大数据之路-Hadoop-5-HDFS原理解析及NameNode、DataNode工作机制

-
-
- 一HDFS的工作机制
- 1 概述
- 二HDFS写数据流程
- 1 概述
- 2 详细步骤图
- 3 详细步骤解析
- 三HDFS读数据流程
- 1 概述
- 2 详细步骤图
- 3 详细步骤解析
- 四NameNode工作机制
- 1 问题场景
- 2 NameNode的职责
- 3 元数据管理
- 31 元数据存储机制
- 32 元数据手动查看
- 33 元数据checkpoint
- 34 元数据目录说明
- 五DataNode工作机制
- 1 问题场景
- 2 概述
- 21 DataNode工作职责
- 22 DataNode掉线判断时限参数
- 3 观察验证DataNode功能
- 一HDFS的工作机制
-
一、HDFS的工作机制
很多不是真正理解hadoop技术体系的人,经常会觉得HDFS可用于网盘类应用。但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解。
1.1 概述
- HDFS集群分为两大角色: NameNode、DataNode
- NameNode负责管理整个文件系统的元数据
- DataNode负责管理用户的文件数据块
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台DataNode上。
- 每一个文件块可以有多个副本,并存放在不同的DataNode上。
- DataNode会定期向NameNode汇报自身所保存的文件block信息,而NameNode则会负责保存文件的副本数量。
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过NameNode申请来进行。
二、HDFS写数据流程
2.1 概述
客户端要向HDFS写数据,首先要跟NameNode通信以确认可以写文件并获得接收文件block的DataNode,然后,客户端按顺序将文件逐个以block传递给相应DataNode,并由接收到block的DataNode负责向其他DataNode复制block的副本。
2.2 详细步骤图

2.3 详细步骤解析
- 与NameNode通信请求上传文件,NameNode检查目标文件是否存在,父目录是否存在
- NameNode返回是否可以上传
- client请求第一个block该传输到那些DataNode服务器上
- NameNode返回3个DataNode服务器 node01、node02、node03
- client请求3台中DataNode中的一台node01上传数据(本质上是 RPC调用,建立pipeline),node01收到请求会继续调用node02,然后node02继续调用node03,将整个pipeline建立完成,逐级返回客户端
- client开始往node01上传第一个block(先从磁盘读数据放到一个本地内存缓存),以packet为单位,node01收到一个packet就会传给node02,node02传给node03,node01每传一个packet会放入一个应答队列,等待应答。
- 当一个block传输完成之后,client再次请求NameNode上传第二个block的服务器
三、HDFS读数据流程
2.1 概述
客户端将要读取的文件路径发送个NameNode,NameNode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应的DataNode,逐个获取文件的block并在客户端本地进行数据追加合并,从而获得整个文件。
2.2 详细步骤图
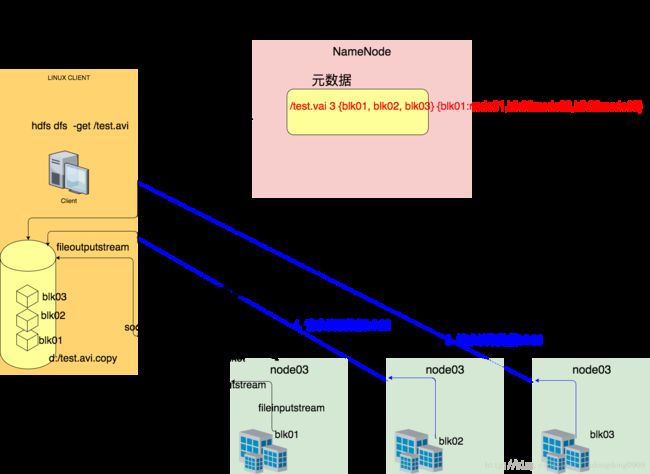
2.3 详细步骤解析
- 与NameNode通信查询元数据,找到文件块坐在的DataNode服务器
- 挑选一台DataNode(就近原则,然后随机)服务器,请求建立socket流
- DataNode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4.客户端以packet为单位接收,先在本地缓存,然后写入目标文件
四、NameNode工作机制
4.1 问题场景
- 集群启动之后,可以查看文件,但是上传文件时报错,打开web页面可以看到NameNode正处于safemode状态,怎么处理?
- NameNode服务器的磁盘故障导致NameNode宕机,如何挽救集群及数据?
- NameNode是否可以有多个? NameNode内存要配置多大?NameNode跟集群数据存储能力有关系吗?
- 文件的blocksize究竟调大好还是调小好?
