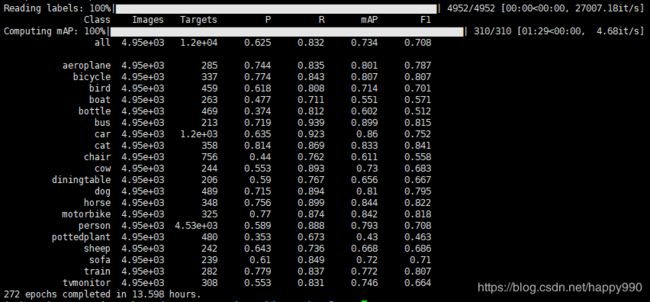
YOLOv3迁移学习并在VOC数据集上测试
服务器使用
远程连接
使用XShell与服务器建立SSH连接,配置好用户名和密码

环境配置
创建自己的python环境,为了方便,直接克隆base环境
conda create --name yzh-env --clone base
切换到自己的环境,并安装jupyter notebook
conda activate yzh-env
conda install jupyter notebook
启动jupyter notebook
jupyter notebook
因为服务器没有浏览器,所以需要将服务器端口映射到本地端口,然后在自己电脑上访问,可以使用XShell的隧道功能
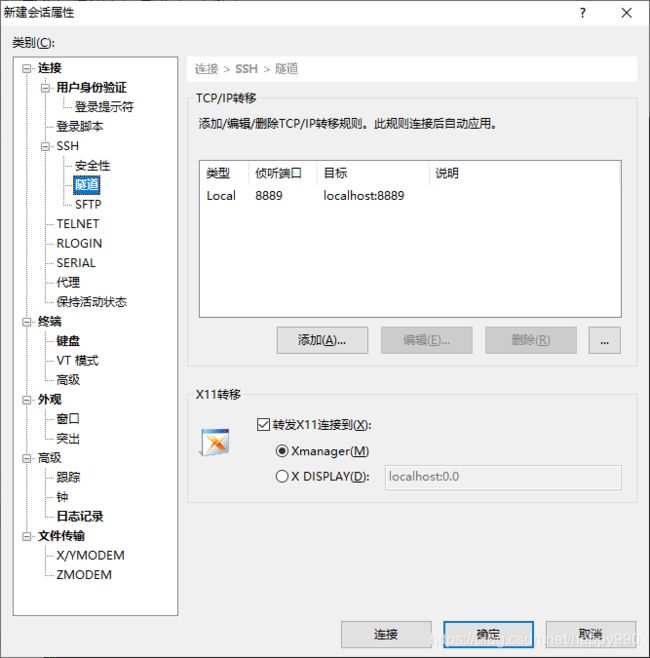
修改打开jupyter notebook的默认工作路径
jupyter notebook --generate-config
然后打开/.jupyter/jupyter_notebook_config.py,找到如下文字
`## The directory to use for notebooks and kernels.
#c.NotebookApp.notebook_dir = ''
修改为
`The directory to use for notebooks and kernels.
c.NotebookApp.notebook_dir = '/data3/yanpengxiang/shixun'
安装pytorch
## 不需要加官网的-c pytroch后缀,如果加了,就是指定从官方源下载,没有使用国内源conda install pytorch torchvision cudatoolkit=9.0
运行效果

工具使用
**Tmux **可用于在一个终端窗口中运行多个终端会话。不仅如此,还可以通过 Tmux 使终端会话运行于后台或是按需接入、断开会话,这个功能非常实用。
默认创建一个会话,以数字命名
tmux
新建会话,以“ccc”命名
tmux new -s ccc
查看创建的所有会话
tmux ls
登录一个已知会话
tmux a -t aaa
退出会话而不关闭
ctrl+b d
退出并关闭会话
ctrl+d
关闭会话
tmux kill-session -t bbb
YOLO网络
下载github上一个开源实现,作者是在COCO数据集上进行的训练,所以要下载coco数据集
git clone https://github.com/ultralytics/yolov3
bash yolov3/data/get_coco_dataset.sh
训练
python3 train.py
检测
python3 detect.py --cfg cfg/yolov3.cfg --weights weights/yolov3.weights
测试mAP
python3 test.py --weights weights/yolov3.weights
迁移学习
利用darknet/scripts/voc_label.py将VOC数据集的格式转换为训练darknet需要的格式,生成每张图片的label,保存在/labels文件夹下,图片在/JPEGImages文件夹中
-
每一张图片会有一个label文件(如果图片中没有对象,则不需要)
-
每一行表示一个物体
-
每一行的格式是
class x_center y_center width height -
Box 的坐标必须标准化到0-1之间
-
类的索引从0开始
创建一个文件data/VOC/voc.names,将voc的20个分类写入文件,每行一类

