【Ambari2.7.3源码分析】Agent组件状态收集器ComponentStatusExecutor
1、InitializerModule.py中
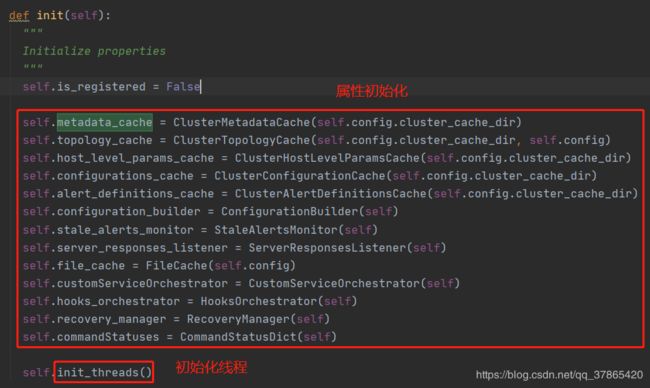
在InitializerModule.py中,初始化了众多属性后,进行线程的初始化
这些线程在agent端非常重要
def init_threads(self):
"""
Initialize thread objects
"""
self.component_status_executor = ComponentStatusExecutor(self)
self.action_queue = ActionQueue(self)
self.alert_scheduler_handler = AlertSchedulerHandler(self)
self.command_status_reporter = CommandStatusReporter(self)
self.host_status_reporter = HostStatusReporter(self)
self.alert_status_reporter = AlertStatusReporter(self)
self.heartbeat_thread = HeartbeatThread.HeartbeatThread(self)
其中ComponentStatusExecutor(self)就是ambari-agent对组件状态执行器进行初始化
本文也主要讲此线程
2、ComponentStatusExecutor.py中
在ComponentStatusExecutor.py中
核心方法为下面的run()方法
def run(self):
"""
Run an endless loop which executes all status commands every 'status_commands_run_interval' seconds.
"""
if self.status_commands_run_interval == 0:
self.logger.warn("ComponentStatusExecutor is turned off. Some functionality might not work correctly.")
return
while not self.stop_event.is_set():
try:
# 为了删除已删除的信息需要这样子做
self.clean_not_existing_clusters_info()
cluster_reports = defaultdict(lambda:[])
with self.reports_to_discard_lock:
self.reports_to_discard = []
for cluster_id in self.topology_cache.get_cluster_ids():
# TODO: check if we can make clusters immutable too
try:
topology_cache = self.topology_cache[cluster_id]
metadata_cache = self.metadata_cache[cluster_id]
except KeyError:
# multithreading: if cluster was deleted during iteration
continue
if 'status_commands_to_run' not in metadata_cache:
continue
status_commands_to_run = metadata_cache.status_commands_to_run
if 'components' not in topology_cache:
continue
current_host_id = self.topology_cache.get_current_host_id(cluster_id)
if current_host_id is None:
continue
cluster_components = topology_cache.components
for component_dict in cluster_components:
# 这里command_name只有status
for command_name in status_commands_to_run:
if self.stop_event.is_set():
break
# cluster was already removed
if cluster_id not in self.topology_cache.get_cluster_ids():
break
# check if component is installed on current host
if current_host_id not in component_dict.hostIds:
break
service_name = component_dict.serviceName
component_name = component_dict.componentName