诸如此类问题的回答,都需要基于对NameNode自身的工作原理的深刻理解。
4.2 NameNode的职责
NameNode主要的两个职责:
1. 负责客户端请求的响应
2. 元数据的管理(查询、修改)
4.3 元数据管理
NameNode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
4.3.1 元数据存储机制
- 内存中有一份完整的元数据(内存 meta data)
- 磁盘有一个“准完整”的元数据镜像(fsimage)文件(在NameNode的工作目录中)
- 用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日子(edits文件)注意:当客户端对hdfs中的文件进行新增或修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存metadata中
4.3.2 元数据手动查看
先查看一下 hdpdata中的数据结构:
[hadoop@hadoop01 dfs]$ pwd
/home/hadoop/apps/hdpdata/dfs
[hadoop@hadoop01 dfs]$
[hadoop@hadoop01 dfs]$ tree
.
├── data
│ ├── current
│ │ ├── BP-60221078-172.16.29.161-1514955036901
│ │ │ ├── current
│ │ │ │ ├── dfsUsed
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741832
│ │ │ │ │ ├── blk_1073741832_1008.meta
│ │ │ │ │ ├── blk_1073741833
│ │ │ │ │ ├── blk_1073741833_1009.meta
│ │ │ │ │ ├── blk_1073741843
│ │ │ │ │ ├── blk_1073741843_1019.meta
│ │ │ │ │ ├── blk_1073741850
│ │ │ │ │ ├── blk_1073741850_1026.meta
│ │ │ │ │ ├── blk_1073741851
│ │ │ │ │ ├── blk_1073741851_1027.meta
│ │ │ │ │ ├── blk_1073741853
│ │ │ │ │ ├── blk_1073741853_1029.meta
│ │ │ │ │ ├── blk_1073741864
│ │ │ │ │ ├── blk_1073741864_1040.meta
│ │ │ │ │ ├── blk_1073741865
│ │ │ │ │ ├── blk_1073741865_1041.meta
│ │ │ │ │ ├── blk_1073741867
│ │ │ │ │ ├── blk_1073741867_1043.meta
│ │ │ │ │ ├── blk_1073741868
│ │ │ │ │ └── blk_1073741868_1044.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── dncp_block_verification.log.curr
│ │ │ ├── dncp_block_verification.log.prev
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
├── name
│ ├── current
│ │ ├── edits_0000000000000000001-0000000000000000340
│ │ ├── edits_0000000000000000341-0000000000000000341
│ │ ├── edits_0000000000000000342-0000000000000000343
│ │ ├── edits_0000000000000000344-0000000000000000345
│ │ ├── edits_0000000000000000346-0000000000000000347
│ │ ├── edits_0000000000000000348-0000000000000000349
│ │ ├── edits_0000000000000000350-0000000000000000351
│ │ ├── edits_0000000000000000352-0000000000000000353
│ │ ├── edits_0000000000000000354-0000000000000000355
│ │ ├── edits_0000000000000000356-0000000000000000357
│ │ ├── edits_0000000000000000358-0000000000000000359
│ │ ├── edits_0000000000000000360-0000000000000000361
│ │ ├── edits_0000000000000000362-0000000000000000386
│ │ ├── edits_inprogress_0000000000000000420
│ │ ├── fsimage_0000000000000000417
│ │ ├── fsimage_0000000000000000417.md5
│ │ ├── fsimage_0000000000000000419
│ │ ├── fsimage_0000000000000000419.md5
│ │ ├── seen_txid
│ │ └── VERSION
│ └── in_use.lock
└── namesecondary
├── current
│ ├── edits_0000000000000000001-0000000000000000340
│ ├── edits_0000000000000000341-0000000000000000341
│ ├── edits_0000000000000000342-0000000000000000343
│ ├── edits_0000000000000000344-0000000000000000345
│ ├── edits_0000000000000000346-0000000000000000347
│ ├── edits_0000000000000000348-0000000000000000349
│ ├── edits_0000000000000000350-0000000000000000351
│ ├── edits_0000000000000000352-0000000000000000353
│ ├── edits_0000000000000000354-0000000000000000355
│ ├── edits_0000000000000000356-0000000000000000357
│ ├── edits_0000000000000000358-0000000000000000359
│ ├── edits_0000000000000000360-0000000000000000361
│ ├── edits_0000000000000000362-0000000000000000386
│ ├── fsimage_0000000000000000417
│ ├── fsimage_0000000000000000417.md5
