【CCAI 2016】微软、腾讯、头条、清北专家解析机器学习的局限与明天
8月26日至27日,在中国科学技术协会、中国科学院的指导下,由中国人工智能学会发起主办、中科院自动化研究所与CSDN共同承办的2016中国人工智能大会(CCAI 2016)在北京辽宁大厦盛大召开,这也是本年度国内人工智能领域规模最大、规格最高的学术和技术盛会,对于我国人工智能领域的研究及应用发展有着极大的推进作用。大会由CSDN网站进行专题直播,并由百度开放云提供独家视频直播技术支持。
本次大会除了邀请8位全球顶级人工智能专家详细解读当前人工智能领域的热门/前沿研究,还设置了4大专题论坛,邀请近30位学术界和产业界的专家共同探讨人工智能的技术趋势与实践经验。27日下午第二个专题论坛是“机器学习的明天论坛”,今日头条科学家李磊、北京大学信息科学技术学院机器感知与智能教育部重点实验室教授林宙辰、腾讯AI Lab计算机视觉组负责人刘威、微软亚洲研究院首席研究员刘铁岩、清华大学计算机科学与技术系特别研究员朱军五位分别来自工业界和学术界的嘉宾就机器学习的明天进行了分享,并在讨论环节,对在场观众提出的关于深度学习、自动驾驶等问题进行了解答回复。
本次分论坛由滴滴研究院副院长叶杰平和第四范式创始人&CEO戴文渊担任共同主席。
在论坛开场之初,戴文渊引出主题:机器学习的明天是一个很难的问题,公众关心更多的可能是机器学习或深度学习,以及随阿法狗出现火起来的强化深度学习。机器学习的明天很可能是今天大家看来是一个冷板凳的领域,正如20年前的深度学习。因此今天要谈的明天的机器学习,戴文渊认为一定不是深度学习。因此,本次论坛要探讨的很可能是一个在大家看来会觉得离应用很远、很不现实的事物,但是很可能会成为十年后重要机器学习方向之一。

今日头条李磊:会思考的通用智能机器还有多远?
今日头条科学家、头条实验室总监李磊带来的演讲是《会思考的通用智能机器还有多远?》。在演讲中,李磊主要对人工智能是什么?人工智能发展到什么程度以及面临的挑战三个方面进行了阐述,李磊首先阐述了对人工智能的两种定义:类人智能和理性智能。类人智能的目标是让机器像人那样思考、决策、解决问题,具备学习能力和行动能力。理性智能是研究如何通过计算方法达到合理的感知、决策、解决问题、学习和行为能力。不是和人去比较,而是把计算看成自然现象。
人工智能要研究的内容十分广泛,包括知识表示、形式化推理、规划与决策、机器学习、理解文字、自然语言(人类语言)、语音识别与合成、理解图像、视觉感知以及机器人控制。目前人工智能在某些具体任务上达到或超过人类能力,但通用型智能还有漫漫长路。
李磊介绍到头条最近发布了一款奥运机器人,可以在奥运期间自动发布了450条新闻。他谈到经过过去多次的实践证明:深度学习加大数据可以较好地解决监督学习的问题。
深度学习从人脑解决问题的的思路出发,创造了人工神经网络和人工神经单元的概念,随着层数的加深,神经网络能够完成一些合理对话之类的任务。但是仍需注意人工智能和机器学习不仅仅是监督学习和深度学习,要解决的问题其实更多,目前的深度学习还有很大的局限性,例如依赖大量标注数据,并且这些数据的获取代价非常高;此外,目前的深度学习的通用性还不够强。
最后,李磊总结了明天机器学习需要突破的三个方面:
- 需要有可解释性的机器学习,当机器学习模型成功和失败的时候,需要知道它成功或者失败的原因;
- 机器学习能够做更多的推理,而不仅仅是简单的判断;
- 过去做深度学习时需要很多的计算集群,需要耗费大量的能力,未来的是否可以实现在不影响性能的情况下实现单位能耗呢?
