北航软院系统分析大作业
简介
项目主要是做一个科技资源共享平台,其实就是低配版的百度学术,从百度学术中爬取数据,后端采用Flask Restful 框架和MongoDB数据库,前端采用Vue.js,搜索引擎使用的是Elasticsearch。项目主页:斑马科技资源平台
支持对专家,论文和学者的搜索,以及各种限定条件的高级搜索,并且搜索出来的关键词高亮。
效果大概如下:
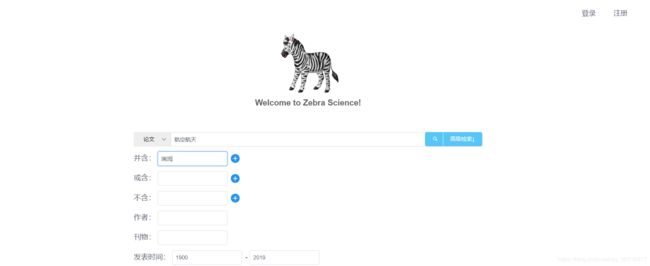
搜索结果:
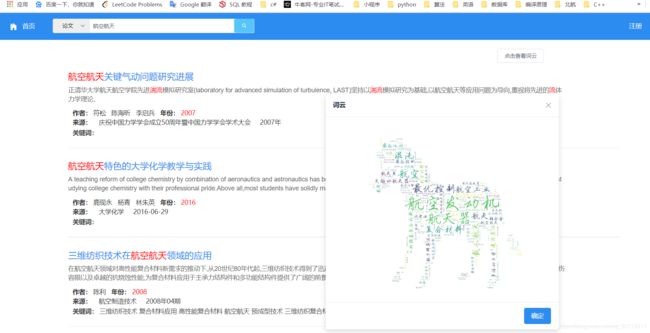
其余的就不一一展示了。
由于在本次开发中,我主要负责后端搜索部分、数据库部分和爬虫的开发,所以只叙述这部分内容,前端请移步:https://blog.csdn.net/tygkking/article/details/92372027
爬取数据
一、学者ID的爬取
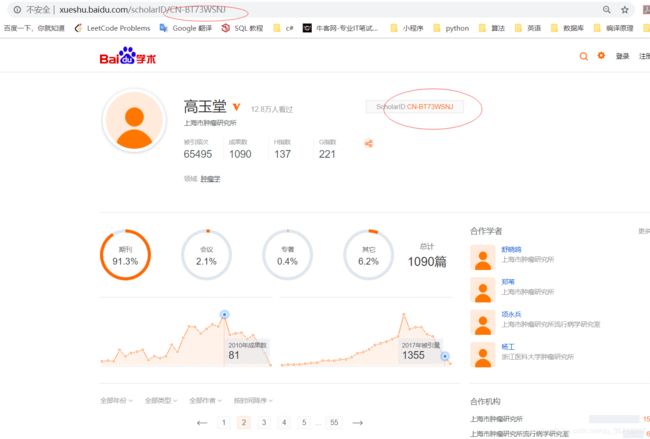
每个学者有一个ScholarID,通过它我们可以构造url来访问主页,
难点一
并没有一个学者列表可以获取到大量scholarid,绞尽脑汁之后终于发现,通过百度直接搜索百度学术学者ScholarID就可以获得大量id了。
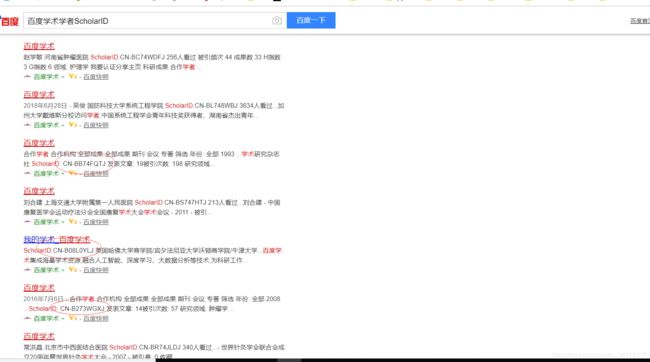
虽然这样搜索出来的并不是全部的学者ID,但是有十几页也够了。之后就可以通过学者关系网来获取学者了。
然后就可以爬ID了。由于百度搜索出来的结果是动态加载的,所以需要使用selenium来模拟浏览器的请求。
代码如下:
import re
import time
from lxml import etree
from selenium import webdriver
class ScholarID:
scholarid_url='https://www.baidu.com/s?wd=%E7%99%BE%E5%BA%A6%E5%AD%A6%E6%9C%AF%E5%AD%A6%E8%80%85ScholarID&pn=50&oq=%E7%99%BE%E5%BA%A6%E5%AD%A6%E6%9C%AF%E5%AD%A6%E8%80%85ScholarID&rn=50&ie=utf-8&rsv_idx=1&rsv_pq=8ef9d1fa000294c9&rsv_t=ba9fl3H02IVc7Zn2G9ovtPU66UfwbWJOaiYeIyL4JzARGb4BnQpq8LKChT0'
browser = webdriver.Chrome()
def parse_list(self,page):
browser=self.browser
new_pn='pn='+str(page*50)
url=re.sub('pn=\d+',new_pn,self.scholarid_url)
print(url)
browser.get(url)
html=etree.HTML(browser.page_source)
scid_url=html.xpath('//h3/a/@href')
# next_page_url=browser.find_elements_by_css_selector('#page a')
# print(next_page_url)
for s_url in scid_url:
browser.get(s_url)
real_url=browser.current_url
with open('scholarid_url.txt','a+',encoding='utf-8') as urlfile:
urlfile.write(real_url)
urlfile.write('\n')
if __name__ == '__main__':
scid=ScholarID()
for index in range(0,16):
scid.parse_list(index)
print('爬取第'+str(index)+'页完成!')然后爬取到的结果:

大概七八百条吧。
二、学者信息的爬取
需要爬取的主要信息如下:
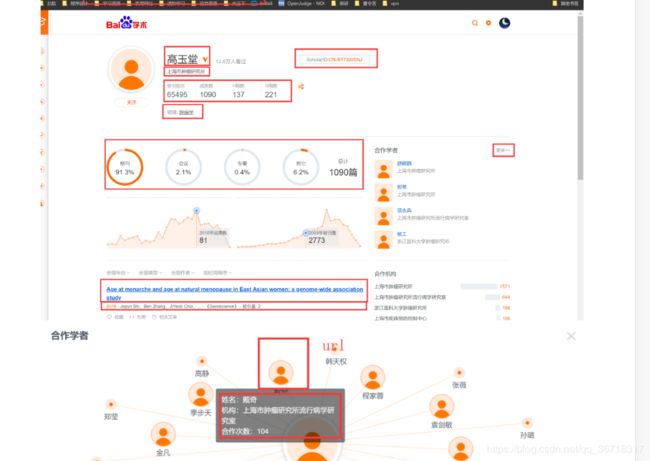
这部分中,除了学者的关系网不能直接爬取外,其它的都可以使用选择器来提取,学者的关系网还是得用selenium,这也是使爬取速度很慢的主要原因。
这里使用scrapy框架,并没有采用深度优先搜索,因为如果按照关系网来爬的话,最后的学者可能都是某个领域的,所以先存到数据库,然后从数据库中依次取出没有被爬过的学者。scrapy的spider部分代码如下:
# -*- coding: utf-8 -*-
import os
import ssl
import requests
import scrapy
