数据分析入门之2012美国大选政治献金项目
操作环境: window10,Python3.7,Jupyter notebook
数据资料: https://www.lanzous.com/i98lfra
文章目录
- 1、数据载入与总览
- 1.1、数据加载
- 1.2、数据合并
- 1.3、数据预览和基本统计分析
- 1.3.1、查看数据形状
- 1.3.2、查看是否有空值
- 1.3.3、查看描述性的信息
- 2、数据清洗
- 2.1、缺失值处理
- 2.1.1、查看带有缺失值的列
- 2.1.2、空值指定填充
- 2.2、数据转换
- 2.2.1、候选人去重
- 2.2.2、添加党派
- 2.2.3、统计两个党派支持的次数
- 2.2.4、查询每个政党的捐献额
- 2.2.5、按照职业汇总对赞助总金额进行排序
- 2.2.6、职业类型去重
- 2.3、数据筛选
- 2.3.1、赞助金额筛选
- 2.3.2、查看各候选人获得的赞助总金额
- 2.3.3、数据可视化
- 2.3.4、选取选举人为Obama、Romney的子集数据
- 2.4、面元化数据
- 3、数据聚合与分组运算
- 3.1、透视表(pivot_table)分析党派和职业
- 3.1.1、求每个职业为两个党派献金之和
- 3.1.2、过滤掉总和小于200W的数据
- 3.1.3、数据可视化
- 3.2、分组及运算和转换
- 3.2.1、不同职业对他两人的支持度
- 3.2.2、不同公司对他两人的支持度
- 3.3、统计各区间的赞助金额
- 3.3.1、查看区间金额
- 3.3.2、绘制Obama和Romney各区间赞助的总金额
- 3.3.3、过滤掉大金额
- 3.3.4、百分比堆积图
- 4、时间处理
- 4.1、查看数据类型
- 4.2、str转datetime
- 5、各州支持率
- 5.1、数据分组
- 5.2、候选人各州金额占比
- 5.3、删除不存在的州
- 5.4、绘制地图
- 5.4.1、导入相关库
- 5.4.2、同一绘制不同颜色方法
- 5.4.3、查看Obama各州均值
- 5.4.3、绘制美国地图
1、数据载入与总览
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
1.1、数据加载
contb1 = pd.read_csv('./contb_01.csv')
contb2 = pd.read_csv('./contb_02.csv')
contb3 = pd.read_csv('./contb_03.csv')
1.2、数据合并
contb = pd.concat([contb1, contb2, contb3], axis=0)
contb.head() #查看前五行
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | |
|---|---|---|---|---|---|---|---|
| 0 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 250.0 | 20-JUN-11 |
| 1 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 50.0 | 23-JUN-11 |
| 2 | Bachmann, Michelle | SMITH, LANIER | AL | INFORMATION REQUESTED | INFORMATION REQUESTED | 250.0 | 05-JUL-11 |
| 3 | Bachmann, Michelle | BLEVINS, DARONDA | AR | NONE | RETIRED | 250.0 | 01-AUG-11 |
| 4 | Bachmann, Michelle | WARDENBURG, HAROLD | AR | NONE | RETIRED | 300.0 | 20-JUN-11 |
字段解释:
cmte_id :候选人ID
cand_nm :候选人姓名
contbr_nm : 捐赠人姓名
contbr_st :捐赠人所在州
contbr_employer : 捐赠人所在公司
contbr_occupation : 捐赠人职业
contb_receipt_amt :捐赠数额(美元)
contb_receipt_dt : 捐款的日期
1.3、数据预览和基本统计分析
1.3.1、查看数据形状
contb.shape
(1001733, 7)
- 一共有1001733行,7列数据
1.3.2、查看是否有空值
contb.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1001733 entries, 0 to 1730
Data columns (total 7 columns):
cand_nm 1001733 non-null object
contbr_nm 1001733 non-null object
contbr_st 1001729 non-null object
contbr_employer 988004 non-null object
contbr_occupation 993303 non-null object
contb_receipt_amt 1001733 non-null float64
contb_receipt_dt 1001733 non-null object
dtypes: float64(1), object(6)
memory usage: 61.1+ MB
- 从上面的结果可以看出:
- 一共有1001733行数据,其中contbr_st,contbr_employe,contbr_occupation 有空值。
1.3.3、查看描述性的信息
contb.describe()
| contb_receipt_amt | |
|---|---|
| count | 1.001733e+06 |
| mean | 2.982358e+02 |
| std | 3.749663e+03 |
| min | -3.080000e+04 |
| 25% | 3.500000e+01 |
| 50% | 1.000000e+02 |
| 75% | 2.500000e+02 |
| max | 2.014491e+06 |
2、数据清洗
2.1、缺失值处理
2.1.1、查看带有缺失值的列
cond = contb['contbr_employer'].isnull() #判断是否有缺失值,返回True和False
contb[cond] #筛选满足的数据
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | |
|---|---|---|---|---|---|---|---|
| 41 | Bachmann, Michelle | MINNIS, RITA | CA | NaN | NaN | -1500.0 | 20-JUN-11 |
| 264 | Bachmann, Michelle | BISHOP, GERARD | NY | NaN | NaN | -1700.0 | 28-JUN-11 |
| 752 | Romney, Mitt | KNIGHT, RENA | AL | NaN | NaN | -60.0 | 07-MAR-12 |
| 897 | Romney, Mitt | THE STEWART FIRM L.L.C. | AL | NaN | NaN | 250.0 | 23-MAR-12 |
| 1033 | Romney, Mitt | SELLERS, LEE | AL | NaN | NaN | -120.0 | 20-JAN-12 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1715 | Perry, Rick | TEXAS ENERGY L.L.C. | WY | NaN | NaN | 250.0 | 30-SEP-11 |
