一文弄懂Kafka基础理论
文章目录
- 概述
- docker安装
- Kafka版本演进
- Kafka架构
- 架构
- Kafka支持高并发读写核心技术
- 页缓存技术 + 磁盘顺序写
- 零拷贝技术(zero-copy)
- 性能测试
- 元数据
- 文件存储
- 日志的清除及压缩策略
- 日志清除策略
- 日志压缩策略
- 分区和副本
- 分区副本的分布算法
- Leader副本的选举
- 副本复制原理
- 基本原理
- 同步方式
- 如何处理Replica恢复?
- 副本HA的Purgatory机制
- 同步源码分析
- Controller 控制器
- 为什么需要Controller
- leader broker选举
- Controller中存储的数据存储
- Broker Controller 初始化
- Broker之间元数据缓存一致性
- Broker Controller 故障转移
- 幂等和事务
- 生产者
- 原理
- 客户端缓存池技术
- 源码分析
- Kafka Producer相关参数
- 分区策略
- 默认分区策略
- 自定义分区
- 代码示例
- Broker
- 消费者
- 原理
- Kafka Consumer相关参数说明
- 消费者组的重平衡(Rebalance)
- kafka中partition和消费者对应关系
- KafkaConsumer API 提交偏移量方式
- kafka消费者从哪开始消费
- 代码示例
- Kafka与其他消息队列的对比
- 消费者的均衡算法
- Q&A
- 参考
概述
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统)Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka目前主要用于三大场景:Kafka作为消息系统、Kafka作为消息系统和Kafka 作为存储系统。
具有如下特点:
- 高吞吐、低延迟 :kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
- 高伸缩性 :每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
- 持久性、可靠性 :Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。
- 容错性 :允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
- 高并发 :支持数千个客户端同时读写
docker安装
# 拉取zookeeper和kafka镜像
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kafka
# 安装zookeeper镜像
sudo docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
# 安装kafka镜像 192.168.0.100 改为宿主机器的IP地址,如果不这么设置,可能会导致在别的机器上访问不到kafka
sudo docker run -d --name kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --env KAFKA_ADVERTISED_HOST_NAME=192.168.0.100 --env KAFKA_ADVERTISED_PORT=9092 --volume /etc/localtime:/etc/localtime wurstmeister/kafka:latest
# kafka-manager管理界面,由于宿主9000端口冲突,所以把docker的9000端口映射到宿主8000端口
docker pull sheepkiller/kafka-manager
sudo docker run -itd --name=kafka-manager -p 8000:9000 -e ZK_HOSTS="192.168.0.100:2181" sheepkiller/kafka-manager
如果不用上面的kafka-manager,可以使用下面客户端工具:
Kafka可视化管理工具下载:Kafka Tool
Zookeeper的可视化管理工具:链接: https://pan.baidu.com/s/1K4kC9zenYuLd_lqvokdicA 提取码: vey4 (下载完成后,直接拖入Mac的应用程序中就可以使用了)
Kafka版本演进

查看已安装的版本号:
find / -name \*kafka_\* | head -1 | grep -o '\kafka[^\n]*'
![]()
上图中的kafka_2.12-2.3.0,其中2.12是Scala版本,2.3.0是Kafka版本。其中2.3.0中的2表示大版本号,即major version;中间的3表示小版本号或者次版本号,即minor version;最后的0表示修订版本号,也就是patch号。kafka社区在发布1.0.0版本后特意写过一篇文章,宣布kafka版本命名规则正式从4位演进到3位,比如0.11.0.0版本就是4位版本号。
Kafka架构
架构
如下图为总体架构图:

一个典型的Kafka集群包含若干Producer,若干Broker,若干Consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举Leader,以及在Consumer Group发送变化时进行Rebalance(负载均衡)。Producer 使用push(推)模式将消息发布到Broker;Consumer 使用pull(拉)模式从Broker订阅并消费消息。
注:Producer不在Zookeeper中注册,Consumer在Zookeeper中注册
下图是数据流模型

Kafka中涉及的概念:
- Producer:负责发布消息到 Kafka broker。
- Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
- Consumer Group:每个 Consumer 属于一个特定的 Consumer Group,若不指定 group name 则属于默认的 group。在同一个Group中,每一个customer可以消费多个Partion,但是一个partion只能指定给一个这个Group中一个Customer。
- Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition:topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格全局保证消息的消费顺序的场景下,需要将partition数目设为1(实际中需多思考基于partition分区有序的场景)。
- Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
- Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
- Replicas:partition的副本,保障partition的高可用。
- Zookeeper:kafka通过Zookeeper来存储集群的meta信息。
- Controller:kafka集群中的一个服务器,用来进行leader election以及各种failover。
Kafka支持高并发读写核心技术
高并发的一个重要的技术就是 *对page cache的利用 ,包含写和读两个方面。在linux中执行free命令如下:

注意到会有两列名为buffers和cached。其中,cached列表示当前的页缓存(page cache)占用量,buffers列表示当前的块缓存(buffer cache)占用量。用一句话来解释:page cache用于缓存文件的页数据,buffer cache用于缓存块设备(如磁盘)的块数据。在2.4版本内核之后,两块缓存近似融合在了一起:如果一个文件的页加载到了page cache,那么同时buffer cache只需要维护块指向页的指针就可以了。
Kafka三大件(broker、producer、consumer)与page cache的关系可以用下面的简图来表示。

producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。 另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。这个结论俗称为“读写空中接力”。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
Kafka为什么不自己管理缓存,而非要用page cache?原因有如下三点:
- JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
- 如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
- 一旦程序崩溃,自己管理的缓存数据会全部丢失。
页缓存技术 + 磁盘顺序写
Kafka 为了保证磁盘写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。

通过上图这种方式可以将磁盘文件的写性能提升很多,其实这种方式相当于写内存,不是在写磁盘。
另外,Kafka在写数据的时候是以磁盘顺序写的方式来落盘的,也就是说,仅仅将数据追加到文件的末尾(append),而不是在文件的随机位置来修改数据。
零拷贝技术(zero-copy)
首先,看下如果未使用零拷贝技术,Kafka从磁盘中读取数据发送给下游的消费者的大概过程是:
- 先看看要读的数据在不在os cache中,如果不在的话就从磁盘文件里读取数据后放入os cache
- 接着从操作系统的os cache 里拷贝数据到应用程序进程的缓存里,再从应用程序进程的缓存里拷贝数据到操作系统层面的Socket缓存里,最后从Soket缓存里提取数据后发送到网卡,最后发送出去给下游消费者

从上图可以看出,这整个过程有两次没必要的拷贝
一次是从操作系统的cache里拷贝到应用进程的缓存里,接着又从应用程序缓存里拷贝回操作系统的Socket缓存里。
而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是应用程序在执行,一会儿上下文切换到操作系统来执行。
所以这种方式来读取数据是比较消耗性能的。
Kafka 为了解决这个问题,在读数据(例如:副本同步或消费者消费数据)的时候是引入零拷贝技术。
也就是说,直接让操作系统的cache中的数据发送到网卡后传出给下游的消费者,中间跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存。

通过零拷贝技术,就不需要把os cache里的数据拷贝到应用缓存,再从应用缓存拷贝到Socket缓存了,两次拷贝都省略了,所以叫做零拷贝。
对Socket缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从os cache中发送到网卡上去了,这个过程大大的提升了数据消费时读取文件数据的性能。
而且大家会注意到,在从磁盘读数据的时候,会先看看os cache内存中是否有,如果有的话,其实读数据都是直接读内存的。
如果kafka集群经过良好的调优,大家会发现大量的数据都是直接写入os cache中,然后读数据的时候也是从os cache中读。
相当于是Kafka完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
在Java NIO包中提供了零拷贝机制对应的API,即FileChannel.transferTo()方法。不过FileChannel类是抽象类,transferTo()也是一个抽象方法,因此还要依赖于具体实现。FileChannel的实现类并不在JDK本身,而位于sun.nio.ch.FileChannelImpl类中,零拷贝的具体实现自然也都是native方法
性能测试
性能测试参考:Apache Kafka基准测试:每秒写入2百万(在三台廉价机器上)
参考:
消息中间件如何实现每秒几十万的高并发写入?
为什么Kafka那么快
聊聊page cache与Kafka之间的事儿
零拷贝(Zero-copy)及其应用详解
元数据
对于集群中的每一个broker都保存着相同的完整的整个集群的metadata信息;
Kafka客户端从任一broker都可以获取到需要的metadata信息;
首先看元数据存储
由于ZooKeeper并不适合大批量的频繁写入操作,从0.8.2版本开始Kafka开始支持将consumer的位移信息保存在Kafka内部的topic中(从0.9.0版本开始默认将offset存储到系统topic中),首先看0.8.2版本之前的存储结构,此时的位移信息如下图在offsets的子节点中保存了不同的topic的offset 信息。Consumer在消费topic中的信息时需要不断的更新ZooKeeper中的offset信息。wiki


