语义分割【论文解读】新思路:几何感知蒸馏 CVPR-2019
文章转自:知乎 原文链接:https://zhuanlan.zhihu.com/p/146165099
作者:python小宗师
简介
语义分割是计算机视觉中一个基本而又具有挑战性的问题。通过语义分割获得更好的场景,有利于许多应用程序,如机器人,视觉SLAM和虚拟/增强现实。与基于RGB图像的方法相比,基于深度(RGB-D)的RGB方法可以利用来自场景的额外的三维几何信息,有效地解决单一2D显示方法所面临的挑战,然而,大多数已有的方法都需要精确的深度图作为场景分割的输入,这严重限制了它们的应用。现有的数据库RGB-D数据集 i.e NYU-v2, SUN-RGBD 的深度图/视差图不够精确,准确来说有很大缺陷,例如中心目标标签像素的缺失[0,0,0],导致最终预测的结果失败;
在本文中,提出在挖掘有用的深度域信息的同时,通过提取几何感知嵌入来联合推断语义和深度信息,以消除这种强约束。此外,通过提出的几何感知传播框架和多个跳跃特征融合块,利用所学的嵌入知识来提高语义分割的质量。通过将单任务预测网络解耦为语义分割和几何嵌入学习两个联合任务,并结合提出的信息传播和特征融合架构,在公开数据及上取得了 state-of-the-art结果。
工作描述:
在这项工作中,我们提出通过学习密集的深度嵌入的联合推理框架来提取/提取几何感知的信息,用于单个RGB图像的语义分割。该模型没有直接采用深度信息作为输入,而是将深度图嵌入,与RGB输入一起提取,从而指导语义分割。在该框架中,通过提出的几何感知传播块将学习到的嵌入信息与二维外观特征融合,利用几何亲和性来指导语义传播。此外,发现分割结果往往缺乏细节,特别是近物体边界。在特征空间中提出了一种增量的跨尺度融合方案,从而进一步丰富了结构细节。一些对象可能有非常相似的2D外观,不能很好地识别。该模型能够很好地将三维几何信息嵌入到所学特征中,使预测具有语义一致性和几何一致性。
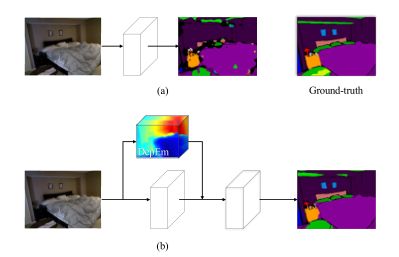
如图所示,仅根据二维特征很难对枕头进行分割,而通过学习嵌入,由于枕头的三维几何信息与周围环境不同,可以很好地进行分类。床的形状也受益于学习的嵌入,它揭示了提炼的几何信息的有效性。我们的方法的关键思想是预测语义标签从单一的RGB图像,同时考虑三维几何信息隐含。
本文的主要贡献归纳为:
1)提出了一种新的方法,通过隐式深度推断提取几何感知嵌入,有效地指导RGB输入场景分割。
2)该联合框架实现了深度标签和语义标签之间的信息融合,并具有端到端可训练性。
3)模型在NYU-Dv2和SUN RGBD的室内语义分割数据集方面达到了最先进的性能。
3. 几何感知蒸馏
提出了几何感知精馏的框架,以隐式地提高分割性能。整个网络通过一个联合目标函数进行端到端的训练。
3.1 学习深度感知嵌入
这项工作的目标是利用几何(深度)信息进行语义分割,而不需要额外的深度图作为输入。一种直观的方法是首先从输入的RGB图像中预测深度图,然后将深度信息并入传统的RGB- d分割管道。本文建议从RGB图像中学习一种深度感知嵌入方法,并同时进行语义分割,而不是采用这种顺序的解决方案。将深度感知嵌入定义为在语义层次上对深度信息和像素亲和力进行编码的表示。