| 1717 | Perry, Rick | HARDER, ROBERT | WY | NaN | RETIRED | 100.0 | 12-NOV-11 |
| 1720 | Perry, Rick | HARDER, ROBERT | WY | NaN | RETIRED | 100.0 | 01-OCT-11 |
| 1722 | Perry, Rick | HARDER, ROBERT | WY | NaN | RETIRED | 100.0 | 29-OCT-11 |
| 1723 | Perry, Rick | HARDER, ROBERT | WY | NaN | RETIRED | 100.0 | 30-NOV-11 |
2.1.2、空值指定填充
- 用某个值去填充上面的空值
- 上面
contbr_st,contbr_employe,contbr_occupation的一些用户没有提供信息,这是使用NOT PROVIDE进行填充。
# 填充空值,NOT PROVIDE没有提供
contb['contbr_employer'].fillna('NOT PROVIDE', inplace=True) #用NOT PROVIDE填充空值
#填充contbr_occupation为空的值为NOT PROVIDE
contb['contbr_occupation'].fillna('NOT PROVIDE', inplace=True)
contb['contbr_st'].fillna('NOT PROVIDE', inplace=True)
contb.info() # 查看填充后的结果
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1001733 entries, 0 to 1730
Data columns (total 7 columns):
cand_nm 1001733 non-null object
contbr_nm 1001733 non-null object
contbr_st 1001733 non-null object
contbr_employer 1001733 non-null object
contbr_occupation 1001733 non-null object
contb_receipt_amt 1001733 non-null float64
contb_receipt_dt 1001733 non-null object
dtypes: float64(1), object(6)
memory usage: 61.1+ MB
- 现在所有带有空值的数据被
NOT PROVIDE填充后,不再有空值。
2.2、数据转换
利用字典映射进行转换:党派分析
2.2.1、候选人去重
contb['cand_nm'].unique()
array(['Bachmann, Michelle', 'Romney, Mitt', 'Obama, Barack',
"Roemer, Charles E. 'Buddy' III", 'Pawlenty, Timothy',
'Johnson, Gary Earl', 'Paul, Ron', 'Santorum, Rick',
'Cain, Herman', 'Gingrich, Newt', 'McCotter, Thaddeus G',
'Huntsman, Jon', 'Perry, Rick'], dtype=object)
- 去重后发现一共有13名候选人参与竞选
2.2.2、添加党派
- 通过搜索引擎等途径,获取每个总统候选人的所属党派,建立字典parties,候选人名字作为键,所属党派作为对应的值
建立字典:
parties = {
'Bachmann, Michelle': 'Republican',
'Romney, Mitt': 'Republican',
'Obama, Barack': 'Democrat',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Pawlenty, Timothy': 'Republican',
'Johnson, Gary Earl': 'Republican',
'Paul, Ron': 'Republican',
'Santorum, Rick': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Huntsman, Jon': 'Republican',
'Perry, Rick': 'Republican'
}
数据映射:
%%time
contb['party'] = contb['cand_nm'].map(parties)
Wall time: 129 ms
- 新加党派,使用map字典映射,100万数据,增加一列耗时129ms
查看前5行:
contb.head()
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | party | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 250.0 | 20-JUN-11 | Republican |
| 1 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 50.0 | 23-JUN-11 | Republican |
| 2 | Bachmann, Michelle | SMITH, LANIER | AL | INFORMATION REQUESTED | INFORMATION REQUESTED | 250.0 | 05-JUL-11 | Republican |
| 3 | Bachmann, Michelle | BLEVINS, DARONDA | AR | NONE | RETIRED | 250.0 | 01-AUG-11 | Republican |
| 4 | Bachmann, Michelle | WARDENBURG, HAROLD | AR | NONE | RETIRED | 300.0 | 20-JUN-11 | Republican |
2.2.3、统计两个党派支持的次数
contb['party'].value_counts()
Democrat 593747
Republican 407986
Name: party, dtype: int64
2.2.4、查询每个政党的捐献额
contb.groupby('party')['contb_receipt_amt'].sum()
party
Democrat 1.335028e+08
Republican 1.652498e+08
Name: contb_receipt_amt, dtype: float64
2.2.5、按照职业汇总对赞助总金额进行排序
grouped_occupation = contb.groupby(['contbr_occupation'])['contb_receipt_amt'].sum()
grouped_occupation.sort_values(ascending=False) #ascending=False降序
contbr_occupation
RETIRED 48176647.00
ATTORNEY 18470473.30
HOMEMAKER 17484807.65
INFORMATION REQUESTED PER BEST EFFORTS 15859514.55
INFORMATION REQUESTED 8742357.59
...