│ ├── fsimage_0000000000000000419
│ ├── fsimage_0000000000000000419.md5
│ └── VERSION
└── in_use.lock
可以通过hdfs的一个工具来查看edits中的信息。该命令需要以下参数:
必须参数:
-i,–inputFile 输入edits文件,如果是xml后缀,表示XML格式,其他表示二进制。
-o,–outputFile 输出文件,如果存在,则会覆盖。
可选参数:
-p,–processor 指定转换类型: binary (二进制格式), xml (默认,XML格式),stats (打印edits文件的静态统计信息)
-h,–help 显示帮助信息
-f,–fix-txids 重置输入edits文件中的transaction IDs
-r,–recover 使用recovery模式,跳过eidts中的错误记录。
-v,–verbose 打印处理时候的输出。
例子1:
hdfs oev -i /home/hadoop/apps/hdpdata/dfs/name/current/edits_0000000000000000362-0000000000000000386 -o /home/hadoop/apps/edits.xml未指定-p选项,默认转换成xml格式,查看edits.xml文件:
<EDITS>
<EDITS_VERSION>-60EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENTOPCODE>
<DATA>
<TXID>362TXID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_MKDIROPCODE>
<DATA>
<TXID>363TXID>
<LENGTH>0LENGTH>
<INODEID>16473INODEID>
<PATH>/aaaPATH>
<TIMESTAMP>1516160391094TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>hadoopUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>493MODE>
PERMISSION_STATUS>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_END_LOG_SEGMENTOPCODE>
<DATA>
<TXID>386TXID>
DATA>
RECORD>
EDITS>在输出的xml文件中,每个RECORD记录了一次操作,比如图中的OP_ADD代表添加文件操作,OP_MKDIR代表创建目录操作。里面还记录了文件路径(PATH),修改时间(MTIME)、添加时间(ATIME)、客户端名称(CLIENT_NAME)、客户端地址(CLIENT_MACHINE)、权限(PERMISSION_STATUS)等非常有用的信息。
当edits文件破损进而导致HDFS文件系统出现问题时,可以通过将原有的binary文件转换为xml文件,并手动编辑xml文件然后转回binary文件来实现。
例子2:
hdfs oev -i /home/hadoop/apps/hdpdata/dfs/name/current/edits_0000000000000000362-0000000000000000386 -o /home/hadoop/apps/edits.txt -p stats指定-p stats选项,用于输出该edits文件中的统计信息:
查看edits.txt,打印出该edits文件中每种操作的数量。
VERSION : -60
OP_ADD ( 0): 4
OP_RENAME_OLD ( 1): 2
OP_DELETE ( 2): null
OP_MKDIR ( 3): 2
OP_SET_REPLICATION ( 4): null
OP_DATANODE_ADD ( 5): null
OP_DATANODE_REMOVE ( 6): null
OP_SET_PERMISSIONS ( 7): 1
OP_SET_OWNER ( 8): null
OP_CLOSE ( 9): 4
OP_SET_GENSTAMP_V1 ( 10): null
OP_SET_NS_QUOTA ( 11): null
OP_CLEAR_NS_QUOTA ( 12): null
OP_TIMES ( 13): 1
OP_SET_QUOTA ( 14): null
OP_RENAME ( 15): null
OP_CONCAT_DELETE ( 16): null
OP_SYMLINK ( 17): null
OP_GET_DELEGATION_TOKEN ( 18): null
OP_RENEW_DELEGATION_TOKEN ( 19): null
OP_CANCEL_DELEGATION_TOKEN ( 20): null
OP_UPDATE_MASTER_KEY ( 21): null查看fsimage中的信息:
hdfs oiv -i /home/hadoop/apps/hdpdata/dfs/name/current/fsimage_0000000000000000417 -p XML -o /home/hadoop/apps/fsimage.xml
[hadoop@hadoop01 current]$ [hadoop@hadoop01 apps]$
[hadoop@hadoop01 apps]$ vim fsimage.xml 里面的内容:
<fsimage><NameSection>
<genstampV1>1000genstampV1><genstampV2>1044genstampV2><genstampV1Limit>0genstampV1Limit><lastAllocatedBlockId>1073741868la
stAllocatedBlockId><txid>417txid>NameSection>
<INodeSection><lastInodeId>16480lastInodeId><inode><id>16385id><type>DIRECTORYtype><name>name><mtime>1516163790530mtime>
<permission>hadoop:supergroup:rwxr-xr-xpermission><nsquota>9223372036854775807nsquota><dsquota>-1dsquota>inode>
<inode><id>16387id><type>DIRECTORYtype><name>inputname><mtime>1516123196956mtime><permission>hadoop:supergroup:rwxr-xr-x
permission><nsquota>-1nsquota><dsquota>-1dsquota>inode>
<directory><parent>16400parent><inode>16413inode><inode>16412inode><inode>16414inode><inode>16432inode><inode>16431ino
de><inode>16433inode><inode>16451inode><inode>16450inode>
INodeDirectorySection>
<FileUnderConstructionSection>FileUnderConstructionSection>
