类的成员:
成员有以下:
1、字段: 可分为静态字段 普通字段
2、方法: 可分为静态方法 类方法 普通方法
3、特性/属性 普通属性
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
一、字段
静态字段在内存中只保存一份。
普通字段在每个对象中都要保存一份。
类可以直接访问静态字段,不能直接访问普通字段。
二、方法
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
静态方法:由类调用;无默认参数;
三、属性
对于属性property的使用方法
class Foo:
def __init__(self):
pass
@property
def property_func(self):
return 'xxx'
f = Foo()
f.property_func ###属性的调用 不需要加括号
注意:
属性存在的意义是:访问属性时可以制造出和访问字段完全相同的假象。
属性用法一、
class A:
def func(self):
return 'xxx'
BAR = property(func)
a = A()
res = a.BAR #####自动调用property中的个的func方法,并获取返回值
print(res)
属性的三种用法(新式类):
以下来Python源码
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
fget is a function to be used for getting an attribute value, and likewise
fset is a function for setting, and fdel a function for del'ing, an
attribute. Typical use is to define a managed attribute x:
class C(object):
def getx(self): return self._x
def setx(self, value): self._x = value
def delx(self): del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")
# Decorators make defining new properties or modifying existing oneseasy:
class C(object):
@property
def x(self): #####获取属性
"I am the 'x' property."
return self._x
@x.setter
def x(self, value): ###设置值时,一定要有两个参数。
self._x = value
@x.deleter ##删除属性
def x(self):
del self._x
Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性
请看以下代码
class WSGIRequest(http.HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
path_info = get_path_info(environ)
if not path_info:
# Sometimes PATH_INFO exists, but is empty (e.g. accessing
# the SCRIPT_NAME URL without a trailing slash). We really need to
# operate as if they'd requested '/'. Not amazingly nice to force
# the path like this, but should be harmless.
path_info = '/'
self.environ = environ
self.path_info = path_info
# be careful to only replace the first slash in the path because of
# http://test/something and http://test//something being different as
# stated in http://www.ietf.org/rfc/rfc2396.txt
self.path = '%s/%s' % (script_name.rstrip('/'),
path_info.replace('/', '', 1))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
self.content_type, self.content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))
if 'charset' in self.content_params:
try:
codecs.lookup(self.content_params['charset'])
except LookupError:
pass
else:
self.encoding = self.content_params['charset']
self._post_parse_error = False
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None
def _get_scheme(self):
return self.environ.get('wsgi.url_scheme')
@cached_property
def GET(self):
# The WSGI spec says 'QUERY_STRING' may be absent.
raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '')
return http.QueryDict(raw_query_string, encoding=self._encoding)
def _get_post(self): ##############################
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
def _set_post(self, post): ##################################
self._post = post
@cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return http.parse_cookie(raw_cookie)
@property
def FILES(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
POST = property(_get_post, _set_post) ###########################
isinstance 和 issubclass
isinstance(obj,cls)检查是否obj是否是类 cls 的对象
class Foo(object):
pass
obj = Foo()
isinstance(obj, Foo)
issubclass(sub, super)检查sub类是否是 super 类的派生类
class Foo(object):
pass
class Bar(Foo):
pass
issubclass(Bar, Foo)
str和repr
直接上代码
class Foo(object):
def __init__(self,name):
self.name = name
def __str__(self):
return '%s str method in class Foo'%self.name
def __repr__(self):
return '%s repr method in class Foo'%self.name
a = Foo('egon')
print('%s in Foo'%a)
print('%r in Foo'%a)
注意:
1、在一个类中,如果这两种方法都存在,在执行打印实例对象的时候将会执行str。
2、在语法糖的帮助下,%r 将会调用repr方法。
反射(自省):
class Foo:
f = '类的静态变量'
def __init__(self,name,age):
self.name=name
self.age=age
def say_hi(self):
print('hi,%s'%self.name)
obj=Foo('egon',73)
#获取属性 getattr