给定一个RGB图像像素I,深度感知嵌入是从一个可学习的投影函数g(I),它将RGB像素转换到一个高维空间,嵌入相应的特征。然后将嵌入学习建模为一个优化问题:
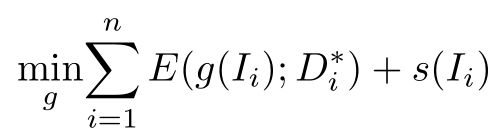
其中E(x,x)为数据拟合项,D为提供需要通过投影嵌入的深度信息的GT。第二项s(x) = E(g (x),x)是语义项,目的是嵌入语义信息,n是像素的总数。
为了得到一个好的投影g,用一个深度神经网络模型来参数化它,通过反向传播来优化嵌入。因此,g被定义为f,其中f是一个深度CNN。然后将优化重新表述为:
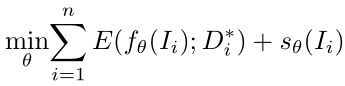
3.2 几何感知的导引传播---GAP
在学习了嵌入后,将其应用于语义分割的即时验证。提出一种几何感知传播(GAP)方法来利用已学习的嵌入作为指导。通过这种方式,深度嵌入作为一种亲和引导,提供几何信息,以便更好地组合这些特征。给定嵌入空间中的一个点i与其相邻点j,对于用于预测语义标签的分数图中位置j对应的特征点pj,其在位置i的传播输出q i可表示为:
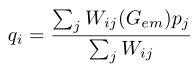
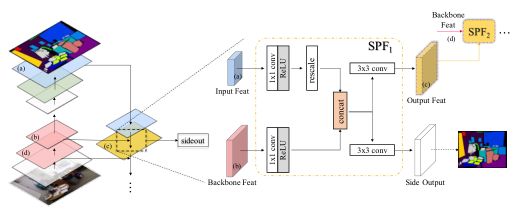
其中Gem = f(I)为学习的深度嵌入,W ij为几何指导G em导出的传播权值。由于W ij表示嵌入空间的几何亲和力,这里我们将其定义为解耦嵌入的点积为:
![]()
两个参数将原始嵌入解耦为两个子嵌入。为了应对传播过程中维数的变化,进一步利用映射算法将语义特征一致地投影到嵌入空间中。特别是传播权由几个卷积单元设计,这些单元可以通过反向传播自动学习。特别地,将原始语义特征加入到传播结果中,避免了整个传播过程的中断。将所提出的间隙块定义为:
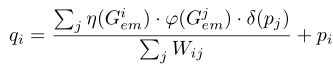
3.3 模型结构
通过引导传播和金字塔特征融合提取几何感知信息,进行精确分割。如下图所示,该网络由共享骨干网络、语义分割分支、深度嵌入分支、感知几何传播块、跳过金字塔融合块五部分组成。所提出的网络在全球范围内遵循一种编解码器结构,具有多任务预测。该编码器的网络权值由两种任务共享。在解码器部分,上分支通过预测深度图来预测语义标签,下分支通过预测深度图来学习深度嵌入。
将深度分支(通过总和)传播到各个分支以提供多尺度深度引导。在解码器中,还传播不同的尺度特征,以丰富最后一层的输出。解码器的每一层都是上采样,然后是卷积。在语义分支的末端应用几何感知传播块(GAP),以学习到的嵌入作为指导,提高语义特征的质量。通过skip pyramid fusion block (SPF),结合来自骨干网的多级特征图,进一步细化蒸馏后的输出。最后使用来自底部SPF块的得分图进行语义标签的预测。对最右边的特征和每一级SPF侧输出进行语义监控。相应的深度映射作为学习嵌入的超视觉。整个网络由一个联合目标函数端到端进行训练(具体见目标函数部分)。
