Python可视化实验
***Python可视化实验
看一部精彩的经典电影,就像看一本经典的书一样。我们可以在书中成长,也可以在一部影片中成长,体验生活,感悟人生,增长智慧。我们可以在一部电影中成长,通过一部影片思考生活,感悟人生,并从中得到启发且受益。下面我将使用Python将豆瓣TOP250的电影分析一下并推荐给大家。希望你们会喜欢,并能在这些电影获得人生的哲理和生活的感悟。
数据抓取
豆瓣电影在拥有最大影迷社区以及电影数据库的基础上,豆瓣电影根据移动场景的需求,解决了用户去哪看电影、该看哪部电影的问题。让用户查资料、查评分、查影讯、给电影评分的行为真正做到了随时随地。 ------BiaNews
#豆瓣电影TOP250
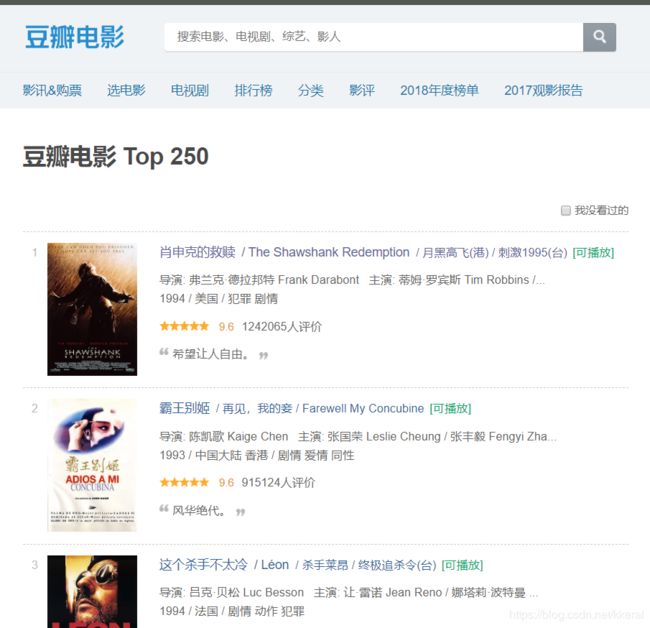
在谷歌浏览器中可以右键并点击检查就可以看到网页源代码

利用下面代码即可获取电影名,电影评分,评价人数,电影类型
import urllib.request
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
import pandas as pd
mylist = []
def get_text(url):
page = urllib.request.urlopen(url)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
try:
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span', class_='rating_num').get_text())
m_people = tag.find('div', class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].get_text()[:-3]
m_type = tag.find('p',class_="").get_text()[-27:-25]
mylist.append((m_name, str(m_rating_score), m_peoplecount,str(m_type)))
return mylist
except:
return None
for i in range(0, 250, 25) :
url = 'https://movie.douban.com/top250?start=' + str(i) + '&filter='
df = pd.DataFrame(get_text(url))
df
#运行结果
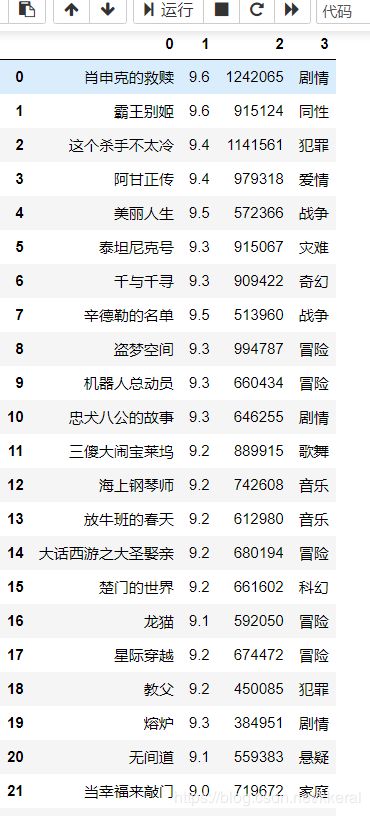
如果想要将这个表格存为.csv文件加上下面这句代码即可
df.to_csv('H:\\output.csv', encoding='gbk', index=False)
数据分析
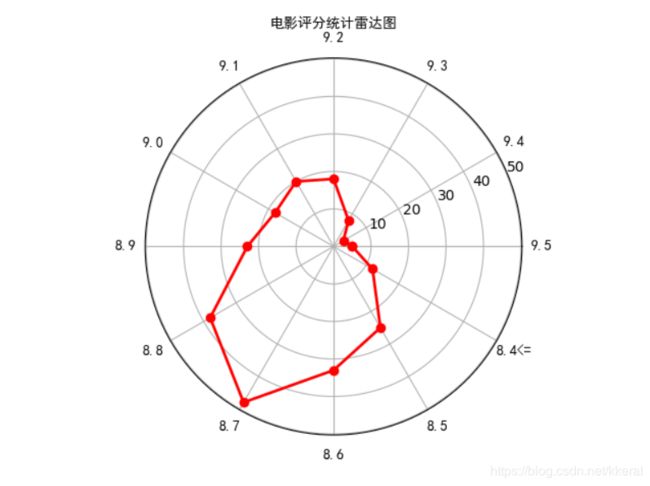
上图为TOP250电影的评分统计雷达图,从雷达图中可以看出大部分作品的评分集中在8.6-8.8的区间中。超过9.0分的电影比较少且集中于9.1、9.2。虽然作品之间的评分方差比较大,也并不代表他们的质量会有很大的差距,都是值得一看的。
import numpy as np
import matplotlib.pyplot as plt
import csv
l = [0,0,0,0,0,0,0,0,0,0,0,0]
#打开爬取的csv文件导入并计算各个评分的电影数
csv_file = csv.reader(open('H:\output.csv', 'r'))