print(getattr(obj,'asdf','doesn\'t exist')) ####若对象中的属性不存在,则打印最后后面的结果。
#检测是否含有属性 hasattr
print(hasattr(obj,'name')) #注意,第二个参数要是字符串。
print(hasattr(obj,'say_hi'))
# 为对象设置属性
setattr(obj,'sb',True)
setattr(obj,'show_name',lambda self:self.name + 'sb')
print(obj.__dict__)
print(obj.show_name(obj))
#删除对象属性
delattr(obj,'age')
delattr(obj,'sdf') ### 属性不存在则报错
反射也适用于类
class Foo(object):
staticField = "old boy"
def __init__(self):
self.name = 'wupeiqi'
def func(self):
return 'func'
@staticmethod
def bar():
return 'bar'
print(getattr(Foo, 'staticField'))
print(getattr(Foo, 'func'))
print(getattr(Foo, 'bar'))
getitem、setitem、delitem
class Bar(object):
def __getitem__(self, key):
print('__getitem__', key)
def __setitem__(self, key, value):
print('__setitem__', key, value)
def __delitem__(self, key):
print('__delitem__', key)
obj = Bar()
result = obj['k1'] # 自动触发执行 __getitem__
obj['k2'] = 'parker' # 自动触发执行 __setitem__
del obj['k1'] # 自动触发执行 __delitem__
绑定方法与非绑定方法
类中定义的函数分成两大类
绑定方法(绑定给谁,谁来调用就自动将他本身当作第一个参数传入)
1、绑定到类的方法:用classmethod装饰器装饰的方法,为类量身定制类. bound_method(), 自动将类当作第一个参数传入,(其实对象也能调用,但仍将类当作第一个参数传入)
2、绑定到对象的方法:没有被任何装饰器装饰的方法。
为对象量身定制。对象.bound_method(),自动将对象当作第一个参数传入
(属于类的函数,类可以调用,但是必须按照函数的规则来,没有自动传值这么一说)
非绑定方法:用staticmethod装饰器装饰的方法
1、不与类或对象绑定,类和对象都能调用,但是没有自动传值这么一说,就是一个普通工具而已
注意:与绑定到对象的方法区分开,在类中直接定义的函数,没有被任何装饰器装饰的,都是绑定到对象的方法,可不是普通函数,对象调用方法会自动传值,而staticmethod装饰的方法,不管谁来调用,都没有自动传值一说
class
How to get the type of an object without using the type() function?
a = '111'
print(a.__class__)
slots
1.slots是什么:是一个类变量,变量值可以是列表,元祖,或者可迭代对象,也可以是一个字符串(意味着所有实例只有一个数据属性)
2.引子:使用点来访问属性本质就是在访问类或者对象的dict属性字典(类的字典是共享的,而每个实例的是独立的)
3.为何使用slots:字典会占用大量内存,如果你有一个属性很少的类,但是有很多实例,为了节省内存可以使用slots取代实例的dict
当你定义slots后,slots就会为实例使用一种更加紧凑的内部表示。实例通过一个很小的固定大小的数组来构建,而不是为每个实例定义一个
字典,这跟元组或列表很类似。在slots中列出的属性名在内部被映射到这个数组的指定小标上。使用slots一个不好的地方就是我们不能再给实例添加新的属性了,只能使用在slots中定义的那些属性名。
4.注意事项:slots的很多特性都依赖于普通的基于字典的实现。另外,定义了slots后的类不再 支持一些普通类特性了,比如多继承。大多数情况下,你应该只在那些经常被使用到 的用作数据结构的类上定义slots比如在程序中需要创建某个类的几百万个实例对象 。
关于slots的一个常见误区是它可以作为一个封装工具来防止用户给实例增加新的属性。尽管使用slots可以达到这样的目的,但是这个并不是它的初衷。 更多的是用来作为一个内存优化工具。
class A:
__slots__ = ['Parker','Zhang']
def __init__(self):
pass
a = A()
a.Parker = 1
# a.zhang = 12 ##无法给实例添加新属性
# print(a.__dict__) #报错
print(a.__slots__) ######['Parker', 'Zhang']
总结: slots的好处: 节省内存,由slots代替dict
enter和exit (上下文管理器)
官网链接:
https://docs.python.org/2/library/stdtypes.html
Python’s with statement supports the concept of a runtime context defined by a context manager. This is implemented using two separate methods that allow user-defined classes to define a runtime context that is entered before the statement body is executed and exited when the statement ends.
An example of a context manager that returns itself is a file object. File objects return themselves from enter() to allow open() to be used as the context expression in a with statement.
Exit the runtime context and return a Boolean flag indicating if any exception that occurred should be suppressed. If an exception occurred while executing the body of the with statement, the arguments contain the exception type, value and traceback information. Otherwise, all three arguments are None.
Returning a true value from this method will cause the with statement to suppress the exception and continue execution with the statement immediately following the with statement. Otherwise the exception continues propagating after this method has finished executing. Exceptions that occur during execution of this method will replace any exception that occurred in the body of the with statement.
The exception passed in should never be reraised explicitly - instead, this method should return a false value to indicate that the method completed successfully and does not want to suppress the raised exception. This allows context management code (such as contextlib.nested) to easily detect whether or not an __exit__() method has actually failed.