from gevent import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from fake_useragent import UserAgent
from Scholarid.Scholarid.Savescid import Savescid
from Scholarid.Scholarid.items import ScholaridItem
class ScholarSpider(scrapy.Spider):
name = 'Scholar'
# allowed_domains = ['http://xueshu.baidu.com/scholarID/CN-B374BHLJ']
# start_urls = ['http://http://xueshu.baidu.com/scholarID/CN-B374BHLJ/']
def start_requests(self):
self.idlist=list() #辨别此ID是否爬取过
self.scid = Savescid('localhost', 27017, 'Scholar', 'scid')
self.scmessage=Savescid('localhost',27017,'Scholar','scmessage')
#从之前得到的scid集合中取id
for id in self.scid.getscid():
if id!=None and self.scmessage.collection.find_one({'scid':id}) ==None:
print(id + ' from scid ')
yield scrapy.Request(url=self.scid.scid2url(id),meta={'scid':id,'scurl':self.scid.scid2url(id)})
#从学者信息集合中取与他合作的学者的id
for id in self.scmessage.getsccopid():
if id!=None and self.scmessage.collection.find_one({'scid':id}) ==None:
print(id+' from scmessage')
yield scrapy.Request(url=self.scmessage.scid2url(id), meta={'scid': id, 'scurl': self.scmessage.scid2url(id)})
'''
网页中的网址转换为实际的网址
'''
def source2real(self,url):
location = os.getcwd() + '\\fake_useragent.json'
ua=UserAgent(path=location)
headers={'User-Agent':ua.random}
ssl._create_default_https_context = ssl._create_unverified_context
request=requests.get(url,headers=headers,timeout=2,verify=False)
return request.url
def parse(self, response):
item=ScholaridItem()
item['scid']=response.meta['scid']
item['scurl']=response.meta['scurl']
item['name']=response.css('.p_name ::text').extract_first()
item['mechanism']=response.css('.p_affiliate ::text').extract_first()
p_ach=response.css('.p_ach_num ::text').extract()
item['citedtimes']=p_ach[0]
item['resultsnumber']=p_ach[1]
item['Hindex']=p_ach[2]
item['Gindex']=p_ach[3]
field=response.css('.person_domain ::text').extract()
item['field']=list(filter(lambda x:x!='/',field))
pie=response.css('.pieText .number ::text').extract()
if len(pie)==4:
item['journal']=pie[0]
item['meeting']=pie[1]
item['professionwork']=pie[2]