林宙辰:机器学习一阶优化算法
北京大学信息科学技术学院机器感知与智能教育部重点实验室教授林宙辰带来的分享是 《机器学习一阶优化算法》。他主要分享了机器学习在过去、现在、未来的优化方面的问题。从上个世纪90年代,优化技术就已经发展的比较完备了。在此之前,可以划分为两个阶段,第一阶段到上世界60年代,此前的优化方法较为缓慢;在60年代到90年代,随着计算机的发明,有着很大进展。
按照当时所用信息类别可以划分为三类:
- 第一类是只用目标函数的方法;
- 第二类是一阶的方法,也就是目标函数和梯度方法;
- 第三类是二阶方法,如Newton’s Methods、Sequential Quadratic Programming、Interior Point Methods。

接着,林宙辰谈到了选择一阶方法的两个原因,并认为一阶的方法是机器学习里面一个主流的学习方法。
- 因为一阶方法对数字精度的要求不太高;
- 一阶方法的存储和和计算的成本较低。
从90年代到现在,主要是对一些现有的方法进行复兴和更好的改进。接着,他总结了一阶方法从过去到现在的研究进展,主要包括六个方面:
- Smooth -> Nonsmooth:光滑可以对每一个点选一个梯度,选非光滑就不能选梯度,那么次梯度就比较慢,现在就是使用Proximal;
- Convex -> Nonconvex:首先一般只能证明非真的,如果好一点就每个据点都会收到临界点上面,2012年开始有一个非常好的理论突破,就是把这个几何理论引入到优化里面,常用的函数基本都属于这种函数类型;
- Deterministic -> Stochastic:在大数据情况下,很难能够有计算量支持确定性,所以只能随机抽取一些样本来算,2013年张老师提出来方差下降,可以进行加速;
- One/Two Blocks -> Multiple Blocks:如果是一个或者两个Block可以作为一个交界;
- Synchronous -> Asynchronous:同步会导致很多机器要等着其他的机器算完之后才能进行分析,所以需要异步;
- Convergence & Convergence Rate:Convergence Rate分析方面有更好的技术,尤其是加速差值技巧。
演讲结尾,林宙辰表示,未来的机器研究方面会集中在两个方向:
- 计算的规模会进一步增加,需要采用完全随机的方式进行,否则大数据之下是无法完成这些计算的;
- 利用量子计算的方法来参与规划,可以在两个层面进行:
- 将传统的算法每个步骤进行量子化;
- 在整体上设计量子的算法。
刘威:机器学习的明天会更好
腾讯AI Lab计算机视觉组负责人刘威带来的分享是《机器学习的明天会更好》。他首先讲解了机器学习的概念:机器学习通过历史数据学习映射函数–输入数据到输出决策的关系。其中决策有多重结构和角度。分享中,他提到机器学习大致可以分为浅层和深层机器学习,其中浅度学习主流方法主要Logistic Regression, SVM, Boosting 等,但浅度学习只能描述相对简单的映射关系:手工设计数据的特征表示,使用浅层网络。但浅层学习并没有死亡,还有很多方面值得深入研究下去,如:
- 超大规模学习:parameter server
- 聪明地构建 F (x ): (structured) sparsity, low-rank
- 随机优化算法: SGD, Newton
- 组合优化问题:hashing, bipartite matching, TSP
- 不做独立同分布假设:transfer learning
谈到机器学习的未来到底是不是深度学习?刘威认为深度学习可能是机器学习未来的曙光,有了这个曙光之后,很度现在无法完成任务可以得到实现。因此深度学习目前和未来的探索应该放在更深的网络上,因为只有用更深的网络才能建模更复杂的映射,处理更有挑战的问题、更广的应用;另外还需要推出更强的优化算法和推广性证明——如何能够对深度学习做更强的理论的干预,将更加确定深度学习就是未来的曙光;如果不能证明,则深度学习是一个很错误的道路。

紧着,刘威通过对计算机视觉的案例分析,进一步解读深度学习和浅度学习。对比传统计算机视觉,基于深度学习的计算机视觉可以全自动学习更有价值的图像特征,同时卷积神经网络算法的突破导致物体识别精度大幅上升,到2015年错误率降低到3.57%,直接解决了此类问题。同时卷积神经网络一直在深度进化,算法和工程能力的不断提升,从2012年到2016年,层次完成了从8层到1001层的巨大飞跃。
刘威最后表示:机器学习的明天一定会更好。
刘铁岩:破解机器学习的阿喀琉斯之踵
微软亚洲研究院首席研究员刘铁岩本次带来的分享是《Addressing Achilles’ Heel of Machine Learning》。他认为要想很好的回答未来“机器学习的明天”这个问题,首先需要理解目前机器学习繁荣背后存在的隐患和软肋。只有清楚当前的问题才能明确未来发展的方向。