<SnapshotDiffSection><diff><inodeid>16385inodeid>diff>SnapshotDiffSection>
<SecretManagerSection><currentId>0currentId><tokenSequenceNumber>0tokenSequenceNumber>SecretManagerSection><CacheManagerSect
ion><nextDirectiveId>1nextDirectiveId>CacheManagerSection>
fsimage>4.3.3 元数据checkpoint
每隔一段时间,会secondary NameNode 将NameNode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge,这个过程称作 checkpoint
checkpoint的详细过程如下图:
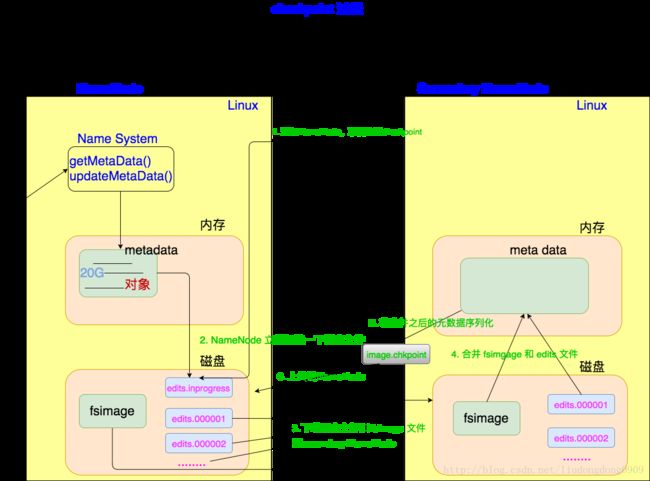
checkpoint 操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录checkpoint附带作用
NameNode和secondary NameNode 的工作目录存储结构完全相同,所有,当NameNode故障退出需要重新恢复时,可以从secondary NameNode的工作目录中将fsimage拷贝到NameNode的工作目录,以恢复NameNode的元数据。
4.3.4 元数据目录说明
在第一次部署好hadoop集群的时候,我们需要在NameNode节点上格式化磁盘:
hdfs namenode -format格式化完成之后,将会在$dfs.namenode.name.dir/current目录下产生如下的文件结构:
current/
|-- VERSION
|-- edits_*
|-- fsimage_0000000000008547077
|-- fsimage_0000000000008547077.md5
|-- seen_txid # 文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits其中 dfs.name.dir实在hdfs-site.xml文件中配置的,默认值如下:
<property>
<name>dfs.name.dirname>
<value>file://${hadoop.tmp.dir}/dfs/namevalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/tmp/hadoop-${user.name}value>
<description>A base for other temporary directories.description>
property>dfs.namenode.name.dir属性可以配置多个目录,如/data1/dfs/name, /data2/dfs/name, /data3/dfs/name …. 各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统 Network File System, NFS)之上,及时你这台机器损坏了,元数据也得到保存。
下面对 $dfs.namenode.name.dir/current/目录下的文件进行解释。
一、. VERSION 文件时Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013
namespaceID=934548976
clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196
cTime=0
storageType=NAME_NODE
blockpoolID=BP-893790215-192.168.24.72-1383809616115
layoutVersion=-47其中:
1. namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
2. storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
3. cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
4. layoutVersion表示HDFS永久性数据结构的版本信息,只要数据结构变更,版本号也要递减,此时HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会到孩子新版本的NameNode无法使用
5. clusterID是系统生成或手动指定的集群ID,在clusterID选项中可以使用它;如下说明:
a. 使用如下命令格式化一个NameNode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId ]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format -clusterId
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId
如果没有提供ClusterID,则会自动生成一个ClusterID。
- blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
二、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
三、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
五、DataNode工作机制
5.1 问题场景
- 集群容量不够,怎么扩容?
- 如果有一个DataNode宕机,该怎么办?
- DataNode明明已启动,但是集群中的可用DataNode列表中就是没有,怎么办?
5.2 概述
5.2.1 DataNode工作职责
- 存储管理用户的文件块数据
- 定期向NameNode汇报自身所持有的block信息(通过心跳信息上报)【这点很中重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题】
<property>
<name>dfs.blockreport.intervalMsecname>
<value>3600000value>
<description>Determines block reporting interval in milliseconds.description>
property>
5.2.2 DataNode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
<property>
<name>heartbeat.recheck.intervalname>
<value>2000value>
property>
<property>
<name>dfs.heartbeat.intervalname>
<value>1value>
property>5.3 观察验证DataNode功能
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/apps/hdpdata/dfs/data/current/BP-60221078-172.16.29.161-1514955036901/current/finalized