tag.send_keys(Keys.ENTER) get_goods(driver) finally: driver.close() if __name__ == '__main__': spider('https://www.jd.com/',keyword='iPhone8手机')
破解极验滑动验证(博客园)
流程:
1、拿到浏览器驱动,然后请求地址,然后隐式等待,找到输入框输入账号密码然后点击登录。
2、点击按钮弹出图(没有缺口的图片)---截图
3、点击滑动按钮,弹出有缺口的图 -----截图
4、对比两张图片,找到缺口,就是要移动的位移
5、按照人的行为习惯,把总的位移切成一段段小的位移 ********()
6、按照位移移动