tensorboard的使用——一mnist手写库为例
定义变量的汇总函数 variable_summaries,计算变量的mean,stddev,max和min,对这些标量使用tf.summary.scalar进行记录和汇总;
使用tf.summary.histogram记录变量的直方图数据。
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)其中tf.RunOption()定义TensorFlow运行选项,其中设置trace_level为FULL_TRACE,并使用tf.RunMetadata()定义TensorFlow运行的元信息,这样可以记录训练时运算时间和内存占用等方面的信息。
saver = tf.train.Saver()
for i in range(max_steps):
if i % 10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summaries, and train
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
saver.save(sess, log_dir+"/model.ckpt", i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()tensorboard运行结果

图1

图2

图3
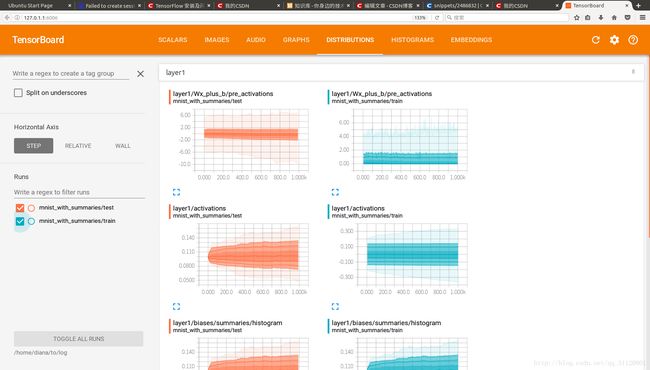
图4

图5

图6
SCALARS窗口:显示tf.summary.scalar()函数记录的数据。其中Smoothing参数的作用是控制对曲线的平滑处理,数值越小越接近真实值,但波动较大;数值越大越平缓(图1)
IMAGES窗口:所有在tf.summary.image()中汇总的图片数据都可以在这里看到.(图2)
GRAPHS窗口:可以看到整个计算图的结构。其中左边面板的Session runs选择之前记录过得run_metadata的训练元信息,这样可以查看某轮迭代计算的时间消耗,内存占用等情况。(图3)
DISTRIBUTIONS窗口:查看之前记录的各个神经网络层输出的分布。(图4)
HISTOGRAMS窗口:一直方图的形式显示每一步训练后的神经网络层的输出。(图5)
EMBEDDINGS窗口:可以看到降维后的嵌入向量的可视化效果,我们使用tf.save.Saver保存整个模型后,就可以让TensorBoard自动对模型中所有二维的Variable进行可视化。这个功能对于Word2Vec模型和语言模型非常有用。(图6)