for stu in csv_file:
if float(stu[1]) >= 9.5:
l[0] = int(l[0]) + 1
elif float(stu[1]) >= 9.4:
l[1] = int(l[1]) + 1
elif float(stu[1]) >= 9.3:
l[2] = int(l[2]) + 1
elif float(stu[1]) >= 9.2:
l[3] = int(l[3]) + 1
elif float(stu[1]) >= 9.1:
l[4] = int(l[4]) + 1
elif float(stu[1]) >= 9.0:
l[5] = int(l[5]) + 1
elif float(stu[1]) >= 8.9:
l[6] = int(l[6]) + 1
elif float(stu[1]) >= 8.8:
l[7] = int(l[7]) + 1
elif float(stu[1]) >= 8.7:
l[8] = int(l[8]) + 1
elif float(stu[1]) >= 8.6:
l[9] = int(l[9]) + 1
elif float(stu[1]) >= 8.5:
l[10] = int(l[10]) + 1
else:
l[11] = int(l[11]) + 1
#标签
labels = np.array(["9.5","9.4","9.3","9.2","9.1","9.0",
"8.9","8.8","8.7","8.6","8.5","8.4<="])
#数据个数
dataLenth = 12
#数据
data = np.array(l)
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
data = np.concatenate((data, [data[0]]))
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, data, 'ro-', linewidth=2)
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
ax.set_title("电影评分统计雷达图", va='bottom', fontproperties="SimHei")
ax.grid(True)
plt.show()
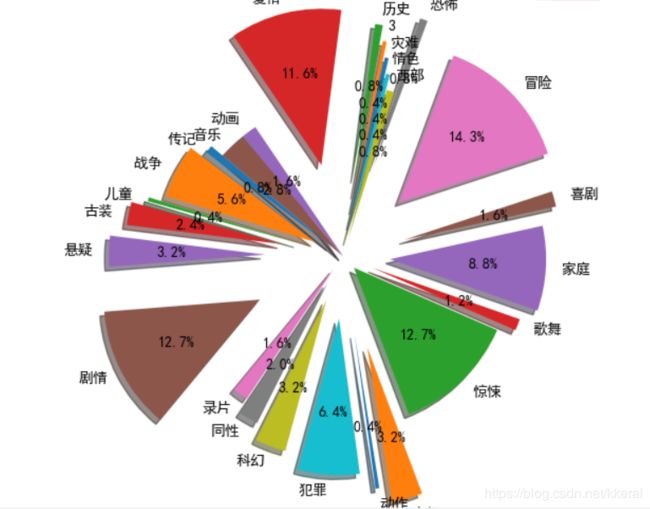
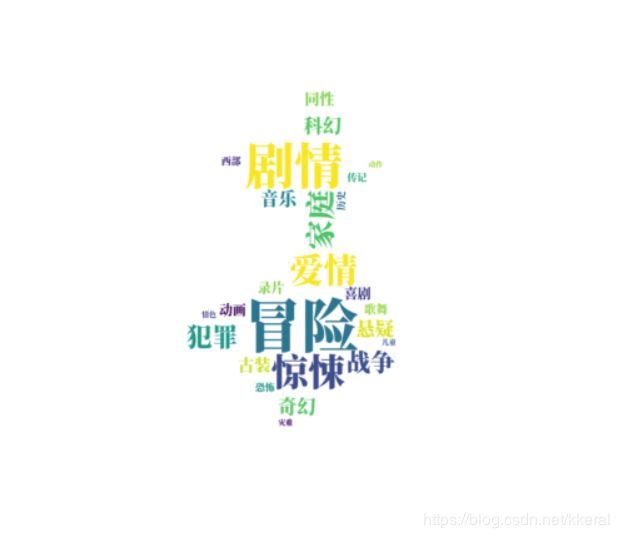
饼图图表分析了不同电影类型数在TOP250中的占比。将这些电影类型生成一个词云图:冒险,惊悚爱情,战争,剧情等等这些词比较醒目。从中可以看出剧情片、惊悚片、冒险片、爱情片占比比较大,看来这些类型的电影比较容易出经典。
###饼图
import csv
import matplotlib.pyplot as plt
import numpy as np
type_name = set() #电影类型名
count = [] #同一类型名电影数量
#打开爬取的csv文件导入类型名
csv_file = csv.reader(open('H:\output.csv', 'r'))
for stu in csv_file:
type_name.add(str(stu[3]))
#初始化count列表
for i in type_name:
count.append(int(0))
l = []
#将type_name转为l列表 并与count列表使用zip合并成字典d
for i in type_name:
l.append(str(i))
