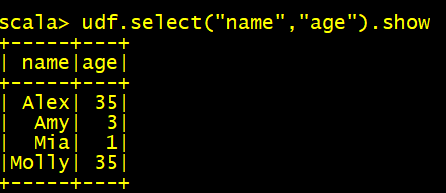
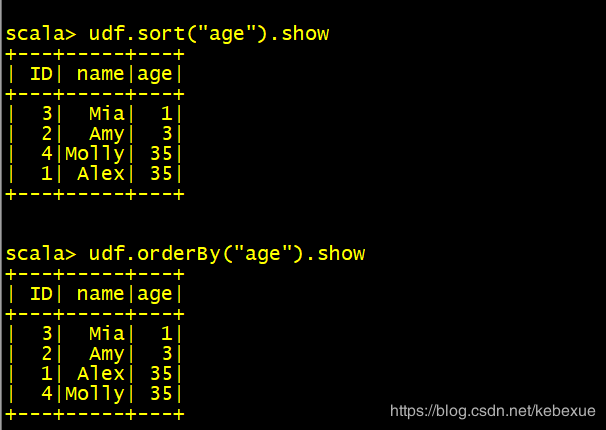
- 【Spark征服之路-3.7-Spark-SQL核心编程(六)】
qq_46394486
sparksqlajax
数据加载与保存:通用方式:SparkSQL提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL默认读取和保存的文件格式为parquet加载数据:spark.read.load是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定。spark.read.format("…")[.option("…")].
- Spark从入门到熟悉(篇三)
小新学习屋
数据分析spark大数据分布式
本文介绍Spark的DataFrame、SparkSQL,并进行SparkSQL实战,加强对编程的理解,实现快速入手知识脉络包含如下7部分内容:RDD和DataFrame、SparkSQL的对比创建DataFrameDataFrame保存成文件DataFrame的API交互DataFrame的SQL交互SparkSQL实战参考资料RDD和DataFrame、SparkSQL的对比RDD对比Data
- 【SequoiaDB】4 巨杉数据库SequoiaDB整体架构
Alen_Liu_SZ
巨杉数据库SequoiaDB架构编目节点协调节点数据节点巨杉数据库
1整体架构SequoiaDB巨杉数据库作为分布式数据库,由数据库存储引擎与数据库实例两大模块组成。其中,数据库存储引擎模块是数据存储的核心,负责提供整个数据库的读写服务、数据的高可用与容灾、ACID与发你不是事务等全部核心数据服务能力。数据库实例模块则作为协议与语法的适配层,用户可根据需要创建包括MySQL、PostgreSQL与SparkSQL在内的结构化数据实例;支持JSON语法的MongoD
- Spark教程3:SparkSQL最全介绍
Cachel wood
大数据开发spark大数据分布式计算机网络AHP需求分析
文章目录SparkSQL最全介绍一、SparkSQL概述二、SparkSession:入口点三、DataFrame基础操作四、SQL查询五、SparkSQL函数六、与Hive集成七、数据源操作八、DataFrame与RDD互转九、高级特性十、性能优化十一、Catalyst优化器十二、SparkSQL应用场景十三、常见问题与解决方法SparkSQL最全介绍一、SparkSQL概述SparkSQL是A
- Pyspark中的int
闯闯桑
pythonsparkpandas大数据
在PySpark中,整数类型(int)与Python或Pandas中的int有所不同,因为它基于SparkSQL的数据类型系统。以下是PySpark中整数类型的详细说明:1.PySpark的整数类型PySpark主要使用IntegerType(32位)和LongType(64位)表示整数,对应SQL中的INT和BIGINT:PySpark类型SQL类型位数取值范围占用存储IntegerTypeIN
- 史上最全Hive面试题(10w字完整版)
zh_19995
hive
1、下述SQL在Hive、SparkSql两种引擎中,执行流程分别是什么,区别是什么HiveonMapreducehive的特性:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapR
- spark sql解析过程详解
Chrollo
spark源码分析大数据sparkhadoop
sparksql解析sparksql解析过程这里直接引用论文SparkSQL:RelationalDataProcessinginSpark中的流程图,整体流程非常的清晰。下面将按顺序进去讲解。从Analysis这个阶段开始,主要流程都是在QueryExecution类中进行处理的。//Analysis阶段lazyvalanalyzed:LogicalPlan=executePhase(Query
- 第66课:SparkSQL下Parquet中PushDown的实现学习笔记
梦飞天
SparkSparkSQLPushDown
第66课:SparkSQL下Parquet中PushDown的实现学习笔记本期内容:1SparkSQL下的PushDown的价值2SparkSQL下的Parquet的PuahDown实现Hive中也有PushDown。PushDown可以极大减少数据输入,极大的提高处理效率。SparkSQL实现了PushDown,在Parquet文件中实现PushDown具有很重要的意义。PushDown是一种S
- Spark(四) SQL
小雨光
大数据spark
一、简介SparkSQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。之前Hive是将hql转换成MapReduce然后放在集群上执行,简化了编写MapReduce的复杂性,但是由于MapReduce执行的效率比较慢,所以产生了SparkSQL,它是将SQL转换成RDD,然后提交到集群执行,效率就会变快。二、
