《Spark高级数据分析》ChapterII 读书笔记
Chapter II 用Scala和Spark进行数据分析
前言
练习的平台是在三台主机组成的服务器上搭建Spark集群,同时安装Jupyter Notebook以及加载了spark内核,然后在自己电脑的windows浏览器中访问jupyter notebook来进行scala编程。
数据清洗是数据科学项目中的第一步,往往也是最重要的一步。俗话说“磨刀不误砍柴工”,花精力去做好数据清洗这一步骤往往能在后面的算法运行中起到至关重要的作用。
2.1 数据科学家的Scala
Spark框架是用Scala语言编写的,在向数据科学家介绍Spark时,采用与底层框架相同的编程语言有许多好处,比如性能开销小(不用花费代价在不同的环境中传递代码和数据)、能用上最新的版本和最好的功能、有助于更好的了解Spark的原理等等。
2.2 Spark编程模型
Spark编程属于数据集,而数据集往往存放在分布式持久化存储之上,比如Hadoop分布式文件系统HDFS。编写Spark程序通常包括一系列相关步骤:
- 在输入的数据集上定义一组转换
- 调用action,用以将转换后的数据集保存到持久存储上,或者把结果返回到驱动程序的本地内存。
- 运行本地计算,本地计算处理分布式计算的结果。本地计算有助于你确定下一步的转换和action。
要想理解Spark,就必须理解Spark框架提供的两种抽象:存储和执行。Spark优美的搭配这两类抽象,可以将数据处理管道中的任何中间步骤缓在内存里已备后用。
2.4 小试牛刀:Spark shell和SparkContext
本文的数据集来自加州大学欧文分校机器学习资料库(UC Irvine Machine Learning Repository),使用以下命令下载数据:
$ mkdir linkage
$ cd linkage/
$ curl -o donation.zip http://bit.ly/1Aoywaq
$ unzip donation.zip
$ unzip 'block_*.zip'需下载,或者百度云链接:http://pan.baidu.com/s/1c29fBVy
刚好有Hadoop集群,可以先在HDFS上为块数据创建一个目录,然后将数据集文件复制到HDFS上。
$ hadoop fs -mkdir linkage
$ hadoop fs -put block_*.csv linkage上传成功后截图 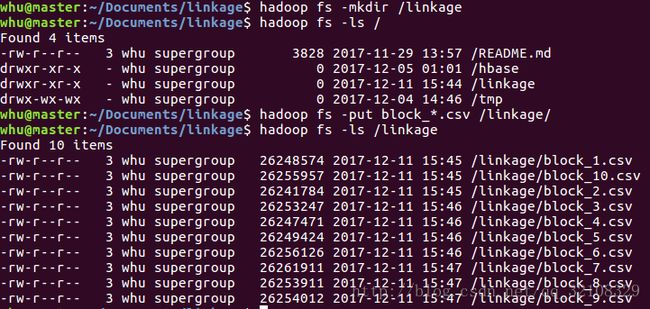
我自己的Spark版本是Spark-2.0.1,书中是在Spark-shell里编程,我这里就选择另一种方式,即jupyter notebook。但这里还是简单介绍以下spark-shell。
spark-shell是一个Scala语言的REPL(交互式解释器,Read, Evaluate, Print, Loop),就是可以得到实时反馈的结果,不需要每次自己想知道结果时要手动编译运行。可以在bin/spark-shell –master ?? 来指定master,这里采用本地模式。
这里简要介绍一下Spark的核心数据结构RDD(Resilient Distributed Dataset,弹性分布式数据集)。RDD是Spark所提供的最基本的抽象,代表分布式数据集中多台机器上的对象集合。Spark有两种方法可以创建RDD:
- 用SparkContext基于外部数据源创建RDD,外部数据源包括HDFS上的文件,通过JDBC访问数据库表(??)或Spark shell中创建的本地对象集合;
- 在一个或多个已有RDD上执行转换操作来创建RDD,这些转换操作包括记录过滤(filter),对具有相同键值的记录做汇总(reduceByKey),把多个RDD关联在一起(zip)等等。
RDD以分区(partition)的形式分布在集群的多个机器上,每个分区代表着数据集的一个子集。分区定义了Spark中数据的并行单位。Spark框架并行处理多个分区,一个分区内的数据对象则是顺序处理。创建RDD最简单的方法是在本地对象集合上调用SparkContext的parallelize方法。
val rdd = sc.parallelize(List(1, 2, 3, 4))
rdd.first
## output : 1或者要在分布式文件系统上的文件或目录创建RDD,可以给textFile方法传入文件或目录的名称:
val rdd = sc.textFile("hdfs://some/path.txt")如果输入是目录而不是单个文件,Spark会把该目录下的所有文件作为RDD
的输入。最后值得注意的是,实际上Spark并未将数据读取到客户端机器或集群内存中,当需要对分区内的对象进行计算时,Spark才会读入输入文件的某个部分,然后应用其他RDD定义的后续转换操作。
将书中的某一段文字粘贴过来(个人觉得挺有用的):
