你不得不看的leetcode常考题(四月份每日一题)——Python版本
四月的每日一题
四月开始进阶!
文章目录
- 四月的每日一题
- 1号——1111. 有效括号的嵌套深度
- 相关题目:20. 有效的括号
- 2号——289. 生命游戏
- 3号——8. 字符串转换整数 (atoi)
- 4号——42. 接雨水
- 5号——460. LFU缓存
- 6号——72. 编辑距离
- 7号——面试题 01.07. 旋转矩阵
- 8号——面试题13. 机器人的运动范围
- 9号——22. 括号生成
- 学习内容:回溯算法
- 10号——151. 翻转字符串里的单词
- 11号——887. 鸡蛋掉落
- 12号——面试题 16.03. 交点
- 13号——355. 设计推特
- 14号——445. 两数相加 II
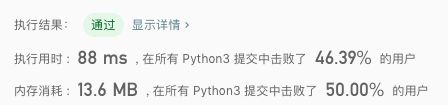
- 15号——542. 01 矩阵
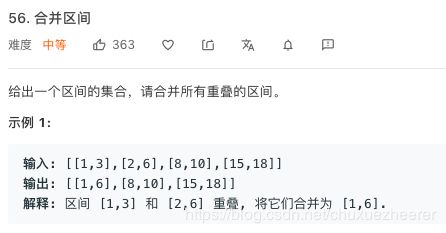
- 16号——56. 合并区间
- 17号——55. 跳跃游戏
- 18号——11. 盛最多水的容器
- 19号——466. 统计重复个数
- 20号——200. 岛屿数量
- 21号——1248. 统计「优美子数组」
- 22号——199. 二叉树的右视图
- 23号——面试题 08.11. 硬币
- 24号——面试题51. 数组中的逆序对
- 25号——46. 全排列
- 常见的回溯算法题
- 26号——23. 合并K个排序链表
- 27号——33. 搜索旋转排序数组
- 28号——面试题56 - I. 数组中数字出现的次数
- 29号——1095. 山脉数组中查找目标值
- 30号——202. 快乐数
1号——1111. 有效括号的嵌套深度

(这道题开始连题都没读懂…)
还是某位大佬在解析题目时说的明白:“一句话概括就是,给你一个合法的括号序列,你需要将其拆分成两个合法的子序列(不连续),使得两个子序列的括号嵌套深度较大者尽量的小。”
所以想法一就是用栈的思想来辅助,左括号的深度就是括号所在的深度,要想使最大的深度最小,就最好平分两个子序列的括号嵌套的深度。可以用奇偶来平分。
虽然用了栈的思想,但因为题目原因可以不用栈来进行实现。
class Solution:
def maxDepthAfterSplit(self, seq: str) -> List[int]:
res=[]
ans=0
for ch in seq:
if ch=="(":
ans+=1
res.append(ans%2)
elif ch==")":
res.append(ans%2)
ans-=1
return res
相关题目:20. 有效的括号
这道题是面试常见题型吧,既然做到了这里就再写一遍吧!
class Solution:
def isValid(self, s: str) -> bool:
dic = {'(':')','[':']','{':'}'}
stack = []
for ch in s:
if ch in dic:
stack.append(ch)
else:
if len(stack) == 0:
return False
elif ch == dic[stack.pop()]:
pass
else:
return False
return len(stack) == 0

2号——289. 生命游戏

这道题首先的想法是应用广度优先遍历,但难点是如何保证所有的结点同时变,就是变化后不影响后面的行为。
方法一:再复制一遍board表。
class Solution:
def gameOfLife(self, board: List[List[int]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
row=len(board)
line=len(board[0])
#这里注意深拷贝浅拷贝问题
copy_board = [[board[i][j] for j in range(line)] for i in range(row)]
for i in range(row):
for j in range(line):
live=0
for di,dj in [[0,1],[1,1],[1,0],[1,-1],[0,-1],[-1,-1],[-1,0],[-1,1]]:
cur_i=i+di
cur_j=j+dj
if 0<=cur_i<row and 0<=cur_j<line and copy_board[cur_i][cur_j]==1:
live+=1
#条件一,三
if copy_board[i][j]==1 and (live<2 or live>3):
board[i][j]=0
#条件四
if copy_board[i][j]==0 and live==3:
board[i][j]=1
这里有一个坑就是 copy_board = [[board[i][j] for j in range(line)] for i in range(row)],不能直接使用copy_board=board,这样就是浅拷贝了,两个对象指向了同一个空间,