PRES OF GAS & ELECTRIC -2500.00
AVIATION ATTORNEY -2500.00
DREDGING -2500.00
METAL SMITH -4225.00
VENTURE PHILANTHROPIST -5000.00
Name: contb_receipt_amt, Length: 45074, dtype: float64
2.2.6、职业类型去重
- 整理同种类型职业
- 按照职位进行汇总,计算赞助总金额,发现不少职业都是相同的,只不过是表达形式不同而已,如C.E.0与CEO,都是一个职业
- 利用函数进行转换:职业与雇主信息分析
- 建立一个职业对应的字典,把相同职业的不同表达映射为对应的职业,比如C.E.O映射为CEO
#整理一部分相同的职业,如果全部整理需要花费很长时间
occupation = {'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDE',
'INFORMATION REQUESTED':'NOT PROVIDE',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED ':'SELF-EMPLOYED'}
f = lambda x : occupation.get(x, x)
contb['contbr_occupation'] = contb['contbr_occupation'].map(f)
# 统计同种职业捐献的总额,查看前5个
contb.groupby(['contbr_employer'])['contb_receipt_amt'].sum().sort_values(ascending = False)[:10
contbr_employer
RETIRED 41374333.67
SELF-EMPLOYED 37483895.22
NOT PROVIDE 31281997.76
HOMEMAKER 14738524.86
NOT EMPLOYED 8636809.43
NONE 3809582.99
STUDENT 957971.85
REQUESTED 894009.54
MORGAN STANLEY 386129.40
UNEMPLOYED 377088.31
Name: contb_receipt_amt, dtype: float64
2.3、数据筛选
2.3.1、赞助金额筛选
- 去掉金额小于 “0” 的异常数据
# 捐赠金额大于0
contb_over = contb[contb['contb_receipt_amt'] > 0]
contb_over.head()
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | party | |
|---|---|---|---|---|---|---|---|---|
| 0 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 250.0 | 20-JUN-11 | Republican |
| 1 | Bachmann, Michelle | HARVEY, WILLIAM | AL | RETIRED | RETIRED | 50.0 | 23-JUN-11 | Republican |
| 2 | Bachmann, Michelle | SMITH, LANIER | AL | NOT PROVIDE | NOT PROVIDE | 250.0 | 05-JUL-11 | Republican |
| 3 | Bachmann, Michelle | BLEVINS, DARONDA | AR | NONE | RETIRED | 250.0 | 01-AUG-11 | Republican |
| 4 | Bachmann, Michelle | WARDENBURG, HAROLD | AR | NONE | RETIRED | 300.0 | 20-JUN-11 | Republican |
#去重前
contb.shape #(1001733, 8)
#去重后
contb_over.shape #(991477, 8)
2.3.2、查看各候选人获得的赞助总金额
cand_nm_amt = contb_over.groupby(['cand_nm'])['contb_receipt_amt'].sum().sort_values(ascending = False)
cand_nm_amt
cand_nm
Obama, Barack 1.358776e+08
Romney, Mitt 8.833591e+07
Paul, Ron 2.100962e+07
Perry, Rick 2.030675e+07
Gingrich, Newt 1.283277e+07
Santorum, Rick 1.104316e+07
Cain, Herman 7.101082e+06
Pawlenty, Timothy 6.004819e+06
Huntsman, Jon 3.330373e+06
Bachmann, Michelle 2.711439e+06
Johnson, Gary Earl 5.669616e+05
Roemer, Charles E. 'Buddy' III 3.730099e+05
McCotter, Thaddeus G 3.903000e+04
Name: contb_receipt_amt, dtype: float64
2.3.3、数据可视化