新版Kafka将consumer的 位移信息 (即上图的/consumers/)保存在Kafka内部的topic中,即__consumer_offsets,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。关于Kafka __consumer_offests的讨论
__consumer_offsets中保存的记录是普通的Kafka消息,只是它的格式完全由Kafka来维护,用户不能干预。
__consumer_offsets中保存三类消息,包含Consumer Group组元数据消息 、 Consumer Group位移消息 和 Tombstone消息 :
- Consumer Group组元数据消息
__consumer_offsets是保存位移的,但实际上每个消费者组的元数据信息也保存在这个topic。这些元数据对应的消息的key是一个二元组,格式是【版本+groupId】,这里的版本表征这类消息的版本号,无实际用途;而value就是下图所有这些信息打包而成的字节数组。

- Consumer group组位移提交消息
如果只允许说出__consumer_offsets的一个功能,那么我们就记住这个好了:__consumer_offsets保存consumer提交到Kafka的位移数据。这句话有两个要点:1. 只有当consumer group向Kafka提交位移时才会向__consumer_offsets写入这类消息。如果你的consumer压根就不提交位移,或者你将位移保存到了外部存储中(比如Apache Flink的检查点机制或老版本的Storm Kafka Spout),那么__consumer_offsets中就是无位移数据;2. 这句话中的consumer既包含consumer group也包含standalone consumer。也就是说,只要你向Kafka提交位移,不论使用哪种java consumer,它都是向__consumer_offsets写消息。
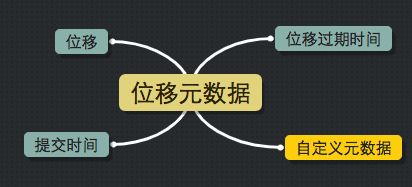
这类消息的key是一个三元组,格式是【groupId + topic + 分区号】,value则是要提交的位移信息,如下图所示:
位移就是待提交的位移,提交时间是提交位移时的时间戳,而过期时间则是用户指定的过期时间。由于目前consumer代码在提交位移时并没有明确指定过期间隔,故broker端默认设置过期时间为提交时间+offsets.retention.minutes参数值,即提交1天之后自动过期。Kafka会定期扫描__consumer_offsets中的位移消息并删除掉那些过期的位移数据,其删除过程也是通过添加Tombstone消息(第三类消息)方式,写入具有相同key的tombstone消息(举例说明假设__consumer_offsets当前保存有一条位移消息,key是【testGroupid,test, 0】(三元组),value是待提交的位移信息。无论何时,只要我们向__consumer_offsets相同分区写入一条key=【testGroupid,test, 0】,value=null的消息,那么Kafka就会认为之前的那条位移信息是可以删除的了——即相当于我们向__consumer_offsets中插入了一个tombstone mark)
上图中还有个“自定义元数据”,实际上consumer允许用户在提交位移时指定一些特殊的自定义信息。我们不对此进行详细展开,因为java consumer根本就没有使用到它。相反地,Kafka Streams利用该字段来完成某些定制任务。
- Tombstone消息(Delete Mark消息)
这类消息只出现在源码中而不暴露给用户。它和第一类消息很像,key都是二元组【版本+groupId】,唯一的区别在于这类消息的消息体是null,即空消息体。何时写入这类消息?前面说过了,Kafka会定期扫描过期位移消息并删除之。一旦某个consumer group下已没有任何active成员且所有的位移数据都已被删除时,Kafka会将该group的状态置为Dead并向__consumer__offsets对应分区写入tombstone消息,表明要彻底删除这个group的信息。简单来说,这类消息就是用于彻底删除group信息的。
(注:向__consumer_offsets写入tombstone消息仅仅是标记它之前的具有相同key的消息是可以被删除的,但删除操作通常不会立即开始。真正的删除操作是由log cleaner的Cleaner线程来执行的。)
新版Kafka的位移读取是通过Group Coordinator实现的,Coordinator一般指的是运行在broker上的group Coordinator,用于管理Consumer Group中各个成员,每个KafkaServer都有一个GroupCoordinator实例,管理多个消费者组,主要用于offset位移管理和Consumer Rebalance。聊聊kafka的group coordinator,下面主要介绍offset位移管理:
Consumer通过发送OffsetCommitRequest请求到指定broker(偏移量管理者)提交偏移量。这个请求中包含一系列分区以及在这些分区中的消费位置(偏移量)。偏移量管理者会追加键值(key-value)形式的消息到一个指定的topic(__consumer_offsets)。key是由consumerGroup-topic-partition组成的,而value是偏移量。聊聊kafka的group coordinator
下面主要介绍offset位移管理:
Consumer通过发送OffsetCommitRequest请求到指定broker(偏移量管理者)提交偏移量。这个请求中包含一系列分区以及在这些分区中的消费位置(偏移量)。偏移量管理者会追加键值(key-value)形式的消息到一个指定的topic(__consumer_offsets)。key是由consumerGroup-topic-partition组成的,而value是偏移量。

内存中也会维护一份最近的记录,为了在指定key的情况下能快速的给出OffsetFetchRequests而不用扫描全部偏移量topic日志。如果偏移量管理者因某种原因失败,新的broker将会成为偏移量管理者并且通过扫描偏移量topic来重新生成偏移量缓存。位移信息的提交就会既新增到topic分区新的记录,同时更新内存中维护的对应记录。

而__consumer_offsets这个topic日志offset清除是通过log.cleaner.enable=true(默认为true)启用的,其策略为compact(日志压缩,通过log.cleanup.policy=compact配置,主要为合并相同key的日志,仅仅保留key的最后一次更新),这样总是能够保存最新的位移信息,既控制了该topic总体的日志容量,也能实现保存最新offset的目的。清除间隔通过log.segment.delete.delay.ms参数控制,默认是1分钟,表示Kafka发起删除操作后,等1分钟才会开始删除底层的物理文件。cleaner.delete.retention.ms参数是Kafka会定期清理过期consumer group的元数据信息,其中compact策略方式如下图:

Offset Commit提交过程:
Coordinator上负责管理offset的组件是Offset Manager。负责存储,抓取,和维护消费者的offsets. 每个broker都有一个offset manager实例. 有两种具体的实现:
- ZookeeperOffsetManager: 调用zookeeper来存储和接收offset(老版本的位移管理)。
- DefaultOffsetManager: 提供消费者offsets内置的offset管理。
其中Offset Manager接口的概要:

通过在config/server.properties中的offset.storage参数选择。其中,DefaultOffsetManager除了将offset作为logs保存到磁盘上,DefaultOffsetManager维护了一张能快速服务于offset抓取请求的consumer offsets表。

Offset Fetch获取过程:

参考:Coordinator与offset管理和Consumer Rebalance
文件存储
kafka的数据,实际上是以文件的形式存储在文件系统的。topic下有partition,partition下有segment,segment是实际的一个个文件,topic和partition都是抽象概念。

在目录/${topicName}-{$partitionid}/下,存储着实际的log文件(即segment),还有对应的索引文件。
每个segment文件大小相等,文件名以这个segment中最小的offset命名,文件扩展名是.log;segment对应的索引的文件名字一样,扩展名是.index。有两个index文件,一个是offset index用于按offset去查message,一个是time index用于按照时间去查,其实这里可以优化合到一起,下面只说offset index。总体的组织是这样的:

为了减少索引文件的大小,降低空间使用,方便直接加载进内存中,这里的索引使用稀疏矩阵,不会每一个message都记录下具体位置,而是每隔一定的字节数,再建立一条索引。 索引包含两部分,分别是:
baseOffset :意思是这条索引对应segment文件中的第几条message。这样做方便使用数值压缩算法来节省空间。例如kafka使用的是varint。
position :在segment中的绝对位置。
查找offset对应的记录时,会先用二分法,找出对应的offset在哪个segment中,然后使用索引,在定位出offset在segment中的大概位置,再遍历查找message。
日志的清除及压缩策略
日志清除策略
- 根据消息的保留时间,当消息在kafka中保存的时间超过了指定的时间,就会触发清理过程
- 根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阀值,则可以开始删除最旧的消息。kafka会启动一个后台线程,定期检查是否存在可以删除的消息
通过log.retention.bytes和log.retention.hours这两个参数来设置,当其中任意一个达到要求,都会执行删除。
默认的保留时间是:7天
日志压缩策略
Kafka还提供了“日志压缩(Log Compaction)”功能,通过这个功能可以有效的减少日志文件的大小,缓解磁盘紧张的情况,在很多实际场景中,消息的key和value的值之间的对应关系是不断变化的,就像数据库中的数据会不断被修改一样,消费者只关心key对应的最新的value。因此,我们可以开启kafka的日志压缩功能,服务端会在后台启动启动Cleaner线程池,定期将相同的key进行合并,只保留最新的value值,其中__consumer_offsets主题默认启用了该压缩策略。日志的压缩原理是:

分区和副本
Kafka 的主题(Topic)被分为多个分区(Partition) ,分区是 Kafka 最基本的存储单位。每个分区可以有多个副本(Replica),其中副本可以在创建主题时使用 replication-factor 参数进行指定(参数包括Leader和Follower总个数,默认是1,其中副本因子不能大于 Broker 的个数)。其中一个副本是Leader ,负责处理所有Producer、Consumer的请求,同时还负责监管和维护ISR;其它的副本是Follower,不处理任何来自客户端的请求,只通过Fetch Request拉取leader的数据进行同步。
为了保证吞吐率,Topic采用多分区机制,分区尽可能均匀的分布在不同的broker上,所有消息的读写都是Leader上,而Follower则会定期地到Leader上同步数据。从某种程度上说,broker 节点中 leader 副本个数的多少决定了这个节点负载的高低。
为了保证高可用,分区采用多副本机制,这样如果有部分服务器不可用,副本所在的服务器就会接替上来,保证应用的持续性。
比如我们使用 kafka-topics.sh 脚本创建一个分区数为3、副本因子为3的主题 topic-partitions,创建之后的分布信息如下:
[root@node1 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper localhost:2181/ kafka --describe --topic topic-partitions
Topic:topic-partitions PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic-partitions Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: topic-partitions Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: topic-partitions Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
分区副本的分布算法
参考:Kafka创建Topic时如何将分区放置到不同的Broker中
为了更好的做负载均衡,Kafka尽量将所有的Partition和其副本均匀分配到整个集群上。
- 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
- 其它分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;
- 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的;
假设现在有5个 Broker,分区数为5,副本为3的主题,假设第一个分区放在broker0上,下一个副本依次放下一个broker,那分布大概为:

如果再考虑到机架的因素,我可以举例,现在如果我们有两个机架的 Kafka 集群,brokers 0、1 和 2 同属于一个机架1;brokers 3、 4 和 5 属于机架2。现在我们对这些 Broker 进行排序:0, 3, 1, 4, 2, 5(每个机架依次选择一个Broker进行排序)。按照机架的 Kafka 分区放置算法,如果分区0的第一个副本放置到broker 4上面,那么其第二个副本将会放到broker 2上面,第三个副本将会放到 broker 5上面;同理,分区1的第一个副本放置到broker 2上面,其第二个副本将会放到broker 5上面,第三个副本将会放到 broker 0上面。这就保证了这两个副本放置到不同的机架上面,即使其中一个机架出现了问题,我们的 Kafka 集群还是可以正常运行的。现在把机架因素考虑进去的话,我们的分区看起来像下面一样:

Leader副本的选举
分区leader副本的选举由 Kafka Controller 负责。 KafkaController会监听ZooKeeper的/brokers/ids下的节点路径,一旦发现有broker挂了(暂时先不考虑KafkaController所在broker挂了的情况,KafkaController挂了,各个broker会重新leader选举出新的KafkaController),分布在改broker的leader分区不可用,将开启新一轮的选举。
目前的选举策略为:
- 1、优先从ISR列表中选出第一个作为leader副本,这个叫优先副本,理想情况下优先副本就是该分区的leader副本。
- 2、如果ISR列表为空,则查看该topic的
unclean.leader.election.enable配置。
unclean.leader.election.enable如果为true则代表允许选用OSR列表的副本作为leader,那么此时就意味着数据可能丢失;为false则表示不允许,直接抛出NoReplicaOnlineException异常,造成leader副本选举失败,不过一般生产系统不建议开启该参数,生产系统往往是新增ISR的监控(例如是否为空了)来做提前预警。
- 3、如果上述配置为true,则从其它副本中选出一个作为leader副本,并且ISR列表只包含该leader副本。
一旦选举成功,则将选举后的leader、ISR和其它副本信息写入到该分区的对应的zk路径上,同时KafkaController将向所有的broker发送UpdateMetadata请求,更新每个broker的缓存的metadata数据。
参考:
Kafka leader副本选举与消息丢失场景讨论
副本复制原理
Kafka作为分布式系统,为了实现HA,采用多副本机制,并确保主副本(Leader)Crash时,备份副本(Follower)能接管服务,这就要求备Follower和Leader一直保持同步,避免Leader异常是Follower数据丢失。其中,副本同步的核心是 follower 通过向 leader replica 发送 Fetch 请求来实现数据同步的。
基本原理
Kafka动态维护了一个同步状态的副本的集合(a set of In-Sync Replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息只有被这个集合中的每个节点读取并追加到日志中,才会向外部通知说“这个消息已经被提交”。
只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。消息从leader复制到follower,我们可以通过决定Producer是否等待消息被提交的通知(ack)来区分同步复制和异步复制。
整个过程涉及如下概念:
- HW :Hight Watermark,最高水位值,标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
- LEO :Log End Offset,每个partition的log下一条待写入的消息的offset。
- ISR :In-Sync Replicas,每个分区(Partition)中同步的副本列表【包含Leader和Follower】。
- OSR:Outof-Sync Replicas,由于同步落后而被剔除的副本列表,阈值参数:
replica.lag.time.max.ms - AR:Assigned Replicas,所有副本集;AR = ISR + OSR。
- LW:Low Watermark,最低水位值,代表 AR 集合中最小的 logStartOffset 值。副本的拉取请求(FetchRequest,它有可能触发新建日志分段而旧的被清理,进而导致 logStartOffset 的增加)和删除消息请求(DeleteRecordRequest)都有可能促使 LW 的增长。
首先我们来看HW机制:

例如:

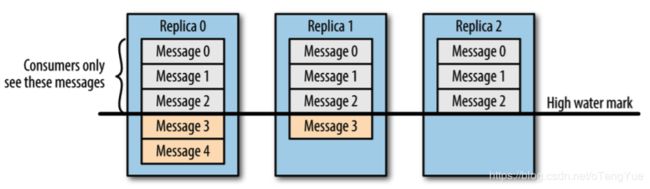
如上图,这个日志文件中只有9条消息,第一条消息的offset(LogStartOffset)为0,最有一条消息的offset为8,offset为9的消息使用虚线表示的,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。上图中offset为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的offset值加1。参考:Kafka中的HW、LEO、LSO等分别代表什么?
HW机制严格保证了所有Broker上面某个唯一偏移量之前的消息是一样的,这样新写入的消息还不能被立即消费,即使这时候宕机了,偏移量最多也只能更新到HW代表的偏移量。在多副本角度,生产者最新写入的消息如果还没有达到备份数量,对消费者是不可消费的,如下图,消费者只能消费Message0、Message1、Message2:
然后我们看下ISR机制
副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。默认情况下Kafka的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常会为partition设置多个副本,由这多个副本组成的新概念,称之为Assigned Replicas,即AR(In-Sync Replicas)。可用副本则为ISR,而被剔除的副本会存到一个叫做OSR(Outof-Sync Replicas)列表中,当然,新加入的也会被加入到OSR中。那么可以理解AR = ISR + OSR。
Leader会维护一个与其基本保持同步的Replica列表,即ISR列表,如果一个Follower比Leader落后太多,或者超过一定时间未发起数据复制请求,则Leader将其从ISR中移除,当ISR中所有Replica都向Leader发送ACK时,Leader即Commit(告诉Producer消息发送成功)。
ISR集合中的副本必须满足两个条件:
- 副本所在节点必须维持着与zookeeper的连接
- 副本最后一条消息的offset与leader副本的最后一条消息的offset之间的差值不能超过指定的阈值
- ISR数据保存在Zookeeper的
/brokers/topics/[Topic]/partitions/2/state节点信息,例如:{"controller_epoch":1,"leader":1001,"version":1,"leader_epoch":0,"isr":[1001]}
把Followerr剔除ISR场景主要包含如下:
- follower副本进程卡住,在一段时间内根本没有想leader副本发起同步请求(例如:频繁的Full GC)。
- follower副本进程同步过慢,在一段时间内都无法追赶上leader副本(例如:IO开销过大)。
其中超时时间参数设置在Broker级别,从Kafka 0.9.x版本开始通过唯一的一个参数可以通过replica.lag.time.max.ms(默认大小为10000);其中在Kafka 0.9.x版本之前还有另一个参数replica.lag.max.messages(默认大小为4000),即当一个follower副本滞后leader副本的消息数超过replica.lag.max.messages的大小时则判定此follower副本为失效副本。该参数移除原因主要是因为在消息流入速度很高的topic,容易引起ISR的频繁变动。
当producer向leader发送数据时,如何保证leader和follower副本数据的一致性,主要通过request.required.acks参数来设置数据可靠性的级别:
- acks=0 如果设置为0,则 producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。
- acks=1 如果设置为1,leader节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。
- acks=-1 如果设置为-1,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。只要至少有一个同步副本(通过
min.insync.replicas配置)存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1与acks=all是等效的。
再看下整个数据的流转过程

