mysql系统学习
版本
5.x是用的最多的,mysql整合了第三方的新存储引擎,5.5-5.7最多。
安装命令
rpm -ivh 软件名
如:rpm -ivh MySQL-server5.5xxxxxxxx
如果安装时与其他软件冲突,则需要卸载其他软件。
如果安装时出现“GPG keys。。。”的问题,则在安装命令后边加 --force --nodoeps 如:rpm -ivh MySQL-server5.5xxxxxxxx --force --nodoeps
卸载
yum -y remove 名字* (可以用名字+通配符来多个删除)
检验是否安装
mysqladmin --version 命令来验证
在计算机reboot后,登陆MySQL: mysql 可能会报错,“/var/lib/mysql/mysql.sock不存在”
原因MySQL的服务没有启动,
启动服务
- 每次使用前手动启动服务 /etc/init.d/mysql start
2.开机自启 chkconfig mysql on(启动自启) chkconfig mysql off(关闭自启)
检查开机是否自动启动: ntsysv
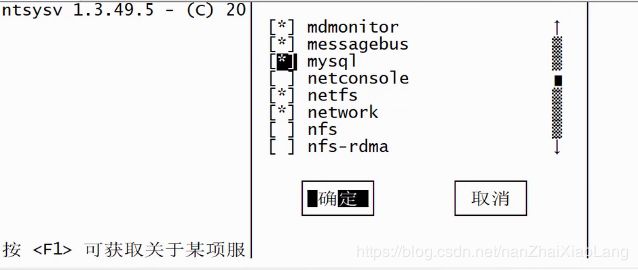
前边有 * 的是自动开启的
常用其他命令
启动: service mysql start
关闭: service mysql stop
重启: service mysql restart
清屏: ctrl+L 或 system clear
给mysql的超级管理员设置密码
命令: /usr/bin/mysqladmin -u root psaaword root 把账号密码设置都成root (注意这个是linux命令,不是mysql命令)
登陆命令: mysql -u root -p +回车+root (密码不显示登陆)
数据库的存放命令
ps -ef|grep mysql (注意这个是linux命令,不是mysql命令)
如:

核心目录

MySQL配置文件
my-huge.cnf 高端服务器 1-2G内存
my-large.cnf 中等规模
my-medium.cnf 一般的
my-small.cnf 较小的
但是,以上的配置文件musql默认不能识别,默认只能识别 /etc/my.cnf
用哪个就把哪个复制到 /etc/my.cnf
如: cp /usr/share/mysql/my-huge.cnf /etc/my.cnf
注意: 5.5 默认配置文件叫 /etc/my.cnf 5.6的叫 /etc/mysql-default.cnf
默认端口 3306
mysql字符编码命令
在mysql中:show variables like ‘%char%’

将拉丁改成utf-8 : vi /etc/my.cnf (系统命令)
在[mysql] 下加上一句 default-character-set=utf8
在[client] 下加 default-character-set=utf8
在[mysqld] 加character_set_client=utf8 character_server=utf8 collation_server=utf8_general_ci
注意:修改编码只对之后创建的数据库生效
mysql的原理
连接层:提供与客户端连接的服务
服务层:提供各种用户使用的接口和提供和sql优化器把sql语句优化
引擎层:提供了各种存储数据的方式(InnoDB和MyISM).
存储层:存储数据
InnoDB:事务优先(适合高并发操作,行锁)
MyIAM:性能优先(表锁)
查询数据库引擎:
查看支持哪些引擎:show engines;或show engines /g
mysql默认支持InnoDB
查看当前使用的引擎:show variables like ‘%storage_engine%’;

sql优化
sql性能低,执行时间太长,等待时间太长,sql语句欠佳,索引失效,服务器参数失效
编写过程:select…from…join…on…where…group by…having…order by…limit…
解析过程:from…on…join…where…group by …having…select…order by …limit…
https://www.cnblogs.com/annsshadow/p/5037667.html
索引:是帮助mysql高效获取数据的数据结构,索引是数据结构,相当于目录
mysql默认使用B树(跟二叉树相似)
B树:小的放左。大的放右(三层B树可以放百万级的数据量)
B树指向的是数据库的硬件地址(16进制的)
1:索引本身很大,可以存放在内存、硬盘里,
2:不建议使用索引的是情况:a:少量数据 b:频繁更新的字段 c:很少使用的列
3:索引降低增删改的操作
优势:
1:提高查询效率(降低IO使用率,提高IO效率)
2:降低CPU的使用率(因为索引本身就是排好序了,在排序时直接使用)
B树:一般指的是B+树,数据全部放到叶节点中,查询次数是n次 ,高度。
索引类型
分类:
主键索引:不能重复(不能是null)
单值索引:单列,一个表可以有多个单值索引
唯一索引:不能重复(可以是null)
复合索引:多个列构成的索引
查看索引:show index from 表名;
sql性能问题
1、分析sql的执行计划 expalin 可以模拟sql优化器执行sql语句,从而让开发人员指导自己的sql语句的执行
2、mysql查询优化器会干扰我们的优化
查询执行计划:explain + sql语句

