【JVM和性能优化】5. 深入了解性能优化
对于Java 程序来说宏观上一般分为三层,

性能指标
常用的性能测试(工具Jmeter)指标一般为下面几个:
Jmeter教程,Jmeter参数解析,Jmeter
- 响应时间:
- 提交请求时跟请求返回之间的使用时间,一般公司关注的是平均响应时间。
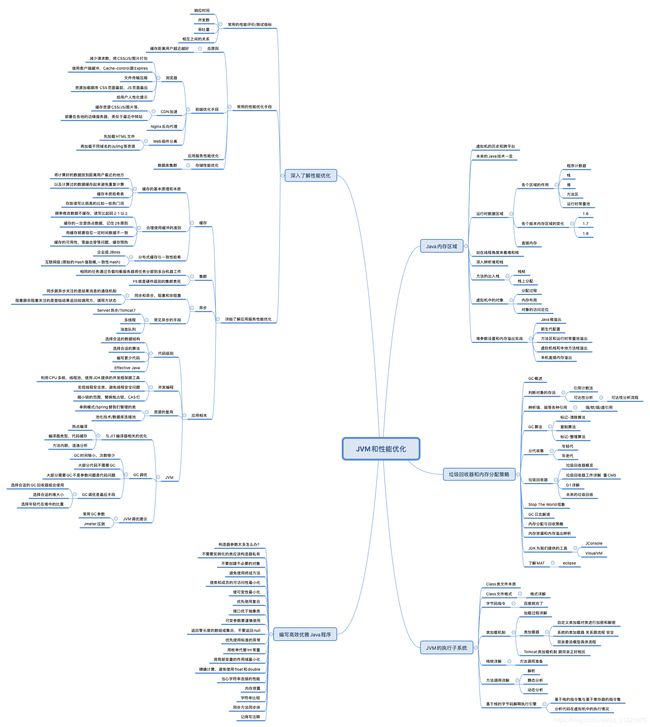
平常用到的一些时间指标级别如图:
2. 并发数
指同一时刻对服务器有实际交互的请求数,这个数字一般跟网站在线用户数想关联,一般为网站在线用户的5%~15%。
PS:注意并发跟并行的区别哦。
- 吞吐量
系统对单位时间内完成对工作量的度量。
比如每分钟的数据库事务,每分钟Web服务器命中数。
这些指标之间的关系一般是响应时间越短,吞吐量越大;响应时间越长,吞吐量越小;但是吞吐量越大,响应时间不一定越短。
性能优化
一般情况下,业务代码运行起来的实现规则
- 首先保证业务代码可以正常运行
- 可以处理异常情况。
- 要发现异常跟耗时点,进行系统性能测试跟异常测试,不可相信主观意识。
- 最终才是各个环节的性能优化,切勿过早优化 by Donald Knuth。
- 优化寻找系统瓶颈,逐步优化。
前端优化
浏览器
- 减少请求次数
Http请求是无连接的,所以如果我们能减少请求便是一种手段,合并CSS/JS/图片 这些数据,一次性传送给客户端。
HTTP1.1 的**keep-alive **可以确保 HTTP 请求不重复建立。
- 使用客户端缓冲
对于CSS/JS/IMG 这些静态数据,采用缓存到浏览器的方式。
Cache-Control:相对时间,指浏览器自我控制的时间间隔
Expires :服务器发送过来的以服务器为准的绝对时间。
- 启用压缩
服务器端对JS/CSS等文件进行gzip压缩,服务器进行解压缩。对文本文件进行压缩可节省80%的空间。比如jquary的一些官方文件,传输的时候把空格都节省了。
- 资源文件加载顺序
我们写HTML文件,里面会包含CSS跟JS,一般是CSS放最前面,JS放最后面
- 浏览器会在下载完成全部css之后才对整个页面进行渲染,因此最好的方式是将css放在页面最上面,让浏览器尽快启动下载css。
- 因为js的运行是要占用主线程的,也就是在js运行的时候,页面是不进行解析和渲染的,如果js写在最前面,如果不做特殊处理,除了能提供依赖以外和做一些预处理之外,连dom节点都无法捕捉,导致功能受到了很大的限制
- 给予用户友善提示
即使系统性能再慢也要跟用户有交互,点了没有任何反应就无语了让客户。
CDN加速
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。将CSS/JS等东西放到距离我们用户网关最近的地方。
通俗一点讲什么是CDN,简单一点理解就是一个中转站,在给网站主提供一定的方便,用户也可以享受到一定的方便,在提高打开网站和访问速度上面都有大大的提升,使用CDN的好处显而易见。CDN也是缓存实现对一种机制,不过比较贵。
反向代理缓存
可将Nginx做为Apache的反向代理服务器,反向代理服务器不使用缓存时,吞吐率会下降,因为原本直达Web的请求,现在绕路转达,处理时间必然会增加。
可将Web服务器和应用服务器分离,前者处理一些静态内容,并作为反向代理,后者处理动态内容。
WEB组件分离
网站的静态网页HTML、JavaScript脚本、CSS样式、图片、动态数据称为网站的Web组件。如果用户请求上面东西全部从同一个网址获取那么性能会收到影响。
那么我们可以吧不同的资源放到不同的服务器上。比如我们有顶级域名:www.sowhat.com,我们可以用若干二级域名来存储不同的类型数据。
- static.sowhat.help #用于存放静态数据
- api.sowhat.help #存放动态数据
- css.sowhat.help #存放css
- js.sowhat.help #存放js
- upload.sowhat.help #存放图片、音频、文档
