python爬取美团评论做词云分析
前言: 这是一个帮忙做的毕业论文设计相关的爬虫,爬取美团的评论后,进行词云分析,倒是不复杂,我花半个小时写好了爬虫相关的代码,然后又花了近两个小时录制了教程视频,如果大家想看的话,等我到学校有网络了,可以发给大家学习,这个视频由于在录制的过程收到了干扰,分为了4个部分,分别为(抓包分析,美团爬虫,IP代理,词云流程),里面都是我个人积累的爬虫实战经验,可以作为一个很好的入门项目。
文章目录
- 1、抓包分析
- 1.1、分析网页
- 1.2、如何进行抓包?
- 2、美团爬虫
- 2.1、如何提取json()数据?
- 2.2、正式爬取信息
- 3、IP代理
- 3.1、爬取存入CSV代码汇总
- 3.1、爬取存入TXT代码汇总
- 4、词云流程
- 4.1、打开txt文本做词云图
- 4.1.1、对jieba分词的简单了解
- 4.1.2、词云基础
- 4.1.3、加入背景图片
- 4.2、打开CSV文本做词云图
- 4.2.1、导入数据
- 4.2.2、读取表格中的评论文本
- 4.2.2.1、单独把文本读取出来
- 4.2.2.2、数据清洗
- 4.3、转化为文本
开发环境: window10,python37,jupyter notebook
爬取结果及流程文档下载: https://www.lanzous.com/i9m0sfe
1、抓包分析
- 按照需求,我随便选择了一家花溪大学城评论多的点评点评信息进行爬取
商铺链接: https://www.meituan.com/meishi/193383554/
1.1、分析网页
对于网络爬虫,我拿到的第一件事就是分析它的网页数据的加载方式,再决定我请求服务器的方式。

- 从上面的文字看出,它并没有对字体进行加密,这样我们就省心一点儿了。
- 它的这些评论都可以直接查看,不需要登陆,这样的话反爬措施又少了一层。
- 点击下一页,它的URL并没有发生变化,可以初步判断它是ajax加载的数据,所以我们可以抓包来看看了。
1.2、如何进行抓包?
浏览器的中的每一条信息的加载都离不开 Network ,这就意味着我们可以通过它来查看网页加载出来的内容。
抓包的步骤:
- 鼠标右击,打开检查功能
- 选择Network
- 选择All
- 刷新网页
- 查看加载的数据

如何更好的查看加载的内容是什么?
-
我们的目的只是找到自己需要的内容,没有必要全部都查看一遍,只需要知道一些关键的数据进行查看就好了。
最重要的是注意 Network 中的Type(加载的文件类型) 和 size(加载的文件大小) 这两个要素,如我们要查看的目标是文字文件,带有图片类型的文件都可以不用查看了,其二就是它的大小,上面的很多文件都没有显示大小,我们几乎可以把它忽略了。对于网页不是很了解的同学,不建议直接使用筛选功能。 -
查看内容:

也可以把这些信息复制到一个json数据解析的网站上解析一下,就可以看到格式化的内容了。 -
从上面信息中,可以发现一共有10个用户在评论,说明每次它只加载10个评论与回复。
-
我们再来看它请求数据的方式,把它点在headers这里查看它的请求头
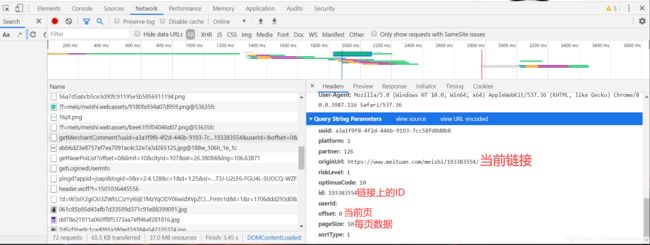
注意看这上面的信息,完全和它这个路径的信息相同,我们把这个链接复制到浏览器打开试试

-
如果出现了这样的结果,说明这个链接已经自带请求参数了,这样我们就方便很多了,可以直接拿来就用。
-
现在点击第二页,找到它的这个路径,复制过来,粘贴到编辑器里,然后再点击下一页,复制第三来进行对比

从上面的结果发现,它们的参数只有offset=不同,并且间隔为10,接下来我们直接生成对应的这个数据通道就ok了。 -
这样抓包就算完成了,接下了就可以请求服务器,提取数据了。
2、美团爬虫
2.1、如何提取json()数据?
json数据的模块拥有包含关系,它们的级别可以互相包含,拥有层次感,如:

具体提取和美化的方法可以转至我的另一篇博客学习 python爬虫爬取微博之战疫情用户评论及详情
2.2、正式爬取信息
import requests
from fake_useragent import UserAgent
for page in range(0, 371, 10):#0~100
url = "https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=2ff7056c-9d76-424c-b564-b7084f7e16e4&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset={}&pageSize=10&sortType=1".format(page)
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
respone = requests.get(url = url, headers = headers) #向服务器发出请求,服务器返回结果
for item in respone.json()['data']['comments']:#遍历,循环
userId = item['userId']
userName = item['userName']
avgPrice = item['avgPrice']
comment = item['comment']
merchantComment = item['merchantComment']
data = (userId, userName, avgPrice, comment, merchantComment)
print (data)
爬取到几条以后,它就这样报错了:

突然间就说找不到 data 了,这是为什么呢?来打印一下我们最后这一次请求看看结果:
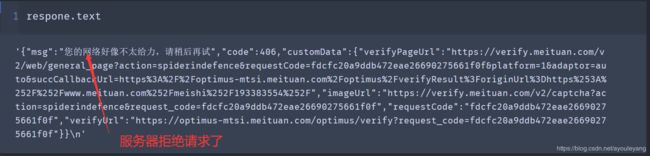
正常情况下,不可能上一个还是正常的,下一个网络就有问题的,推断应该是服务器已经识别出来这是一个爬虫程序在向它发起的请求,我们再来浏览器中打开它评论的这个页面来看看,发现它出现了一个验证码,我们输入验证码后重新请求,程序又可以正常跑一会儿,然后就会挂掉,估计是它禁止某个IP不断的访问它的信息,接下来去弄一堆 IP 代理来访问它试试
3、IP代理
下去爬一个 IP代理网站的 IP来供我们使用代理,具体方法可以到 学习python爬虫看一篇就足够了之爬取《太平洋汽车》论坛及点评实战爬虫大全 观看 第3部分:requests + IP代理 ,我在这里有详细的介绍,这个代码也是直接从那里复制过来的。
3.1、爬取存入CSV代码汇总
# https://www.meituan.com/meishi/193383554/ 商品链接
import requests, json, re, random, time, csv
from fake_useragent import UserAgent
starttime = time.time()#记录开始时间
ips = [] #装载有效 IP
for i in range(1, 6):
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_{}.html'.format(i)
html = requests.get(url=ip_url, headers=headers).text
res_re = html.replace(" ", "").replace("\n", "").replace("\t", "")
#使用正则表达式匹配出IP地址及端口
r = re.compile('(.*?) (.*?) ')
result = re.findall(r, res_re)
for i in range(len(result)):
ip = "http://" + result[i][0] + ":" + result[i][1]
# 设置为字典格式
proxies = {"http": ip}
#使用上面的IP代理请求百度,成功后状态码200
baidu = requests.get("https://www.baidu.com/", proxies = proxies)
if baidu.status_code == 200:
ips.append(proxies)
print ("正在准备IP代理,请稍后。。。")
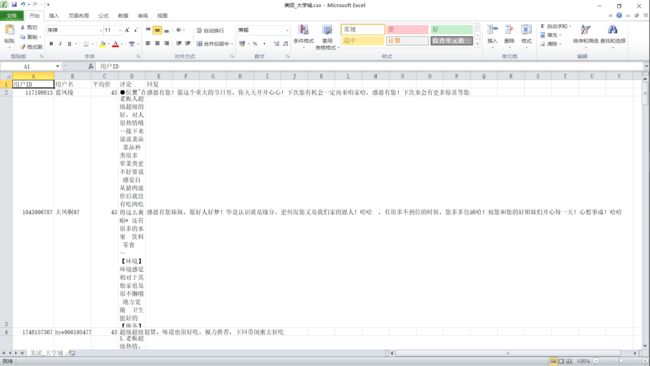
#创建CSV文件,并写入表头信息,并设置编码格式为“utf-8-sig”防止中文乱码
fp = open('./美团_大学城.csv','a', newline='',encoding='utf-8-sig') #"./"表示当前文件夹,"a"表示添加
writer = csv.writer(fp) #方式为写入
writer.writerow(('用户ID','用户名', '平均价','评论','回复')) #表头
for page in range(0, 371, 10):#0~100
url = 'https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=9f45527e-2983-40c9-bc92-f58a8290c947&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset={}&pageSize=10&sortType=1'.format(page)
try:
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
rep = requests.get(url=url, headers=headers, proxies=ips[random.randint(0 , len(ips)-1)])
print ("爬取条数:", page)
for info in rep.json()['data']['comments']:
userId = info['userId']
userName = info['userName']
avgPrice = info['avgPrice']
comment = info['comment']
merchantComment = info['merchantComment']
data = (userId, userName, avgPrice, comment, merchantComment)
writer.writerow((data))
except:
print ("这里发生异常:", url)
pass
fp.close() #关闭文件
endtime = time.time()#获取结束时间
sumTime = endtime - starttime #总的时间
print ("一共用的时间是%s秒"%sumTime)