id
id值一样,从上而下依次执行,数据量小的先执行(多表查询)。
id值不一样,值大的先执行(子查询)。
id值有相同有不同,id值大的先执行,如果有相同的再从上往下执行。
select_type
select_type:查询类型
PRIMARY: 包含子查询sql中的 主查询(最外层)
SUBQUERY: 包含子查询sql的 子查询 (非最外层)
simple:简单查询(不包含子查询和union)
derived:衍生查询(使用到的临时表)
a、在from子查询中只有一张表
b、在from子查询中,如果有table union table2,则table 就是derived
union result: 告知开发人员,哪些表中用了union
type 类型、索引类型
system>const>eq_ref>ref>range>index>all
system:基本达不到(只有一条数据,或衍生表只有一条数据)。
const:基本达不到,仅仅能查到一条数据的sql,用于主键或者唯一索引(类型与索引类型有关)
eq_ref:唯一索引,对于每个索引键的查询,返回匹配唯一行数据(有且只有一个,不能多,不能是0)
ref: 非唯一性索引,对于每个索引键查询,返回匹配的所有行(0,1,多)。
range:检索指定范围的行,where后边跟的是范围(between,in有时候有用有时候索引失效不能用,<,>,>=)
index:查询全部数据,查询全部索引的数据
all:查询全部数据,查询表所有的数据

一般没优化的是all,优化的实际类型是ref>range
possible_keys 可能用到的索引
key 实际用到的索引
ket_len 索引长度 用于判断复合索引是否被完全使用 字节数
utf8 :一个字符三个字节
gbk:一个字符二个字节
latin:一个字符一个字节
ref
ref跟type的ref的值区分,作用是指明当前表锁参照的字段
rows
被索引优化查询的数据个数
Extra 其它
using filesort :性能消耗大,需要额外的一次排序(查询) 一般出现在哎order by中
using temporary:性能消耗大,需要额外用到了临时表(另外一张表)。一般出现在group by语句中
using index:性能提升,索引覆盖,这次查询不读取源文件,只需要查索引。
using where:需要回访查询。即需要查索引的也需要查没有索引的列(去表里查)。
impossible where:where子句永远为false。
using join buffer:extra中的意思是MySQL殷勤使用了连接缓存(sql连接语句差,系统自动加)。
sql优化
单表优化
1.索引不能跨列使用(最佳做前缀),保持索引的定义和使用的顺序一致,
2.索引需要逐步优化
3.将含in的范围查询条件放到后边
双表优化
where后的条件原则:小表在前大表在后(小表驱动大表)。
也就是外层小内层大,程序更快。
加索引:加在经常使用的列。
左外连接给左加索引,右表连接给右加索引。
三张表和多张表
跟双表差不多,小表驱动大表、索引建立在经常查询的字段上。
避免索引失效
1.复合索引,不要跨列和无序使用(最左前缀原则)。
2.复合索引,尽量使用全索引匹配(建立的复合索引,尽量全部使用)。
3.不要再索引上进行任何操作(计算、函数、类型转换(显示,隐式)),否则索引失效。
4.复合索引不能使用不等于(!=、<、>)或者is null (is not null),否则自身以及右侧所有全部失效。
5.like以常量开头,不要用%开头,如果必须%开头则使用索引覆盖可满足部分索引。
6.尽量不要使用or,否则索引失效。
注意:上边的符合索引的第四条是概率问题,有时候是这样,有时候不会失效,如果要做到完全一致,则执行计划里的其它全向是using index则完全一致。
其他的优化方法
如果主查询的数据集大用in。
如果子查询数据集大用exist(将主查询的结果,房贷子查询结果中进行条件校验)。
order by优化:
using filesort:需要排序的语句。有两种算法:双路排序,单路排序(4.1之前的是双路排序,4.1之后的是单路排序)。
双路:扫描两次磁盘(IO的次数),
第一次是扫描查询排序字段,第二次扫描其它字段,先查id再在buffer缓存区排序id,。
单路:只读取一次全部字段,然后在buffer进行排序,这种排序有一定的隐患,不一定是单路可能是多路(原因是因为数据量特别大会分片读取,也就是多路读取)。
注意:单路排序会占用buffer的更多内存空间,如果数据量大也可以调大buffer调大。
调整buffer内存大小:set max_length_for_sort_data=1024 单位是字节
提高order by查询的策略:
1.选择单路,双路;调整buffer的容量大小。
2.避免select * 。。。。查询(通配符不仅占用带宽,还要计算,还有就是用通配符没办法索引覆盖)。
3.复合索引不能跨列使用,不面using filesort
4.保证全部排序字段,排序的一致性(要么全升序要么全降序)。
sql排查 慢日志查询
mysql提供了一种日志记录,用于记录mysql中响应时间找过阈值的sql语句(long_query_time,默认10秒)。
慢日志查询默认关闭,开发时开启,部署时关闭。