d = dict(zip(l, count))
#打开爬取的csv文件计算同一类型名的数量
csv_file = csv.reader(open('H:\output.csv', 'r'))
for j in csv_file:
d[j[3]] = d[str(j[3])] + 1
#画饼图
import numpy as np
import matplotlib.pyplot as plt
explode = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6,
0.1, 0.2, 0.3, 0.4, 0.5, 0.6,
0.1, 0.2, 0.3, 0.4, 0.5, 0.6,
0.1, 0.2, 0.3, 0.4, 0.5, 0.6,
0, 0]
#生成标签列表
labels = list(d.keys())
#生成数量列表
fracs = list(d.values())
#解决中文乱码 字体为黑体
plt.rcParams['font.sans-serif']=['SimHei']
plt.axes(aspect=1)
plt.pie(x=fracs, labels=labels, explode=explode, autopct='%3.1f%%',
shadow=True, labeldistance=1.1, startangle=140, pctdistance=0.6)
plt.show()
###词云图
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, STOPWORDS
import csv
l = []
#打开爬取的csv文件导入电影类型
csv_file = csv.reader(open('H:\\output.csv', 'r'))
for stu in csv_file:
l.append(str(stu[3]))
#将电影类型存成txt
file = open('H:\\file_name.txt','w');
for i in l:
file.write(str(i))
file.write('\n')
file.close()
###当前文件路径
d = path.dirname(__file__)
# Read the whole text.
file = open(path.join(d, 'H:\\file_name.txt')).read()
##进行分词
default_mode =jieba.cut(file)
text = " ".join(default_mode)
alice_mask = np.array(Image.open(path.join(d, "H:\\alice_mask.png")))
stopwords = set(STOPWORDS)
stopwords.add("said")
fontname = path.join(d, 'F:\\1.otf')
wc = WordCloud(
#设置字体,不指定就会出现乱码,这个字体文件需要下载
font_path = fontname,
background_color="white",
max_words=2000,
mask=alice_mask,
stopwords=stopwords)
wc.generate(text)
# store to file
# show
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure()
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G