创建一个文件data/VOC/voc.data,指定类别数,训练集和测试集的位置等

修改网络结构,新建一个yolov3-voc.cfg。因为每一个YOLO层有255个输出(每个候选框85个输出 [4 box coordinates + 1 object confidence + 80 class confidences],有三个候选框)。而VOC只有20个类,所以要将YOLO层前一层的filter数量改为75,YOLO层的classes改为20。观察网络结构输出,只有三个YOLO层的梯度是激活的。
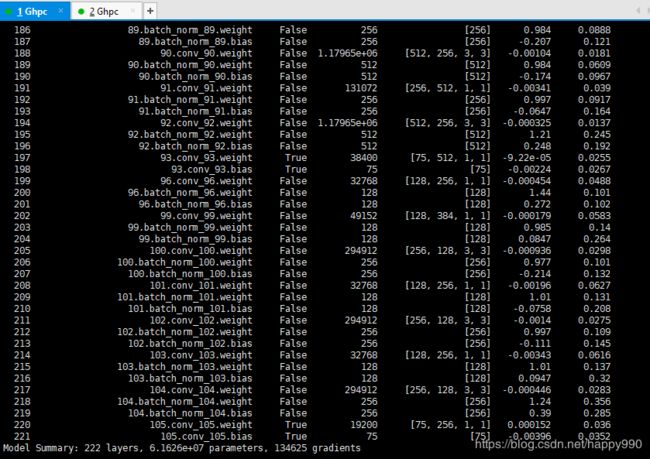
修改utils/dataset.py,因为VOC和coco的文件夹命名有一点不同
class LoadImagesAndLabels(Dataset): # for training/testing
def __init__(self, path, img_size=416, batch_size=16, augment=False):
with open(path, 'r') as f:
img_files = f.read().splitlines()
self.img_files = list(filter(lambda x: len(x) > 0, img_files))
n = len(self.img_files)
assert n > 0, 'No images found in %s' % path
self.img_size = img_size
self.augment = augment
self.label_files = [
# coco dataset
# x.replace('images', 'labels').replace('.bmp', '.txt').replace('.jpg', '.txt').replace('.png', '.txt')
# VOC dataset
x.replace('JPEGImages', 'labels').replace('.bmp', '.txt').replace('.jpg', '.txt').replace('.png', '.txt')
for x in self.img_files]
下载官方预训练权重weights/yolov3.pt,开始迁移训练
python3 train.py --transfer --cfg cfg/yolov3-voc.cfg --data data/VOC/voc.data
最终结果
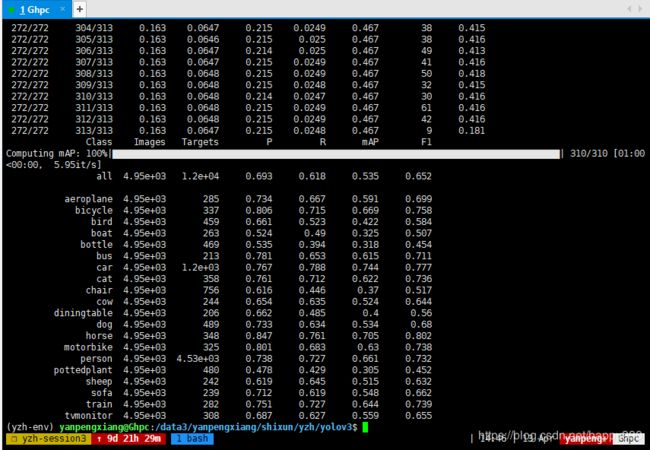
测试
python3 test.py --cfg cfg/yolov3-voc.cfg --data data/VOC/voc.data --weights weights/yolov3-voc.pt
检测
python3 detect.py --weights weights/latest.pt --cfg cfg/yolov3-voc.cfg --data-cfg data/VOC/voc.data