或者可以使用语句:copy_board = copy.deepcopy(board)
3号——8. 字符串转换整数 (atoi)
这道题如果常规解法要考虑到的情况感觉好多,所以直接看了官方题解,学习到了状态机这个概念
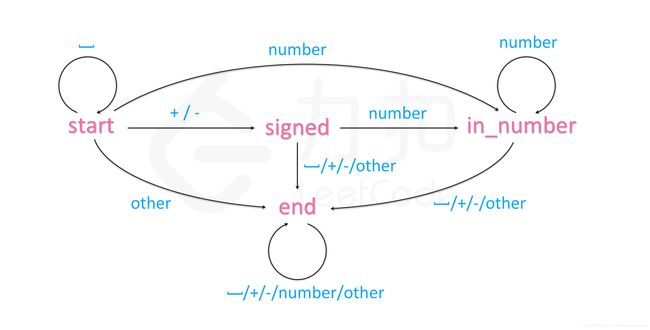
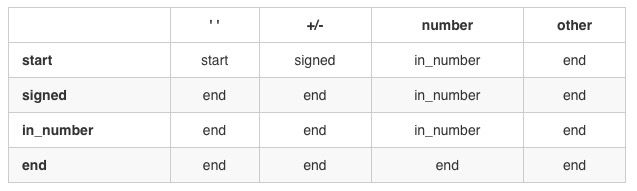
INT_MAX = 2 ** 31 - 1
INT_MIN = -2 ** 31
class Solution:
def myAtoi(self, str: str) -> int:
auto=Auto()
for c in str:
auto.get(c)
return auto.sign*auto.ans
class Auto:
def __init__(self):
self.state='start' #标记起始状态
self.sign=1 #符号位
self.ans=0
self.table={#状态机
'start':['start','signed','in_number','end'],
'signed':['end','end','in_number','end'],
'in_number':['end','end','in_number','end'],
'end':['end','end','end','end'],
}
def get_col(self,c):#根据题目输出几个状态
if c.isspace(): #空格状态
return 0
if c=='+' or c=='-':#正负号状态
return 1
if c.isdigit():
return 2
return 3
def get(self,c):
self.state=self.table[self.state][self.get_col(c)]
if self.state=='in_number':
self.ans=self.ans*10+int(c)
if self.sign==1:
self.ans=min(self.ans,INT_MAX)
else:
self.ans=min(self.ans,-INT_MIN)
elif self.state=='signed':
if c=='+':
self.sign=1
else:
self.sign=-1
4号——42. 接雨水
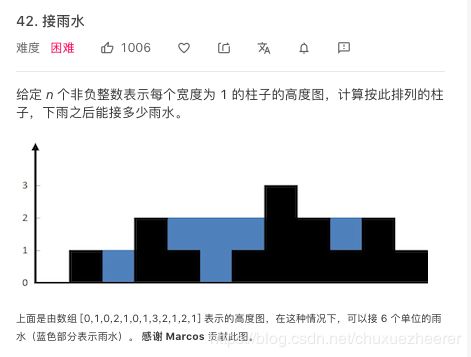
借鉴大佬的:
https://leetcode-cn.com/problems/trapping-rain-water/solution/dong-tai-gui-hua-shuang-zhi-zhen-tu-jie-by-ml-zimi/
方法一:暴力法
对每个位置判断左边的最高值和右边的最高值,然后如果两边的最低值大于这个位置的值,那么能储存的水量就是左右两边的最低值减去这个位置的值,然后不停的累加。
但是暴力破解Python会超时。
class Solution:
def trap(self, height: List[int]) -> int:
length=len(height)
res=0
for i in range(length):
max_left,max_right=0,0
for j in range(0,i):
max_left=max(max_left,height[j])
for j in range(i+1,length):
max_right=max(max_right,height[j])
min_num=min(max_left,max_right)
if height[i]<min_num:
res+=min_num-height[i]
return res
方法二:用空间换时间,弄两个数组分别记录该位置左边的最大值和右边的最大值。
class Solution:
def trap(self, height: List[int]) -> int:
if not height:
return 0
length=len(height)
max_left=[0]*length
max_right=[0]*length
res=0
#初始化
max_left[0]=height[0]
max_right[length-1]=height[length-1]
#开始对每个位置设计备忘录
for i in range(1,length):
max_left[i]=max(max_left[i-1],height[i])
for j in range(length-2,-1,-1):
max_right[j]=max(max_right[j+1],height[j])
#开始对每个位置计算可能存储的雨水量
for i in range(length):
if min(max_left[i],max_right[i])>height[i]:
res+=min(max_left[i],max_right[i])-height[i]
return res
方法三:双指针
双指针法原理,借鉴某位大佬写的内容感觉非常清楚

class Solution:
def trap(self, height: List[int]) -> int:
if not height:
return 0
length=len(height)
left=0
right=length-1
max_left=height[left]
max_right=height[right]
res=0
while left<=right:
max_left=max(max_left,height[left])
max_right=max(max_right,height[right])
if max_left<max_right:
res+=max_left-height[left]
left+=1
else:
res+=max_right-height[right]
right-=1
return res

5号——460. LFU缓存
表示今天的题不会…题解也还没有看懂,先把官方答案贴一下,再学学再看(哭泣…)
class Node:
def __init__(self, key, val, pre=None, nex=None, freq=0):
self.pre = pre
self.nex = nex
self.freq = freq
self.val = val
self.key = key
def insert(self, nex):
nex.pre = self
nex.nex = self.nex
self.nex.pre = nex
self.nex = nex
def create_linked_list():
head = Node(0, 0)
tail = Node(0, 0)
head.nex = tail
tail.pre = head
return (head, tail)
class LFUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.size = 0
self.minFreq = 0
self.freqMap = collections.defaultdict(create_linked_list)
self.keyMap = {}
def delete(self, node):
if node.pre:
node.pre.nex = node.nex
node.nex.pre = node.pre
if node.pre is self.freqMap[node.freq][0] and node.nex is self.freqMap[node.freq][-1]:
self.freqMap.pop(node.freq)
return node.key
def increase(self, node):
node.freq += 1
self.delete(node)
self.freqMap[node.freq][-1].pre.insert(node)
if node.freq == 1:
self.minFreq = 1
elif self.minFreq == node.freq - 1:
head, tail = self.freqMap[node.freq - 1]
if head.nex is tail:
self.minFreq = node.freq
def get(self, key: int) -> int:
if key in self.keyMap:
self.increase(self.keyMap[key])
return self.keyMap[key].val
return -1
def put(self, key: int, value: int) -> None:
if self.capacity != 0:
if key in self.keyMap:
node = self.keyMap[key]
node.val = value
else:
node = Node(key, value)
self.keyMap[key] = node
self.size += 1
if self.size > self.capacity:
self.size -= 1
deleted = self.delete(self.freqMap[self.minFreq][0].nex)
self.keyMap.pop(deleted)
self.increase(node)
(1)defaultdict()
当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0。

6号——72. 编辑距离

这是一道DP中的经典题型。鉴于这种菜鸡只能看着答案做了。
某位大佬的思路说的很清楚:


设有两个数组A、B,其实只有三种状态,在A中插入,在B中插入(等价于对A删除),修改A中的字符。
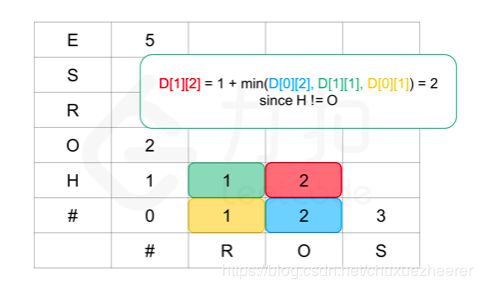
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
len1=len(word1)
len2=len(word2)
#如果有一个数组长度为0
if len1*len2==0:
return len1+len2
#创建DP数组,要多留一行一列出来存储初始状态
dp=[[0]*(len2+1) for _ in range(len1+1)]
#边界值情况
for i in range(len1+1):
dp[i][0]=i
for i in range(len2+1):
dp[0][i]=i
#开始进行DP数组迭代
for i in range(1,len1+1):
for j in range(1,len2+1):
if word1[i-1]==word2[j-1]:
dp[i][j]=1+min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1]-1)
else:
dp[i][j]=1+min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])
return dp[len1][len2]

7号——面试题 01.07. 旋转矩阵

方法一:复制一份原数组,然后根据复制的数组内容在原数组上进行操作。
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
if not matrix:
return matrix
row=len(matrix)
line=len(matrix[0])
copy_matrix=[[matrix[i][j] for j in range(line)] for i in range(row)]
mi=0
mj=0
for j in range(line):
for i in range(row-1,-1,-1):
matrix[mi][mj]=copy_matrix[i][j]
mj+=1
mi+=1
mj=0
return matrix
方法二:然后根据题意,原地旋转数组。

class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
n=len(matrix)
#开始旋转数组
for i in range(n//2):
for j in range((n+1)//2):#旋转单位,这里要考虑奇偶情况
#每一次旋转90度就是四个位置交换值
matrix[i][j],matrix[n-j-1][i],matrix[n-i-1][n-j-1],matrix[j][n-i-1]=matrix[n-j-1][i],matrix[n-i-1][n-j-1],matrix[j][n-i-1],matrix[i][j]

方法三:看官方题解,发现还有一种这样的方法

class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
n = len(matrix)
# 水平翻转
for i in range(n // 2):
for j in range(n):
matrix[i][j], matrix[n - i - 1][j] = matrix[n - i - 1][j], matrix[i][j]
# 主对角线翻转
for i in range(n):
for j in range(i):
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
(谜一样的lc时空结果…)
8号——面试题13. 机器人的运动范围

广度优先遍历
class Solution:
def sum_res(self,num):
res=0
while num:
res+=num%10
num=num//10
return res
def movingCount(self, m: int, n: int, k: int) -> int:
visited=set()#创建一个集合记录已经访问过的元素
queue=collections.deque()
queue.append((0,0))
while queue:
i,j=queue.popleft()
if (i,j) not in visited and self.sum_res(i)+self.sum_res(j)<=k:
visited.add((i,j))
for di,dj in [[1,0],[0,1]]:# 向右向下就行,左上角为(0,0)点
if 0<=i+di<m and 0<=j+dj<n:
queue.append((i+di,j+dj))
return len(visited)
深度优先遍历
class Solution:
def sum_res(self,num):
res=0
while num:
res+=num%10
num=num//10
return res
def movingCount(self, m: int, n: int, k: int) -> int:
def dfs(i,j):
if i==m or j==n or self.sum_res(i)+self.sum_res(j)>k or (i,j) in visited:
return #返回条件:到达边界值 or 和大于k or 结点已经被访问过了
visited.add((i,j))
dfs(i+1,j)
dfs(i,j+1) #递归,深度优先遍历
visited=set()
dfs(0,0)
return len(visited)

9号——22. 括号生成
明确合法字符串要求:
1、一个「合法」括号组合的左括号数量一定等于右括号数量,这个显而易见。
2、对于一个「合法」的括号字符串组合p,必然对于任何0 <= i < len§都有:子串p[0…i]中左括号的数量都大于或等于右括号的数量。
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res=[]
def backstrack(temp,left,right):
#结束条件
if len(temp)==2*n:
res.append("".join(temp))
return
#开始进行遍历
#可用的左括号left,可用的右括号right
if left<n:
#做选择
temp.append('(')
#下一轮决策
backstrack(temp,left+1,right)
#撤回
temp.pop()
#同理
if right<left:
temp.append(')')
backstrack(temp,left,right+1)
temp.pop()
backstrack([],0,0)
return res
学习内容:回溯算法
借鉴大佬的公众号内容:labuladong(套路讲的非常清楚,推荐!)
解决一个回溯问题,世纪上就是一个决策树的遍历过程。

我的另一篇博客:leetcode常见回溯算法题 Python版
10号——151. 翻转字符串里的单词

方法一,运用Python中的内置函数
class Solution:
def reverseWords(self, s: str) -> str:
return " ".join(reversed(s.split()))
方法二:向用trim()函数把除了单词之间的空格去掉,然后翻转所有的单词,然后再把每个小单词进行翻转。
class Solution:
#自定义去掉空格的初始化字符串
def trim_space(self,s)->list:
left,right=0,len(s)-1
#去掉头部空格
while left<=right and s[left]==" ":
left+=1
#去掉尾部空格
while left<=right and s[right]==" ":
right-=1
#去掉单词之间多余的空格
cur_s=[]
while left<=right:
#把不是空格的字母加入
if s[left]!=" ":
cur_s.append(s[left])
#如果cur_s最后一个字符不是空格,则加入一个空格。防止连续空格加入。
elif cur_s[-1]!=" ":
cur_s.append(s[left])
left+=1
return cur_s
def reverse(self,strs,left,right):
while left<right:
strs[left],strs[right]=strs[right],strs[left]
left+=1
right-=1
def reverse_word(self,strs):
start=0
end=0
n=len(strs)
#循环至末尾
while start<n:
#找一个单词的长度
while end<n and strs[end]!=" ":
end+=1
#翻转单词
self.reverse(strs,start,end-1)
#更新新的单词位置
start=end+1
end+=1
def reverseWords(self, s: str) -> str:
#获得初始化字符串
strs=self.trim_space(s)
#翻转整个字符串
self.reverse(strs,0,len(strs)-1)
#翻转每个内部单词
self.reverse_word(strs)
return "".join(strs)
方法三:
用栈的思想。遍历每个字符,若为不是空格的字符,则加入word[]中,遇到空格将word中的加入到queue的队列中,注意运用appendleft方法,然后word清空,准备存储下一个单词。
class Solution:
def reverseWords(self, s: str) -> str:
left,right=0,len(s)-1
#去掉开头的空格
while left<=right and s[left]==' ':
left+=1
#去掉结尾的空格
while left<=right and s[right]==' ':
right-=1
queue=collections.deque()
word=[]
#将单词push到头部
while left<=right:
#遇到空格,将word单词加入queue
if s[left]==' ' and word:
queue.appendleft("".join(word))
word=[]
#如果是字母,则加入word中
elif s[left]!=' ':
word.append(s[left])
left+=1
queue.appendleft("".join(word))
return " ".join(queue)
11号——887. 鸡蛋掉落