应用服务器优化
缓存
网站优化优先考虑使用缓存进行性能优化,用了缓存访问数据速度快。一些计算结果也可以放置重复计算。
缓存:在内存中我们用各种基本容器存储数据都是缓存,memcached跟redis, 这些都是缓存。缓存距离用户越近越好。缓存的本质就是一个Hash表。
缓存原则:
- 频繁修改数据不可缓存,读写比起码要2:1以上。
- 缓存一定是热点数据,借鉴28定律,80%的访问在20%的数据。
弊端:缓存用了就要考虑数据的一定时间不一致性,还要考虑缓存雪崩,击穿,穿透,缓存预热等问题。
工业中一般是分布式缓存:
Jboss:所以集群点时间都保持相同数据,需实时更新同步。
Hash算法实现分布式存储,每个机器都存储一部分数据。很早前一般是Hash(参数)%机器数 来实现缓存,后来又引入来 一致性哈希跟虚拟一致性哈希
集群
相同的任务通过nginx实现反向代理,然后业务运算端通过集群来实现集群的扩展。比如我们常用的Redis集群,MySQL集群,Hadoop集群等都是为提供系统性能以及业务稳定性来搞的。硬件级别的集群比如F5也OK不过较贵 。
异步
关于同步异步的概念跟区别可参考此文同步异步
- 同步跟异步:关注的是服务方的结果信息的通信机制。
- 阻塞跟非阻塞:关注的是调用方等待结果时候的状态。
常见的异步手段
- Servlet异步: 服务器收到服务器请求后,开启一个A线程,然后A线程将该任务打包发给后端的一个集群服务B,B搞定后再把信息发给A,然后最终信息返回。
- 多线程:线程池咯当然是
- 消息队列:任务接后打包然后放到任务队列。
程序
- 代码级别
- 选择合适的数据结构,是用LinkedList 还是ArrayLIst呢,要根据查询多还是增删多来考虑。
- 根据数据量大小选择合适的算法,Java的Arrays.sort() 底层是快排+插入排序,而C++ 的STL排序底层实现sort()底层是快排/堆排/插排合并使用。
- 编写更少的代码,业务总逻辑那么多,如果系统给我们写的越多底层优化越多那么我们需要写的就越少,bug就更少。
- 并发编程
- 充分利用CPU多核,使用线程池,尽量使用JUC提供的类,
- 避免线程安全问题,资源冲突,锁的范围,读写锁 CAS锁,ThreadLOcal等等
- 资源复用
- 比如Spring框架给我管理的Bean 都是单例的对象。
- 比如数据库连接这样耗时任务尽量用连接池。
JVM中JIT
日常关注中经常用到的其实是JIT(just in time ) 也就是即时编译器,JIT的功能就是可以把翻译过的机器码选择性的保存起来,以备下次使用。

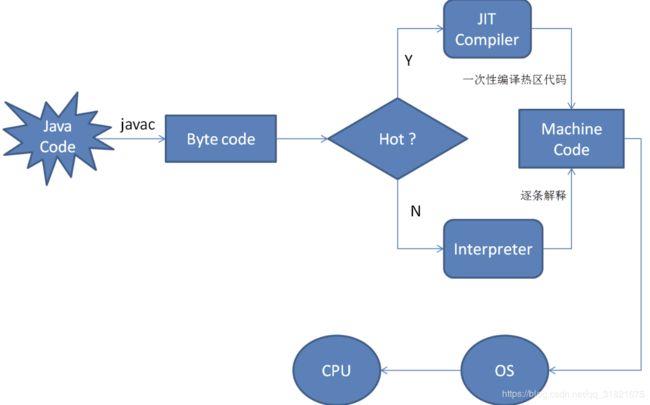
热点编译:
当 JVM 执行代码时,它并不立即开始JIT代码。这主要有两个原因:
- 首先,如果这段代码本身在将来只会被执行一次,那么从本质上看,编译就是在浪费精力。因为将代码翻译成 java 字节码相对于编译这段代码并执行代码来说,要快很多。
- Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能,所以当字节码被 JIT 编译为机器码的时候,此时可以认为是编译型语言类。
JIT模式:
通过Java -version 来查看编译器模式

JIT默认模式
默认两种
- Client 模式:当虚拟机运行在-client 模式的时候,启动快,使用的是一个代号为 C1 的轻量级编译器,
- Server 模式:–server 模式启动的虚拟机采用相对重量级代号为 C2 的编译器。速度较慢,但是一旦运行起来后,性能将会有很大的提升。C2 比 C1 编译器编译的相对彻底,服务起来之后,性能更高。
- 新添加的分层编译, -xx:+TieredCompilation,多层编译经常是长时运行应用程序的最佳选择,短暂应用程序则选择毫秒级性能的 client 编译器。
同时我们开启JIT后,要为代码缓存区设置参数
–XX:ReservedCodeCacheSize=Nflag