plt.figure(figsize=(8, 8))
cand_nm_amt.plot(kind='pie') #
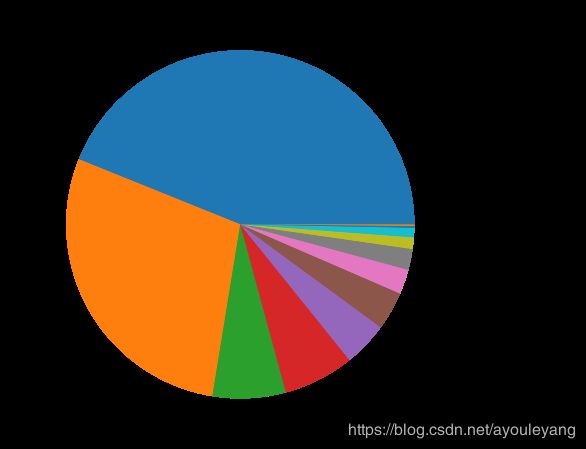
- 从上面的数据可以看出,支持Obama, Barack 和 Romney, Mitt 的人是最多的。
2.3.4、选取选举人为Obama、Romney的子集数据
方法一:
cond1 = contb_over['cand_nm'] == 'Obama, Barack'
cond2 = contb_over['cand_nm'] == 'Romney, Mitt'
# 这是一个与运算
cond = cond1|cond2
cond.sum() #694283次
contb_vs = contb_over[cond]
contb_vs
方法二:
contb_over.query("cand_nm == 'Obama, Barack' or cand_nm == 'Romney, Mitt'")
方法三:
cond = contb_over['cand_nm'].isin(['Obama, Barack', 'Romney, Mitt'])
contb_over[cond]
结果:
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | party | |
|---|---|---|---|---|---|---|---|---|
| 411 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 25.0 | 01-FEB-12 | Republican |
| 412 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 110.0 | 01-FEB-12 | Republican |
| 413 | Romney, Mitt | CARLSEN, RICHARD | AE | DEFENSE INTELLIGENCE AGENCY | INTELLIGENCE ANALYST | 250.0 | 13-APR-12 | Republican |
| 414 | Romney, Mitt | DELUCA, PIERRE | AE | CISCO | ENGINEER | 30.0 | 21-AUG-11 | Republican |
| 415 | Romney, Mitt | SARGENT, MICHAEL | AE | RAYTHEON TECHNICAL SERVICES CORP | COMPUTER SYSTEMS ENGINEER | 100.0 | 07-MAR-12 | Republican |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 201381 | Obama, Barack | MOUNTS, ROBERT | ZZ | HQ USFK (FKDC-SA) | GS-15 INTERNATIONAL RELATIONS OFFICER | 25.0 | 26-FEB-12 | Democrat |
| 201382 | Obama, Barack | TAITANO, TYRONE | ZZ | NOT EMPLOYED | RETIRED | 250.0 | 20-JAN-12 | Democrat |
| 201383 | Obama, Barack | TUCKER, PAMELA | ZZ | DODEA | EDUCATOR | 3.0 | 20-JAN-12 | Democrat |
| 201384 | Obama, Barack | MOUNTS, ROBERT | ZZ | HQ USFK (FKDC-SA) | GS-15 INTERNATIONAL RELATIONS OFFICER | 25.0 | 26-APR-12 | Democrat |
| 201385 | Obama, Barack | NEAL, AMBER | ZZ | THE DEPARTMENT OF DEFENSE EDUCATION AC | TEACHER | 135.0 | 04-SEP-11 | Democrat |
2.4、面元化数据
接下来我们对该数据做另一种非常实用的分析,利用cut函数根据出资额大小将数据离散化到多个面元中
contb_over['contb_receipt_amt'].sort_values()
323688 0.01
327537 0.01
327468 0.01
326458 0.01
317091 0.01
...
319478 526246.17
344419 1511192.17
344539 1679114.65
326651 1944042.43
325136 2014490.51
Name: contb_receipt_amt, Length: 991477, dtype: float64
- 他们的金额出现在 (0.01,2014490.51)之间,现在将它们进行范围分组。
bins = [0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000]
labels = pd.cut(contb_over['contb_receipt_amt'], bins)
labels
0 (100, 1000]
1 (10, 100]
2 (100, 1000]
3 (100, 1000]
4 (100, 1000]
...