Kafka取Partition所对应的ISR中最小的LEO作为整个Partition的HW;每个Partition都会有自己独立的HW,与此同时leader和follower都会负责维护和更新自己的HW。对于leader新写入的消息,Consumer不能立刻被发现并进行消费,leader会等待该消息被ISR中所有的replica同步更新HW后,此时leader才会更新该partition的HW为之前新写入消息的offset,此时该消息对外才可见。如上图:假设当前状态为3个partition都有3个数据,HW = LEO;当Producer向leader发送消息4和5过来了,那么HW=3,LEO = 5;这时,leader有了新的消息,就会将阻塞的follower解锁,通知它们来复制新消息;假如其中一个follower完全跟上leader,还有一个follower只复制了消息4,那么HW = 4, LEO = 5;当所有follower都跟上leader时,HW = LEO,follower又进入阻塞状态,继续等待leader的通知。
由此可见,kafka的复制机制并不是单纯的异步复制,或者同步复制。如果单纯的异步复制,当数据写入到leader时,就已经当作是commit,而follower还没来得复制新数据,leader就宕机了,这就造成数据的丢失;如果使用单纯的同步复制,只有当所有follower都复制完成,数据才算是commit,那么就极大的影响kafka的吞吐量。
同步方式
follower向leader拉取数据的方式是串行的,即是先请求消息1,然后再接收到消息1,在接受到请求1之后,发送请求2,在收到领导者给发送给跟随者之前,跟随者是不会继续发送消息的。
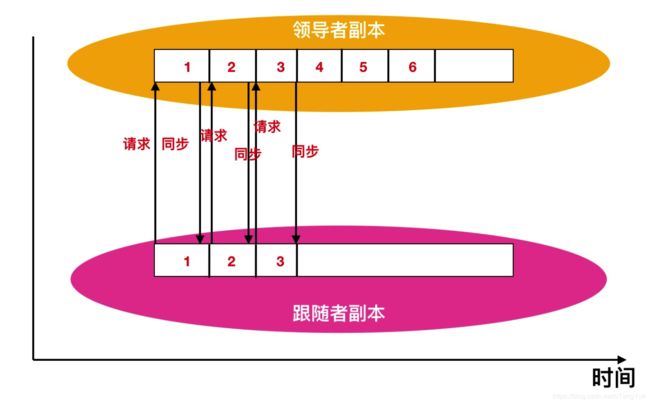
跟随者副本在收到响应消息前,是不会继续发送消息,这一点很重要。 通过查看每个跟随者请求的最新偏移量,首领就会知道每个跟随者复制的进度。如果跟随者在10s(默认,通过replica.lag.time.max.ms配置) 内没有请求任何消息,或者虽然跟随者已经发送请求,但是在10s 内没有收到消息,就会被认为是不同步的。不同步的follower将会剔除ISR队列。
如何处理Replica恢复?
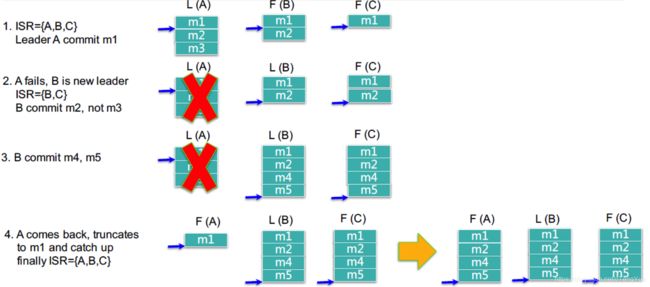
- 1、可以看到ISR={A,B,C},Leader(A)节点中存在m1,m2,m3三条消息,F(B)存在m1,m2两条消息,f©只存在m1一消息,所以这里只会提交m1这条消息,因为m2这条消息还没有在ISR中完成复制。它只会提交三个ISR中都存在的消息。
- 2、当L(A)在将消息m2复制到B,C之后挂掉,此时ISR中只有{B,C},B被选举成为新的主节点,当m2,m1都存在于B,C节点中时,B将会提交m1,m2两条消息,不会提交m3消息。此时,注意关键的一步:新选举的leader副本B,会将此时自己的LEO,设置为HW,然后HW未提交的数据会同步到其follower副本。
- 3、此时消息将都会发送到B节点上,C节点同步了B节点中的新发的消息m4,m5之后,将会提交m4,m5。
- 4、此时A节点连接集群成功或重启,可以使用了,它会从B节点中同步从m1,到m5的消息,直到它的消息与B和C中的一致为止,此时的Replica将会变成ISR={A,B,C},完成了Replica的恢复。这里我们发现m3并没有存在了,这里并不是丢失了,只是当没有主节点提交m3这条消息时,它将会自动反馈到Producer,Producer会重试,或做其他处理,当重试成功后可能m3消息将会append到m5的后面,所以consumer消费消息时,我们保证的顺序性不是producer发送消息的顺序,而是commit时的顺序。
副本HA的Purgatory机制
无论follower同步leader,还是consumer消费数据,都是通过pull的方式,即consumer 读取数据与副本同步数据都是通过向 leader 发送 Fetch 请求来实现的,在对这两种不同情况处理过程中,其底层的实现是统一的,只是实现方法的参数不同而已。下图是工作流程:

从图中我们可以看出HA的缓存分为拉取缓存事件池和生产缓存事件池两块结构相同的缓存区,分别拉取请求(ProducerRequestPurgatory)和缓存生产请求(FetchRequestPurgatory)。
两个缓存事件池的作用:
- 生产缓存事件池:当生产者设置了等待从partition的同步选项(requiredAcks为-1)时才会启动生产缓存。因为每一批生产的消息,需要等待所有的处于同步状态的从partition(in-sync)同步成功,在所有follow partition上报自己的水位线追上leader partition之前,生产请求会一直保留在生产缓存中,等待直到超时。
- 拉取缓存事件池:拉取请求为什么也需要缓存?因为kafka在消费消息时有一个默认选项,一次拉取最低消费1条消息。那么,如果消费者拉取的时候没有任何新消息生产,则拉取请求会保留到拉取缓存中,等待直到超时。这一定程度上避免了反复拉取一批空消息占用带宽资源的问题,不过也把Kafka的ha缓存架构的复杂度提升了一个等级。
下图是拉取缓存和生产缓存的设计思路:

可以看到缓存从两个维度对请求做了记录,1是partition维度,缓存中为每一个partition创建了一个watcher,watcher中使用ArrayList保存请求,所以任何partition的消息有生产或消费都能找到为这个partition缓存各种请求。2是时间维度,缓存中创建了延迟队列,每一个请求的引用会被推入延迟队列,超时会自动释放掉。
从缓存中释放需要满足一些条件,如图所示,生产请求和拉取请求的满足条件各不相同。只要满足条件,请求就会被标记为satisfied, 会被移除缓存区。
缓存中还额外设有一个检查线程,会定期检查已经达到满足条件,但还没来得及从缓存中移除的请求。要知道这个缓存区是没有边界的,持续不断的请求被放入生产缓存和拉取缓存,但释放不及时会导致内存膨胀过快。所以kafka从各个方面都做了保证第一时间把达到满足条件的请求释放的设计。
参考:
kafka高可用性架构分析
Kafka Broker HA机制
同步源码分析
在深入到副本间的同步的内容前,先来看一下副本间同步的任务是如何从Kafka服务端启动后是如何开始的。KafkaServer启动时,主要调用KafkaServer.startup()方法进行初始化和启动,在startup()方法中初始化KafkaController并启动它,进行Controller选举,如果当选为Controller,则进行一些缓存的清理,并在zk上注册监听事件,用于行使Controller的具体职责。并且通过发送UpdateMetadataRequest,用于各个Broker更新metadata。在启动过程中,Controller还会启动副本状态机和分区状态机。这两个状态机用于记录副本和分区的状态,并且预设了状态转换的处理方法。在Controller启动时会分别调用两个状态机的startup()方法,在该方法中初始化副本和分区的状态,并且主要地触发LeaderAndIsrRequest请求到Broker。各Broker接收到LeaderAndIsrRequest请求后,会初始换ReplicaManager并调用replicaManager.becomeLeaderOrFollower()方法处理请求,如果本Broker为分区的leader,则调用 makeLeaders()方法进行停止fetcher线程,更新缓存等。如果本Broker为分区的follower,则调用makeFollowers(),该方法中更新缓存,停止接收Producer请求,对日志进行offset进行处理,并且在broker可用情况下向新的leader开启同步线程。在ReplicaManager.makeFollowers()方法调用了replicaFetcherManager.addFetcherForPartitions()方法进行后台同步线程的创建。为每个变更了leader的副本创建一个ReplicaFetcherThread后台线程并启动,用于副本的主从同步。初始化过程详细源码分析见:Kafka 副本间的主从同步 和 Kafka 源码解析:分区多副本容错机制
下面是从makeFollowers()函数开始Fetch的整体流程,包括了 replica fetcher 线程的启动、工作流程、关闭三个部分(Kafka 源码解析之副本同步机制实现):