item['other']=pie[3]
else:
item['journal']=''
item['meeting']=''
item['professionwork']=''
item['other']=''
item['total']=response.css('.pieMapTotal .number ::text').extract_first()
#爬取关系网
chrome_options=webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser=webdriver.Chrome(chrome_options=chrome_options)
browser.get(response.request.url)
item['copinfo'] = list()
#如果有关系网图,就爬取图的,否则爬取侧栏的合作学者
try :
browser.find_element_by_css_selector('.co_author_wr h3 a').click() #模拟点击更多按钮
time.sleep(0.5)
sreach_window = browser.current_window_handle #重定位网页
co_persons=browser.find_elements_by_css_selector('.co_relmap_person')
for co_person in co_persons:
person=dict()
person['url']=self.source2real(co_person.get_attribute('href'))
co_person=co_person.find_element_by_css_selector('.co_person_name')
person['name']=co_person.text
person['count']=co_person.get_attribute('paper-count') #合作次数
person['mechanism']=co_person.get_attribute('affiliate')
item['copinfo'].append(person)
except NoSuchElementException:
co_persons=response.css('.au_info')
for co_person in co_persons:
person=dict()
person['url']=self.source2real('http://xueshu.baidu.com'+co_person.css('a::attr(href)').extract_first())
person['name']=co_person.css('a ::text').extract_first()
person['mechanism']=co_person.css('.au_label ::text').extract_first()
person['count']=1 #暂定,网页并没有合作次数
item['copinfo'].append(person)
finally:
browser.close()
yield item这里没有一起爬论文的原因是,爬的时候百度学术在维护网站,下面并没有出现论文,发了几封邮件催了之后才维护好了,然后才开始爬论文。学者爬了几天才爬了一万多个,主要是selenium爬合作学者太慢,不过对于我们的项目而言已经够了。
三、论文信息的爬取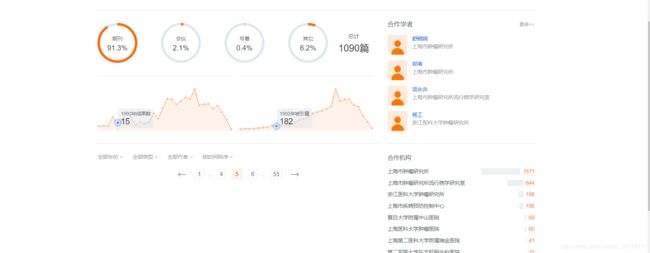
刚刚发现,百度学术学者主页又没有论文了,sad。此处难点又来了
难点二
一般爬取网站时,遇到换页的情况,直接获取下一页url再递归调用解析函数即可,这里点击下一页url并不改变,它是通过ajax请求其它的地址来实现换页的。
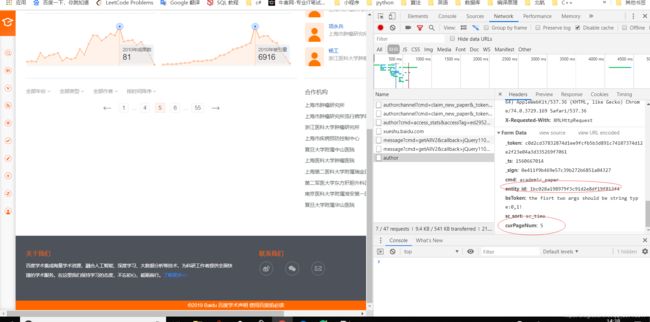
这里的entity_id标识作者,curPageNum标识第几页,所以我们可以通过模拟post请求来获取数据。代码如下:
# -*- coding: utf-8 -*-
import json
import os
import re
import time
from fake_useragent import UserAgent
from lxml import etree
import requests
from Paper.items import PaperItem
import scrapy
import copy
from Scholarid.Scholarid.Savescid import Savescid
class ZebrapaperSpider(scrapy.Spider):