REPL 与编译
除了交互式 shell,Spark 也支持编译程序。我们通常推荐使用 Maven 来编译程序和管理依赖关系。本书在 GitHub 的资料库的 simplesparkproject/ 目录下包含了一个完整的Maven 工程,你可以用它作为开端。
现在你有两个选择:shell 和编译程序,但测试和构建数据处理程序时该选哪个呢?通常在初始阶段工作可能全部用 REPL 完成。REPL 可以加快原型开发,使迭代更快,让你的想法很快能看到结果。但随着程序越来越大,在一个文件中维护大量代码就变得很笨拙了,这时解释 Scala 程序也要消耗更多时间。如果数据量巨大,情况会更糟,经常会出现一个操作导致 Spark 应用崩溃或 SparkContext 不可用。如果发生这种情况,意味着所有的工作和输入的代码都丢失了。这时我们往往应该采用混合模式。最前面的开发工作在 REPL 里完成,随着代码逐渐成熟,将代码移到编译库里。可以在spark-shell 中引用已编译好的 JAR,只要给 spark-shell 设置 –jars 参数即可。这样的话,如果使用得当,就不用频繁重新编译 JAR,同时 REPL 可以支持快速代码迭代和逐步成熟方式。
如何引用外部的 Java 和 Scala 类库呢?要编译引用了外部类库的代码,需要在工程的Maven 配置文件(pom.xml)中指定所需的类库。要运行依赖外部类库的代码,需要在 Spark 进程中通过 classpath 将所需类库的 JAR 文件包含进来。为此一种好的做法是使用 Maven 来打包 JAR,使生成的 JAR 包含应用程序的所有依赖文件。接着在启动shell 时通过 –jars 属性引用该 JAR。这种方法的优点是依赖只需要在 Maven 的 pom.xml 中指定一次即可。如何进行设置,请参考本书 GitHub 资料库 simplesparkproject/目录。同 时 可 以 用 SPARK-5341 跟 踪 如 下 功 能 的 开 发 进 度: 在 spark-shell 里 直 接 指 定Maven 资料库,从 Maven 资料库获取的 JAR 自动设置在 Spark 的 classpath 里。
2.5 把数据从集群上获取到客户端
RDD有许多方法,我们可以用这些方法从集群读取数据到客户端机器上的 Scala REPL 中。比如first方法,像客户端返回RDD的第一个元素;或者collect方法,向客户端返回一个包含所有RDD内容的数组;或者用take(num)方法,向客户端返回包含指定数量num的记录的数组。 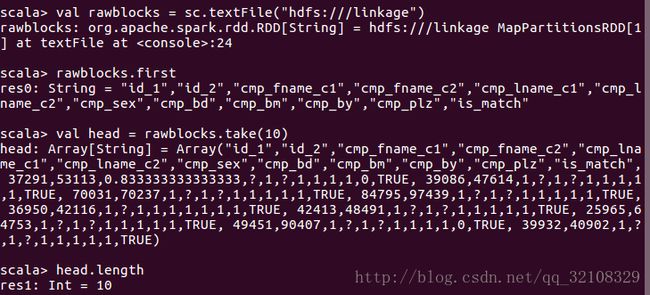
创建 RDD 的动作(action)并不会导致集群执行分布式计算。相反,RDD 只是定义了作为计算过程中间步骤的逻辑数据集。只有调用 RDD 上的 action 时分布式计算才会执行。比如count()方法,返回RDD中对象的个数;collect动作,返回一个包含RDD中所有对象Array。
我们可以使用foreach方法并结合println来打印出数组中的每个值,并且每行打印一个值。 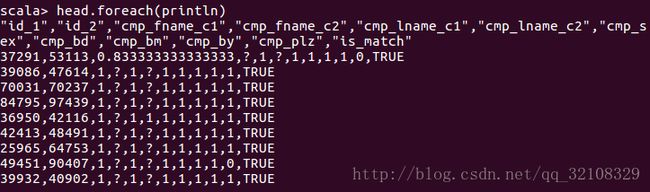
这是一种常见的函数式编程模式。
为了便于后面的处理,我们首先要过滤掉CSV文件的标题行。可以通过编写一个简单的函数来测试一行记录中是否包含该字符串。Scala定义函数的时候,必须为函数参数指定参数类型,为了阅读的方便建议也指明函数的返回类型。
scala> def isHeader(line: String): Boolean = {
| line.contains("id_1")
| }
isHeader: (line: String)Boolean
scala> head.filterNot(isHeader).length
res1: Int = 9
scala> head.filter(x => !isHeader(x)).length
res2: Int = 9
scala> head.filter(!isHeader(_)).length
res3: Int = 9
首先定义了isHeader函数,接着第一种方法使用filterNot的方法过滤出非标题行,第二种方法使用scala的匿名函数,Scala允许使用下划线(_)表示匿名函数的参数,具体怎么用,就是熟练度的问题了。
2.6 把代码从客户端发送到集群
将上述写的方法应用到集群数据上
scala> val noheader = rawblocks.filter(!isHeader(_))
noheader: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at :28
scala> noheader.first