开启有临时开启,永久开启两种。一般用临时开启。
临时开启:set global slow_query_log =1; (在内存中开启),mysql推出就没了。

永久开启: 在 /etc/my.cnf 追加配置
在[mysqld]下追加
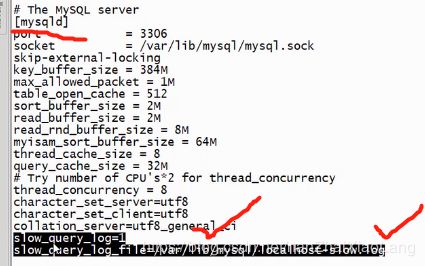
查看慢日志是否开启:show variables like ‘%show_query_log%’;
修改慢查询日志的阈值
查询阈值:show variables like ‘%long_query_time%’;

临时设置阈值:show global long_query_time = 5; (设置完毕后需要重新登陆)。
永久设置阈值:修改文件 vi /etc/my.cnf 还是在mysqld里加上 long_query_time = 3
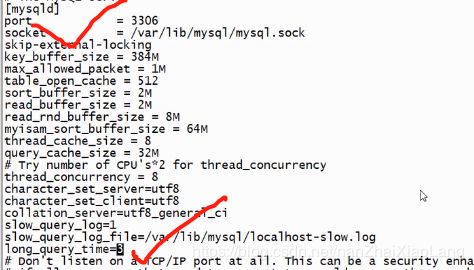
查看超过阈值的sql
显示超过阈值的条数:show global status like ‘%slow_querys%’;
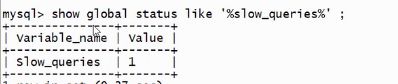
显示超过阈值的sql: 通过慢日志文件
查看 cat 慢日志的文件名

通过mysqldumpslow工具查看慢sql
mysqldumpslow --help

如何查看日志文件的指定条数数据:

模拟海量数据
存储过程无return,存储函数有return。
根据存储函数,创建存储函数:randstring (6) ->aXiayx 模拟字符串 ,括号中的6是位数。
产生随机的字符:
delimiter $
create function randstring (n int) returns varchar(255)
begin
declaer all_str varchar(100) default ‘abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ’ ;
declaer return_str varchar(255) default ‘’ ;
declare i int default 0 ;
while i < n
do
set return_str = count( substring( all_str, FLOOR(1+rand()*52),1) );
set i=i+1;
end while ;
return return_str;
end $
产生随机的数字:
create function ran_num() treutns int(5)
begin
declart i int default 0;
set i = floor(rand()*100);
retirn i;
end $
通过存储过程插入海量数据,如emp表
create procedure insert_emp ( in eid_start int(10), in data_times int(10) )
begin
declare i int default 0;
set autocommit = 0;
repeat
insert into emp values (eid_start + i ,randstring(5), ‘other’, ran_num())
set i =i+1;
until i = data_times
end repeat;
commit;
end $
插入数据:
delimiter ;
call insert_emp(1000,8000000);
call insert_dept(10,30);

关闭慢日志查询。
临时解决:
查看是否开启:show variables like ‘%log_bin_trust_function_creators%’;
修改:set global log_bin_trust_function_creators = 1
永久解决: 在my.cnf 中的mysqld中加 log_bin_trust_function_creators = 1
分析海量数据:profiles
show profiles; --默认关闭
show variables like ‘%profiling%’ ;
set profiling = on ;
show profiles: 会记录所有profiling 打开只够的全部sql查询语句所花费的总时间(IO和CPU的时间)。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
show profile all for query 1 ; – 查询第一条查询数据的详细信息。
show profile cpu , block io for query 1 ; --查询第一条sql的精确信息。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
全局日志查询
show variables like ‘%general_log%’;
set global general_log =1 ; --开启全局日志
set global log_output = ‘table’ ; --开启后记录到表中而不是记录到文件里。
或者用下边的保存到文件中–》
set global general_log =1 ; --开启全局日志
set global_log_file = ‘/tmp/general.log’; --开启保存到指定日志文件中
开启后,会记录所有sql:会被记录 mysql自带的数据库的mysql.general_log表中。
select * from mysql.general_log; --查看表的sql。
锁机制
锁机制是解决因资源共享而造成的并发问题。