1726 (1000, 10000]
1727 (1000, 10000]
1728 (100, 1000]
1729 (100, 1000]
1730 (1000, 10000]
Name: contb_receipt_amt, Length: 991477, dtype: category
Categories (8, interval[int64]): [(0, 1] < (1, 10] < (10, 100] < (100, 1000] < (1000, 10000] < (10000, 100000] < (100000, 1000000] < (1000000, 10000000]]
3、数据聚合与分组运算
contb_over.columns
Index(['cand_nm', 'contbr_nm', 'contbr_st', 'contbr_employer',
'contbr_occupation', 'contb_receipt_amt', 'contb_receipt_dt', 'party'],
dtype='object')
3.1、透视表(pivot_table)分析党派和职业
- 按照党派,职业对赞助金额进行汇总,类似Excel表中的透视表功能,聚合函数为sum
ret = contb_over.pivot_table('contb_receipt_amt', index='contbr_occupation', columns='party', aggfunc='sum', fill_value=0)
ret
| party | Democrat | Republican |
|---|---|---|
| contbr_occupation | ||
| MIXED-MEDIA ARTIST / STORYTELLER | 100.0 | 0.0 |
| AREA VICE PRESIDENT | 250.0 | 0.0 |
| RESEARCH ASSOCIATE | 100.0 | 0.0 |
| TEACHER | 500.0 | 0.0 |
| THERAPIST | 3900.0 | 0.0 |
| ... | ... | ... |
| ZOOKEEPER | 35.0 | 0.0 |
| ZOOLOGIST | 400.0 | 0.0 |
| ZOOLOGY EDUCATION | 25.0 | 0.0 |
| \NONE\ | 0.0 | 250.0 |
| ~ | 0.0 | 75.0 |
3.1.1、求每个职业为两个党派献金之和
ret['total'] = ret['Democrat'] + ret['Republican']
ret.head()
| party | Democrat | Republican | total |
|---|---|---|---|
| contbr_occupation | |||
| MIXED-MEDIA ARTIST / STORYTELLER | 100.0 | 0.0 | 100.0 |
| AREA VICE PRESIDENT | 250.0 | 0.0 | 250.0 |
| RESEARCH ASSOCIATE | 100.0 | 0.0 | 100.0 |
| TEACHER | 500.0 | 0.0 | 500.0 |
| THERAPIST | 3900.0 | 0.0 | 3900.0 |
3.1.2、过滤掉总和小于200W的数据
cond = ret['total'] < 2000000 #条件
index = ret[cond].index # 索引
ret_big = ret.drop(labels=index) # 移除
ret_big
| party | Democrat | Republican | total |
|---|---|---|---|
| contbr_occupation | |||
| ATTORNEY | 14302461.84 | 7.868419e+06 | 2.217088e+07 |
| CEO | 2074974.79 | 4.211041e+06 | 6.286015e+06 |
| CONSULTANT | 2459912.71 | 2.544725e+06 | 5.004638e+06 |
| ENGINEER | 951525.55 | 1.818374e+06 | 2.769899e+06 |
| EXECUTIVE | 1355161.05 | 4.138850e+06 | 5.494011e+06 |
| HOMEMAKER | 4248875.80 | 1.363428e+07 | 1.788315e+07 |
| INVESTOR | 884133.00 | 2.431769e+06 | 3.315902e+06 |
| MANAGER | 762883.22 | 1.444532e+06 | 2.207416e+06 |
| NOT PROVIDE | 13725187.32 | 2.097161e+07 | 3.469680e+07 |
| OWNER | 1001567.36 | 2.408287e+06 | 3.409854e+06 |
| PHYSICIAN | 3735124.94 | 3.594320e+06 | 7.329445e+06 |
| PRESIDENT | 1878509.95 | 4.720924e+06 | 6.599434e+06 |
| PROFESSOR | 2165071.08 | 2.967027e+05 | 2.461774e+06 |
| REAL ESTATE | 528902.09 | 1.625902e+06 | 2.154804e+06 |
| RETIRED | 25305316.38 | 2.356124e+07 | 4.886656e+07 |
| SELF-EMPLOYED | 721108.40 | 1.961786e+06 | 2.682894e+06 |
3.1.3、数据可视化
# 绘制图形
ret_big.plot(kind='bar', figsize=(12, 6))

3.2、分组及运算和转换
- 根据职业和雇主信息分组运算
grouped = contb_over.groupby('cand_nm')