res4: String = 37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE 这太强大了!它意味着我们可以先从集群上采样得到小数据集,在小数据集上开发和调试数据处理代码,等一切就绪后把代码发送到集群界面上处理完整的数据集就行了。
2.7 用元组和case class对数据进行结构化
刚才head数组和noheader RDD中的记录都是逗号分隔的字符串。为了更容易分析这些数据,我们要对这些数据进行处理。
分析head数组的内容,发现数据会有如下结构:
- 前两个字段是整数型ID,代表记录中匹配的两个病人。
- 后面九个值是双精度浮点值,存在数据丢失的情况。
- 最后一个字段是布尔型。
因此我们可以定义一个元组tuple来结构化每条记录。注意访问scala数组元素的时候用圆括号而不用方括号,原因是因为Scala访问数组元素是函数调用,比如head(5)实际上是head.apply(5)。
我们取出一条记录测试一下:
scala> val line = head(5)
line: String = 36950,42116,1,?,1,1,1,1,1,1,1,TRUE
scala> val pieces = line.split(',')
pieces: Array[String] = Array(36950, 42116, 1, ?, 1, 1, 1, 1, 1, 1, 1, TRUE)
scala> val id1 = pieces(0).toInt
id1: Int = 36950
scala> val id2 = pieces(1).toInt
id2: Int = 42116
scala> val matched = pieces(11).toBoolean
matched: Boolean = true这里的split函数和contains函数都是Java String类定义的,但是toInt,toBoolean方法是由Scala是由Scala的StringOps定义的,这里用到了Scala的隐式类型转换。
我们还需要转换双精度浮点数类型的九个匹配分值字段。要一次完成全部转换,可以先用Scala Array类型的slice方法提取出一部分数组的元素,然后调用高阶函数map把slice中每个元素的类型从String转换为Double,注意到存在”?”的缺失数据,所以还需要定义一个函数将”?”处理成为NaN。
scala> def toDouble(s: String) = {
| if ("?".equals(s)) Double.NaN else s.toDouble
| }
toDouble: (s: String)Double
scala> val rawscores = pieces.slice(2, 11)
rawscores: Array[String] = Array(1, ?, 1, 1, 1, 1, 1, 1, 1)
scala> val scores = rawscores.map(toDouble)
scores: Array[Double] = Array(1.0, NaN, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)最后把所有解析代码合并到一个函数,在一个元组中返回所有解析好的值。
scala> def parse(line: String) = {
| val pieces = line.split(',')
| val id1 = pieces(0).toInt
| val id2 = pieces(1).toInt
| val scores = pieces.slice(2, 11).map(toDouble)
| val matched = pieces(11).toBoolean
| (id1, id2, scores, matched)
| }
parse: (line: String)(Int, Int, Array[Double], Boolean)
scala> val tup = parse(line)
tup: (Int, Int, Array[Double], Boolean) = (36950,42116,Array(1.0, NaN, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),true)从元组中获取单个字段的值,我们可以用下标函数,从_1开始,或者用productElement方法,它是从0开始计数的。也可以用productArity方法得到元组的大小。
但实际上通过下标而不是有意义的名称来访问记录元素会让代码很难理解。其实我们希望能创建一个简单的记录类型,它可以根据名称而不是用下标访问字段。Scala提供了case class来实现这一功能。
case class MatchData(id1: Int, id2: Int, scores: Array[Double], matched: Boolean)
