redis 集群 gossip 源码分析
gossip
以后都在 github 更新,请戳 redis 集群->gossip
目录
- cluster bus
- 什么时候会发送消息
- ping
- pong
cluster bus
来自 cluster-tutorial
每一个 Redis 集群节点需要两条 TCP 连接, 通用的 TCP 端口用来和客户端进行交互, 比如 6379. 还有一个从通用端口加上一万以后的端口, 比如 16379
第二个数值比较高的端口是用来作为集群间的通信用的, 那是一个节点之间交换信息所使用的的二进制协议. 它的使用场景有宕机检测, 配置更新, 故障转移的授权等. 客户端应该通过普通的端口进行连接而不是尝试通过这个端口进行连接. 并且, 你需要保证你的防火墙同时打开这两个端口, 否则的话集群间的节点将无法进行交流
命令端口和集群通信端口之间的差值是固定的, 就是 10000
注意, 一个能正常工作的集群每个节点需要具备如下条件
集群中所有节点正常的客户端交互端口(通常是 6379) 需要对所有可用的客户端开放, 并且集群中所有的节点也需要互相开放这个端口(key 转移的时候需要用到)
集群间的通信端口(普通端口 + 10000) 需要对集群中所有其他的节点开放
如果你不把这两个 TCP 端口都进行开放的话, 你的集群跑起来之后可能会有问题
集群间的通信使用了一个不同的, 二进制的协议, 用来做集群间节点的数据通信, 这个协议比起原来的协议, 耗费更少带宽和处理时间, 也更适合在节点之间交换数据
什么时候会发送消息
Redis 当前支持以下几种消息类型
#define CLUSTERMSG_TYPE_PING 0 /* Ping */
#define CLUSTERMSG_TYPE_PONG 1 /* Pong (回复 Ping 消息的时候用) */
#define CLUSTERMSG_TYPE_MEET 2 /* Meet 加入集群的消息 */
#define CLUSTERMSG_TYPE_FAIL 3 /* 把某个节点标记成故障 */
#define CLUSTERMSG_TYPE_PUBLISH 4 /* 发布订阅时发布消息推送 */
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 5 /* 我可以进行故障转移吗 ? */
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 6 /* 可以, 我给你投票 */
#define CLUSTERMSG_TYPE_UPDATE 7 /* 集群节点配置信息 */
#define CLUSTERMSG_TYPE_MFSTART 8 /* 手动暂停这个节点, 进行手动故障转移 */
#define CLUSTERMSG_TYPE_MODULE 9 /* 集群模块 API 消息 */
#define CLUSTERMSG_TYPE_COUNT 10 /* 消息类型的总数 */
clusterCron 会遍历每个节点, 如果当前的节点和被遍历的节点之间没有活跃的连接, 则调用 clusterSendPing 发送 PING 消息
clusterCron 也会每秒随机对 1 个节点进行 PING 消息发送
/* 每10次循环随机的 Ping 一些节点, 通常我们每秒都会随机对一个节点发送 PING 消息 */
if (!(iteration % 10)) {
int j;
/* 随机检查几个节点, 并 PING 其中 pong_received 时间最晚的那个节点 */
for (j = 0; j < 5; j++) {
de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
/* 不去 ping 那些已经断开或者当前有一个活跃的 ping 的节点 */
if (this->link == NULL || this->ping_sent != 0) continue;
if (this->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE))
continue;
if (min_pong_node == NULL || min_pong > this->pong_received) {
min_pong_node = this;
min_pong = this->pong_received;
}
}
if (min_pong_node) {
serverLog(LL_DEBUG,"Pinging node %.40s", min_pong_node->name);
clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING);
}
}
clusterCron 会再次遍历所有节点, 并在以下情况发生时发送 PING 消息
/* 如果当前的节点和这个节点之前没有正在发送的 PING 消息, 并且收到的 PONG 比集群超时时间的一半还要长,
* 那么给这个节点发送一个新的 PING 消息, 这个策略可以保证所有的节点都和当前的节点之间的 PING 延时不会太高 */
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/* 如果我们是一个 master, 并且其中的一个 slaves 要求一个手动的故障转移, 那么持续的对这个节点进行 PING */
if (server.cluster->mf_end &&
nodeIsMaster(myself) &&
server.cluster->mf_slave == node &&
node->link)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
所以, 如果我们是 nodeC, 我们会和 nodeA, nodeB 和所有 nodeA 的 slaves 之间保持连接, 并且根据上面的规则不间断的发送 PING 消息

ping
这是两个节点之间的 MSG 的结构
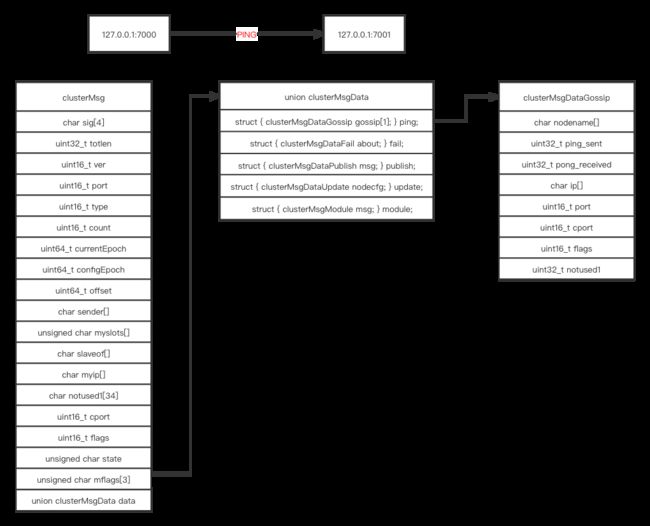
这是 PING 消息的结构和内容

clusterMsg 存储和发送者的一些信息, 比如 epoch 数量, 槽的位映射, 普通端口号, 集群交互端口号等
在 clusterMsgData 字段中, 每一条 gossip 消息都会带上发送者存储的部分集群节点信息, 所以在几次 gossip PING/PONG 握手后, 一个节点最终会获得所有其他节点的新的状态
clusterMsgData 中的实际节点信息数目为 min(freshnodes, wanted)
/* freshnodes 是我们最多可以增加到尾部的节点信息数目
* 所有可用的节点数目 - 2(我们自己和我们现在正在发送的目标节点)
* 实际上可能有比上面公式更少的能用的节点, 比如那些在握手阶段的, 断线的都未考虑进去
*/
int freshnodes = dictSize(server.cluster->nodes)-2;
/*
/* 有多少个节点信息需要被添加到 gossip 消息中 ? 所有节点数的 1/10
* 并且至少为 3 个
* 1/10 的原因在 redis/src/cluster.c 源码注释中
* 主要是这个比例能在一定时间范围内收到错误报告信息
*/
wanted = floor(dictSize(server.cluster->nodes)/10);
所以, clusterMsgData 中节点的选择是随机的
pong
每一条 PING 消息都会有一条 PONG 消息作为回复, PING 消息的回复就是 PONG 消息, PONG 的构造和 PING 消息基本一致, 除了 hdr->type 中的类型不一样
int clusterProcessPacket(clusterLink *link) {
/* ... */
/* PING 和 MEET 消息需要生成一条 PONG 消息作为回复*/
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_MEET) {
/* ... */
clusterSendPing(link,CLUSTERMSG_TYPE_PONG);
}
/* ... */
}
/* 创建消息头, hdr 必须指向拥有 sizeof(clusterMsg) 空间大小的缓冲区 */
void clusterBuildMessageHdr(clusterMsg *hdr, int type) {
/* ... */
hdr->ver = htons(CLUSTER_PROTO_VER);
hdr->sig[0] = 'R';
hdr->sig[1] = 'C';
hdr->sig[2] = 'm';
hdr->sig[3] = 'b';
hdr->type = htons(type);
memcpy(hdr->sender,myself->name,CLUSTER_NAMELEN);
/* ... */
}
如果你对其他类型的消息感兴趣, 请参考 redis/src/cluster.c 中的源码