grouped
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001D1D57CBE08>
- 可以用 for 方法遍历出分组的结果
3.2.1、不同职业对他两人的支持度
- 由于职业和雇主的处理非常相似,我们定义函数get_top_amounts()对两个字段进行分析处理
- 首先统计各区间的赞助笔数,这里用到unstack(),stack()函数是堆叠,unstack()函数是不要堆叠,即把多层索引变为表格数据
def get_top_amounts(grouped, key, n):
#先分组,grouped,然后继续再分
return grouped.groupby(key)['contb_receipt_amt'].sum().sort_values(ascending=False)[:n]
grouped = contb_over.groupby('cand_nm')
grouped.apply(get_top_amounts, 'contbr_occupation', 7).unstack(level=0)
| cand_nm | Obama, Barack | Romney, Mitt |
|---|---|---|
| contbr_occupation | ||
| ATTORNEY | 14302461.84 | 5372424.02 |
| CEO | NaN | 2324297.03 |
| CONSULTANT | 2459912.71 | NaN |
| EXECUTIVE | NaN | 2300947.03 |
| HOMEMAKER | 4248875.80 | 8147446.22 |
| NOT PROVIDE | 13725187.32 | 11638509.84 |
| PHYSICIAN | 3735124.94 | NaN |
| PRESIDENT | NaN | 2491244.89 |
| PROFESSOR | 2165071.08 | NaN |
| RETIRED | 25305316.38 | 11508473.59 |
结论:从数据可以看出,Obama更受精英群体(律师、医生、咨询顾问)的欢迎,Romney则得到更多企业家或企业高管的支持
3.2.2、不同公司对他两人的支持度
- 同样,使用get_top_amounts()对雇主进行分析处理
def get_top_amounts(grouped, key, n):
#先分组,grouped,然后继续再分
return grouped.groupby(key)['contb_receipt_amt'].sum().sort_values(ascending=False)[:n]
grouped = contb_over.groupby('cand_nm')
grouped.apply(get_top_amounts, 'contbr_employer', 7)
cand_nm contbr_employer
Obama, Barack RETIRED 22694558.85
SELF-EMPLOYED 18626807.16
NOT PROVIDE 13883494.03
NOT EMPLOYED 8586308.70
HOMEMAKER 2605408.54
STUDENT 318831.45
VOLUNTEER 257104.00
Romney, Mitt NOT PROVIDE 12321731.24
RETIRED 11506225.71
HOMEMAKER 8147196.22
SELF-EMPLOYED 7414115.22
STUDENT 496490.94
CREDIT SUISSE 281150.00
MORGAN STANLEY 267266.00
Name: contb_receipt_amt, dtype: float64
结论: Obama:微软,盛德国际律师事务所;Romney:瑞士瑞信银行,摩根斯坦利,高盛公司,巴克莱资本,H.I.G资本
3.3、统计各区间的赞助金额
3.3.1、查看区间金额
labels = pd.cut(contb_vs['contb_receipt_amt'], bins)
contb_vs.groupby(['cand_nm', labels]).size().unstack(level=0, fill_value=0)
| cand_nm | Obama, Barack | Romney, Mitt |
|---|---|---|
| contb_receipt_amt | ||
| (0, 1] | 493 | 77 |
| (1, 10] | 40070 | 3681 |
| (10, 100] | 372280 | 31853 |
| (100, 1000] | 153992 | 43357 |
| (1000, 10000] | 22284 | 26186 |
| (10000, 100000] | 2 | 1 |
| (100000, 1000000] | 3 | 0 |
| (1000000, 10000000] | 4 | 0 |
3.3.2、绘制Obama和Romney各区间赞助的总金额
amt_vs = contb_vs.groupby(['cand_nm', labels]).sum().unstack(level=0, fill_value=0)
amt_vs.fillna(0, inplace=True)
amt_vs.plot(kind='bar', figsize=(12,6))

3.3.3、过滤掉大金额
# 过滤掉大金额
amt_vs[:-2].plot(kind='bar', figsize=(12,6))

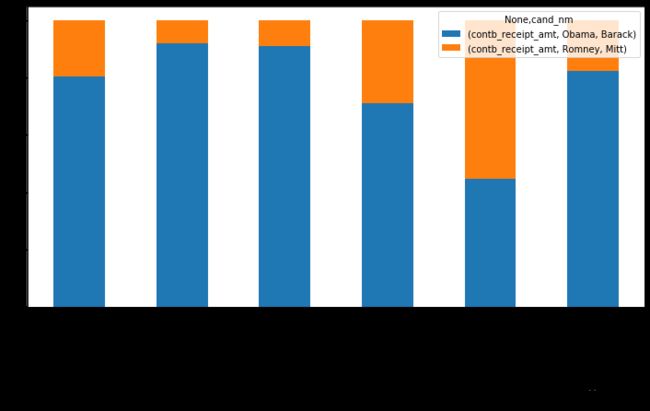
3.3.4、百分比堆积图
算出每个区间两个候选人收到赞助总金额比:
amt_vs.div(amt_vs.sum(axis = 1), axis=0)[:-2]
| contb_receipt_amt | ||
|---|---|---|
| cand_nm | Obama, Barack | Romney, Mitt |
| contb_receipt_amt | ||