def parse(line: String) = {
val pieces = line.split(',')
val id1 = pieces(0).toInt
val id2 = pieces(1).toInt
val scores = pieces.slice(2, 11).map(toDouble)
val matched = pieces(11).toBoolean
MatchData(id1, id2, scores, matched)
}在单条记录上测试无误之后,就可以将解析函数用于集群数据。在noheader RDD上调用map函数:
val parsed = noheader.map(line => parse(line))注意到parse函数并没有实际应用到集群数据上。当在parsed这个RDD上执行某个需要输出的调用时,就会用parse函数把noheader RDD的每个String转换成MatchData类的实例。如果在parsedRDD上执行另一个调用以产生不同的输出,parse函数就会在输入数据上再次计算一遍。
这没有充分利用资源。**数据一旦解析完成,我们想以解析格式把数据保存到集群上,这样就不需要每次遇到新问题时都重新解析。**Spark支持这种使用场景,通过在实例上调用cache方法,可以指示在内存里缓存某个RDD。
缓存
虽然默认情况下 RDD 的内容是临时的,但 Spark 提供了在 RDD 中持久化数据的机制。第一次调用动作并计算出 RDD 内容后,RDD 的内容可以存储在集群的内存或磁盘上。这样下一次需要调用依赖该 RDD 的动作时,就不需要从依赖关系中重新计算 RDD,数据可以从缓存分区中直接返回:
cached.cache()
cached.count()
cached.take(10)
在上述代码中, cache 方法调用指示在下次计算 RDD 后,要把 RDD 存储起来。调用count 会导致第一次计算 RDD。采取( take )这个动作返回一个本地的 Array ,包含RDD 的前 10 个元素。但调用 take 时,访问的是 cached 已经缓存好的元素,而不是从 cached 的依赖关系中重新计算出来的。
Spark 为持久化 RDD 定义了几种不同的机制,用不同的 StorageLevel 值表示。 rdd.cache() 是 rdd.persist(StorageLevel.MEMORY) 的 简 写, 它 将 RDD 存 储 为 未 序 列 化的 Java 对象。当 Spark 估计内存不够存放一个分区时,它干脆就不在内存中存放该分区,这样在下次需要时就必须重新计算。在对象需要频繁访问或低延访问时适合使用StorageLevel.MEMORY ,因为它可以避免序列化的开销。相比其他选项, StorageLevel.MEMORY 的问题是要占用更大的内存空间。另外,大量小对象会对 Java 的垃圾回收造成
压力,会导致程序停顿和常见的速度缓慢问题。Spark 也提供了MEMORY_SER 的存储级别,用于在内存中分配大字节缓冲区以存储 RDD
序列化内容。如果使用得当(稍后会详细介绍),序列化数据占用的空间比未经序列化的数据占用的空间往往要少两到五倍。Spark 也可以用磁盘来缓存 RDD。存储级别 MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER分别类似于 MEMORY 和 MEMORY_SER 。对于 MEMORY 和 MEMORY_SER ,如果一个分区在内存里放不下,整个分区都不会放在内存。对于MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER ,如果分区在内存里放不下,Spark 会将其溢写到磁盘上。
什么时候该缓存数据是门艺术,这通常需要对空间和速度进行权衡,垃圾回收开销的问题也会时不时让情况更复杂。一般情况下,如果多个动作需要用到某个 RDD,而它的计算代价又很高,那么就应该把这个 RDD 缓存起来。
2.8 聚合
对集合数据进行聚合时,一定要时刻记住我们分析的数据是存放在多台机器上的,并且聚合需要通过连接机器的网络来移动数据,跨网络移动数据需要许多计算资源,因此为了提高速度,我们需要尽可能地少移动数据。
2.9 创建直方图
RDD[T]类已经定义了一个名为countByValue的动作,它向客户端返回Map[T, Long]类的结果。
如果想要对内容进行排序的话,Sorry,Map类没有提供根据内容的键或值排序的方法。但我们可以将Map转换成Scala的Seq类型,而Seq支持排序。Scala的Seq类和Java的List类借口相似,都是可迭代的集合,即具有确定长度并且可以根据下边来查找值。
val matchCounts = parsed.map(md => md.matched).countByValue()
val matchCountsSeq: Seq[(Boolean, long)] = matchCounts.toSeq