- spark java dataframe_Spark DataFrame简介(一)
克勒kk
sparkjavadataframe
1.DataFrame本片将介绍SparkRDD的限制以及DataFrame(DF)如何克服这些限制,从如何创建DataFrame,到DF的各种特性,以及如何优化执行计划。最后还会介绍DF有哪些限制。2.什么是SparkSQLDataFrame?从Spark1.3.0版本开始,DF开始被定义为指定到列的数据集(Dataset)。DFS类似于关系型数据库中的表或者像R/Python中的datafra
- 征服Spark as a Service
wangruoze
SparkSpark课程Spark培训Spark企业内训Spark讲师
Spark是当今大数据领域最活跃最热门的高效的大数据通用计算平台,基于RDD,Spark成功的构建起了一体化、多元化的大数据处理体系,在“OneStacktorulethemall”思想的引领下,Spark成功的使用SparkSQL、SparkStreaming、MLLib、GraphX近乎完美的解决了大数据中BatchProcessing、StreamingProcessing、Ad-hocQu
- 一天征服Spark!
wangruoze
SparkSpark课程Spark培训Spark企业内训Spark讲师
Spark是当今大数据领域最活跃最热门的高效的大数据通用计算平台,基于RDD,Spark成功的构建起了一体化、多元化的大数据处理体系,在“OneStacktorulethemall”思想的引领下,Spark成功的使用SparkSQL、SparkStreaming、MLLib、GraphX近乎完美的解决了大数据中BatchProcessing、StreamingProcessing、Ad-hocQu
- Spark SQL DataFrame 算子
猫猫姐
Spark实战sparksql大数据
SparkSQLDataFrame算子DataFrame与DatasetAPI提供了简单的、统一的并且更富表达力的API,简言之,与RDD与算子的组合相比,DataFrame与DatasetAPI更高级。DataFrame不仅可以使用SQL进行查询,其自身也具有灵活的API可以对数据进行查询,与RDDAPI相比,DataFrameAPI包含了更多的应用语义,所谓应用语义,就是能让计算框架知道你的目
- SparkSQL 优化实操
社恐码农
sparksql
一、基础优化配置1.资源配置优化#提交Spark作业时的资源配置示例spark-submit\--masteryarn\--executor-memory8G\--executor-cores4\--num-executors10\--confspark.sql.shuffle.partitions=200\your_spark_app.py参数说明:executor-memory:每个Execu
- JOIN使用的注意事项
对许
#Hive#Sparksparksqlhivesql
JOIN的使用要求在SparkSQL/HQL中,使用JOIN进行表关联时,需要注意以下要求:空值处理,多个表进行JOIN取值,在非INNERJOIN的情况下大多会取到NULL空值,对这些空值在必要情况下需要进行空值处理,一般使用COALESCE进行转换确认关联字段是否唯一对于字符型关联字段,如果无法保障不存在前后空格,最好进行TRIM处理后再关联关联条件关键字ON与JOIN关键字右对齐,AND进行
- 使用 PySpark 从 Kafka 读取数据流并处理为表
Bug Spray
kafkalinq分布式
使用PySpark从Kafka读取数据流并处理为表下面是一个完整的指南,展示如何通过PySpark从Kafka消费数据流,并将其处理为可以执行SQL查询的表。1.环境准备确保已安装:ApacheSpark(包含SparkSQL和SparkStreaming)KafkaPySpark对应的Kafka连接器(通常已包含在Spark发行版中)2.完整代码示例frompyspark.sqlimportSp
- 4.2.5 Spark SQL 分区自动推断
酒城译痴无心剑
Spark3.x基础学习笔记SparkSQL自动分区推断
在本节实战中,我们学习了SparkSQL的分区自动推断功能,这是一种提升查询性能的有效手段。通过创建具有不同分区的目录结构,并在这些目录中放置JSON文件,我们模拟了一个分区表的环境。使用SparkSQL读取这些数据时,Spark能够自动识别分区结构,并将分区目录转化为DataFrame的分区字段。这一过程不仅展示了分区自动推断的便捷性,还说明了如何通过配置来控制分区列的数据类型推断。通过实际操作
- Spark SQL ---一般有用
okbin1991
sparksql大数据hive分布式
SparkSQLandDataFrame1.课程目标1.1.掌握SparkSQL的原理1.2.掌握DataFrame数据结构和使用方式1.3.熟练使用SparkSQL完成计算任务2.SparkSQL2.1.SparkSQL概述2.1.1.什么是SparkSQLSparkSQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。2.