name = 'Zebrapaper'
base_url='http://xueshu.baidu.com'
location = os.getcwd() + '\\fake_useragent.json'
ua = UserAgent(path=location)
headers = {'User-Agent': ua.random}
# allowed_domains = ['http://xueshu.baidu.com/s?wd=%E7%8E%8B%E6%96%8C%20%22%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E5%A4%A7%E5%AD%A6%E6%96%B0%E9%97%BB%E5%AD%A6%E9%99%A2%22%20author%3A%28%E7%8E%8B%E6%96%8C%29']
# start_urls = ['http://http://xueshu.baidu.com/s?wd=%E7%8E%8B%E6%96%8C%20%22%E4%B8%AD%E5%9B%BD%E4%BA%BA%E6%B0%91%E5%A4%A7%E5%AD%A6%E6%96%B0%E9%97%BB%E5%AD%A6%E9%99%A2%22%20author%3A%28%E7%8E%8B%E6%96%8C%29/']
def start_requests(self):
self.scmessage = Savescid('localhost', 27017, 'Scholar', 'scmessage')
self.paper=Savescid('localhost',27017,'Scholar','paper')
for scurl in self.scmessage.getscurl():
scid = self.scmessage.scurl2id(scurl)
if len(self.scmessage.collection.find_one({'scid':scid})['paper'])==0:
yield scrapy.Request(url=scurl,meta={'scid':scid},callback=self.parse_list,headers=self.headers)
def paperid2url(self,paperid):
return 'http://xueshu.baidu.com/usercenter/paper/show?paperid='+paperid
#爬取学者主页下的论文列表
def parse_list(self,response):
is_hasnext=True
#获取专家论文列表最大的页数
try:
max_page=int(response.css('.pagenumber ::text').extract()[-1])
author_url = 'http://xueshu.baidu.com/usercenter/data/author'
for index in range(1, max_page + 1):
form_data = {
'cmd': 'academic_paper',
'entity_id': '',
'bsToken': '07d57f29985111be7bc2ecb0be738da8',
'curPageNum': str(index),
}
# 获取entity_id,其唯一确定一个学者
r = requests.get(response.request.url,headers=self.headers)
r.raise_for_status()
html = etree.HTML(r.text)
html = etree.tostring(html).decode('utf-8')
search_entity_id = re.search('entity_id: \'(.*?)\',', html)
entity_id = ''
if search_entity_id:
entity_id = search_entity_id.group(1)
form_data['entity_id'] = entity_id
# 再次请求,得到以后每页论文列表
r = requests.post(author_url, data=form_data,timeout=1,headers=self.headers)
r.raise_for_status()
html = etree.HTML(r.text)
year_list = html.xpath('//span[@class="res_year"]/text()')
pattern = re.compile(r'data-longsign="(.*?)"')