matchCountsSeq.sortBy(_._1).foreach(println)
matchCountsSeq.sortBy(_._2).foreach(println)
## Output:
(false,5728201)
(true,20931)
(true,20931)
(false,5728201)默认情况下,sortBy函数对数值按升序排序,但很多情况下降序排序对直方图数据更有用。通过在序列上调用reverse方法,在打印之前可以改变排序方式。
matchCountsSeq.sortBy(_._2).reverse.foreach(println)2.10 连续变量的概要统计
对于离散类型的字段,非常适合用Spark的countByValue动作创建直方图。但对连续变量,我们想要快速得到其分布的基本统计信息,比如均值、标准差和极值。
stats是RDD[Double]的一个隐式动作,它提供了我们渴望的RDD值概要统计信息。
import java.lang.Double.isNaN
val stats = (0 until 9).map(i => {
parsed.map(md => md.scores(i)).filter(!isNaN(_)).stats()
})2.11 为计算概要信息创建可重用的代码
显然上述的方法很低效,其重复处理了parsedRDD数据9次才得到我想要的结果。即使能通过内存缓存中间结果以节省处理时间,随着数据量越来越大,重复处理所有数据的开销也将越来越高。因此我们要设计一个函数,输入一个RDD[Array[Double]],返回一个数组,其中包含每个指标对应的缺失值个数和一个StatCounter对象(包含每个指标去掉缺失值之后的概率统计信息)。
为此,我们定义如下的类,代码如下,相关注释代表我自己对代码的理解
//我们把类标记为Serialiable,因为我们要在Spark RDD内部使用该类的实例,如果Spark不能持久化其内部数据,我们的作业会失败。
class NAStatCounter extends Serializable {
val stats = new org.apahce.spark.util.StatCounter() //直接写statCounter会报错,虽然我前面导入了包
var missing: Long = 0
//用于将一个新的Double值加到由NAStatCounter跟踪的统计信息上中,返回该this实例。方法merge向当前实例加入了统计信息,它由另一个NAStatCounter实例跟踪。
def add(x: Double): NAStatCounter = {
if (x.isNaN) {
missing += 1
} else {
stats.merge(x)
}
this
}
def merge(other: NAStatCounter): NAStatCounter = {
stats.merge(other.stats)
missing += other.missing
this
}
//覆盖NAStatCounter方法,必须要在方法定义之前加上override关键字。
override def toString: String = {
"stats: " + stats.toString + "NaN: " + missing
}
}
//为类定义列一个伴生对象,该对象为类提供助手方法,类似于Java类的static方法定义。
object NAStatCounter extends Serializable {
def apply(x: Double) = new NAStatCounter().add(x)
}现在用新的NAStatCounter类来处理parsed RDD中MatchData记录的匹配分数。每个MatchData实例包含一个Array[Double]类型的分值数组,对数组的每一项,我们都想有一个NAStatCounter实例来追踪数组下标对应的值有多少个是NaN,同时也去追踪除去缺失值后的常规分布的统计信息。
给定一个值的数组,我们可以用map函数来创建一组NAStatCounter对象:
val arr = Array(1.0, Double.NaN, 17.29)
val nas = arr.map(d => NAStatCounter(d))
## 将这个方法用到集群上的parsedRDD
val nasRDD = parsed.map( md => {
md.scores.map(d => NAStatCounter(d))
})现在就需要把多个Array[NAStatCounter]实例聚合到一个Array[NAStatCounter]上,使用如下代码:
val reduced = nasRdd.reduce((n1, n2) => {