- 4.8.2 利用Spark SQL计算总分与平均分
酒城译痴无心剑
Spark3.x基础学习笔记SparkSQL成绩统计
在本次实战中,我们的目标是利用SparkSQL计算学生的总分与平均分。首先,我们准备了包含学生成绩的数据文件,并将其上传至HDFS。接着,通过Spark的交互式编程环境,我们读取了成绩文件并将其转换为结构化的DataFrame。然后,我们创建了一个临时视图,并通过SQL查询计算了每个学生的总分和平均分。此外,我们还通过创建一个Spark项目来实现相同的功能。在项目中,我们定义了Maven依赖,配置
- Spark SQL进阶:解锁大数据处理的新姿势
£菜鸟也有梦
大数据基础大数据sparksqlhadoophive
目录一、SparkSQL,为何进阶?二、进阶特性深剖析2.1窗口函数:数据洞察的新视角2.2高级聚合:挖掘数据深度价值2.3自定义函数(UDF和UDTF):拓展功能边界三、性能优化实战3.1数据分区与缓存策略3.2解决数据倾斜问题3.3合理配置Spark参数四、实际项目案例4.1项目背景与数据介绍4.2SparkSQL进阶应用4.3优化过程与效果展示五、总结与展望一、SparkSQL,为何进阶?在
- Spark,连接MySQL数据库,添加数据,读取数据
Eternity......
spark大数据
以下是使用Spark/SparkSQL连接MySQL数据库、添加数据和读取数据的完整示例(需提前准备MySQL驱动包):一、环境准备1.下载MySQL驱动-下载mysql-connector-java-8.0.33.jar(或对应版本),放入Spark的jars目录,或提交任务时用--jars指定路径。2.启动SparkSessionscalaimportorg.apache.spark.sql.
- Spark入门秘籍
£菜鸟也有梦
大数据基础spark大数据分布式
目录一、Spark是什么?1.1内存计算:速度的飞跃1.2多语言支持:开发者的福音1.3丰富组件:一站式大数据处理平台二、Spark能做什么?2.1电商行业:洞察用户,精准营销2.2金融行业:防范风险,智慧决策2.3科研领域:加速研究,探索未知三、Spark核心组件揭秘3.1SparkCore3.2SparkSQL3.3SparkStreaming3.4SparkMLlib3.5SparkGrap
- Spark大数据分析案例(pycharm)
qrh_yogurt
spark数据分析pycharm
所需文件(将文件放在路径下,自己记住后面要用):通过百度网盘分享的文件:beauty_p....csv等4个文件链接:https://pan.baidu.com/s/1pBAus1yRgefveOc7NXRD-g?pwd=22dj提取码:22dj复制这段内容打开「百度网盘APP即可获取」工具:Spark下安装的pycharm5.202.窗口操作(SparkSQL)在处理数据时,经常会遇到数据的分类
- SparkSQL数据提取和保存
古拉拉明亮之神
大数据spark
在前面我们学习了RDD的算子还有分区器,今天我们来一起完成一个大一点的案例,通过案例来巩固学习内容。下面来做一个综合案例:读入csv文件中的数据,并做简单的数据筛选,然后写入数据到数据库。准备工作:建立一个.csv文件,然后添加基本数据。11,name,age12,xiaoming,2413,小花,19importorg.apache.spark.sql.SparkSessionimportjav
- Spark SQL 之 Analyzer
zhixingheyi_tian
sparksparksql大数据
SparkSQL之Analyzer//SpecialcaseforProjectasitsupportslateralcolumnalias.casep:Project=>valresolvedNoOuter=p.projectList.map(resolveExpressionByPlanChildren(_,p
- SparkSQL基本操作
Eternity......
spark大数据
以下是SparkSQL的基本操作总结,涵盖数据读取、转换、查询、写入等核心功能:一、初始化SparkSessionscalaimportorg.apache.spark.sql.SparkSessionvalspark=SparkSession.builder().appName("SparkSQLDemo").master("local[*]")//本地模式(集群用`spark://host:p
- spark mysql多表查询_scala spark2.0 sparksql 连接mysql8.0 操作多表 使用 dataframe 及RDD进行数据处理...