如果 Broker 的本地副本被选举为 follower,那么它将会启动副本同步线程,makeFollowers() 的处理过程如下:
- 1、先从本地记录 leader partition 的集合中将这些 partition 移除,因为这些 partition 已经被选举为了 follower;
- 2、将这些 partition 的本地副本设置为 follower,后面就不会接收关于这个 partition 的 Produce 请求了,如果依然有 client 在向这台 broker 发送数据,那么它将会返回相应的错误;
- 3、先停止关于这些 partition 的副本同步线程(如果本地副本之前是 follower 现在还是 follower,先关闭的原因是:这个 partition 的 leader 发生了变化,如果 leader 没有发生变化,那么 makeFollower 方法返回的是 False,这个 Partition 就不会被添加到 partitionsToMakeFollower 集合中),这样的话可以保证这些 partition 的本地副本将不会再有新的数据追加;
- 4、对这些 partition 本地副本日志文件进行截断操作并进行 checkpoint 操作;
- 5、完成那些延迟处理的 Produce 和 Fetch 请求;
- 6、如果本地的 broker 没有掉线,那么向这些 partition 新选举出来的 leader 启动副本同步线程。(该步并不一定会为每一个 partition 都启动一个 fetcher 线程,对于一个目的 broker,只会启动 num.replica.fetchers 个线程,具体这个 topic-partition 会分配到哪个 fetcher 线程上,是根据 topic 名和 partition id 进行计算得到)
在 ReplicaManager 调用 makeFollowers() 启动 replica fetcher 线程后,它实际上是通过 ReplicaFetcherManager 实例进行相关 topic-partition 同步线程的启动和关闭,其启动过程分为下面两步:
- 1、ReplicaFetcherManager 调用 addFetcherForPartitions() 添加对这些 topic-partition 的数据同步流程;
- 2、ReplicaFetcherManager 调用 createFetcherThread() 初始化相应的 ReplicaFetcherThread 线程。
replica fetcher 线程在启动之后就开始进行正常数据同步流程了,这个过程都是在 ReplicaFetcherThread 线程中doWork()实现的(其中ReplicaFetcherThread继承自AbstractFetcherThread,而AbstractFetcherThread又继承自ShutdownableThread,在ShutdownableThread的run()方法中可以看到后台线程是一直循环调用doWork()进行发送fetch请求并处理结果),在 doWork() 方法中主要做了两件事:
- 1、构造相应的Fetch请求buildFetchRequest();
- 2、通过processFetchRequest()方法发送Fetch请求,并对其结果进行相应的处理。
processFetchRequest() 这个方法的作用是发送 Fetch 请求,并对返回的结果进行处理,最终写入到本地副本的 Log 实例中,具体包含:
- 1、通过 fetch() 方法,发送 Fetch 请求,获取相应的 response(如果遇到异常,那么在下次发送 Fetch 请求之前,会 sleep 一段时间再发);
- 2、如果返回的结果 不为空,并且 Fetch 请求的 offset 信息与返回结果的 offset 信息对得上,那么就会调用 processPartitionData() 方法将拉取到的数据追加本地副本的日志文件中,如果返回结果有错误信息,那么就对相应错误进行相应的处理;
- 3、对在 Fetch 过程中遇到异常或返回错误的 topic-partition,会进行 delay 操作,下次 Fetch 请求的发生至少要间隔
replica.fetch.backoff.ms时间。
其中涉及的Replica Fetcher 线程参数设置如:
- 参数: num.replica.fetchers
说明: 从一个 broker 同步数据的 fetcher 线程数,增加这个值时也会增加该 broker 的 Io 并行度(也就是说:从一台 broker 同步数据,最多能开这么大的线程数)
默认值: 1 - 参数: replica.fetch.wait.max.ms
说明: 对于 follower replica 而言,每个 Fetch 请求的最大等待时间,这个值应该比 replica.lag.time.max.ms 要小,否则对于那些吞吐量特别低的 topic 可能会导致 isr 频繁抖动
默认值: 500 - 参数: replica.high.watermark.checkpoint.interval.ms
说明: hw 刷到磁盘频率
默认值: 500 - 参数: replica.lag.time.max.ms
说明: 如果一个 follower 在这个时间内没有发送任何 fetch 请求或者在这个时间内没有追上 leader 当前的 log end offset,那么将会从 isr 中移除
默认值: 10000 - 参数: replica.fetch.min.bytes
说明: 每次 fetch 请求最少拉取的数据量,如果不满足这个条件,那么要等待 replicaMaxWaitTimeMs
默认值: 1 - 参数: replica.fetch.backoff.ms
说明: 拉取时,如果遇到错误,下次拉取等待的时间
默认值: 1000 - 参数: replica.fetch.max.bytes
说明: 在对每个 partition 拉取时,最大的拉取数量,这并不是一个绝对值,如果拉取的第一条 msg 的大小超过了这个值,只要不超过这个 topic 设置(defined via message.max.bytes (broker config) or max.message.bytes (topic config))的单条大小限制,依然会返回。
默认值: 1048576 - 参数: replica.fetch.response.max.bytes
说明: 对于一个 fetch 请求,返回的最大数据量(可能会涉及多个 partition),这并不是一个绝对值,如果拉取的第一条 msg 的大小超过了这个值,只要不超过这个 topic 设置(defined via message.max.bytes (broker config) or max.message.bytes (topic config))的单条大小限制,依然会返回。
默认值: 10MB
Controller 控制器
Controller是Kafka中的核心组件之一,负责管理和协调Kafka集群。
为什么需要Controller
在Kafka早期版本,对于分区和副本的状态的管理依赖于zookeeper的Watcher和队列:每一个broker都会在zookeeper注册Watcher,所以zookeeper就会出现大量的Watcher, 如果宕机的broker上的partition很多比较多,会造成多个Watcher触发,造成集群内大规模调整;每一个replica都要去再次zookeeper上注册监视器,当集群规模很大的时候,zookeeper负担很重。这种设计很容易出现脑裂和羊群效应以及zookeeper集群过载。
新的版本中该变了这种设计,使用KafkaController,只有KafkaController,Leader会向zookeeper上注册Watcher,其他broker几乎不用监听zookeeper的状态变化。
Kafka集群中多个broker,有一个会被选举为controller leader,负责管理整个集群中分区和副本的状态,比如partition的leader 副本故障,由controller 负责为该partition重新选举新的leader 副本;当检测到ISR列表发生变化,有controller通知集群中所有broker更新其MetadataCache信息;或者增加某个topic分区的时候也会由controller管理分区的重新分配工作。
leader broker选举
Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息。每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文件 server.properties 中进行配置,或者由程序自动生成。其选举leader成为controller的过程如下:
- 1、在kafka集群中,每一个 broker 启动的时候,它会在zk 的
/brokers/ids路径下创建一个 临时节点(例如:{“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}),并将自己的 broker.id 写入,从而将自身注册到集群; - 2、第一个启动的broker会在zk中创建一个临时节点
/controller让自己成为控制器。其他broker启动时也会试着创建这个节点当然他们会失败,因为已经有人创建过了。那么这些节点会在控制器节点上创建zk watch对象,这样他们就可以收到这个节点变更的通知。任何时刻都确保集群中只有一个leader的存在。 - 3、如果控制器被关闭或者与zk断开连接,zk上的KB是节点马上就会消失。那么其他订阅了leader节点的broker也会收到通知随后他们会尝试让自己成为新的leader,重复第一步的操作。
- 4、如果leader完好但是别的broker离开了集群,那么leader会去确定离开的broker的分区并确认新的分区领导者(即分区副本列表里的下一个副本)。然后向所有包含该副本的follower或者observer发送请求。随后新的分区首领开始处理请求。
利用Zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为leader,即先到先得原则,leader也就是集群中的controller,负责集群中所有大小事务。
Controller中存储的数据存储
Kafka 是离不开 ZooKeeper的,所缓存的数据信息在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。

归纳主要包含三类:
- broker 上的所有信息。包括 broker 中的所有分区,broker 所有分区副本,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
- 所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
- 所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
Broker Controller 初始化

Controller选举成功在启动后,首先进行一些缓存的清理,并在zk上注册监听事件,监听那些Broker变化,Topic变化等事件,用于行使Controller的具体职责。同时通过发送UpdateMetadataRequest,用于各个Broker更新metadata。在启动过程中,Controller还会启动副本状态机和分区状态机,这两个状态机用于记录副本和分区的状态,并且预设了状态转换的处理方法。在Controller启动时会分别调用两个状态机的startup()方法,在该方法中初始化副本和分区的状态,并且主要地触发LeaderAndIsrRequest请求到Broker。
参考:
KafkaController启动源码分析
Broker之间元数据缓存一致性
Kafka在设计时一个愿景:每台Kafka broker都要维护相同的缓存,这样客户端程序(clients)随意地给任何一个broker发送请求都能够获取相同的数据,这也是为什么任何一个broker都能处理clients发来的Metadata请求的原因。这种用空间去换时间的做法可以缩短请求被处理的延时从而提高整体clients端的吞吐。
目前Kafka是怎么更新cache的?
简单来说,有集群中的controller监听Zookeeper上元数据节点,由controller和ZK元数据保持一致,具体的更新操作实际上是由controller来完成的。controller会在一定场景下向各broker发送UpdateMetadata请求令这些broker去更新它们各自的cache,这些broker一旦接收到请求便开始全量更新——即清空当前所有cache信息,使用UpdateMetadata请求中的数据来重新填充cache。
注:由于是异步更新的,所以在某一个时间点集群上所有broker的cache信息就未必是严格相同的。只不过在实际使用场景中,这种弱一致性似乎并没有太大的问题。原因如下:1. clients并不是时刻都需要去请求元数据的,且会缓存到本地;2. 即使获取的元数据无效或者过期了,clients通常都有重试机制,可以去其他broker上再次获取元数据; 3. cache更新是很轻量级的,仅仅是更新一些内存中的数据结构,不会有太大的成本。因此我们还是可以安全地认为每台broker上都有相同的cache信息。
参考:Kafka元数据缓存(metadata cache)
Broker Controller 故障转移
由于broker controller 只有一个,那么必然会存在单点失效问题。kafka 为考虑到这种情况提供了故障转移功能,也就是 Fail Over。如下图:

幂等和事务
见另一篇 学习笔记之Kafka幂等和事务
生产者
原理
producer和consumer过去直接与Zookeeper连接,以获得这些信息。现在Kafka已经脱离了这种耦合,从0.8版和0.9版开始,客户端直接从Kafka brokers那里获取元数据信息,集群中的每个 broker 都会缓存所有主题的分区副本信息,元数据同步可以通过配置metadata.max.age.ms参数(默认五分钟)定时刷新元数据(注:如果在定时请求的时间间隔内发生的分区副本的选举,则意味着原来缓存的信息可能已经过时了,此时还有可能会收到 Not a Leader for Partition 的错误响应,这种情况下客户端会再次向Controller【与Zookeeper数据一致性由Controller完成】发出元数据请求,然后刷新本地缓存),有了元数据信息后,客户端就知道了leader副本所在的 broker,之后直接将读写请求发送给对应的 broker 即可。如下图

发送消息流程原理图如下图,需要注意的有:
- 1.发送到kafka的数据会封装为ProducerRecord对象,包含topic、partition、key、value信息;
- 2.调用send()方法后,将数据序列化为字节数组,分区器Partitioner会根据ProducerRecord 对象的键来计算一个分区(如果发送过程中指定了有效的分区号,那么在发送记录时将使用该分区。如果未指定分区,则将使用key 的 hash 函数映射指定一个分区。如果既没有分区号也没有key值,则将以循环的方式分配一个分区);
- 3.当消息达到一个批次设定的量(消息放在缓冲区中),通过网络发送到不同的主题,不同的分区;
- 4.如果消息成功写入 Kafka,就返回一 个RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败, 则告知生产者尝试重新发送消息,达到最大重试次数就抛出异常,其中重试次数可以在配置
message.send.max.retries中指定。


下面看一下详细流程图:

整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。
在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
- RecordAccumulator
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
主线程中发送过来的消息都会被追加到 RecordAccumulator 的某个双端队列(Deque)中,在 RecordAccumulator 的内部为每个分区都维护了一个双端队列。
消息写入缓存时,追加到双端队列的尾部;Sender 读取消息时,从双端队列的头部读取。
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区, Deque< ProducerBatch>> 的保存形式转变成
KafkaProducer 要将此消息追加到指定主题的某个分区所对应的 leader 副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定)目标分区,之后 KafkaProducer 需要知道目标分区的 leader 副本所在的 broker 节点的地址、端口等信息才能建立连接,最终才能将消息发送到 Kafka。
所以这里需要一个转换,对于网络连接来说,生产者客户端是与具体的 broker 节点建立的连接,也就是向具体的 broker 节点发送消息,而并不关心消息属于哪一个分区。 - InFlightRequests
请求在从 Sender 线程发往 Kafka 之前还会保存到 InFlightRequests 中,InFlightRequests 保存对象的具体形式为 Map - 拦截器
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现 org.apache.kafka.clients.producer. ProducerInterceptor 接口。ProducerInterceptor 接口中包含3个方法:
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
public void close();
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。一般来说最好不要修改消息 ProducerRecord 的 topic、key 和 partition 等信息。
KafkaProducer 会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的 onAcknowledgement() 方法,优先于用户设定的 Callback 之前执行。这个方法运行在 Producer 的I/O线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close() 方法主要用于在关闭拦截器时执行一些资源的清理工作。
- 序列化器
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从 Kafka 中收到的字节数组转换成相应的对象。
生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的,如果生产者使用了某种序列化器,比如 StringSerializer,而消费者使用了另一种序列化器,比如 IntegerSerializer,那么是无法解析出想要的数据的。
序列化器都需要实现org.apache.kafka.common.serialization.Serializer 接口,此接口有3个方法:
public void configure(Map<String, ?> configs, boolean isKey)
public byte[] serialize(String topic, T data)
public void close()
configure() 方法用来配置当前类,在创建 KafkaProducer 实例的时候调用的,主要用来确定编码类型。serialize() 方法用来执行序列化操作。而 close() 方法用来关闭当前的序列化器。
- 分区器
消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
Kafka 中提供的默认分区器是org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了org.apache.kafka.clients.producer.Partitioner接口,这个接口中定义了2个方法,具体如下所示。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
其中 partition() 方法用来计算分区号,返回值为 int 类型。partition() 方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。close() 方法在关闭分区器的时候用来回收一些资源。
自定义的分区器,只需同 DefaultPartitioner 一样实现 Partitioner 接口即可。由于每个分区下的消息处理都是有顺序的,我们可以利用自定义分区器实现在某一系列的key都发送到一个分区中,从而实现有序消费。
生产者在向broker发送消息时是怎么确定向哪一个broker发送消息?
- 1:生产者客户端会向任一个broker发送一个元数据请求(MetadataRequest),获取到每一个分区对应的leader信息,并缓存到本地。
- 2:生产者在发送消息时,会指定partion或者通过key得到到一个partion,然后根据partion从缓存中获取相应的leader信息。

客户端缓存池技术
当我们应用程序调用kafka客户端 producer发送消息的时候,在kafka客户端内部,会把属于同一个topic分区的消息先汇总起来,形成一个batch。真正发往kafka服务器的消息都是以batch为单位的。其中,这个Batch的管理就非常值得探讨了。用上面的方案就是使用的时候new一个空间然后赋值给一个引用,释放的时候把引用置为null等JVM GC处理就可以了。在并发量比较高的时候就会频繁的进行GC。我们都知道GC的时候有个stop the world,尽管最新的GC技术这个时间已经非常短,依然有可能成为生产环境的性能瓶颈。
针对上述容易出现GC的问题,Kafka客户端内部实现了一个非常优秀的机制,就是 缓冲池的机制(类似于数据库连接池,线程池等的池化技术),即首先开辟初始化一些内存块做为缓冲池,每个batch其实都对应了缓冲池中的一个内存空间,发送完消息之后,batch不再使用了,此时这个batch底层的内存空间不是交给JVM去垃圾回收,而是把内存块归还给缓冲池。如果一个缓冲池里的内存资源都占满了,暂时没有内存块了,怎么办呢?很简单,阻塞写入,不停的等待,直到有内存块释放出来,然后再继续写入消息。
缓冲池的机制原理如下图:

参考源码分析:带你了解下Kafka的客户端缓冲池技术
源码分析
Kafka 源码解析之 Server 端如何处理 Produce 请求
Kafka Producer相关参数



分区策略
Kafka中的分区策略,就是决定生产者将消息发送到哪个分区的算法。Kafka在默认分区策略的选择:如果指定了Key,那么默认实现按消息键策略;如果没有指定Key,则使用轮询策略。
默认分区策略
- Round-robin策略(即顺序分配,也叫轮询策略),如存在分区1-5,假设有3个生产者,则生产者1->分区1,生产者2->分区2,生产者3->分区3,生产者1->分区4,生产者2->分区5。轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
- Key-ordering策略,Kafka允许为每条消息定义消息键,简称为Key,一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,这样就能保证每个分区下的相同key的消息处理都是有顺序的。其核心代码如:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
- 随机策略,随机就是我们随意地将消息放置到任意一个分区上。其中,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。其核心代码如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
自定义分区
Kafka中Producer支持自定义分区分配方式,与默认的org.apache.kafka.clients.producer.internals.DefaultPartitioner一样首先实现org.apache.kafka.clients.producer.Partitioner接口,然后在KafkaProducer的配置中显式的指定partitioner.class为对应的自定义分区器(Partitioners)即可,如下:
properties.put("partitioner.class","com.hidden.partitioner.DemoPartitioner");
举例自定义DemoPartitioner主要是实现Partitioner接口的public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)的方法。
public class DemoPartitioner implements Partitioner {
private final AtomicInteger atomicInteger = new AtomicInteger(0);
@Override
public void configure(Map<String, ?> configs) {}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (null == keyBytes || keyBytes.length<1) {
return atomicInteger.getAndIncrement() % numPartitions;
}
//借用String的hashCode的计算方式
int hash = 0;
for (byte b : keyBytes) {
hash = 31 * hash + b;
}
return hash % numPartitions;
}
@Override
public void close() {}
}
代码示例
// 仅列出必需参数
private Properties properties = new Properties();
properties.put("bootstrap.servers","broker1:9092,broker2:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties = new KafkaProducer<String,String>(properties);
// 构建消息,参数【 topic主题,key 和 value。】
ProducerRecord<String,String> record = new ProducerRecord<String, String>("CustomerCountry","West","France");
// 同步发送
try{
RecordMetadata recordMetadata = producer.send(record).get();
}catch(Exception e){
e.printStackTrace();
}
// 异步发送
producer.send(record,new DemoProducerCallBack());
class DemoProducerCallBack implements Callback {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null){
exception.printStackTrace();;
}
}
}
Broker

在Kafka的架构中,会有很多客户端向Broker端发送请求,Kafka 的 Broker 端有个 SocketServer 组件,用来和客户端建立连接,然后通过Acceptor线程来进行请求的分发,由于Acceptor不涉及具体的逻辑处理,非常得轻量级,因此有很高的吞吐量。
接着Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中,网络线程池默认大小是 3个,表示每台 Broker 启动时会创建 3 个网络线程,专门处理客户端发送的请求,可以通过Broker 端参数 num.network.threads来进行修改。
那么接下来处理网络线程处理流程如下:

当网络线程拿到请求后,会将请求放入到一个共享请求队列中。Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程池处中的线程是执行请求逻辑的线程,默认是8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求,可以通过Broker 端参数 num.io.threads调整。
Purgatory组件是用来缓存延时请求(Delayed Request)的。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。
消费者
原理
Kafka有两种模式消费数据:队列和发布订阅;在队列模式下,一条数据只会发送给customer group中的一个customer进行消费;在发布订阅模式下,一条数据会发送给多个customer进行消费。
Kafka中的消费者是以消费者组(Consumer Group)的方式工作,由一个或者多个消费者组成一个组,共同消费一个topic。每个分区在同一时间只能由group中的一个消费者读取,但是多个group可以同时消费这个partition。
Kafka的Customer采用pull(拉)模式从broker中读取数据,其过程是基于offset对kafka中的数据进行消费,对于一个Customer Group中的所有customer共享一个offset偏移量。

如上图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
Kafka Consumer相关参数说明


消费者组的重平衡(Rebalance)
当在群组里面 新增/移除消费者 或者 新增/移除 kafka集群broker节点 时,群组协调器Broker会触发重平衡,重新为每一个partion分配消费者。重平衡期间,消费者无法读取消息,造成整个消费者群组一小段时间的不可用。
重平衡过程的通知机制是靠消费者端的心跳线程(Heartbeat Thread),通知到其他消费者实例的。当协调者决定开启新一轮再均衡后,它会将 REBALANCE_IN_PROGRESS 封装进心跳请求的响应中,发还给消费者实例。当消费者实例发现心跳响应中包含了REBALANCE_IN_PROGRESS,就能立马知道重平衡又开始了。
触发场景:
- 1、新增|移除消费者:新增customer或执行customer.close()操作
- 2、新增|移除broker:如新增或重启broker节点
- 3、组成员数量发生变化:如消费者被检测无“心跳”
上面触发场景中1、2一般无法控制,第三种情况一般是一些异常引起的,我们可以在Consumer端进行一些针对性调参:
- 1、Consumer未及时发送心跳,导致Consumer被踢出Group而引发的。(注:每个Consumer初次加入后,会启动一个后台线程,定时发送心跳)
设置session.timeout.ms=10000,默认10s, 表示Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。
设置heartbeat.interval.ms=3000,默认3s,表示发送心跳请求的频率。 - 2、Consumer消费时间过长导致的。Consumer 不间断的调用poll(),如果长时间没有调用poll(例如:处理时间过长),间隔超过这个值时,就会认为这个consumer失败了。
设置max.poll.interval.ms=300000,默认5分钟,如何消费任务时间达到8分钟,而此设置为5分钟,那么会发生Rebalance。 - 3、频繁的Full GC导致的长时间停顿。
为了实现消费者重平衡机制,Kafka引入了协调器,服务端引入组协调器(GroupCoordinator),消费者端引入消费者协调器(ConsumerCoordinator)。每个broker启动的时候,都会创建GroupCoordinator实例,管理部分消费组(集群负载均衡)和组下每个消费者消费的偏移量(offset)。每个consumer实例化时,同时实例化一个ConsumerCoordinator对象,负责同一个消费组下各个消费者和服务端组协调器之前的通信。


重平衡流程
在消费者端,重平衡分为两个步骤:分别是加入组和等待领导者消费者(Leader Consumer)分配方案。即 JoinGroup 请求和 SyncGroup 请求。
- 加入组发送JoinGroup请求
当消费组内成员加入组时,它会向 GroupCoordinator 发送JoinGroup请求,在该请求中,每个成员都会携带各自的分配策略和订阅信息。一旦收集了全部成员的JoinGroup请求后,Coordinator 会从这些成员中选择一个担任这个消费者组的领导者。(通常情况下,第一个发送JoinGroup请求的成员自动成为领导者。领导者消费者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。)
选出消费者的领导者之后,GroupCoordinator 会把消费者组订阅信息封装进JoinGroup请求的响应体中,然后发给消费者领导者,由消费者领导者统一做出分配方案后,进入到下一步:发送SyncGroup请求。 - 发送SyncGroup请求
(1)消费者领导者发送SyncGroup请求:消费者领导者完成分配方案后,领导者向 GroupCoordinator 发送 SyncGroup 请求,在该请求中,携带相关分配方案;
(2)同时组内所有消费者发送SyncGroup请求,只不过请求体中并没有实际的内容,接收到一个SyncGroup响应,接受分配的方案。
这样组内所有成员就都知道自己该消费哪些分区了。
因为分区重平衡会导致分区与消费者的重新划分,有时候可能希望在重平衡前执行一些操作:比如提交已经处理但是尚未提交的偏移量,关闭数据库连接等。此时可以在订阅主题时候,调用 subscribe 的重载方法传入自定义的分区重平衡监听器。
consumer.subscribe(Collections.singletonList(topic), new ConsumerRebalanceListener() {
/*该方法会在消费者停止读取消息之后,再均衡开始之前就调用*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("再均衡即将触发");
// 提交已经处理的偏移量
consumer.commitSync(offsets);
}
/*该方法会在重新分配分区之后,消费者开始读取消息之前被调用*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});
kafka中partition和消费者对应关系
topic下的一个分区只能被同一个consumer group下的一个consumer线程来消费。
- 消费者多于partition。同一个partition内的消息只能被同一个组中的一个consumer消费。当消费者数量多于partition的数量时,多余的消费者空闲。

- 消费者少于partition。按照消费者的均衡算法分配。

- 消费者等于partition。同一个分组内消费者与partition一一对照关系,如果启动多个组,则会使同一个消息被每个分组都消费(广播)。

KafkaConsumer API 提交偏移量方式
- 自动提交
最简单的方式就是让消费者自动提交偏移量。如果
enable.auto.commit被设置为true,那么每过 5s,消费者会自动把从 poll() 方法轮询到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认是 5s。
注:使用自动提交是存在隐患的,假设我们使用默认的 5s 提交时间间隔,在最近一次提交之后的 3s 发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了 3s ,所以在这 3s 内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量,减小可能出现重复消息的时间窗,不过这种情况是无法完全避免的。基于这个原因,Kafka 也提供了手动提交偏移量的 API,使得用户可以更为灵活的提交偏移量。
- 手动提交当前偏移量
把
auto.commit.offset设置为 false,可以让应用程序决定何时提交偏移量。使用 commitSync() | commitSync() 提交偏移量。这个 API 会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
commitSync() 将会同步提交由 poll() 返回的最新偏移量,如果处理完所有记录后要确保调用了 commitSync(),否则还是会有丢失消息的风险,如果发生了在均衡,从最近一批消息到发生在均衡之间的所有消息都将被重复处理;异步提交 commitAsync() 与同步提交 commitSync() 最大的区别在于异步提交不会进行重试,同步提交会一致进行重试。 一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大的问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。但是如果在关闭消费者或再均衡前的最后一次提交,就要确保提交成功。 因此,在消费者关闭之前一般会组合使用commitAsync和commitSync提交偏移量。
- 手动提交特定的偏移量
消费者API允许调用 commitSync() 和 commitAsync() 方法时传入希望提交的 partition 和 offset 的 map,即提交特定的偏移量。
kafka消费者从哪开始消费

通过subscribe()方法订阅主题具有消费者自动再均衡(reblance)的功能,存在多个消费者的情况下可以根据分区分配策略来自动分配各个消费者与分区的关系。当组内的消费者增加或者减少时,分区关系会自动调整。实现消费负载均衡以及故障自动转移。如果需要指定消费者读取哪个主题分区,可以使用assign()方法订阅,但此时就不具有再均衡功能了。
设置kafka其实消费点是通过group.id和auto.offset.reset配置的,其中auto.offset.reset包含:earliest、latest(默认)和none。其中none代表如果未找到使用者组的先前偏移量,则向使用者抛出异常。
properties.put("group.id", "xx");
properties.setProperty("auto.offset.reset", "xx”)
只要不更改group.id,每次重新消费kafka,都是从上次消费结束的地方继续开始,不论"auto.offset.reset”属性设置的是什么值。
下面分场景说明:
- 场景一:Kafka上在实时被灌入数据,但kafka上已经积累了两天的数据,如何从最新的offset开始消费?
1.将group.id换成新的名字(相当于加入新的消费组)
2.properties.setProperty(“auto.offset.reset”, "latest”)
注:由于latest是默认值,所以也可以不用设置第2步
- 场景二:kafka在实时在灌入数据,kafka上已经积累了两天的数据,如何从两天前最开始的位置消费?
1.将group.id换成新的名字
2.properties.setProperty(“auto.offset.reset”, "earliest”)
- 场景三:不更改group.id,只是添加了
properties.setProperty("auto.offset.reset", "earliest”),consumer会从两天前最开始的位置消费吗?
不会,只要不更改消费组,只会从上次消费结束的地方继续消费
- 场景四:不更改group.id,只是添加了
properties.setProperty("auto.offset.reset", "latest”),consumer会从距离现在最近的位置消费吗?
不会,只要不更改消费组,只会从上次消费结束的地方继续消费
代码示例
// 仅列出必需参数
Properties properties = new Properties();
properties.put("bootstrap.servers", "broker1:9092,broker2:9092");
properties.put("group.id", "CountryCounter");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(properties);
// 订阅主题
consumer.subscribe(Collections.singletonList("customerCountries"));
try {
while (true) {
// 轮询拉取数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100));
for (ConsumerRecord<String, String> record : records) {
log.debug("topic = %s, partition = %s, offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
System.out.println(json.toString(4))
}
}
} finally {
consumer.close(); //4
}
注:
- 这是一个无限循环。消费者实际上是一个长期运行的应用程序,它通过轮询的方式向 Kafka 请求数据。
- Kafka 必须定期循环请求数据,否则就会认为该 Consumer 已经挂了,会触发重平衡,它的分区会移交给群组中的其它消费者。传给 poll() 方法的是一个超市时间,用 java.time.Duration 类来表示,如果该参数被设置为 0 ,poll() 方法会立刻返回,否则就会在指定的毫秒数内一直等待 broker 返回数据。
- poll() 方法会返回一个记录列表。每条记录都包含了记录所属主题的信息,记录所在分区的信息、记录在分区中的偏移量,以及记录的键值对。我们一般会遍历这个列表,逐条处理每条记录。
- 在退出应用程序之前使用 close() 方法关闭消费者。网络连接和 socket 也会随之关闭,并立即触发一次重平衡,而不是等待群组协调器发现它不再发送心跳并认定它已经死亡。
Kafka与其他消息队列的对比