results = pattern.findall(r.text)
paperid_list = list()
for result in results:
if len(result) > 0:
paperid_list.append(result)
print('该页论文数'+str(len(paperid_list)))
if len(paperid_list) > 0 and len(year_list) > 0:
count=0
for paperid, year in zip(paperid_list, year_list):
count+=1
if count==len(paperid_list) and index==max_page:
is_hasnext=False
print(response.request.url + '的第' + str(index) + '页 ' + self.paperid2url(paperid))
yield scrapy.Request(url=self.paperid2url(paperid), callback=self.parse,headers=self.headers,
meta={'scid': response.meta['scid'], 'paperid': paperid, 'year': year,'is_hasnext':is_hasnext})
except Exception:
paperid_list=response.xpath('//div[@class="reqdata"]/@data-longsign').extract()
print('paperid_list的长度:'+str(len(paperid_list)))
year_list=response.css('.res_year ::text').extract()
if len(paperid_list) > 0 and len(year_list) > 0:
count=0
for paperid, year in zip(paperid_list, year_list):
count+=1
if count==len(paperid_list):
is_hasnext=False
print(response.request.url+ '仅有1页 ' + self.paperid2url(paperid))
yield scrapy.Request(url=self.paperid2url(paperid), callback=self.parse,headers=self.headers,
meta={'scid': response.meta['scid'], 'paperid': paperid, 'year': year,'is_hasnext':is_hasnext})
#爬取论文的主页面
def parse(self, response):
#插入paper表格
paper=dict()
source_journal=dict()
#论文的名字,paperid,年份,全部来源链接,来源期刊,免费下载链接,作者,摘要,关键词
paper['name'] = response.css('.main-info h3 a::text').extract_first()
paper['paperid']=response.meta['paperid']
paper['year']=response.meta['year']
paper['source_url'] = response.css('.allversion_content .dl_item_span a[class="dl_item"]::attr(href)').extract()
source_journal['name']=response.css('.journal_title ::text').extract_first()
source_journal['date']= response.css('.journal_content ::text').extract_first()
paper['source_journal']=source_journal
paper['free_download_url']=response.css('#savelink_wr .dl_item_span a::attr(href)').extract()
paper['author'] = response.css('.author_text a::text').extract()
paper['abstract'] = response.xpath('//p[@class="abstract"]/text()').extract_first()
paper['keyword'] = response.css('.kw_main a::text').extract()
if self.paper.collection.find_one({'paperid':paper['paperid']})==None and paper['name']!=None:
self.paper.collection.insert(paper)
temp_paper_list=self.scmessage.collection.find_one({'scid':response.meta['scid']})['paper']
temp_paperid_list=list()
for item in temp_paper_list:
temp_paperid_list.append(item['paperid'])
if paper['paperid'] not in temp_paperid_list and paper['name']!=None:
temp_paper_list.append(paper)
self.scmessage.collection.update({'scid':response.meta['scid']},{'$set':{'paper':temp_paper_list}})获取每篇论文的链接之后,再爬取它的主页获得如下信息:
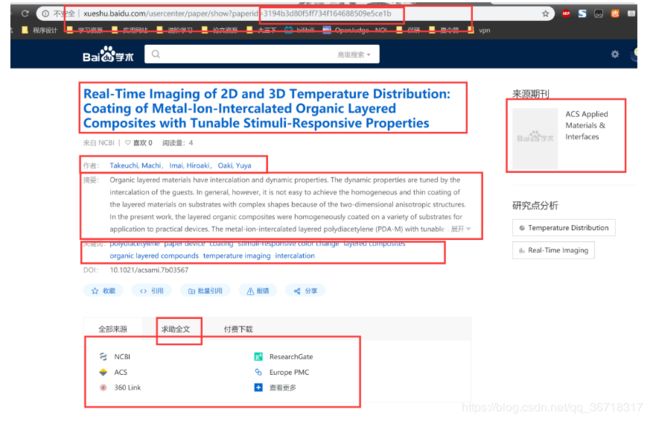
这里就比较简单了。
数据如下:
论文:
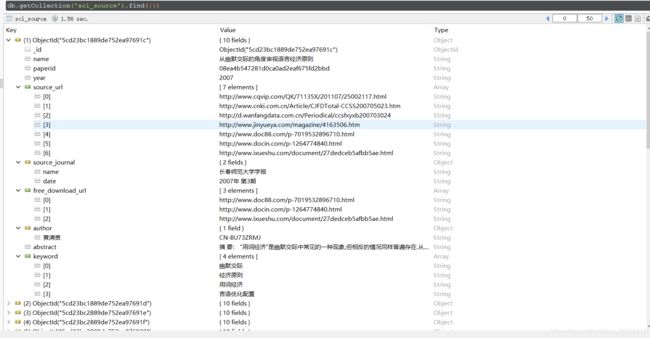
学者:
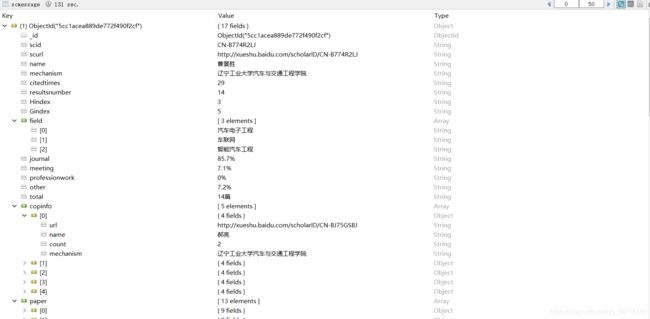
爬取机构
主要是针对学者的机构,在百度百科上爬取机构的相关信息,这个最简单,直接构造url请求即可。