在JDK7的默认范围是32M~48M,JDK8默认范围240M,并且这个内存空间的设置后 虚拟机会单独申请内存空间 跟堆栈是无关哦。
编译阈值
热点编译的阈值有两个的和来定,并且这个是一定时间段内,会有计数器的衰减的,可能下一个时间段就减半了。
- 方法调用计数器
- 循环回边计数器
同时呢,在JIT运行的时候会开启单独的线程来进行干编译的这个活。
方法内联
把函数调用的方法直接内嵌到方法内部,减少函数调用的次数。内联默认开启,如果关闭了性能大概降速50%。
public void SetAge(int age){
this.age = age
}
-------JIT 优化后直接就是 如下,避免类方法调用。
this.age = age
- 编译后的字节码小于325字节,才可能会内联。
- 编译后字节码小于35字节,一定会内敛。所以自定义函数一般尽可能少哦。
逃逸分析
逃逸分析 :虚拟机会经常性的执行这个代码并且很复杂,轻易不要懂缺省值。
GC调优
大部分情况下Java应用程序是不需要GC调优的,如果需要GC调优了一般不是参数问题就是代码问题,先从自身找原因。
目的:
- GC时间够少。
- GC次数够少。
方法:
- 选择合适的GC回收器来组合。
- 选择合适的堆大小。
- 选择合适年轻代在堆中的比例。
- 尽可能减少full GC 的发生跟时间。
指标:
- minor GC 单次小于50ms,频率10秒以上。说明年轻代OK。
- Full GC 单次小于1秒一下,频率10分钟以上,说明年老代OK。
GC常用参数
- -Xms5m 设置JVM最大可用内存为5M
- -Xmx5m 设置JVM初始内存为5M。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
- -XX:+PrintGCDetails 输出GC日志信息
- -XX:+HeapDumpOnOutOfMemoryError 当JVM发生OOM时,自动生成DUMP文件
- -Xloggc:gcc.log 将GC信息输出到制定文件,默认是跟项目/目录一样
- -XX:+UseSerialGC 自由制定年轻代使用的GC
要学会看GC日志
[0.172s][info ][gc,start ] GC(1) Pause Young (Allocation Failure)
[0.177s][info ][gc,heap ] GC(1) DefNew: 1856K->192K(1856K)
DefNew表示新生代使用Serial串行GC垃圾收集器,GC前用空间,GC后用空间,总空间
[0.177s][info ][gc,heap ] GC(1) Tenured: 714K->2326K(4096K) 表示老年区对使用情况。
[0.177s][info ][gc,metaspace ] GC(1) Metaspace: 6245K->6245K(1056768K) 元数据空间,回收前所用值 回收后所用值 总值
[0.177s][info ][gc ] GC(1) Pause Young (Allocation Failure) 2M->2M(5M) 4.335ms
年轻代回收耗时
[0.177s][info ][gc,cpu ] GC(1) User=0.00s Sys=0.00s Real=0.01s
CPU GC总共耗时等信息
GC策略:
- 新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC
日志分析新生代空间大小分配是否合理,适当通过-Xmn命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。- 对于大对象,如果直接在年轻代分配会导致大多年轻代小对象被拥挤到年老代,此时要合理设置-XX:PretenureSizeThreshold 参数,启动空间分配担保。
- 合理设置进入老年代对象的年龄,-XX:MaxTenuringThreshold
- 设置稳定的堆大小,堆大小设置有两个参数:-Xms 初始化堆大小,-Xmx 最大堆大小。
参考
不错的JIT讲解