Machine Learning With Spark--读书笔记
第一章 Spark的环境搭建与运行
Spark的支持四种运行模式
- 本地单机模式Spark Standalone:所有Spark进程都运行在同一个Java虚拟机中。
- 集群单机模式:使用Spark内置的任务调度框架。
- 基于Mesos:Mesos是一个流行的开源集群计算框架。
-基于YARN:即Hadoop2,它是一个与Hadoop关联的集群计算和资源调度框架。
1.1 Spark的本地安装与配置
推荐阅读Spark官方文档: http://spark.apache.org/docs/latest
安装配置单机版Spark之后,可以运行Spark附带的一个示例程序来测试是否一切正常:
>./bin/run-example org.apache.spark.examples.SparkPi
要在本地模式下设置并行的级别,以local[N]的格式来指定一个master变量即可。上述参数中的N表示要使用的线程数目。比如只使用两个线程时,可输入如下命令:
>MASTER=local[2] ./bin/run-example org.apache.spark.examples.SparkPi1.2 Spark集群
本书中将使用Spark的本地单机模式做概念讲解和举例说明,但所用的代码也可运行在Spark集群上。比如在一个Spark单机集群上运行上述示例,只需传入主节点的URL即可:
>MASTER-spark://IP:PORT ./bin/run-example org.apache.spark.examples.SparkPi其中IP和PORT是主节点Master的IP地址和端口号。
1.3 Spark编程模型
1.3.1 SparkContext类与SparkConf类
我的理解是这一步是任何Spark程序的开始,即可以称为Environment Initialization。
1.first edition
val conf = new SparkConf().setAppName("Test Spark App").setMaster("local[4]")
val sc = new SparkContext(conf)
2.second edition
val sc = new SparkContext("local[4]", "Test Spark App")
ps:如果是提交到Spark集群上去运行,那么setMaster("spark://host:port")填写指定Master URL,具体可以去WebUI中查看。1.3.2 Spark Shell
支持利用Scala或Python的交互式shell来进行交互式的程序编写。输入的代码会被立即计算,比较容易理解。spark shell会自动给你初始化好sc as SparkContext。
使用scala for spark shell:
>./bin/spark-shell
使用python for spark shell:
>./bin/pyspark1.3.3 弹性分布式数据集(Resilient Distributed Dataset, RDD)
1.创建RDD
val collection = List("a", "b", "c", "d", "e")
val rddFormCollection = sc.parallelize(collection)
OR
val rddFormTextFile = sc.textFile("File Path")2.Spark操作
Spark Operations = Transformation(Wait) + Action(Run)
转换操作是Lazy的,即只有当运行Action操作时才会执行Transformation操作。
3.RDD缓存策略
persist and cache。详情:http://spark.apache.org/docs/latest/programming-guide.html#rdd-persistence
1.3.4 广播变量和累加器
暂时用不到,就不写这部分了。
1.4 Spark Scala 编程入门
熟能生巧看代码。
输入数据:
John,iPhone Cover,9.99
John,Headphones,5.49
Jack,iPhone Cover,9.99
Jill,Samsung Galaxy Cover,8.95
Bob,iPad Cover,5.49
object Learning_SparkWithScal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("Learn Spark")
.setMaster("local[2]")
val sc = new SparkContext(conf)
val data = sc.textFile("data/UserPurchaseHistory.csv")
.map(line => line.split(","))
.map(purchaseRecord => (purchaseRecord(0), purchaseRecord(1), purchaseRecord(2)))