n1.zip(n2).map{case(a, b) => a.merge(b)}
})reduce函数的输入是一个关联函数,该函数把两个T类型的参数映射为一个T类型的返回值,reduce函数一遍又一遍地将关联函数应用到集合上的所有元素,直到只剩下最后一个元素。本例中,nasRdd是RDD[Array[NAStatCounter]]类型,对每两个Array[NAStatCounter]的元素,首先使用zip函数将他们变为元素对(NAStatCounter, NAStatCounter),最后调用merge函数将两个返回一个NAStatCounter实例,最后利用reduce函数计算所有数据。
我们把缺失值分析的代码打包为一个函数:
import org.apache.spark.rdd.RDD
def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
iter.foreach(arr => {
nas.zip(arr).foreach{ case (n, d) => n.add(d) }
})
Iterator(nas)
})
nastats.reduce((n1, n2) => {
n1.zip(n2).map{case (a, b) => a.merge(b)}
})
}这里用了mapPartition函数,该函数只用一个迭代器Iterator[Array[Double]]处理RDD[Array[Double]]的一个分区中的所有记录。这种方式效率更高。
总结
花了两天时间照书抄了一遍,旨在复习一遍Scala与Spark的基本操作,夯实基础。
完整版的代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.util.StatCounter
//定义两个类,这样可以直接用对象.字段的方式访问变量
case class MatchData(id1: Int, id2: Int, scores: Array[Double], matched: Boolean)
case class Scored(md: MatchData, score: Double)
object sparkTest {
def main(args: Array[String]): Unit = {
//Environment Initialization
val conf = new SparkConf().setAppName("SparkCsv").setMaster("local")
val sc = new SparkContext(conf)
//读入数据,textFile可以直接读入csv数据,csv数据就是每一行数据用,隔开的txt文档。
val rawblocks = sc.textFile("linkage/block_1.csv")
//Scala的函数可以随时随地定义与使用
def isHeader(line: String) = line.contains("id_1")
// 过滤掉标题栏(第一行)
val noheader = rawblocks.filter(x => !isHeader(x))
def toDouble(s: String) = {
if ("?".equals(s)) Double.NaN else s.toDouble
}
//把csv表格数据的每一行都处理成MatchData(id1, id2, scores, matched)格式,对于scores要注意数据缺失即为?的情形
//所以这里定义了函数toDouble,把?清洗成NaN
def parse(line: String) = {
val pieces = line.split(",")
val id1 = pieces(0).toInt
val id2 = pieces(1).toInt
val scores = pieces.slice(2, 11).map(toDouble)
val matched = pieces(11).toBoolean
MatchData(id1, id2, scores, matched)
}
val parsed = noheader.map(line => parse(line))
//数据集过大而且访问频繁所以第一次计算就缓存到内存中,下次再次用到的时候就可以直接从内存中读取
//ps:cache和persist区别,RDD缓存机制?参考链接:http://blog.csdn.net/houmou/article/details/52491419
parsed.cache()
//计算matched这一列的不同value对应的count值,相当于是创建直方图
val matchCounts = parsed.map(md => md.matched).countByValue()
val matchCountsSeq = matchCounts.toSeq