其实是要求至少要扔几次鸡蛋才能确定这个楼层F。
运用动态规划+二分搜索
具体题解借鉴:
leetcode官方题解
某位大佬的题解
class Solution:
def superEggDrop(self, K: int, N: int) -> int:
memo={}
def dp(k,n):
#如果没有在字典中,则加入字典中
if(k,n) not in memo:
#循环跳出条件
#如何在第0层
if n==0:
res=0
#如果只剩下了一个鸡蛋
elif k==1:
res=n
else:
low=1
high=n
#开始进行二分查找
while low+1<high:
#楼层
x=(low+high)//2
#如果碎了
t1=dp(k-1,x-1)
#如果没碎
t2=dp(k,n-x)
if t1<t2:
low=x
elif t1>t2:
high=x
else:
low=high=x
#状态转移方程式
res=1+min(max(dp(k-1,x-1),dp(k,n-x))
for x in (low,high))
memo[k,n]=res
return memo[k,n]
return dp(K,N)
12号——面试题 16.03. 交点

今天的题直奔官方题解了…
class Solution:
def intersection(self, start1: List[int], end1: List[int], start2: List[int], end2: List[int]) -> List[float]:
# 判断 (xk, yk) 是否在「线段」(x1, y1)~(x2, y2) 上
# 这里的前提是 (xk, yk) 一定在「直线」(x1, y1)~(x2, y2) 上
def inside(x1, y1, x2, y2, xk, yk):
# 若与 x 轴平行,只需要判断 x 的部分
# 若与 y 轴平行,只需要判断 y 的部分
# 若为普通线段,则都要判断
return (x1 == x2 or min(x1, x2) <= xk <= max(x1, x2)) and (y1 == y2 or min(y1, y2) <= yk <= max(y1, y2))
def update(ans, xk, yk):
# 将一个交点与当前 ans 中的结果进行比较
# 若更优则替换
return [xk, yk] if not ans or [xk, yk] < ans else ans
x1, y1 = start1
x2, y2 = end1
x3, y3 = start2
x4, y4 = end2
ans = list()
# 判断 (x1, y1)~(x2, y2) 和 (x3, y3)~(x4, y3) 是否平行
if (y4 - y3) * (x2 - x1) == (y2 - y1) * (x4 - x3):
# 若平行,则判断 (x3, y3) 是否在「直线」(x1, y1)~(x2, y2) 上
if (y2 - y1) * (x3 - x1) == (y3 - y1) * (x2 - x1):
# 判断 (x3, y3) 是否在「线段」(x1, y1)~(x2, y2) 上
if inside(x1, y1, x2, y2, x3, y3):
ans = update(ans, x3, y3)
# 判断 (x4, y4) 是否在「线段」(x1, y1)~(x2, y2) 上
if inside(x1, y1, x2, y2, x4, y4):
ans = update(ans, x4, y4)
# 判断 (x1, y1) 是否在「线段」(x3, y3)~(x4, y4) 上
if inside(x3, y3, x4, y4, x1, y1):
ans = update(ans, x1, y1)
# 判断 (x2, y2) 是否在「线段」(x3, y3)~(x4, y4) 上
if inside(x3, y3, x4, y4, x2, y2):
ans = update(ans, x2, y2)
# 在平行时,其余的所有情况都不会有交点
else:
# 联立方程得到 t1 和 t2 的值
t1 = (x3 * (y4 - y3) + y1 * (x4 - x3) - y3 * (x4 - x3) - x1 * (y4 - y3)) / ((x2 - x1) * (y4 - y3) - (x4 - x3) * (y2 - y1))
t2 = (x1 * (y2 - y1) + y3 * (x2 - x1) - y1 * (x2 - x1) - x3 * (y2 - y1)) / ((x4 - x3) * (y2 - y1) - (x2 - x1) * (y4 - y3))
# 判断 t1 和 t2 是否均在 [0, 1] 之间
if 0.0 <= t1 <= 1.0 and 0.0 <= t2 <= 1.0:
ans = [x1 + t1 * (x2 - x1), y1 + t1 * (y2 - y1)]
return ans
13号——355. 设计推特

class Twitter:
class Node:
def __init__(self):
#关注的人
self.followee=set()
#推特列表
self.tweet=list()
def __init__(self):
"""
Initialize your data structure here.
"""
self.time=0
self.recMax=10
self.tweetTime=dict()
self.user=dict()
def postTweet(self, userId: int, tweetId: int) -> None:
"""
Compose a new tweet.
"""
#如果没有这个用户,添加
if userId not in self.user:
self.user[userId]=Twitter.Node()
#把推特加入到特定的用户中去
self.user[userId].tweet.append(tweetId)
#维护推特时间列表
self.time+=1
self.tweetTime[tweetId]=self.time
def getNewsFeed(self, userId: int) -> List[int]:
"""
Retrieve the 10 most recent tweet ids in the user's news feed. Each item in the news feed must be posted by users who the user followed or by the user herself. Tweets must be ordered from most recent to least recent.
"""
if userId not in self.user:
return list()
#ans用来记录推特内容
#初始ans先记录自己的推特内容
ans=self.user[userId].tweet[-10:][::-1]
#开始对所有关注用户遍历
for followeeId in self.user[userId].followee:
if followeeId in self.user:
#取每个关注用户的10条推特,并且逆向输出
opt=self.user[followeeId].tweet[-10:][::-1]
i,j,combined=0,0,list()
#开始合并,时间越大的推特文章越新
while i <len(ans) and j<len(opt):
if self.tweetTime[ans[i]]>self.tweetTime[opt[j]]:
combined.append(ans[i])
i+=1
else:
combined.append(opt[j])
j+=1
#如果一个到头,那么把另一个剩下的都加进来
combined.extend(ans[i:])
combined.extend(opt[j:])
#更新ans为新的前10的文章
ans=combined[:10]
return ans
def follow(self, followerId: int, followeeId: int) -> None:
"""
Follower follows a followee. If the operation is invalid, it should be a no-op.
"""
#首先判断不是关注自己
if followerId !=followeeId:
if followerId not in self.user:
self.user[followerId]=Twitter.Node()
self.user[followerId].followee.add(followeeId)
def unfollow(self, followerId: int, followeeId: int) -> None:
"""
Follower unfollows a followee. If the operation is invalid, it should be a no-op.
"""
if followerId!=followeeId:
if followerId in self.user:
self.user[followerId].followee.discard(followeeId)
# Your Twitter object will be instantiated and called as such:
# obj = Twitter()
# obj.postTweet(userId,tweetId)
# param_2 = obj.getNewsFeed(userId)
# obj.follow(followerId,followeeId)
# obj.unfollow(followerId,followeeId)
14号——445. 两数相加 II