# do not run status commands for the component which is starting/stopping or doing other action
if self.customServiceOrchestrator.commandsRunningForComponent(cluster_id, component_name):
self.logger.info("Skipping status command for {0}. Since command for it is running".format(component_name))
continue
# cluster_id=topology_cache.get_cluster_ids()
# component_dict in cluster_components
# service_name=component_dict.serviceName
# component_name = component_dict.componentName
# metadata_cache = self.metadata_cache[cluster_id]
# status_commands_to_run = metadata_cache.status_commands_to_run
# command_name in status_commands_to_run
result = self.check_component_status(cluster_id, service_name, component_name, command_name)
if result:
cluster_reports[cluster_id].append(result)
cluster_reports = self.discard_stale_reports(cluster_reports)
self.send_updates_to_server(cluster_reports)
except ConnectionIsAlreadyClosed: # server and agent disconnected during sending data. Not an issue
pass
except:
self.logger.exception("Exception in ComponentStatusExecutor. Re-running it")
# 每status_commands_run_interval秒内执行所有状态命令(默认20s)
self.stop_event.wait(self.status_commands_run_interval)
self.logger.info("ComponentStatusExecutor has successfully finished")
3、对run()归纳如下
run()方法中
运行一个无限循环,在每status_commands_run_interval秒内执行所有状态命令(默认20s)
self.stop_event.wait(self.status_commands_run_interval)
3.1、循环所有cluster_id
for cluster_id in self.topology_cache.get_cluster_ids():
topology_cache为InitializerModule.init()中初始化的属性
self.topology_cache = ClusterTopologyCache(self.config.cluster_cache_dir, self.config)
3.2、获取topology_cache、metadata_cache
topology_cach与metadata_cache实际上都是从
/var/lib/ambari-agent/cache/cluster_cache
目录中进行查询的

topology_cache = self.topology_cache[cluster_id]
metadata_cache = self.metadata_cache[cluster_id]
如果cluster_id不存在,则continue
修改下面的文件
vim /etc/ambari-agent/conf/ambari-agent.ini
loglevel=DEBUG
DEBUG后,日志中topology_cache、metadata_cache我各截取了部分
topology_cache:

metadata_cache:
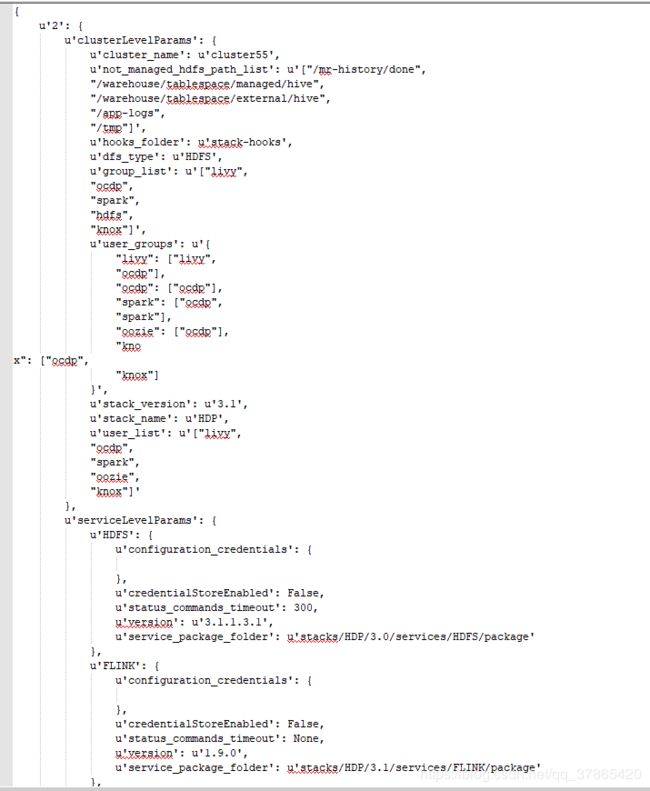
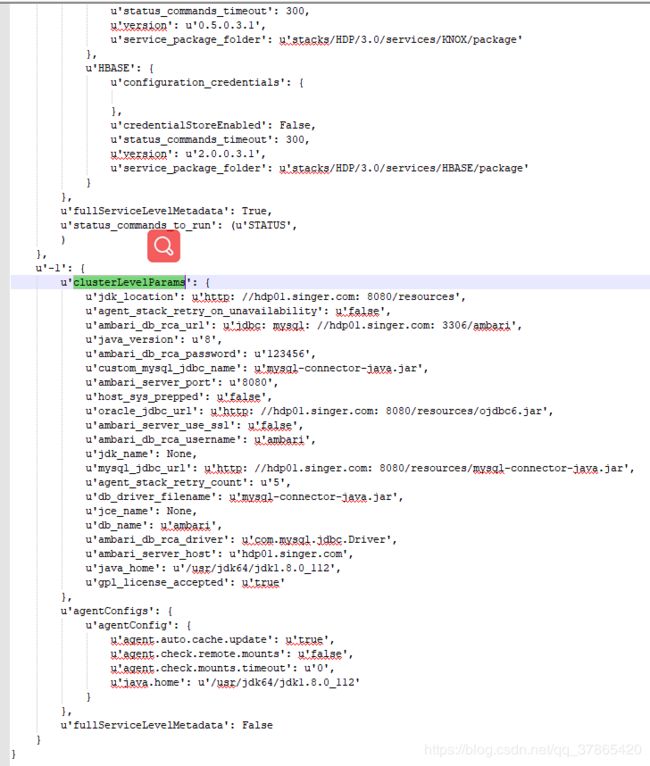
3.3、获取status_commands_to_run、current_host_id
if 'status_commands_to_run' not in metadata_cache:
continue
status_commands_to_run = metadata_cache.status_commands_to_run
如果metadata_cache中不存在status_commands_to_run,则continue
if 'components' not in topology_cache:
continue
current_host_id = self.topology_cache.get_current_host_id(cluster_id)
if current_host_id is None:
continue
topology_cache中没有components则continue