代码分析
网络结构
yolov3.cfg定义了YOLOv3的网络结构,由若干个block组成。在YOLO中有五种类型的layer。
第一个block类型是Net,它不算一个layer,只是描述了网络的输入尺寸以及一些超参数的值。
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=16
subdivisions=1
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
第二种类型是convolutional,它定义了卷积层的一些参数,filter的个数,大小,步长,padding,激活函数
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
第三种类型是shortcut,就是用于ResNet的捷径连接,from=-3表示这一层的输出是将前一层和向前数第三层的输出加起来
[shortcut]
from=-3
activation=linear
第四种类型是upsample,即上采样层,stride表示步长,使用双线性上采样
[upsample]
stride=2
第五种类型是route层,layer参数如果是一个,将会直接拷贝该层的输出,如果是两个参数,会将两层的输出在深度上进行concatenate
[route]
layers = -4
[route]
layers = -1, 61
最后一个类型是YOLO,它是网络的检测层,anchors描述了9个anchors,但是只有mask指定的anchors会被使用。因为yolo每个cell只生成3个box,但是会在三个不同的尺度进行预测,所以总共有三个yolo层,每个层使用不同的anchor size。
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
在models.py中对cfg文件进行解析并组合成yolov3的pytorch模型。总体结构如下图,输入的尺寸是416x416,预测的三个特征层大小分别是52,26,13,输出的预测结果是 3 ∗ ( 4 + 1 + 80 ) = 255 3*(4+1+80)=255 3∗(4+1+80)=255 。

训练代码
训练的代码在train.py中。首先设置训练集的路径,然后创建模型,设置学习率和优化器。
# Initialize model
model = Darknet(cfg, img_size).to(device)
# Optimizer
lr0 = 0.001 # initial learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr0, momentum=0.9, weight_decay=0.0005)
# Set scheduler (reduce lr at epochs 218, 245, i.e. batches 400k, 450k)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[218, 245], gamma=0.1, last_epoch=start_epoch - 1)
加载在ImageNet上预训练好的Imagenet模型。YOLOv3使用在Imagenet上预训练好的模型参数(文件名称: darknet53.conv.74,大小76MB)基础上继续训练。
cutoff = load_darknet_weights(model, weights + 'darknet53.conv.74')
加载数据集
# Configure run
train_path = parse_data_cfg(data_cfg)['train']
# Dataset
dataset = LoadImagesAndLabels(train_path, img_size=img_size, augment=True)
在每一次迭代中,进行预测,计算loss,反向传播
for i, (imgs, targets, _, _) in enumerate(dataloader):
imgs = imgs.to(device)
targets = targets.to(device)
# Run model
pred = model(imgs)
# Build targets
target_list = build_targets(model, targets)
# Compute loss
loss, loss_dict = compute_loss(pred, target_list)
# Compute gradient
loss.backward()
测试代码
测试代码在test.py中
for batch_i, (imgs, targets, paths, shapes) in enumerate(tqdm(dataloader, desc='Computing mAP')):
targets = targets.to(device)
imgs = imgs.to(device)
# Run model
inf_out, train_out = model(imgs) # inference and training outputs
# Build targets
target_list = build_targets(model, targets)
# Compute loss
loss_i, _ = compute_loss(train_out, target_list)
loss += loss_i.item()
# Run NMS
output = non_max_suppression(inf_out, conf_thres=conf_thres, nms_thres=nms_thres)
计算每一类的ap,求平均值即可得到mAP
# Compute statistics
stats_np = [np.concatenate(x, 0) for x in list(zip(*stats))]
nt = np.bincount(stats_np[3].astype(np.int64), minlength=nc) # number of targets per class
if len(stats_np):
p, r, ap, f1, ap_class = ap_per_class(*stats_np)
mp, mr, map, mf1 = p.mean(), r.mean(), ap.mean(), f1.mean()
检测代码
检测代码在detect.py中,加载已经训练好的模型进行检测。
# Initialize model
model = Darknet(cfg, img_size)
# Load weights
if weights.endswith('.pt'): # pytorch format
model.load_state_dict(torch.load(weights, map_location=device)['model'])
else: # darknet format
_ = load_darknet_weights(model, weights)
model.to(device).eval()
对于每张图片,送入模型得到输出,在屏幕显示类别,在图片上显示检测框。
for i, (path, img, im0, vid_cap) in enumerate(dataloader):
# Get detections
img = torch.from_numpy(img).unsqueeze(0).to(device)
pred, _ = model(img)
detections = non_max_suppression(pred, conf_thres, nms_thres)[0]
if detections is not None and len(detections) > 0:
# Rescale boxes from 416 to true image size
scale_coords(img_size, detections[:, :4], im0.shape).round()
# Print results to screen
for c in detections[:, -1].unique():
n = (detections[:, -1] == c).sum()
print('%g %ss' % (n, classes[int(c)]), end=', ')
# Draw bounding boxes and labels of detections
for *xyxy, conf, cls_conf, cls in detections:
if save_txt: # Write to file
with open(save_path + '.txt', 'a') as file:
file.write(('%g ' * 6 + '\n') % (*xyxy, cls, conf))
# Add bbox to the image
label = '%s %.2f' % (classes[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)])
print('Done. (%.3fs)' % (time.time() - t))
加入Focal Loss
训练结果