驴放屁
sparkmysql多表查询
1、配置文件packageconfigimportorg.apache.spark.sql.SparkSessionimportorg.apache.spark.{SparkConf,SparkContext}caseobjectconf{privatevalmaster="local[*]"valconfs:SparkConf=newSparkConf().setMaster(master).s
- SparkSQL-数据提取和保存
心碎土豆块
spark中的问题分析大数据ide
1.建立一个.csv文件,然后添加基本数据。2.在mysql端建立一个数据表准备user.csv文件。在mysql中创建数据表,特别注意字符编码的问题编写spark代码:读入csv文件到dataFramedataFrame做数据筛选dataFrame做数据写入到mysql(三)核心步骤1.在mysql中创建数据表
- SparkSQL操作Mysql
心碎土豆块
spark中的问题分析mysqladb数据库
(一)准备mysql环境我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。以下是具体步骤:使用finalshell连接hadoop001.查看是否已安装MySQL。命令是:rpm-qa|grepmariadb若已安装,需要先做卸载MySQL的操作命令是:rpm-e--nodepsmariadb-libs把mysql的安装包上传到虚拟机。进入/opt
- Spark SQL 读取 CSV 文件,并将数据写入 MySQL 数据库
lqlj2233
数据库sparksql
在Spark中,可以使用SparkSQL读取CSV文件,并将数据写入MySQL数据库。以下是一个完整的示例,展示如何实现这一过程。环境准备安装MySQL:确保MySQL数据库已安装并运行。创建MySQL数据库和表:CREATEDATABASEsparkdb;USEsparkdb;CREATETABLEusers(idINTAUTO_INCREMENTPRIMARYKEY,nameVARCHAR(5
- LeetCode[位运算] - #137 Single Number II
Cwind
javaAlgorithmLeetCode题解位运算
原题链接:#137 Single Number II
要求:
给定一个整型数组,其中除了一个元素之外,每个元素都出现三次。找出这个元素
注意:算法的时间复杂度应为O(n),最好不使用额外的内存空间
难度:中等
分析:
与#136类似,都是考察位运算。不过出现两次的可以使用异或运算的特性 n XOR n = 0, n XOR 0 = n,即某一
- 《JavaScript语言精粹》笔记
aijuans
JavaScript
0、JavaScript的简单数据类型包括数字、字符创、布尔值(true/false)、null和undefined值,其它值都是对象。
1、JavaScript只有一个数字类型,它在内部被表示为64位的浮点数。没有分离出整数,所以1和1.0的值相同。
2、NaN是一个数值,表示一个不能产生正常结果的运算结果。NaN不等于任何值,包括它本身。可以用函数isNaN(number)检测NaN,但是
- 你应该更新的Java知识之常用程序库
Kai_Ge
java
在很多人眼中,Java 已经是一门垂垂老矣的语言,但并不妨碍 Java 世界依然在前进。如果你曾离开 Java,云游于其它世界,或是每日只在遗留代码中挣扎,或许是时候抬起头,看看老 Java 中的新东西。
Guava
Guava[gwɑ:və],一句话,只要你做Java项目,就应该用Guava(Github)。
guava 是 Google 出品的一套 Java 核心库,在我看来,它甚至应该
- HttpClient
120153216
httpclient
/**
* 可以传对象的请求转发,对象已流形式放入HTTP中
*/
public static Object doPost(Map<String,Object> parmMap,String url)
{
Object object = null;
HttpClient hc = new HttpClient();
String fullURL
- Django model字段类型清单
2002wmj
django
Django 通过 models 实现数据库的创建、修改、删除等操作,本文为模型中一般常用的类型的清单,便于查询和使用: AutoField:一个自动递增的整型字段,添加记录时它会自动增长。你通常不需要直接使用这个字段;如果你不指定主键的话,系统会自动添加一个主键字段到你的model。(参阅自动主键字段) BooleanField:布尔字段,管理工具里会自动将其描述为checkbox。 Cha
- 在SQLSERVER中查找消耗CPU最多的SQL
357029540
SQL Server
返回消耗CPU数目最多的10条语句
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
execution_count,
(SELECT SUBSTRING(text, statement_start_of
- Myeclipse项目无法部署,Undefined exploded archive location
7454103
eclipseMyEclipse
做个备忘!