//求购买次数
val numPurchases = data.count()
//求有多少个不同用户购买过商品
val uniqueUsers = data.map{ case (user, product, price) => user}.distinct().count()
//求和得出总收入
val totalRevenue = data.map{case (user, product, price) => price.toDouble}.sum()
//求出最畅销的产品是什么
val productsByPopularity = data.map{ case (user, product, price) => (product, 1)}
.reduceByKey(_ + _)
.collect()
.sortBy(-_._2)
val mostPopular = productsByPopularity(0)
println("Total purchases: " + numPurchases)
println("Unique users: " + uniqueUsers)
println("Total revenue: " + totalRevenue)
println("Most popular product: %s with %d purchases".format(mostPopular._1, mostPopular._2))
}
}1.5 Spark Java编程入门
很少用,相比Scala来说没有啥优势。
1.6 Spark Python 编程入门
和Scala语法差不多,主要是匿名函数的写法上,但是没有Scala逼格高。:D
1.7 在Amazon EC2 上运行Spark
搭建Spark集群,因为这一部分我自己搭过所以也算是略有心得了。
======================2017.6.10 更新===========================
第二章 设计机器学习系统
这一章大多是文字介绍的功夫,这里就不多扯了。
第三章 Spark上数据的获取、处理与准备
本章内容包括:
- 简要概述机器学习中用到的数据类型
- 举例说明从何处获取感兴趣的数据集(通常可从因特网上获取),其中一些会用于阐述本书中所涉及模型的应用
- 了解数据的处理、清理、探索和可视化方法
- 介绍将原始数据转换为可用于机器学习算法特征的各种技术
- 学习如何使用外部库或Spark内置函数来正则化输入特征
3.1 获取公开数据集
常见的公开数据集:
- UCL机器学习知识库 http://archive.ics.uci.edu/ml/
- Amazon AWS公开数据集 http://aws.amazon.com/publicdatasets/
- Kaggle http://www.kaggle.com/competitions
- KDnuggets http://www.kdnuggets.com/datasets/index.html
本章用到的数据集为MovieLens 100k数据集,下载地址: http://files.grouplens.org/datasets/movielens/ml-100k.zip
下载下来后使用unzip命令解压缩,其中比较重要的文件有u.user(用户属性文件), u.item(电影元数据) 和 u.data(用户对电影的评级)
3.2 探索与可视化数据
本文将使用IPython交互式终端和matplotlib库来对数据进行处理和可视化,故我们会用到Python和PySpark shell。
这里我们使用IPython Notebook,相关安装教程见链接:
http://blog.csdn.net/schwxd/article/details/53863483
我这里安装的是Anaconda2,期间还发生了虚拟机内存不够的状况,大概花了30分钟左右才重新分配了更大的内存。关于Vmware虚拟机内存分配的相关链接:
http://blog.csdn.net/timsley/article/details/50742755
在上述博文里我也遇到了点问题。比如:
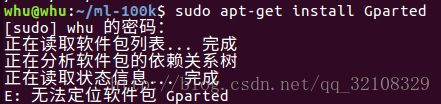
后来发现可以在软件商店中直接下载安装-.-。后序的操作都跟博文中的差不多了,可能就是博文中有些地方描述的过于简单,我一头雾水的操作了半天才弄懂。
言归正传:什么都搞完之后,启动ipthon notebook,然后就打开了如下网页:
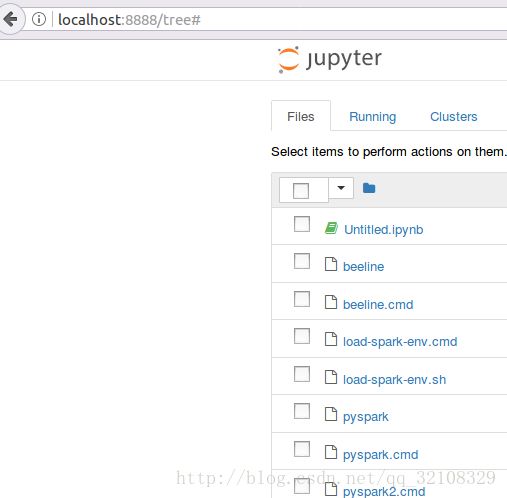
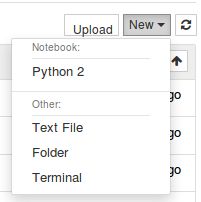
在界面的右边进行如下操作:点击New-> 选择Python2,就会新建一个python2的界面了!(感觉这个类似于一个网页版的python IDE)
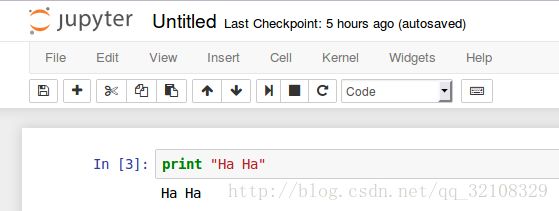
输入一下简单的语句进行测试:
最后说一下简单的快捷键:
暂时看不懂没关系,编程的时候随便用用你就懂了!
好了,又掌握了一个新的看起来还不错的IDE,那么进行愉快的Spark的编程吧- -!