主要代码:
# -*- coding: utf-8 -*-
import os
from urllib.parse import urljoin, quote
import scrapy
from fake_useragent import UserAgent
from Mechanism.items import MechanismItem
from Scholarid.Scholarid.Savescid import Savescid
class BaikeSpider(scrapy.Spider):
name = 'baike'
# allowed_domains = ['https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E8%88%AA%E7%A9%BA%E8%88%AA%E5%A4%A9%E5%A4%A7%E5%AD%A6']
# start_urls = ['http://https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E8%88%AA%E7%A9%BA%E8%88%AA%E5%A4%A9%E5%A4%A7%E5%AD%A6/']
location=os.getcwd()+'\\fake_useragent.json'
ua=UserAgent(path=location)
headers={'User-Agent':ua}
def mechanism2url(self,mechanism):
return urljoin('https://baike.baidu.com/item/',quote(mechanism))
def start_requests(self):
self.scmessage=Savescid('localhost',27017,'Scholar','scmessage')
self.mechanism=Savescid('localhost',27017,'Scholar','mechanism')
count=0
for mechanism in self.scmessage.getscmechanism():
if self.mechanism.collection.find_one({'mechanism':mechanism})==None :
count+=1
print('开始爬取第'+str(count)+'个机构:'+mechanism)
mechanismurl=self.mechanism2url(mechanism)
yield scrapy.Request(url=mechanismurl,callback=self.parse,meta={'mechanism':mechanism,'url':mechanismurl})
def textlist2str(self,textlist):
temp = ''.join(i for i in textlist if '\n' not in i and '[' not in i)
temp = ''.join(temp.split())
return temp
def parse(self, response):
item=MechanismItem()
item['mechanism']=response.meta['mechanism']
item['url']=response.meta['url']
#简介,每一个元素是一个段落
item['introduction']=list()
paras=response.css('.lemma-summary .para')
for para in paras:
item['introduction'].append(self.textlist2str(para.css('::text').extract()))
yield item至此,爬虫工作基本完成。所有的爬虫代码详见:https://github.com/xzd1621/ZebraScienceReptile
数据库接口方法
主要是针对业务需要,写的一些接口方法,如登陆注册,收藏/取消收藏,喜欢/取消喜欢,搜索论文/学者/机构等。三四个人写了大概一千多行的代码,这部分比较简单,代码地址为:https://github.com/Alola-Kirby/ZebraScienceWaterPool
搜索
之前由于并没有想到搜索会这么复杂,虽然给MongoDB数据库建立了索引,搜索速度也差强人意,大概几秒左右,但是它对于一些不连续出现的关键词,多个关键词的情况却没办法处理,最后还是使用了专业的ElasticSearch。
原理
主要原理可以参见:https://blog.csdn.net/andy_wcl/article/details/81631609
它使用的是倒排索引,在我们普通的搜索中都是遍历然后查找有没有这个关键词,倒排索引向查字典一样,首先建立关键词——文档的映射,首先分词,然后将所有关键词出现的文档记录下来,当我们搜索关键词时,就可以很快得到包含关键词的文档。此外它可以按照相关度来排序,支持各种逻辑关系的搜索。
在我们采用elasticsearch之前,需要把数据导入elasticsearch,这里又是难点,废了很久。
难点三
将存到mongodb的数据插入到elasticsearch时,mongodb连接总是断开。之前插入时,逐条遍历mongodb数据库,但是elasticsearch的插入却是批量的,使用mongodb的find方法时会出现连接超时情况。后来一次find限定量的数据,后一次查找时跳过之前的数据,这样就可以解决一次find过多而超时的问题。
代码如下
from elasticsearch import Elasticsearch
from elasticsearch import helpers
from pymongo import MongoClient
ONCE = 1000 # 调用mongo2es中find的数据条数
SKIPNUM = 0 # 第几次调用mongo2es函数
ERROR_ELE = [] # 未插入es的数据序号列表
INSERT_NUM = 100 # 一次批量插入的条数
START = 0 # 开始下标
class zebrasearch():
"""
连接Elaticsearch
"""
def connect_es(self, host, port):
self.es = Elasticsearch([{u'host': host, u'port': port}], timeout=3600)