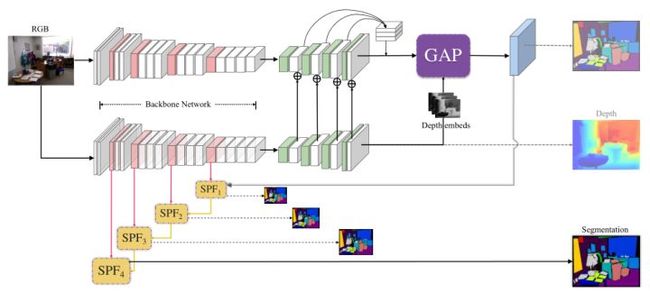
Geometry-Aware传播
几何感知传播是通过几个卷积层、批处理归一化和元素处理来实现的。详细结构如图下所示。深度嵌入首先被发送到两个conv单元,以实现几何亲和力。然后以几何亲和力为导向,与语义特征进行融合。最后,将原始语义特征与融合的信息结合在一起输出,如图3中的蓝色块所示。整个传播主体获得语义特征的维度。在不知道深层组合策略的情况下,将深度特征和颜色特征融合在一起,深度信息指导特征融合。
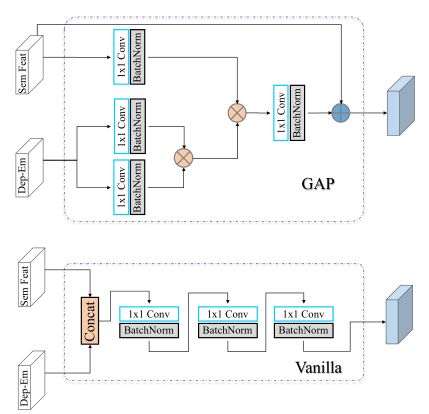
Skip Pyramid Fusion
跳连金字塔融合。当图像通过编码器和解码器时,可能会丢失很多细节信息,试最终的语义特征图中丰富和恢复更多的细节,如下所示。灵感来自特征金字塔网络的目标检测,利用多层次的特征从编码器骨干通过跳跃连接。由于编码器和解码器之间的特征空间是最稀疏的、细节最少的,解码器最终恢复的特征图几乎不包含有用的细节。因此,向编码器部分寻求更多的信息。skip - pyramid fusion (SPF) block的结构如图下所示。第一个SPF(spf1)将提取出来的特征作为输入,经过1×1卷积,适当调整大小后与来自编码器骨干的特征图进行拼接。经过3×3卷积后,组合的特征被传播到另一个SPF。同时,每个SPF预测一个侧输出用于语义分割。
3.4损失函数
为了缓解数据不平衡问题,把用于对象检测的丢失函数扩展到义分割任务中,如下所示:
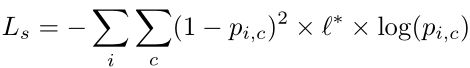
除了语义监督外,深度感知嵌入的学习还需要深度领域的监督。根据最先进的算法进行深度估计,我们使用berHu损失作为我们的深度监督定义为:
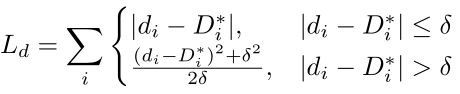
最后结合中间层语义预测(k层聚合)的损失Lsk (spf k处的Ls),最终的联合损失函数为:
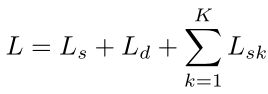
4 结果对比
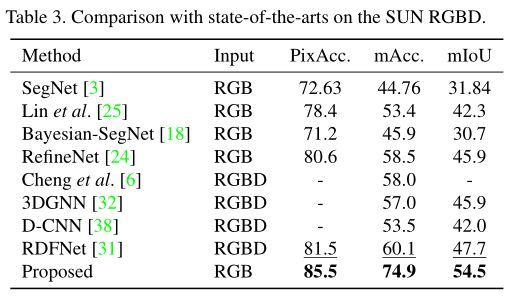
在NYU-Dv2数据集上的结果比较如下:
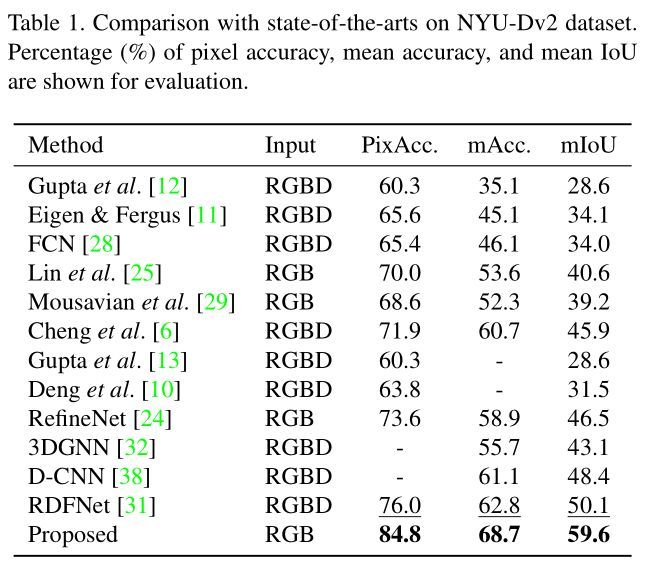
在NYU-Dv2数据集上的结果比较如下:
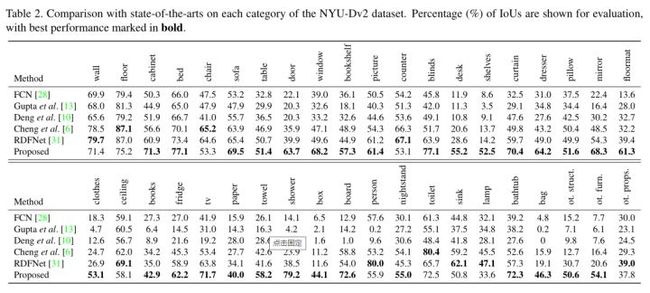
各个类别分类准确性比较如下:
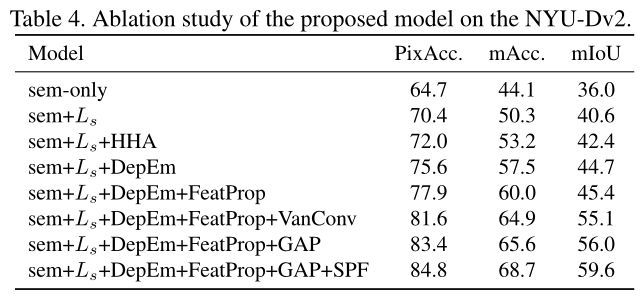
Ablation Study的结果
5 分割结果图

6 结论
充分利用三维几何信息的深度感知嵌入隐式提取的单一RGB图像语义分割。通过解耦共享骨干网络,共同推导了几何精馏和动态标签预测。通过几何感知的传播结构,将学习到的嵌入作为改进语义特征的指导。通过跳过金字塔融合块,将提取出来的特征进一步反馈到共享主干中,与多层次的上下文信息融合。模型仅以一个RGB图像作为输入,就可以同时获取二维外观和三维几何信息。在室内RGB-D语义分割的实验结果表明,模型取得了较先进的方法更好的性能。