错误信息为:
Undefined exploded archive location
原因:
在工程转移过程中,导致工程的配置文件出错;
解决方法:
- GMT时间格式转换
adminjun
GMT时间转换
普通的时间转换问题我这里就不再罗嗦了,我想大家应该都会那种低级的转换问题吧,现在我向大家总结一下如何转换GMT时间格式,这种格式的转换方法网上还不是很多,所以有必要总结一下,也算给有需要的朋友一个小小的帮助啦。
1、可以使用
SimpleDateFormat SimpleDateFormat
EEE-三位星期
d-天
MMM-月
yyyy-四位年
- Oracle数据库新装连接串问题
aijuans
oracle数据库
割接新装了数据库,客户端登陆无问题,apache/cgi-bin程序有问题,sqlnet.log日志如下:
Fatal NI connect error 12170.
VERSION INFORMATION: TNS for Linux: Version 10.2.0.4.0 - Product
- 回顾java数组复制
ayaoxinchao
java数组
在写这篇文章之前,也看了一些别人写的,基本上都是大同小异。文章是对java数组复制基础知识的回顾,算是作为学习笔记,供以后自己翻阅。首先,简单想一下这个问题:为什么要复制数组?我的个人理解:在我们在利用一个数组时,在每一次使用,我们都希望它的值是初始值。这时我们就要对数组进行复制,以达到原始数组值的安全性。java数组复制大致分为3种方式:①for循环方式 ②clone方式 ③arrayCopy方
- java web会话监听并使用spring注入
bewithme
Java Web
在java web应用中,当你想在建立会话或移除会话时,让系统做某些事情,比如说,统计在线用户,每当有用户登录时,或退出时,那么可以用下面这个监听器来监听。
import java.util.ArrayList;
import java.ut
- NoSQL数据库之Redis数据库管理(Redis的常用命令及高级应用)
bijian1013
redis数据库NoSQL
一 .Redis常用命令
Redis提供了丰富的命令对数据库和各种数据库类型进行操作,这些命令可以在Linux终端使用。
a.键值相关命令
b.服务器相关命令
1.键值相关命令
&
- java枚举序列化问题
bingyingao
java枚举序列化
对象在网络中传输离不开序列化和反序列化。而如果序列化的对象中有枚举值就要特别注意一些发布兼容问题:
1.加一个枚举值
新机器代码读分布式缓存中老对象,没有问题,不会抛异常。
老机器代码读分布式缓存中新对像,反序列化会中断,所以在所有机器发布完成之前要避免出现新对象,或者提前让老机器拥有新增枚举的jar。
2.删一个枚举值
新机器代码读分布式缓存中老对象,反序列
- 【Spark七十八】Spark Kyro序列化
bit1129
spark
当使用SparkContext的saveAsObjectFile方法将对象序列化到文件,以及通过objectFile方法将对象从文件反序列出来的时候,Spark默认使用Java的序列化以及反序列化机制,通常情况下,这种序列化机制是很低效的,Spark支持使用Kyro作为对象的序列化和反序列化机制,序列化的速度比java更快,但是使用Kyro时要注意,Kyro目前还是有些bug。
Spark
- Hybridizing OO and Functional Design
bookjovi
erlanghaskell
推荐博文:
Tell Above, and Ask Below - Hybridizing OO and Functional Design
文章中把OO和FP讲的深入透彻,里面把smalltalk和haskell作为典型的两种编程范式代表语言,此点本人极为同意,smalltalk可以说是最能体现OO设计的面向对象语言,smalltalk的作者Alan kay也是OO的最早先驱,
- Java-Collections Framework学习与总结-HashMap
BrokenDreams
Collections
开发中常常会用到这样一种数据结构,根据一个关键字,找到所需的信息。这个过程有点像查字典,拿到一个key,去字典表中查找对应的value。Java1.0版本提供了这样的类java.util.Dictionary(抽象类),基本上支持字典表的操作。后来引入了Map接口,更好的描述的这种数据结构。
&nb
- 读《研磨设计模式》-代码笔记-职责链模式-Chain Of Responsibility
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 业务逻辑:项目经理只能处理500以下的费用申请,部门经理是1000,总经理不设限。简单起见,只同意“Tom”的申请
* bylijinnan
*/
abstract class Handler {
/*
- Android中启动外部程序
cherishLC
android
1、启动外部程序
引用自:
http://blog.csdn.net/linxcool/article/details/7692374
//方法一
Intent intent=new Intent();
//包名 包名+类名(全路径)