利用栈的特性
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
s1=[]
s2=[]
while l1:
s1.append(l1.val)
l1=l1.next
while l2:
s2.append(l2.val)
l2=l2.next
ans=None
#进位符号
preadd=0
while s1 or s2 or preadd!=0:
#a记录s1中出来的值
if not s1:
a=0
else:
a=s1.pop()
#b记录s2中出来的值
if not s2:
b=0
else:
b=s2.pop()
#求本位和
cur_num=a+b+preadd
#求进位数
preadd=cur_num//10
#求本位剩下的数字
node=cur_num%10
curNode=ListNode(node)
curNode.next=ans
ans=curNode
return ans
15号——542. 01 矩阵
用广度优先遍历的思想
class Solution:
def updateMatrix(self, matrix: List[List[int]]) -> List[List[int]]:
m=len(matrix)
if m==0:
return
n=len(matrix[0])
queue=collections.deque()
flag=set()
dist=[[0]*n for _ in range(m)]
for i in range(m):
for j in range(n):
if matrix[i][j]==0:
queue.append([i,j])
flag.add((i,j))
while queue:
i,j=queue.popleft()
for di,dj in [[i,j+1],[i,j-1],[i+1,j],[i-1,j]]:
if 0<=di<m and 0<=dj<n and (di,dj) not in flag:
dist[di][dj]=dist[i][j]+1
queue.append([di,dj])
flag.add((di,dj))
return dist

还有官方给的一种动态规划思想,就当学习了,我觉得我想不到==,…
class Solution:
def updateMatrix(self, matrix: List[List[int]]) -> List[List[int]]:
m, n = len(matrix), len(matrix[0])
# 初始化动态规划的数组,所有的距离值都设置为一个很大的数
dist = [[10**9] * n for _ in range(m)]
# 如果 (i, j) 的元素为 0,那么距离为 0
for i in range(m):
for j in range(n):
if matrix[i][j] == 0:
dist[i][j] = 0
# 只有 水平向左移动 和 竖直向上移动,注意动态规划的计算顺序
for i in range(m):
for j in range(n):
if i - 1 >= 0:
dist[i][j] = min(dist[i][j], dist[i - 1][j] + 1)
if j - 1 >= 0:
dist[i][j] = min(dist[i][j], dist[i][j - 1] + 1)
# 只有 水平向左移动 和 竖直向下移动,注意动态规划的计算顺序
for i in range(m - 1, -1, -1):
for j in range(n):
if i + 1 < m:
dist[i][j] = min(dist[i][j], dist[i + 1][j] + 1)
if j - 1 >= 0:
dist[i][j] = min(dist[i][j], dist[i][j - 1] + 1)
# 只有 水平向右移动 和 竖直向上移动,注意动态规划的计算顺序
for i in range(m):
for j in range(n - 1, -1, -1):
if i - 1 >= 0:
dist[i][j] = min(dist[i][j], dist[i - 1][j] + 1)
if j + 1 < n:
dist[i][j] = min(dist[i][j], dist[i][j + 1] + 1)
# 只有 水平向右移动 和 竖直向下移动,注意动态规划的计算顺序
for i in range(m - 1, -1, -1):
for j in range(n - 1, -1, -1):
if i + 1 < m:
dist[i][j] = min(dist[i][j], dist[i + 1][j] + 1)
if j + 1 < n:
dist[i][j] = min(dist[i][j], dist[i][j + 1] + 1)
return dist
16号——56. 合并区间
先将数组排序,设置一个辅助的结果列表,如果原列表没有重合就直接加入,有的话则新定义边界后加入。
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
#要先排序,不然后面情况会很多
intervals.sort(key=lambda x:x[0])
mergeList=[]
for interval in intervals:
#如果为空或者区间不重合,直接添加
if not mergeList or mergeList[-1][1]<interval[0]:
mergeList.append(interval)
#若区间重合
else:
mergeList[-1][0]=min(mergeList[-1][0],interval[0])
mergeList[-1][1]=max(mergeList[-1][1],interval[1])
return mergeList
17号——55. 跳跃游戏
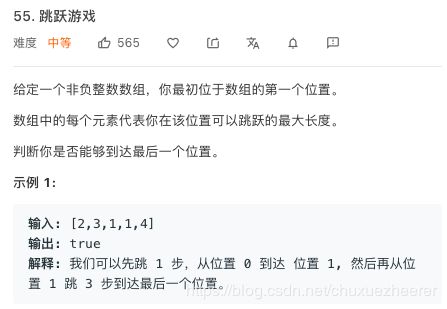
用贪心算法
class Solution:
def canJump(self, nums: List[int]) -> bool:
if not nums:
return False
n=len(nums)
max_distance=nums[0]
for i in range(n):
if i<=max_distance:
#更新所能到达的最远的值
max_distance=max(max_distance,i+nums[i])
if max_distance>=n-1:
return True
return False
18号——11. 盛最多水的容器