"""
连接到mongodb
"""
def connect_mongo(self, host, port):
self.client = MongoClient(host, port)
"""
将mongodb中的db数据库的collection插入
elaticsearch的index索引的types中
"""
def mongo2es(self, db, collection, index, types):
db = self.client[db]
collection = db[collection]
count = 0
actions = []
tmp = collection.find().skip(SKIPNUM * ONCE).limit(ONCE)
for item in tmp:
item = dict(item)
item.pop('_id')
# for p in item['paper']:
# if '_id' in p.keys():
# p.pop('_id')
action = {
"_index": index,
"_type": types,
"_source": item
}
actions.append(action)
count += 1
print('第' + str(SKIPNUM * ONCE + count) + '篇论文已加入列表')
try:
if len(actions) == INSERT_NUM:
print("截止到" + str(SKIPNUM * ONCE + count) + "篇论文正在准备插入")
helpers.bulk(client=self.es, actions=actions)
actions.clear()
except:
actions.clear()
ERROR_ELE.append(SKIPNUM * ONCE + count)
if count > 0:
helpers.bulk(self.es, actions)
"""
将es的index索引的types清空
"""
def cleartypes(self, index, types):
query = {'query': {'match_all': {}}}
self.es.delete_by_query(index=index, body=query, doc_type=types)
if __name__ == '__main__':
zebrasearch = zebrasearch()
zebrasearch.connect_es(u'139.199.96.196', 9200)
zebrasearch.connect_mongo('139.199.96.196', 27017)
# zebrasearch.mongo2es('Business', 'mechanism', 'business', 'user')
# print(zebrasearch.es.search(index='business', doc_type='scisource'))
# zebrasearch.cleartypes('busscisource', 'scisource')
# 专家每次插10条,每次挑100条
# 论文每次插100条,每次挑1000条
START = 300
SKIPNUM = START
END = START + 376
for i in range(START, END):
print("第" + str(i) + "轮")
zebrasearch.mongo2es('Business', 'paper', 'paper_index', '_doc')
SKIPNUM += 1
print(ERROR_ELE)
插入完成之后就可以开始搜索了,主要是一些嵌套的查询语句,比较容易出错。
搜索论文:
def search_paper_nb(self, title, page_num, keyw_and, keyw_or, keyw_not, author, journal, start_time, end_time ):
res = {'state': 'fail', 'reason': '网络出错或BUG出现!', 'count': 0,
'total_count': 0, 'msg': []}
try:
# 根据条件进行高级查询
must_match = ''
for key in keyw_and:
must_match += key+' '
must_not_match = ''
for key in keyw_not:
must_not_match += key+' '
should_match = ''
for key in keyw_or:
should_match += key+' '
try:
start_time = int(start_time)
except:
start_time = 0
try:
end_time = int(end_time)
except:
end_time = 2020
filter_query = {
"range": {
"year": {
"gte": start_time,
"lte": end_time
}
}
}
must_query = [
{
"match": {
"name": title
}
},
]
if author != '':
must_query.append(
{"match": {"author": author}}
)
if journal != '':
must_query.append(
{"match": {"source_journal.name": journal}}
)
must_not_query = {
"multi_match":{
"query": must_not_match,
"fields": [
"abstract",
"name",
"author",
"keyword"
],
"operator": "and"
}
}
should_query = [
{
"multi_match":{
"query": should_match,
"fields": [
"abstract",
"name",
"author",
"keyword"
]
}
},
{
"match": {
"name":{
"query": must_match,
"operator": "and"
}
}
},
{
"match": {
"author": {
"query": must_match,
"operator": "and"