3.2.1 探索用户数据
#读入数据
user_data = sc.textFile("/home/whu/ml-100k/u.user")
user_data.first()
#统计各个维度的总数,count()函数
user_fields = user_data.map(lambda line: line.split("|"))
num_users = user_fields.map(lambda fields: fields[0]).count()
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_users, num_genders, num_occupations, num_zipcodes)
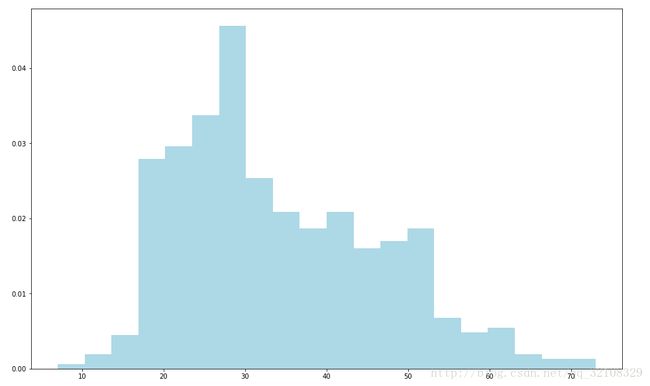
#画用户年龄段分布的直方图
#%pylab inline暂时是什么用不清楚,大概就是类似import numpy , matplotlib类似的功能吧
%pylab inline
ages = user_fields.map(lambda x: int(x[1])).collect()
hist(ages, bins=20, color='lightblue', normed=True)
#hist函数的输入参数有ages数组,直方图的bins数目(即区间数,这里为20)。同时还使用了normed=True参数来正则化直方图,即让每个方条表示年龄在该区间内的数据量占总数据量的比。
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)结果图:至于为什么我这没有竖着的边缘黑线我也不是很清楚。。。
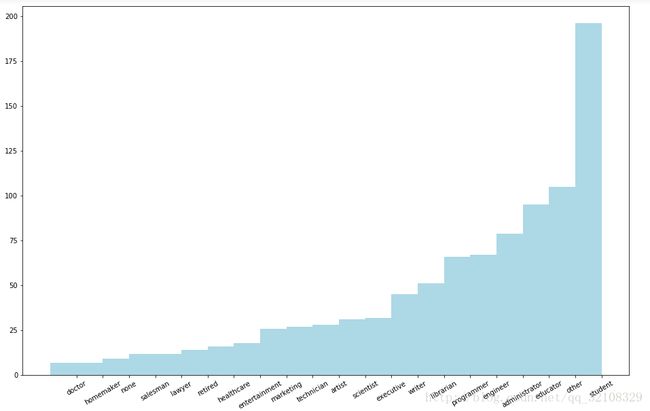
接下来计算用户职业的分布情况:
count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect()
#将RDD转换为两个数组
x_axis1 = np.array([c[0] for c in count_by_occupation]) # 职业标签轴
y_axis1 = np.array([c[1] for c in count_by_occupation]) # 数量轴
#我们需要对该数据进行排序,从而在条形图中以从少到多的顺序来显示各个职业
#为此可先创建两个数组,调用numpy的argsort函数来以数量升序从各数组中选取元素
x_axis = x_axis1[np.argsort(y_axis1)]
y_axis = y_axis1[np.argsort(y_axis1)]
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis, width, color='lightblue')
plt.xticks(rotation=30)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)结果图:
Spark对RDD提供了一个名为countByValue()的便捷函数。它会计算RDD里各不同值所分别出现的次数,并将其以Python dict函数的形式(或是Scala、Java下的Map函数)返回给驱动程序:
count_by_occupation2 = user_fields.map(lambda fields: fields[3]).countByValue()
print "Map-reduce approach: "
print dict(count_by_occupation2)
print ""
print "countByValue approach:"
print dict(count_by_occupation)结果:

3.2.2 探索电影数据
movie_data = sc.textFile("/home/whu/ml-100k/u.item")
print movie_data.first()
num_movie = movie_data.count()
print "Movies: %d" % num_movie
# 有些电影数据不规整,需要如下函数来处理解析错误。
def convert_year(x) :
try:
return int(x[-4:]) # 取最后四个元素
except:
return 1990
movie_fields = movie_data.map(lambda lines: lines.split("|"))
years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x))
#使用Spark的filter操作过滤掉这些1990数据
years_filter = years.filter(lambda x: x != 1990)
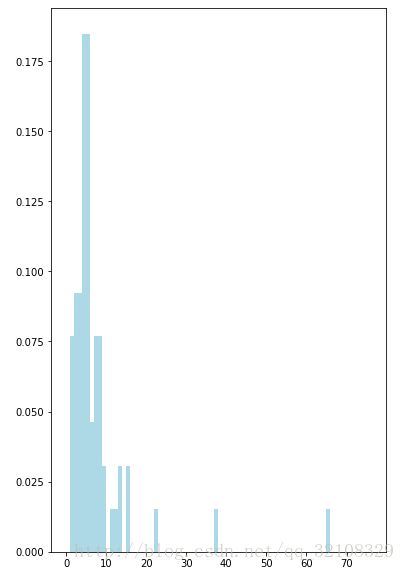
#画电影的年龄分布图(用当前年份1998减去发行年份代表电影的年龄)
movie_ages = years_filter.map(lambda yr: 1998-yr).countByValue()
values = movie_ages.values()
bins = movie_ages.keys()
hist(values, bins=bins, color='lightblue', normed=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(6, 10)结果图:
3.2.3 探索评级数据
rating_data = sc.textFile("/home/whu/ml-100k/u.data")
print rating_data.first()
num_ratings = rating_data.count()
print "Ratings: %d" % num_ratings
rating_data_raw = rating_data.map(lambda line: line.split("\t"))
ratings = rating_data_raw.map(lambda fields: int(fields[2]))
max_rating = ratings.reduce(lambda x,y: max(x, y))
min_rating = ratings.reduce(lambda x,y: min(x, y))
mean_rating = ratings.reduce(lambda x,y: x + y) / double(num_ratings)
median_rating = np.median(ratings.collect())
ratings_per_user = num_ratings / num_users
ratings_per_movie = num_ratings / num_movie