代码:
class Open(object):
def __init__(self,name):
self.name = name
def __enter__(self):
print('enter 方法')
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit 方法') #######4来到__exit__方法
print(exc_type)
print(exc_val)
print(exc_tb)
return True ####return True 后 ,with后面的代码会正常执行,打印 'the final'
with Open('a.txt') as f: ####1.首先进入__enter__方法
print('with 方法') #####2.来到with 方法
sss ######3.抛出异常 (要是不抛出异常,exit方法中的三个参数值为None)
print('the final')
1.使用with语句的目的就是把代码块放入with中执行,with结束后,自动完成清理工作,无须手动干预
2.在需要管理一些资源比如文件,网络连接和锁的编程环境中,可以在exit中定制自动释放资源的机制,你无须再去关系这个问题,这将大有用处
实际应用:
class Open(object):
def __init__(self,name,mode):
self.name = name
self.mode = mode
def __enter__(self):
self.opened = open(self.name,self.mode) # 在enter方法中打开文件并返回文件名称
return self.opened # 返回值就是as后面的writer
def __exit__(self, exc_type, exc_val, exc_tb): #在 close方法中关闭文件
self.opened.close()
with Open('mytext.txt','w') as writer:
writer.write('hello world')
装饰器实现上下文管理
from contextlib import contextmanager
@contextmanager
def open_file(filename,mode):
try:
f = open(filename,mode)
yield f
finally:
f.close()
with open_file('bbb.txt','w') as f:
f.write('I am so awesome')
print(f.closed)
iter方法
类实例化出的对象本身不可被循环,当在父类中加入iter方法后,遍历一个对象将会执行此方法:
class Reverse(object):
def __init__(self,data):
self.data = data
def __iter__(self):
for i in self.data:
yield i
data = Reverse([1,2,3,4])
for datum in data:
print(datum)
class Reverse(object):
def __init__(self,data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def __next__(self):
if self.index == 0:
raise StopIteration
self.index -= 1
return self.data[self.index]
rev = Reverse([1,2,3,4])
i = iter(rev)
for char in i:
print(char)
判断函数与方法的区别:
from types import FunctionType,MethodType
class Foo(object):
def __init__(self):
pass
def func(self):
pass
obj = Foo()
print(isinstance(obj.func,MethodType)) #True
print(isinstance(obj.func,FunctionType)) #False
print(isinstance(Foo.func,MethodType)) #False
print(isinstance(Foo.func,FunctionType)) #True
方法,无需传入self参数
函数,必须手动传self参数
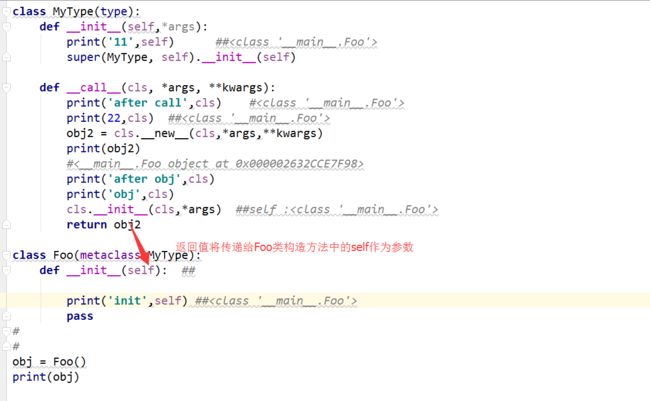
元类
class MyType(type):
def __init__(self, *args,**kwargs):
print(11)
super().__init__(self)
def __call__(self, *args, **kwargs):
print(22)
obj = self.__new__(self, *args, **kwargs)
self.__init__(obj,*args)
return obj
class Foo(metaclass=MyType):
def __init__(self, name):
print(44)
self.name = name
def __new__(cls, *args, **kwargs):
print(33)
return object.__new__(cls)
# 第一阶段:解释器从上到下执行代码创建Foo类
# 第二阶段:通过Foo类创建obj对象
obj = Foo('Parker')
print(obj)
print(obj.name)
元类总结,Python中一切皆对象,类本质上也是对象,有type创建产生,因此上述代码可以理解为:
1、在解释器执行到class Foo时,就会触发type的init方法,因而创建Foo这个类
2、在实例化Foo时,由于Foo(),所以执行创建其类(type)的call方法,call方法将会调用init方法来来执行call方法,再由call方法来触发new方法,创建类后,开始执行Foo类的init方法,初始化对象。
isinstance 和 type

判断对象是否属于一个类时,isinstance() 不如type准确
对象之间的相加
class Foo(object):
def __init__(self,age):
self.age = age
def __add__(self, other):
return Foo(obj1.age + other.age)
obj1 = Foo(11)
obj2 = Foo(12)
obj3 = obj1 + obj2
print(obj3.age)
私有属性的方法
class A(object):
__age = 23
def __init__(self,name):
self.__name = name
a = A('Parker')
print(a._A__age) # 对象._类__字段
print(a._A__name)