3.1、爬取存入TXT代码汇总
# https://www.meituan.com/meishi/193383554/
import requests,json
from fake_useragent import UserAgent
import requests,re,random
from lxml import etree
from fake_useragent import UserAgent
ips = [] #建立数组,用于存放有效IP
for i in range(1,6):
print ("正在准备IP代理,请稍等。。。")
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_%s.html'%i
# 请求IP的网站,得到源码
res = requests.get(url=ip_url, headers=headers).text
res_re= res.replace('\n', '').replace('\t','').replace(' ','')
# 使用正则表达匹配出IP地址及它的端口
re_c = re.compile('(.*?) (.*?) ')
result = re.findall(re_c, res_re)
for i in range(len(result)):
#拼接出完整的IP
ip = 'http://' + result[i][0] + ':' + result[i][1]
# 设置为字典格式
proxies={"http":ip}
#使用上面爬取的IP代理请求百度
html = requests.get('https://www.baidu.com/', proxies=proxies)
if html.status_code == 200: #状态码为200,说明请求成功
ips.append(proxies) #添加进数组中
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
for page in range(0,371, 10):
url = 'https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=9f45527e-2983-40c9-bc92-f58a8290c947&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset={}&pageSize=10&sortType=1'.format(page)
try:
rep = requests.get(url=url, headers=headers, proxies=ips[random.randint(0 , len(ips)-1)])
print ("爬取条数:", page)
for info in rep.json()['data']['comments']:
with open("./美团文本.txt", "a", encoding='utf-8') as f:
comment = str(info['comment'])#评论
merchantComment = str(info['merchantComment'])#商家回复
f.write(comment)
f.write(merchantComment)
f.close()
except:
pass

4、词云流程
4.1、打开txt文本做词云图
# 导入包
import jieba #pip install jieba
from wordcloud import WordCloud #pip install wordcloud
4.1.1、对jieba分词的简单了解
精准模式:
#精准模式
cut_text = jieba.cut("信息管理与信息系统", cut_all=False) #False,精准;True,全能
cut_text = ' '.join(cut_text)
cut_text
'信息管理 与 信息系统'
全能模式:
cut_text = jieba.cut("信息管理与信息系统", cut_all=True) #False,精准;True,全能
cut_text = ' '.join(cut_text)
cut_text
4.1.2、词云基础
f = open("./美团文本.txt", "r", encoding="utf-8") #打开一个文本
txt = f.read()#读取文本内容
cut_text = jieba.cut(txt, cut_all=False) #False,精准;True,全能。# 结果为数组
cut_text = ' '.join(cut_text) #把数组拼接为字符串
word_cloud = WordCloud(font_path="C:/Windows/Fonts/simhei.ttf",
background_color="white",#背景
max_words=800, #画布字体个数
max_font_size=180,#最大字体
min_font_size=40,#最小字体
width=1920,
height=1080).generate(cut_text)#传入分词文本
#定义图片的画布
plt.figure(figsize=(16, 9))#设置画布大小
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
word_cloud.to_file('output.png')#保存图片
plt.show()#展示图片

4.1.3、加入背景图片

from wordcloud import WordCloud #导入词云库 pip install wordcloud
from wordcloud import ImageColorGenerator # 获取图片像素值
from matplotlib.image import imread #读取图片 #pip install matplotlib
import matplotlib.pyplot as plt #显示图片
import jieba.analyse #结巴分析,#pip install jieba
back_img = imread("bg_pic1.jpg") #读取图片
img_colors = ImageColorGenerator(back_img) # 生成图片的像素值
file = open("./美团文本.txt", encoding="utf-8")#打开一个文本
txt = file.read()#读取内容
# 第一个参数:待提取关键词的文本
# 第二个参数:返回关键词的数量,重要性从高到低排序
# 第三个参数:是否同时返回每个关键词的权重
# 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词,allowPOS=('ns', 'n', 'vn', 'v')表示选取地名、名词、动名词、动词
tags = jieba.analyse.extract_tags(txt, topK = 1000, withWeight = True, allowPOS=()) #使用结巴分析提取标签
data = {item[0]: item[1] for item in tags}#tags是数组形式,把数组转为词频字典
word_cloud = WordCloud(font_path="c:\windows\Fonts\simhei.ttf",#字体,本电脑c盘下的黑体,这样才能显示中文
background_color="white",#图片的背景颜色
max_words=1000,#字体个数,不超过上面选取的个数
max_font_size=100,#字体大小
width=1920,#图片像素宽
mask=back_img,#使用图片蒙板,上面读取图片的像素
height=1080).generate_from_frequencies(data)#传入上面的词频结果
file.close()#关闭上面打开的文件
wc_color = word_cloud.recolor(color_func=img_colors) # 替换默认的字体颜色
plt.figure(figsize=(12, 12)) # 创建一个图形实例,设置画布大小
plt.imshow(word_cloud, interpolation='bilinear')#插值='双线性'
plt.axis("off") # 不显示坐标尺寸
word_cloud.to_file('output1.png')#保存图片
plt.show()