print "Min rating: %d" % min_rating
print "Max rating: %d" % max_rating
print "Average rating: %2.2f" % mean_rating
print "Median rating: %d" % median_rating
print "Average # of ratings per user: %2.2f" % ratings_per_user
print "Average # of ratings per movie: %2.2f" % ratings_per_movie
#Spark对RDD提供一个名为stats()的函数,功能如下:
ratings.stats()
# 结果:(count: 100000, mean: 3.52986, stdev: 1.12566797076, max: 5.0, min: 1.0)】
# 绘制电影评级的分布
count_by_ratings = ratings.countByValue()
x_axis = np.array(count_by_ratings.keys())
y_axis = np.array([float(c) for c in count_by_ratings.values()])
#这里对y轴正则化,使它表示百分比
y_axis_normed = y_axis / y_axis.sum()
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis_normed, width, color='lightblue')
plt.xticks(rotation=30)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
#绘制各个用户的电影评级分布
user_ratings_grouped = rating_data_raw.map(lambda fields: (int(fields[0]), 1)).reduceByKey(lambda x, y: x + y)
#user_ratings_byuser = user_ratings_grouped.map(lambda (k, v): (k, len(v)))
user_ratings_grouped.take(5)
# 结果:[(1, 272), (2, 62), (3, 54), (4, 24), (5, 175)]
user_ratings_byuser_local = user_ratings_byuser.map(lambda (k, v): v).collect()
hist(user_ratings_byuser_local, bins=200, color='lightblue', normed=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)3.3 处理与转换数据
主要是 非规整数据和缺失数据的填充,比如之前用1990年来填充那些没有发行年份的电影。
这段代码不是很懂np函数参数的写法,暂时也懒得去看了-。-
years_pre_processed = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)).collect()
years_pre_processed_array = np.array(years_pre_processed)
mean_year = np.mean(years_pre_processed_array[years_pre_processed_array != 1990])
median_year = np.median(years_pre_processed_array[years_pre_processed_array != 1990])
index_bad_data = np.where(years_pre_processed_array == 1990)[0][0]
years_pre_processed_array[index_bad_data] = median_year
print "Mean year of release: %d" % mean_year
print "Median year of release: %d" % median_year
print "Index of '1990' after assigning median: %s" % np.where(years_pre_processed_array == 1990)[0]
3.4 从数据中提取有用特征
主要针对:
- 数值特性
- 类别特征
- 文本特征
- 其他特征
3.4.1 数值特征
这个就比较简单了,基本上不需要做啥处理。
3.4.2 类别特征
类别特征就是那些各个取值之间没有明确的顺序关系的,比如性别、职业等等。将类别特征表示为数字形式,常用k之1的方法,即Hash思想编号。
all_occupations = user_fields.map(lambda fields: fields[3]).distinct().collect()
all_occupations.sort()
idx = 0
all_occupations_dict = {}
for o in all_occupations:
all_occupations_dict[o] = idx
idx += 1
print "Encoding of 'doctor': %d" % all_occupations_dict['doctor']
print "Encoding of 'programmer': %d" % all_occupations_dict['programmer']
# 结果:Encoding of 'doctor': 2
# Encoding of 'programmer': 14
#再将编号转化为长度为k的二元向量来表示一个变量的取值
K = len(all_occupations_dict)
binary_x = np.zeros(K)
k_programmer = all_occupations_dict['programmer']
binary_x[k_programmer] = 1
print "Binary feature vector: %s" % binary_x
print "Length of binary vector: %d" % K
#输出:
Binary feature vector: [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
Length of binary vector: 213.4.3 派生特征
======================今天就先学到这里,周六晚上给自己放个假吧================