接着,刘铁岩谈到了最近人工智能领域有突破性进展的几个例子,如阿尔法狗战胜李世石等。在繁荣的AI背后,可以通过上图所示的公式描述常做的机器学习。其中X表示采集样本、Y表示样本标签,定义了某种学习机制、L代表损失函数,可以通过某种高效优化算法尽量小的减少损失。此后,他谈到机器学习在最近成功的的三个因素:前所未有大数据、复杂的机器学习模型和云计算的能力。
但这三个因素带来便利的同时,也带来了挑战。
- 首先是大数据,标注大数据是一件非常非常代价高的事情,并不是所有的领域都有这个能力;
- 其次,大的模型表达能力是很强,但同时也非常难以优化,甚至有时模型的大小会超出你的运算设备内存;
- 此外,购买一个计算机机器集群可能比较容易的事,但将复杂的机器学习任务部署在集群上,并保证运算是没有精度损失绝非易事。如果这些方面的技术保证没有突破,其实机器学习会被这些大数据和大模型所绑架。
微软研究院研究人员的主要做法:
- 在没有大量标注数据时,利用相反的思想,从一个无标签数据出发制造一个伪标签,从标签出发造一个伪数据,通过互相博弈的过程生成网络,然后大量甚至无节制地生成训练样本,某种程度解决了样本不足的问题。
- 当有了足够的训练数据后,需要采用深度神经网络训练处有效的模型,针对训练层数高,导致训练不充分,残差消减的问题,可以采用增加线性通路使梯度传播比较通畅地达到顶层。
刘铁岩针对大数据量的并行运算同步等其他问题也给出了相应的回答。
未来,刘铁岩表示微软研究院会将机器学习的研究成果逐步通过开源项目展示给大众。
朱军:交互式机器学习
清华大学计算机科学与技术系特别研究员朱军带来的分享主题是《交互式机器学习》。分享中,他首先介绍了机器学习的现状,他表示,目前机器学习处于一个上升时期,因此未来机器学习会有一个很好的发展前景。目前的机器学习是数据驱动的统计机器学习,尽管深度学习在2006年取得突破,但机器学习仍然面临很多困难:
- 首先,机器学习的过程需要大量的专家知识;
- 其次成为有经验的研究生需要训练3-5年,专家需要5-10年;
- 此外,机器学习被掌握(局限)在专家和专业的开发者手中。
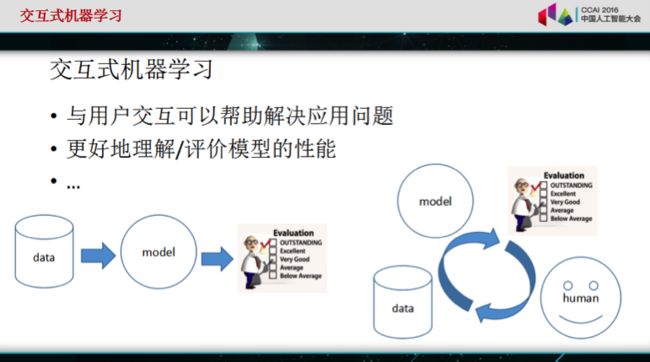
紧接着,朱军表示交互式机器学习可能可以解决机器学习面临的问题:
- 与用户交互可以帮助解决应用问题;
- 交互可以更好地理解/评价模型的性能。
分享中,他总结了目前交互式机器学习中关键问题:
- 模型应该是易于理解、易于交互;
- 这个模型可以接受用户的反馈模型和学习算法;
- 需要具有即使相应的高效算法;
- 对数据噪声的鲁棒性以及从小样本中学习的能力都需要考虑进来。
然后,朱军展示了他和他的团队在交互式学习方面尝试的结果。其中很重要的一点是信息的可视化,通过主题模型对文本进行处理,将学习到的结果在界面上展示出来,用户也可以有反馈互动。此外,朱军提到,在交互过程中,我们是希望获取知识,也就是众包学习问题。一个大规模的需要收集图片高质量标注的任务,可以采用众包标注的方法,例如在世界各国上网的用户都可以写标准,大大减少了工作难度。
朱军最后表示:正在向大家走近的交互机器学习是一个很重要的机器学习方法,我们需要做的是如何更好地实现交互和更好地学习。
机器学习的弱点与明天
在最后的讨论环节,全体嘉宾围绕机器学习的技术与应用问题进行讨论,并回答了现场观众的问题。这里精选部分问答如下。

戴文渊:从各位专家的角度来看,现在的机器学习的算法存在哪些弱点,以及这些弱点该用哪些思路解决呢?
李磊:对于大量的标注数据,在标注的过程中存在很多问题,要解决这个问题,通过部分标注数据,通过更多的逻辑让机器学习能够在过程中学会推理,去做更复杂的问题。
朱军:当前机器学习很关心的一个方面应该是机器学习方法本身,现在机器学习没有考虑如何能够有效地把学习方法用到解决各种具体问题中,解决思路我认为:除了数据之外还要用到逻辑,从某一方面提升学习有效性和效率。
刘铁岩:在深度学习变的很普通之前,机器学习是一个高大上的领域,比如怎么懂得定义特别好的模型结构,是专家才懂得事情;有了深度学习之后,这件事变成一个高富帅的事情,只要有钱就能做,因为深度学习的技术已经可以不用一个特别复杂、自行设计的网络结构,只要有足够的计算能力就可以。从某种意义讲深度学习给机器学习带来一个希望:将高高在上事物拉入人间。但深度学习并不够,它只解决了表达学习的问题,但在参数调优、运算上都还有不足。
刘威:机器学习的挑战或者难点,我更加欣赏“快”。用户不知道机器学习有多强大,他们最直观的反应是延迟有多短。因此快是一个侧重点,但不能丢掉其他条件,例如安全性。
叶杰平:以后两到三年,机器学习的发展方向?