intent.setClassName("com.linxcool", "com.linxcool.PlaneActi
- summary_keep_rate
coollyj
SUM
BEGIN
/*DECLARE minDate varchar(20) ;
DECLARE maxDate varchar(20) ;*/
DECLARE stkDate varchar(20) ;
DECLARE done int default -1;
/* 游标中 注册服务器地址 */
DE
- hadoop hdfs 添加数据目录出错
daizj
hadoophdfs扩容
由于原来配置的hadoop data目录快要用满了,故准备修改配置文件增加数据目录,以便扩容,但由于疏忽,把core-site.xml, hdfs-site.xml配置文件dfs.datanode.data.dir 配置项增加了配置目录,但未创建实际目录,重启datanode服务时,报如下错误:
2014-11-18 08:51:39,128 WARN org.apache.hadoop.h
- grep 目录级联查找
dongwei_6688
grep
在Mac或者Linux下使用grep进行文件内容查找时,如果给定的目标搜索路径是当前目录,那么它默认只搜索当前目录下的文件,而不会搜索其下面子目录中的文件内容,如果想级联搜索下级目录,需要使用一个“-r”参数:
grep -n -r "GET" .
上面的命令将会找出当前目录“.”及当前目录中所有下级目录
- yii 修改模块使用的布局文件
dcj3sjt126com
yiilayouts
方法一:yii模块默认使用系统当前的主题布局文件,如果在主配置文件中配置了主题比如: 'theme'=>'mythm', 那么yii的模块就使用 protected/themes/mythm/views/layouts 下的布局文件; 如果未配置主题,那么 yii的模块就使用 protected/views/layouts 下的布局文件, 总之默认不是使用自身目录 pr
- 设计模式之单例模式
come_for_dream
设计模式单例模式懒汉式饿汉式双重检验锁失败无序写入
今天该来的面试还没来,这个店估计不会来电话了,安静下来写写博客也不错,没事翻了翻小易哥的博客甚至与大牛们之间的差距,基础知识不扎实建起来的楼再高也只能是危楼罢了,陈下心回归基础把以前学过的东西总结一下。
*********************************
- 8、数组
豆豆咖啡
二维数组数组一维数组
一、概念
数组是同一种类型数据的集合。其实数组就是一个容器。
二、好处
可以自动给数组中的元素从0开始编号,方便操作这些元素
三、格式
//一维数组
1,元素类型[] 变量名 = new 元素类型[元素的个数]
int[] arr =
- Decode Ways
hcx2013
decode
A message containing letters from A-Z is being encoded to numbers using the following mapping:
'A' -> 1
'B' -> 2
...
'Z' -> 26
Given an encoded message containing digits, det
- Spring4.1新特性——异步调度和事件机制的异常处理
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- squid3(高命中率)缓存服务器配置
liyonghui160com
系统:centos 5.x
需要的软件:squid-3.0.STABLE25.tar.gz
1.下载squid
wget http://www.squid-cache.org/Versions/v3/3.0/squid-3.0.STABLE25.tar.gz
tar zxf squid-3.0.STABLE25.tar.gz &&
- 避免Java应用中NullPointerException的技巧和最佳实践
pda158
java
1) 从已知的String对象中调用equals()和equalsIgnoreCase()方法,而非未知对象。 总是从已知的非空String对象中调用equals()方法。因为equals()方法是对称的,调用a.equals(b)和调用b.equals(a)是完全相同的,这也是为什么程序员对于对象a和b这么不上心。如果调用者是空指针,这种调用可能导致一个空指针异常
Object unk
- 如何在Swift语言中创建http请求
shoothao
httpswift
概述:本文通过实例从同步和异步两种方式上回答了”如何在Swift语言中创建http请求“的问题。
如果你对Objective-C比较了解的话,对于如何创建http请求你一定驾轻就熟了,而新语言Swift与其相比只有语法上的区别。但是,对才接触到这个崭新平台的初学者来说,他们仍然想知道“如何在Swift语言中创建http请求?”。
在这里,我将作出一些建议来回答上述问题。常见的
- Spring事务的传播方式
uule
spring事务
传播方式:
新建事务
required
required_new - 挂起当前
非事务方式运行
supports
&nbs