| (0, 1] | 0.805182 | 0.194818 |
| (1, 10] | 0.918767 | 0.081233 |
| (10, 100] | 0.910769 | 0.089231 |
| (100, 1000] | 0.710177 | 0.289823 |
| (1000, 10000] | 0.447326 | 0.552674 |
| (10000, 100000] | 0.823120 | 0.176880 |
绘制百分比堆积图:
- 参数 stacked=True
amt_vs.div(amt_vs.sum(axis = 1), axis=0)[:-2].plot(kind='bar', stacked=True, figsize=(12, 6))
4、时间处理
contb_vs.head()
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | party | |
|---|---|---|---|---|---|---|---|---|
| 411 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 25.0 | 01-FEB-12 | Republican |
| 412 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 110.0 | 01-FEB-12 | Republican |
| 413 | Romney, Mitt | CARLSEN, RICHARD | AE | DEFENSE INTELLIGENCE AGENCY | INTELLIGENCE ANALYST | 250.0 | 13-APR-12 | Republican |
| 414 | Romney, Mitt | DELUCA, PIERRE | AE | CISCO | ENGINEER | 30.0 | 21-AUG-11 | Republican |
| 415 | Romney, Mitt | SARGENT, MICHAEL | AE | RAYTHEON TECHNICAL SERVICES CORP | COMPUTER SYSTEMS ENGINEER | 100.0 | 07-MAR-12 | Republican |
- 在上面的结果中,我们可以看出时间格式为
01-FEB-12,拥有英文符号,说明格式是字符串,不能直接用于运算。
4.1、查看数据类型
contb_vs.dtypes
cand_nm object
contbr_nm object
contbr_st object
contbr_employer object
contbr_occupation object
contb_receipt_amt float64
contb_receipt_dt object
party object
dtype: object
4.2、str转datetime
contb_vs['contb_receipt_dt'] = pd.to_datetime(contb_vs['contb_receipt_dt'])
contb_vs.head()
| cand_nm | contbr_nm | contbr_st | contbr_employer | contbr_occupation | contb_receipt_amt | contb_receipt_dt | party | |
|---|---|---|---|---|---|---|---|---|
| 411 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 25.0 | 2012-02-01 | Republican |
| 412 | Romney, Mitt | ELDERBAUM, WILLIAM | AA | US GOVERNMENT | FOREIGN SERVICE OFFICER | 110.0 | 2012-02-01 | Republican |
| 413 | Romney, Mitt | CARLSEN, RICHARD | AE | DEFENSE INTELLIGENCE AGENCY | INTELLIGENCE ANALYST | 250.0 | 2012-04-13 | Republican |
| 414 | Romney, Mitt | DELUCA, PIERRE | AE | CISCO | ENGINEER | 30.0 | 2011-08-21 | Republican |
| 415 | Romney, Mitt | SARGENT, MICHAEL | AE | RAYTHEON TECHNICAL SERVICES CORP | COMPUTER SYSTEMS ENGINEER | 100.0 | 2012-03-07 | Republican |
- 现在时间是
2012-02-01的形式,格式为datetime64
5、各州支持率
5.1、数据分组
根据州和候选人进行分组:
state_vs = contb_vs.groupby(['cand_nm','contbr_st'])['contb_receipt_amt'].sum().unstack(level=0)
state_vs
| cand_nm | Obama, Barack | Romney, Mitt |
|---|---|---|
| contbr_st | ||
| AA | 56405.00 | 135.00 |
| AB | 2048.00 | NaN |
| AE | 42973.75 | 5680.00 |
| AK | 281840.15 | 86204.24 |
| AL | 543123.48 | 527303.51 |
| ... | ... | ... |
| WI | 1130155.46 | 270316.32 |
| WV | 169154.47 | 126725.12 |
| WY | 194046.74 | 252595.84 |
| XX | NaN | 400250.00 |
| ZZ | 5963.00 | NaN |
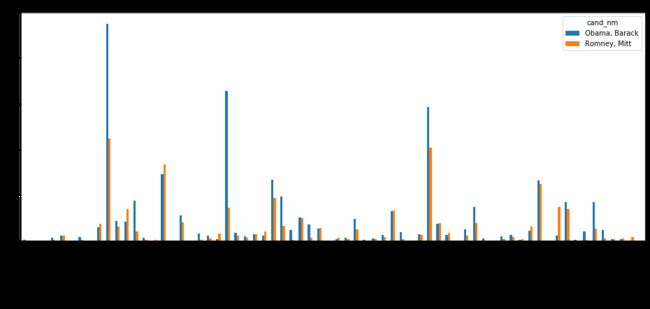
数据可视化:
state_vs.fillna(0, inplace=True)
state_vs.plot(kind='bar', figsize=(16, 6))
5.2、候选人各州金额占比
# 所占的比例
state_vs_rate = state_vs.div(state_vs.sum(axis=1), axis=0)
state_vs_rate
| cand_nm | Obama, Barack | Romney, Mitt |
|---|---|---|
| contbr_st | ||
| AA | 0.997612 | 0.002388 |
| AB | 1.000000 | 0.000000 |
| AE | 0.883257 | 0.116743 |
| AK | 0.765778 | 0.234222 |
| AL | 0.507390 | 0.492610 |
| ... | ... | ... |
| WI | 0.806982 | 0.193018 |
| WV | 0.571700 | 0.428300 |
| WY | 0.434456 | 0.565544 |
| XX | 0.000000 | 1.000000 |
| ZZ | 1.000000 | 0.000000 |
5.3、删除不存在的州
state_vs_rate.drop(labels=['AA', 'AB', 'AE', 'NOT PROVIDE'], inplace=True)
5.4、绘制地图
- basemap 工具包, pip install basemap
- basemap 绘制地图, pip install 无法安装成功
- python本地库下载: https://www.lfd.uci.edu/~gohlke/pythonlibs/#
- basemap官网: https://matplotlib.org/basemap/api/basemap_api.html
- mapShapeFile下载: https://gadm.org/download_country_v3.html
- 美国地图ShapeFile也可以在该博客的顶部数据链接下载
5.4.1、导入相关库
from mpl_toolkits.basemap import Basemap
from matplotlib.patches import Polygon #导入多边形包
from matplotlib.colors import rgb2hex #rgb2hex表示16进制的颜色
5.4.2、同一绘制不同颜色方法
# 着色
cmap = plt.cm.Reds #blues,0cean....
for i in range(10):
print ((i+1) / 10)
plt.plot(np.arange(10) + i, c=cmap((i+1) / 10))
输出结果:
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0

5.4.3、查看Obama各州均值
obama = state_vs_rate['Obama, Barack']
obama
contbr_st
AK 0.765778
AL 0.507390
AP 0.957329
AR 0.772902
AS 1.000000
...
WI 0.806982
WV 0.571700
WY 0.434456
XX 0.000000
ZZ 1.000000
Name: Obama, Barack, Length: 64, dtype: float64
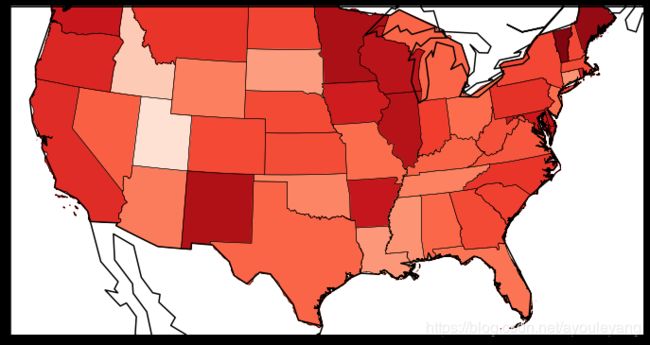
5.4.3、绘制美国地图
'''
关键词 描述
llcrnrlon 所需地图域的左下角经度(度)。
llcrnrlat 所需地图域的左下角纬度(度)。
urcrnrlon 所需地图域右上角的经度(度)。
urcrnrlat 所需地图域右上角的纬度(度)。
'''
plt.figure(figsize=(12, 9))
m = Basemap(llcrnrlon = -122,
llcrnrlat = 23.41,
urcrnrlon = -64,
urcrnrlat = 45,
projection = 'lcc',
lat_1 = 30,
lon_0 = -100
)
m.drawcoastlines(linewidth=1.5) #海岸线
m.drawcountries(linewidth=1.5) # 国家
# m.drawstates() #直接画出州
# 读取美国地图的现状,m中就有了各州的形状,数据
m.readshapefile('./USA/gadm36_USA_1', name='states')
colors = []
states = []
cmap = plt.cm.Reds
#州全称对应缩写缩写
abbr = {'Commonwealth of Kentucky':'KY','Commonwealth of Massachusetts':'MA','Commonwealth of Pennsylvania':'PA',
'State of Rhode Island and Providence Plantations':'RI'}
for shapeinfo in m.states_info:
a = shapeinfo['VARNAME_1'] #结果结构AL|Ala,AK|Alaska
# 州的缩写
s = a.split('|')[0] # 结果AL,AK表示州的缩写
try:
rate = obama[s] # 取出obama的州对应的值
colors.append(cmap(rate)) #转化颜色
states.append(s) #州的简称
except:
colors.append(cmap(obama[abbr[s]]))#有些州没有检查,需要进行替换
states.append(s)
# 州填充颜色
# seg州中的一部分区域,多边形
ax = plt.gca()
for n,seg in enumerate(m.states):
c = rgb2hex(colors[n])
poly = Polygon(seg,color = c )
ax.add_patch(poly)
plt.show()