左右指针的方法:
class Solution:
def maxArea(self, height: List[int]) -> int:
length=len(height)-1
#左右指针
left,right=0,length
res=0
while left<right:
#记录过程中所得到的最大值
res=max(res,min(height[left],height[right])*(right-left))
#将高度小的指针左右缩近
if height[left]<height[right]:
left+=1
else:
right-=1
return res

19号——466. 统计重复个数
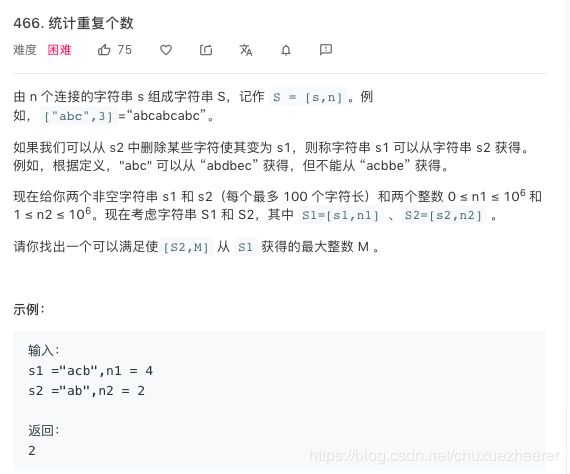
不会写,直接看题解解决问题==。
class Solution:
def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:
if n1 == 0:
return 0
s1cnt, index, s2cnt = 0, 0, 0
# recall 是我们用来找循环节的变量,它是一个哈希映射
# 我们如何找循环节?假设我们遍历了 s1cnt 个 s1,此时匹配到了第 s2cnt 个 s2 中的第 index 个字符
# 如果我们之前遍历了 s1cnt' 个 s1 时,匹配到的是第 s2cnt' 个 s2 中同样的第 index 个字符,那么就有循环节了
# 我们用 (s1cnt', s2cnt', index) 和 (s1cnt, s2cnt, index) 表示两次包含相同 index 的匹配结果
# 那么哈希映射中的键就是 index,值就是 (s1cnt', s2cnt') 这个二元组
# 循环节就是;
# - 前 s1cnt' 个 s1 包含了 s2cnt' 个 s2
# - 以后的每 (s1cnt - s1cnt') 个 s1 包含了 (s2cnt - s2cnt') 个 s2
# 那么还会剩下 (n1 - s1cnt') % (s1cnt - s1cnt') 个 s1, 我们对这些与 s2 进行暴力匹配
# 注意 s2 要从第 index 个字符开始匹配
recall = dict()
while True:
# 我们多遍历一个 s1,看看能不能找到循环节
s1cnt += 1
for ch in s1:
if ch == s2[index]:
index += 1
if index == len(s2):
s2cnt, index = s2cnt + 1, 0
# 还没有找到循环节,所有的 s1 就用完了
if s1cnt == n1:
return s2cnt // n2
# 出现了之前的 index,表示找到了循环节
if index in recall:
s1cnt_prime, s2cnt_prime = recall[index]
# 前 s1cnt' 个 s1 包含了 s2cnt' 个 s2
pre_loop = (s1cnt_prime, s2cnt_prime)
# 以后的每 (s1cnt - s1cnt') 个 s1 包含了 (s2cnt - s2cnt') 个 s2
in_loop = (s1cnt - s1cnt_prime, s2cnt - s2cnt_prime)
break
else:
recall[index] = (s1cnt, s2cnt)
# ans 存储的是 S1 包含的 s2 的数量,考虑的之前的 pre_loop 和 in_loop
ans = pre_loop[1] + (n1 - pre_loop[0]) // in_loop[0] * in_loop[1]
# S1 的末尾还剩下一些 s1,我们暴力进行匹配
rest = (n1 - pre_loop[0]) % in_loop[0]
for i in range(rest):
for ch in s1:
if ch == s2[index]:
index += 1
if index == len(s2):
ans, index = ans + 1, 0
# S1 包含 ans 个 s2,那么就包含 ans / n2 个 S2
return ans // n2
20号——200. 岛屿数量

这道题首先的常规解法,用BFS or DFS,
BFS:
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
if not grid:
return 0
line=len(grid)
row=len(grid[0])
queue=collections.deque()
res=0
for i in range(line):
for j in range(row):
#找出第一个为岛屿的地方
if grid[i][j]=='1':
res+=1
queue.append([i,j])
while queue:
li,lj=queue.popleft()
for di,dj in [[0,1],[0,-1],[-1,0],[1,0]]:
if 0<=li+di<line and 0<=lj+dj<row and grid[li+di][lj+dj]=='1':
#如果周围有岛屿,如队列,然后把该位置设置为0
grid[li+di][lj+dj]='0'
queue.append([li+di,lj+dj])
return res
DFS :
class Solution:
def dfs(self, grid, r, c):
grid[r][c] = 0
nr, nc = len(grid), len(grid[0])
for x, y in [(r - 1, c), (r + 1, c), (r, c - 1), (r, c + 1)]:
if 0 <= x < nr and 0 <= y < nc and grid[x][y] == "1":
self.dfs(grid, x, y)
def numIslands(self, grid: List[List[str]]) -> int:
nr = len(grid)
if nr == 0:
return 0
nc = len(grid[0])
num_islands = 0
for r in range(nr):
for c in range(nc):
if grid[r][c] == "1":
num_islands += 1
self.dfs(grid, r, c)
return num_islands
方法二,并查集
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
f={}
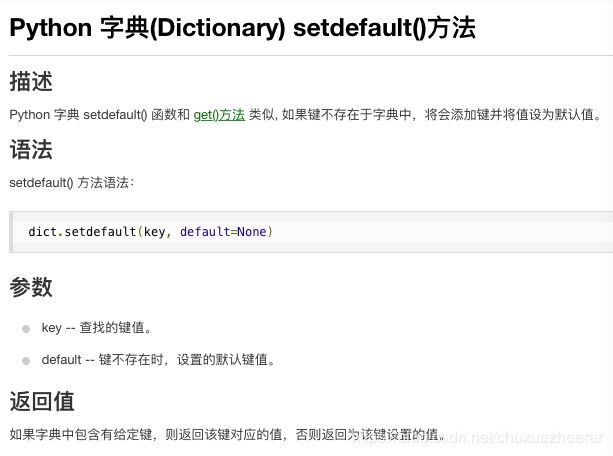
def find(x):
f.setdefault(x,x)
if f[x]!=x:
f[x]=find(f[x])
return f[x]
def union(x,y):
f[find(x)]=find(y)
if not grid:
return 0
row=len(grid)
line=len(grid[0])
for i in range(row):
for j in range(line):
if grid[i][j]=="1":
for x,y in [[-1,0],[0,-1]]:
cur_i=i+x
cur_j=j+y
if 0<=cur_i<row and 0<=cur_j<line and grid[cur_i][cur_j]=="1":
#开始算合并集
union(cur_i*row+cur_j,i*row+j)
res=set()
for i in range(row):
for j in range(line):
if grid[i][j]=="1":
res.add(find(i*row+j))
return len(res)
21号——1248. 统计「优美子数组」