林宙辰:在今后,对于算法的学习性还要加强,在算法整体上面来进行设计规划。
刘威:我觉得还是要以用户为主,用户喜欢什么,我们就做什么,向更快、更高、更强发展。因为在未来2-3年,我们会更加注重收集用户的数据,提高用户的社交体验、丰富用户的社交娱乐、更加精准推荐等。
刘铁岩:我觉得大家现在热捧的深度学习其实只是小荷才露尖尖角,其实机器学习的流程很复杂,整个机器学习是一个很复杂的流程,深度学习其实只是非常小的一个步骤。所以我所在的研究所接下来几年会做一件事情,就是希望用机器学习自己的思想去解决机器学习所有的自动化的问题,有一天如果机器学习真的可以不用人干预,从数据采集到数据的输入到特征抽取,再到模型优化参数学习超参数学习,所有的事情都能自动化进行,才是人工智能该骄傲的那一天。
朱军:刚才所讲的,人在其中是不可能很容易就被完全替换到的,至少在我关心的问题和关系的领域内是需要人的干预和引导的。因此我感兴趣的方向是交互式的机器学习,在一定层次上机器可以降低工作量,但是在关键领域,人还是非常重要是需要考虑的因素。
提问:刚才嘉宾有讲到医疗行业对错误的容忍度是很低的,那么各位专家认为哪些行业会给机器学习成长的时间?在哪些行业能够得到快速的广泛应用?
刘威:对于人工智能或者机器人容忍度多强或者能不能商用,先不谈商业化的问题,我们不在乎速度多慢或者耗费多少资源、成本。但这确实很难,从2011年至今,AI都都很难做到一个商用的状态。但按照中国国情来说,做与老百姓衣食住行相关的机器学习更容易,例如打车来晚一点,也能可以容忍的买。
林宙辰:有很多行业,如果把人工智能作为辅助手段,而不是完全依赖它,那么容忍度就会很好。
刘铁岩:很多行业对人工智能的期望过于高,例如希望用人工智能做客服,就想完全取代人工,但实际是做任何事情都必须踩在地上,因此我建议各位,需要管理这些对手的期望值,告诉他们人工智能能干什么。
朱军:前面几位专家都是从应用方面,希望机器学习能够帮助很好地解决问题。事实上,在学校我不太喜欢说机器学习飞快发展,这样会产生一个预期值太高的问题,所以从学校的角度来看,我们这个行业还是要非常仔细的探讨。
李磊:我们希望机器学习解决的问日或者是机器人解决的问题,应该满足三个标准:频率高、代价低、决策轻。现在机器学习能够利用大量数据做一些决策,但这些决策,即使机器学习做错了如新闻推送,产生的影响也应该不是很大。这应该机器学习目前这个阶段能够解决的比较好的问题。
总结
根据专家们的观点,对于人工智能的目标而言,机器学习的发展还处在比较初级的阶段,目前尚不能对机器学习期望太高。工业界的专家更期待机器学习对更多的应用的支持,但机器学习商用必须能够满足快速迭代的需求,计算速度要快,所以机器学习仍然需要很高的成本,而且在一些关键领域,机器学习的精度还没有达到用户的容忍度之内。
- 机器学习仍然对大量(标注)数据有很强的依赖,规模仍然会继续增长;
- 深度学习不一定是机器学习的明天,而且深度学习极为依赖计算能力,但深度学习毕竟降低了机器学习的门槛,结合大数据在很多场景下是有效的;
- 当然,浅层学习也还有深入研究的必要;
- 机器学习模型的可解释性对于成功很重要,深度学习需要推广性证明等理论的突破;
- 机器学习流程的简化是专家们都关注的问题,交互式机器学习就是为此而生,另外深度学习也只是解决了表达学习,在参数调优、运算上都还有不足,未来希望从数据采集、数据输入到特征抽取,再到模型优化、参数学习、超参数学习,整个流程都能自动化进行。
本文为现场实录,未经演讲者本人确认。CCAI 2016更多精彩信息,请关注CSDN独家直播专题。
作者:刘崇鑫
责编:周建丁([email protected])
想了解人工智能背后的那些人、技术和故事,欢迎关注人工智能头条: 