4.2、打开CSV文本做词云图
我们在做词云图的时候,是对文本进行分词,再统计词频;对于储存在表格中的数据,我们可以先把它提取出来,再进行上面的操作就可以了.
#导入相关的包
import pandas as pd #导入pandas命名为pd #pip install pandas
from wordcloud import WordCloud #导入词云库 pip install wordcloud
from wordcloud import ImageColorGenerator # 获取图片像素值
from matplotlib.image import imread #读取图片 #pip install matplotlib
import matplotlib.pyplot as plt #显示图片
import jieba.analyse #结巴分析,#pip install jieba
4.2.1、导入数据
data = pd.read_csv("./美团_大学城.csv")#打开csv文件
data #运行可以直接显示表格
4.2.2、读取表格中的评论文本

4.2.2.1、单独把文本读取出来
for pl in data['评论']:
print (pl)

4.2.2.2、数据清洗
- str(pl) 把pl转化为字符串
- strip() 移除首尾的空格
- replace(“nan”, “”) 替换掉空值nan
- replace("\n", “”) 替换掉换行符
for pl in data['评论']:
comment = str(pl).strip().replace("nan", "").replace("\n", "")
print (comment)

4.3、转化为文本
- 创建一个空数组存遍历出来的评论和回复的信息
txts = [] #装所有的评论和回复
txts = []
for pl in data['评论']:
txts.append(str(pl).strip().replace("nan", "").replace("\n", ""))
for hf in data['回复']:
txts.append(str(hf).strip().replace("nan", "").replace("\n", ""))
#把上面的评论和回复转化成字符串
text = ' '.join(txts) #数组转字符串拼接的方法
print (text)

- 现在的文本已经去掉了换行和间隔, 可以直接使用上面的方法生成词云图了, 文本数据就在text中
from wordcloud import WordCloud #导入词云库 pip install wordcloud
from wordcloud import ImageColorGenerator # 获取图片像素值
from matplotlib.image import imread #读取图片 #pip install matplotlib
import matplotlib.pyplot as plt #显示图片
import jieba.analyse #结巴分析,#pip install jieba
back_img = imread("bg_pic1.jpg") #读取背景图片
img_colors = ImageColorGenerator(back_img) # 生成图片的像素值
# 第一个参数:待提取关键词的文本
# 第二个参数:返回关键词的数量,重要性从高到低排序
# 第三个参数:是否同时返回每个关键词的权重
# 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词,allowPOS=('ns', 'n', 'vn', 'v')表示选取地名、名词、动名词、动词
tags = jieba.analyse.extract_tags(text, topK = 1000, withWeight = True, allowPOS=()) #使用结巴分析提取标签
data = {item[0]: item[1] for item in tags}#tags是数组形式,把数组转为词频字典
word_cloud = WordCloud(font_path="c:\windows\Fonts\simhei.ttf",#字体,本电脑c盘下的黑体,这样才能显示中文
background_color="white",#图片的背景颜色
max_words=1000,#字体个数,不超过上面选取的个数
max_font_size=100,#字体大小
width=1920,#图片像素宽
mask=back_img,#使用图片蒙板,上面读取图片的像素
height=1080).generate_from_frequencies(data)#传入上面的词频结果
wc_color = word_cloud.recolor(color_func=img_colors) # 替换默认的字体颜色
plt.figure(figsize=(12, 12)) # 创建一个图形实例,设置画布大小
plt.imshow(word_cloud, interpolation='bilinear')#插值='双线性'
plt.axis("off") # 不显示坐标尺寸
word_cloud.to_file('output1.png')#保存图片
plt.show()

词云所用的数据全部来自于上面的爬虫,结果和 html流程文档 已经全部放在上面的链接中,需要的话可以自行下载使用
你可能感兴趣的:(爬虫项目实战)