方法一,我想的是用滑动窗口形式体现,我开始想的是弄两个指针(写了一半感觉非常麻烦),但看到官方题解,我才觉得果然是智商不够==。
用一个数组装入奇数的位置,符合条件的就是(当前奇数-左边前一个奇数位置)*(右边后一个奇数位置-右边奇数位置)。
class Solution:
def numberOfSubarrays(self, nums: List[int], k: int) -> int:
n=len(nums)
odd=[-1]
res=0
for i in range(n):
#将所有奇数位置入栈
if nums[i]%2==1:
odd.append(i)
odd.append(n)
#边界处理:在数组开头添加-1,结尾添加len(nums)
print(odd)
for i in range(1,len(odd)-k):
#左边的偶数(全不选也算一种情况)*右边的偶数(全不选也算一种情况)
res+=(odd[i]-odd[i-1])*(odd[i+k]-odd[i+k-1])
return res
22号——199. 二叉树的右视图
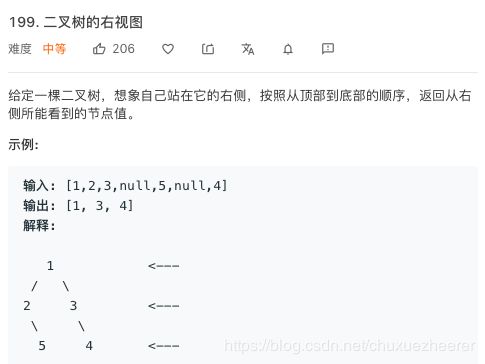
最先想到的就是树的层次遍历,输出每层最后一个结点。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def rightSideView(self, root: TreeNode) -> List[int]:
if not root:
return []
res=[]
queue=collections.deque()
queue.append(root)
while queue:
line=[]
res.append(queue[-1].val)
for node in queue:
if node.left:
line.append(node.left)
if node.right:
line.append(node.right)
queue=line
return res

23号——面试题 08.11. 硬币
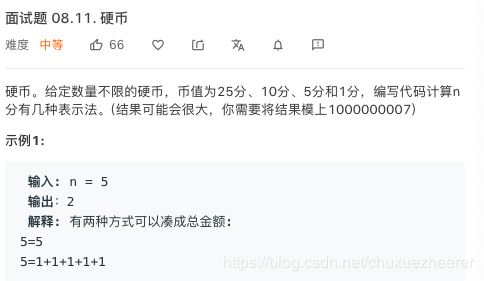
动态规划问题。
class Solution:
def waysToChange(self, n: int) -> int:
coins=[1,5,10,25]
dp=[0]*(n+1)
dp[0]=1
for coin in coins:
for i in range(coin,n+1):
dp[i]=dp[i]+dp[i-coin]
return dp[n]%1000000007
24号——面试题51. 数组中的逆序对
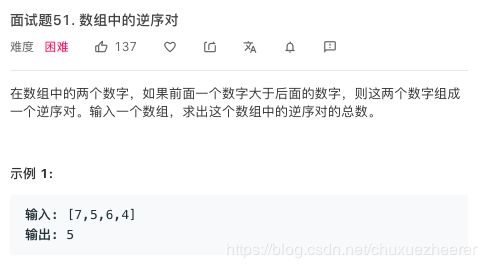
分治思想(借助归并排序统计逆序数):
class Solution:
def reversePairs(self, nums: List[int]) -> int:
self.res=0
#开始改变归并过,从中统计逆序数
def merge(nums,start,mid,end,temp):
#两个指针,分别指向前半部分和后半部分
i,j=start,mid+1
while i<=mid and j<=end:
if nums[i]<=nums[j]:
temp.append(nums[i])
i+=1
else:
#符合逆序数要求
#因为已经排过序,i到mid所有的数和j都可以构成逆序数
self.res+=mid-i+1
temp.append(nums[j])
j+=1
while i<=mid:
temp.append(nums[i])
i+=1
while j<=end:
temp.append(nums[j])
j+=1
#temp维护了一个从小到大的序列
for i in range(len(temp)):
#将已经判断过逆序数的位置排序
nums[start+i]=temp[i]
temp.clear()
def mergeSort(nums,start,end,temp):
#结束条件
if start>=end:
return
#开始进行归并排序
mid=(start+end)//2
mergeSort(nums,start,mid,temp)
mergeSort(nums,mid+1,end,temp)
merge(nums,start,mid,end,temp)
mergeSort(nums,0,len(nums)-1,[])
return self.res
25号——46. 全排列