消费者的均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
- 假如topic1,具有如下partitions: P0,P1,P2,P3
- 加入group中,有如下consumer: C0,C1
- 首先根据partition索引号对partitions排序: P0,P1,P2,P3
- 根据(consumer.id + ‘-’+ thread序号)排序: C0,C1
- 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
- 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
Q&A
Q:一个主题存在多个分区,每一分区属于哪个leader broker?
A:在任意一个broker机器都有每一个分区所属leader的信息,所以可以通过访问任意一个broker获取这些信息。
Q:每个消费者群组对应的分区偏移量的元数据存储在哪里。
A:最新版本保存在kafka中,对应的主题是_consumer_offsets。老版本是在zookeeper中。
Q:如何保证时序性
A:Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。如果你需要在所有记录的上面整体有序,可使用仅有一个分区的主题来实现。
Q:无Zookeeper,还能做哪些操作?
A:离开了Zookeeper, Kafka 不能对Topic 进行新增操作, 但是仍然可以produce 和consume 消息.
Q:一条消息如何知道要被发送到哪个分区?
A:
(1)如果不手动指定分区选择策略类,则会使用默认的分区策略类,具体为:
- 如果存在key值,Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions,保证了相同key的消息一定会被路由到相同的分区;
- 不指定key或key为null时,Kafka几乎就是随机找一个分区发送无key的消息,即kafka 是先从缓存中取分区号,然后判断缓存的值是否为空,如果不为空,就将消息存到这个分区,否则重新计算要存储的分区,并将分区号缓存起来,供下次使用
计算过程为如果key为null,则先根据topic名获取上次计算分区时使用的一个整数并加一。然后判断topic的可用分区数是否大于0,如果大于0则使用获取的nextValue的值和可用分区数进行取模操作。 如果topic的可用分区数小于等于0,则用获取的nextValue的值和总分区数进行取模操作;但缓存的分区号也不是一直有效,是有一个缓存时间(由
topic.metadata.refresh.interval.ms配置),缓存过时之后,就会重新计算分区号,将计算结果缓存起来。基于这些可以说“随机”选的。
(2)如果自定义了分区选择策略类,如果用户自定义了分区器,则按用户自定义分区执行,通过partitioner.class配置。
参考:kafka发送消息分区选择策略详解 和 Kafka 自定义分区器
Q:数据是由leader push过去还是有flower pull过来?
A: 每个Partition有一个leader与多个follower,producer往某个Partition中写入数据是,只会往leader中写入数据,然后数据才会被复制进其他的Replica中。 写是都往leader上写,但是读并不是任意flower上读都行,读也只在leader上读,flower只是数据的一个备份,保证leader被挂掉后顶上来,并不往外提供服务。
Q:如果设置的副本数大于Broker会怎么样?
A:假如当前我们搭建了三个Broker的集群,但是我此时指定4个Replica时,会出现org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3异常
Q:集群中各Broker的Cache什么时候更新?
A:集群中新增加的broker是如何获取这些cache,并且其他broker是如何知晓它的?当有新broker启动时,它会在Zookeeper中进行注册,此时监听Zookeeper的controller就会立即感知这台新broker的加入,此时controller会更新它自己的缓存(注意:这是controller自己的缓存,不是本文讨论的metadata cache)把这台broker加入到当前broker列表中,之后它会发送UpdateMetadata请求给集群中所有的broker(也包括那台新加入的broker)让它们去更新metadata cache。一旦这些broker更新cache完成,它们就知道了这台新broker的存在,同时由于新broker也更新了cache,故现在它也有了集群所有的状态信息。
Q:集群中副本个数可以大于broker个数吗?
A:kafka的每个topic都可以创建多个partition,partition的数量无上限,并不会像replica一样受限于broker的数量,Kafka 集群的一个 broker 中最多只能有相同Topic的一个副本。
Q:Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
A:
简单来说,分区中的所有副本统称为 AR (Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成 ISR (In Sync Replicas)。 ISR 集合是 AR 集合的一个子集。消息会先发送到leader副本,然后follower副本才能从leader中拉取消息进行同步。同步期间,follow副本相对于leader副本而言会有一定程度的滞后。前面所说的 ”一定程度同步“ 是指可忍受的滞后范围,这个范围可以通过参数进行配置。于leader副本同步滞后过多的副本(不包括leader副本)将组成 OSR (Out-of-Sync Replied)由此可见,AR = ISR + OSR。正常情况下,所有的follower副本都应该与leader 副本保持 一定程度的同步,即AR=ISR,OSR集合为空。
ISR的伸缩指leader副本负责维护和跟踪 ISR 集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会把它从 ISR 集合中剔除。如果 OSR 集合中所有follower副本“追上”了leader副本,那么leader副本会把它从 OSR 集合转移至 ISR 集合。默认情况下,当leader副本发生故障时,只有在 ISR 集合中的follower副本才有资格被选举为新的leader,而在 OSR 集合中的副本则没有任何机会(不过这个可以通过配置来改变)。
Q:Kafka生产者客户端中使用了几个线程来处理?分别是什么?
A:整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
Q:消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
A:当前消费者需要提交的消费位移是offset+1。
Q:有哪些情形会造成重复消费|丢失数据?
A:
- 重复消费的情况,主要原因是:数据已经被消费但是offset没有提交。
(1)消费者端手动提交 :如果先消费消息,再更新offset位置,导致消息重复消费。
(2)消费者端自动提交 :设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
(3)Rebalance :一个consumer正在消费一个分区的一条消息,还没有消费完,发生了rebalance(加入了一个consumer),从而导致这条消息没有消费成功,rebalance后,另一个consumer又把这条消息消费一遍。
(4)生产者端 :生产者因为业务问题导致的宕机,在重启之后可能数据会重发 - 丢失数据的情况,
(1)消费者端自动提交 :设置offset为自动定时提交,当offset被自动定时提交时,数据还在内存中未处理,此时刚好把线程kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
(3)消费者端手动提交 :先提交位移,但是消息还没消费完就宕机了,造成了消息没有被消费。自动位移提交同理
(4)acks未设置为all :如果在broker还没把消息同步到其他broker的时候宕机了,那么消息将会丢失
参考
Kafka中文文档:http://kafka.apachecn.org/
wiki:https://cwiki.apache.org/confluence/display/KAFKA/Index
什么是Kafka?有什么优点:https://www.okcode.net/article/27532
Kafka学习笔记:http://zhongmingmao.me/categories/middleware/mq/kafka/
关于Kafka学习的一些资料:https://matt33.com/2015/12/21/kafka-learn/
kafka源码分析:https://matt33.com/tags/kafka/
Kafka元数据缓存(metadata cache):https://www.cnblogs.com/huxi2b/p/8440429.html
Kafka文件存储机制那些事:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html
Kafka 的这些原理你知道吗?https://www.cnblogs.com/cxuanBlog/p/12083127.html
Kafka学习笔记:https://zhmin.github.io/categories/kafka/
Thorough Introduction to Apache Kafka:https://hackernoon.com/thorough-introduction-to-apache-kafka-6fbf2989bbc1
关于 Kafka 入门看这一篇就够了:https://mp.weixin.qq.com/s?__biz=MzU2NDg0OTgyMA==&mid=2247484768&idx=1&sn=724ebf1ecbb2e9df677242dec1ab217b
Kafka的运行流程总结和源码前准备:https://juejin.im/post/5de1e66bf265da05e35e4f98
Kafka的生产者原理及重要参数说明:https://juejin.im/post/5dda7798f265da7e0b02c75c
以上为Kafka网上资料及个人理解整理的笔记,欢迎指正!