}
}
},
{
"match": {
"abstract":{
"query": must_match,
"operator": "and"
}
}
},
{
"match": {
"keyword": {
"query": must_match,
"operator": "and"
}
}
}
]
body = {
"query": {
"bool":{
"filter": filter_query,
"must": must_query,
"must_not": must_not_query,
"should": should_query
}
},
"highlight": {
"pre_tags" : [''],
"post_tags": [''],
"fields": {
"abstract": {
"fragment_size": 150,
"number_of_fragments": 0
},
"name":{
"fragment_size": 150,
"number_of_fragments": 0
},
"keyword":{
"fragment_size": 150,
"number_of_fragments": 0
},
"author":{
"fragment_size": 150,
"number_of_fragments": 0
},
"source_journal.name":{
"fragment_size": 150,
"number_of_fragments": 0
},
"year":{}
}
},
'size': 10,
}
total_count = 0
if page_num == '':
page_num = 1
temp_body = {
"query": {
"bool": {
"filter": filter_query,
"must": must_query,
"must_not": must_not_query,
"should": should_query
}
}
}
temp_body = json.dumps(temp_body, ensure_ascii=False)
temp_res = self.es.count(index='paper_index', body=temp_body)
total_count = temp_res['count']
print(total_count)
temp_body = {
"_source": {
"include": [
"keyword"
]
},
"size": total_count,
"query": {
"bool": {
"filter": filter_query,
"must": must_query,
"must_not": must_not_query,
"should": should_query
}
}
}
path = "keyword_" + str(round(time.time()))
temp_body = json.dumps(temp_body, ensure_ascii=False)
res['word_cloud_path'] = Config.DOMAIN_NAME + "/static/wordCloud/" + path + '.jpg'
t = threading.Thread(target=self.get_word_cloud2, args=(temp_body, path,))
t.start()
page_num = int(page_num)
body['from'] = (page_num - 1) * 10
body = json.dumps(body, ensure_ascii=False)
temp_papers = self.es.search(index='paper_index', body=body)
count = len(temp_papers['hits']['hits'])
papers = []
for temp in temp_papers['hits']['hits']:
source = temp['_source']
highlight = temp['highlight']
if 'source_journal.name' in highlight.keys():
source['source_journal']['name'] = highlight['source_journal.name'][0]
if 'year' in highlight.keys():
source['year'] = highlight['year'][0]
if 'author' in highlight.keys():
for i in range(len(source['author'])):
for h_author in highlight['author']:
if len(source['author'][i]) == self.LCS(source['author'][i], h_author):
source['author'][i] = h_author
if 'name' in highlight.keys():
source['name'] = highlight['name'][0]
if 'abstract' in highlight.keys():
abstract = ''
for item in highlight['abstract']:
abstract += item
source['abstract'] = abstract
if 'keyword' in highlight.keys():
for i in range(len(source['keyword'])):
for kw in highlight['keyword']:
if len(source['keyword'][i]) == self.LCS(source['keyword'][i],kw):
source['keyword'][i] = kw
papers.append(source)
res['total_count'] = total_count
if count > 0:
res['count'] = count
res['msg'] = papers
res['state'] = 'success'
res['reason'] = '成功查询'
else:
res['reason'] = '未找到相关论文'
return res
except:
return res我负责的部分大致就是这样了。