回溯算法,把所有情况遍历出来。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
if not nums:
return nums
#记录路径
res=[]
def backtrack(nums,temp):
#触发条件
if not nums:
# 错误写法 result.append(tem_result[]) 这样把地址传入,后面回退的时候会是一堆空列表
res.append(temp[:])
n=len(nums)
for i in range(n):
#做选择
temp.append(nums[i])
#进入到下一层的决策树
backtrack(nums[:i]+nums[i+1:],temp)
#取消选择
temp.pop()
backtrack(nums,[])
return res
常见的回溯算法题
把这些写到了我另一章博客里
https://blog.csdn.net/chuxuezheerer/article/details/105406779
26号——23. 合并K个排序链表
方法一,用分治的思想
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def mergeKLists(self, lists: List[ListNode]) -> ListNode:
if not lists:return
n = len(lists)
return self.merge(lists, 0, n-1)
def merge(self,lists, left, right):
if left == right:
return lists[left]
mid = left + (right - left) // 2
l1 = self.merge(lists, left, mid)
l2 = self.merge(lists, mid+1, right)
return self.mergeTwoLists(l1, l2)
def mergeTwoLists(self,l1, l2):
if not l1:return l2
if not l2:return l1
if l1.val < l2.val:
l1.next = self.mergeTwoLists(l1.next, l2)
return l1
else:
l2.next = self.mergeTwoLists(l1, l2.next)
return l2

方法二:借助堆这个数据结构
class Solution:
def mergeKLists(self, lists: List[ListNode]) -> ListNode:
import heapq
#建立一个新的结点存储最后的信息
node=ListNode(0)
p=node
head=[]
#获得每个链表的头
for i in range(len(lists)):
if lists[i]:
heapq.heappush(head,(lists[i].val,i))
lists[i]=lists[i].next
#开始对每个链表结点进行操作
while head:
val,idx=heapq.heappop(head)
#p指针指向尾部
p.next=ListNode(val)
p=p.next
if lists[idx]:
heapq.heappush(head,(lists[idx].val,idx))
lists[idx]=lists[idx].next
return node.next
27号——33. 搜索旋转排序数组

一看算法复杂度要求是对数级别,所以首先想到的就是二分法
class Solution:
def search(self, nums: List[int], target: int) -> int:
if not nums:
return -1
left,right=0,len(nums)-1
while left<=right:
mid=(left+right)//2
#返回条件
if nums[mid]==target:
return mid
#根据条件缩小二分边界
if nums[0]<=nums[mid]:
if nums[0]<=target<nums[mid]:
right=mid-1
else:
left=mid+1
else:
if nums[mid]<target<=nums[len(nums)-1]:
left=mid+1
else:
right=mid-1
return -1
28号——面试题56 - I. 数组中数字出现的次数
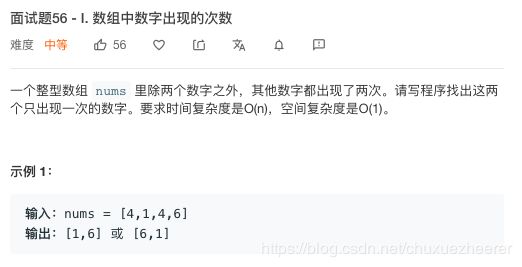
这里还是利用了异或的解题性质。两个相同的数异或为0,0和任何数字异或还是数字本身。这里的难点是会有两个不同的单个的数字,所以第一步,先将两个数字分到不同的组(利用某一位上不同来进行分组)。然后利用异或性质进行判断。
class Solution:
def singleNumbers(self, nums: List[int]) -> List[int]:
#异或结果
res=0
#分组异或
a,b=0,0
for num in nums:
res^=num
#开始找第一位不是零的数,也就是第一位两个数开始不同的位置
position=1
while res&position==0:
position<<=1
#开始分组
for num in nums:
if position&num==0:
a^=num
else:
b^=num
return [a,b]

29号——1095. 山脉数组中查找目标值

其实这道题本质还是运用二分查找。先找到峰顶的位置,然后对左对右进行二分查找。注意左、右区间递减递增顺序不同。
# """
# This is MountainArray's API interface.
# You should not implement it, or speculate about its implementation
# """
#class MountainArray:
# def get(self, index: int) -> int:
# def length(self) -> int:
class Solution:
def findInMountainArray(self, target: int, mountain_arr: 'MountainArray') -> int:
left,right=0,mountain_arr.length()-1
#记录最高峰位置
mount_idx=0
while left<=right:
mid=(left+right)//2
mid_val=mountain_arr.get(mid)
midleft_val=mountain_arr.get(mid-1)
midright_val=mountain_arr.get(mid+1)
#找到最高值
if midleft_val<mid_val and mid_val>midright_val:
mount_idx=mid
break
#如果不是最高值,继续二分寻找
if midleft_val>mid_val:
right=mid
else:
left=mid
#找到峰值后,开始两侧二分法找target
#左山峰查找,注意这个是递增区间
left,right=0,mount_idx
while left<=right:
mid=(left+right)//2
mid_val=mountain_arr.get(mid)
if mid_val==target:
return mid
elif mid_val>target:
right=mid-1
else:
left=mid+1
#右山峰查找,注意这个是递减区间
left,right=mount_idx,mountain_arr.length()-1
while left<=right:
mid=(left+right)//2
mid_val=mountain_arr.get(mid)
if mid_val==target:
return mid
elif mid_val<target:
right=mid-1
else:
left=mid+1
return -1
30号——202. 快乐数

方法一,暴力解法,用一个集合来记录是否有重复值。
class Solution:
def isHappy(self, n: int) -> bool:
if n<0:
return False
#集合,用来记录出现过的数
sets=set()
while n not in sets:
sets.add(n)
#记录每位平方和
sums=0
for num in str(n):
sums+=int(num)**2
if sums==1:
return True
#如果不符合,更新n
n=sums
return False

方法二,看评论区有大佬说,如果考虑集合数组非常大的话,是不合适的,一般判断数组有没有环路,用快慢指针进行实现。

class Solution:
def isHappy(self, n: int) -> bool:
slow_runner=n
fast_runner=self.get_next(n)
while fast_runner!=1 and slow_runner!=fast_runner:
#慢指针
slow_runner=self.get_next(slow_runner)
#快指针
fast_runner=self.get_next(self.get_next(fast_runner))
return fast_runner==1
def get_next(self,number):
total_sum=0
while number>0:
number,digit=divmod(number,10)
#相当于number=number//10,digit=number%10
total_sum+=digit**2
return total_sum
注:
python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。