matchCountsSeq.sortBy(_._2).reverse.foreach(println) //结果1
//计算scores每一维的stats()概率统计信息(均值、最大/小值,方差与标准差),这里scores一共是9维数据
val stats = (0 until 9).map(i => {
parsed.map(_.scores(i)).filter(!_.isNaN).stats()
})
stats.foreach(println) //结果2
//把数据变成了NAStatCounter,只不过是每一维数据都变成列NAStatCounter
val nasRDD = parsed.map(md => {
md.scores.map(d => NAStatCounter(d))
})
//然后把数据合并压缩,A.zip(B)会形成(A, B)对,reduce是RDD很常用的方法
val reduced = nasRDD.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})
reduced.foreach(println) //结果3
val statsm = statsWithMissing(parsed.filter(_.matched).map(_.scores)) //匹配的数据的概率统计信息
val statsn = statsWithMissing(parsed.filter(!_.matched).map(_.scores))// 不匹配的概率统计信息
//简单的评分函数
statsm.zip(statsn).map { case (m, n) =>
(m.missing + n.missing, m.stats.mean - n.stats.mean)
}.foreach(println) //结果4
//这个是根据上述结果产生的分析代码
def naz(d: Double) = if (Double.NaN.equals(d)) 0.0 else d
val ct = parsed.map(md => {
val score = Array(2, 5, 6, 7, 8).map(i => naz(md.scores(i))).sum
Scored(md, score)
})
ct.filter(s => s.score >= 4.0).
map(s => s.md.matched).countByValue().foreach(println) //结果5
ct.filter(s => s.score >= 2.0).
map(s => s.md.matched).countByValue().foreach(println) //结果6
}
//函数statsWithMissing,实现数据的转换与压缩整合
def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
iter.foreach(arr => {
nas.zip(arr).foreach { case (n, d) => n.add(d) }
})
Iterator(nas)
})
nastats.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})
}
}
/*
类 NAStatCounter
两个成员变量: StatCounter对象stats,包含了每一数据去掉丢失值后的概率统计信息
missing表示丢失数据的个数,可变
类的第一个方法add()用于将一个Double变量添加到该StatCounter中,判断其是不是NaN
方法merge向当前实例加入了统计信息
最后覆盖了toString方法,需要添加关键字override
*/
class NAStatCounter extends Serializable {
val stats: StatCounter = new StatCounter()
var missing: Long = 0
def add(x: Double): NAStatCounter = {
if (x.isNaN) {
missing += 1
} else {
stats.merge(x)
}
this
}
def merge(other: NAStatCounter): NAStatCounter = {
stats.merge(other.stats)
missing += other.missing
this
}
override def toString: String = {
"stats: " + stats.toString + "NaN: " + missing
}
}
//为类定义列一个伴生对象
object NAStatCounter {
def apply(x: Double) = new NAStatCounter().add(x)
}