current_host_id 从topology_cache取不到的话也continue
3.4、获取cluster_components并循环所有component
cluster_components = topology_cache.components
for component_dict in cluster_components:
# 这里command_name只有status
for command_name in status_commands_to_run:
if self.stop_event.is_set():
break
# cluster was already removed
if cluster_id not in self.topology_cache.get_cluster_ids():
break
# check if component is installed on current host
if current_host_id not in component_dict.hostIds:
break
在每一个集群cluster_id的循环里
- 要对获取到的所有component进行循环
-
并对该component进行所有要执行的status_command指令循环(# 这里command_name只有status)
(这里注意下,此循环逻辑说白了就是收集所有组件信息,并非执行server端传来的命令,server端的命令是由另外一个线程CommandStatusReporter执行的) -
如果有stop_event事件,则break跳出,等待下一个20s执行下一轮while循环
-
在这时检查cluster_id是否还在topology_cache.get_cluster_ids()中,current_host_id主机id是否还在component_dict.hostIds中
(因为循环很多次,需要在每次执行前进行cluster、host存在的确认) -
在当前要执行的status_command命令执行前获取component_dict组件名称以及对应的服务名称(例如NAMENODE,HDFS;HMASTER,HBASE等)
service_name = component_dict.serviceName component_name = component_dict.componentName -
不为正在启动/停止或正在执行其他操作的组件运行status commands(过滤掉这些处于操作状态的组件)
if self.customServiceOrchestrator.commandsRunningForComponent(cluster_id, component_name): self.logger.info("Skipping status command for {0}. Since command for it is running".format(component_name)) continue -
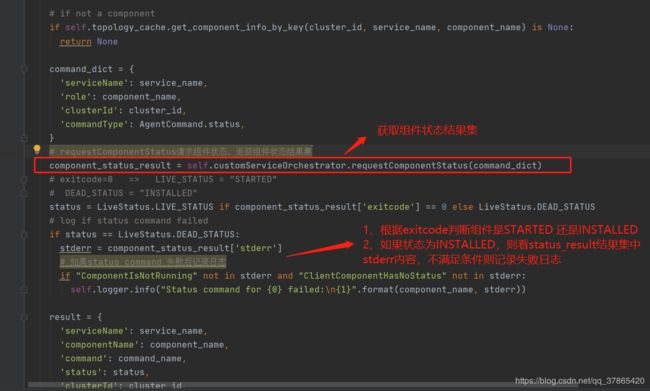
对当前组件执行status检查命令,并返回结果集(check_component_status逻辑为:如果组件状态已更改,则返回组件状态,否则为None)
result = self.check_component_status(cluster_id, service_name, component_name, command_name)check_component_status()方法的解析请看第4小节
-
4、check_component_status()
def check_component_status(self, cluster_id, service_name, component_name, command_name, report=False):
"""
Returns components status if it has changed, otherwise None.
"""
# if not a component
if self.topology_cache.get_component_info_by_key(cluster_id, service_name, component_name) is None:
return None
command_dict = {
'serviceName': service_name,
'role': component_name,
'clusterId': cluster_id,
'commandType': AgentCommand.status,
}
component_status_result = self.customServiceOrchestrator.requestComponentStatus(command_dict)
status = LiveStatus.LIVE_STATUS if component_status_result['exitcode'] == 0 else LiveStatus.DEAD_STATUS
# log if status command failed
if status == LiveStatus.DEAD_STATUS:
stderr = component_status_result['stderr']
if "ComponentIsNotRunning" not in stderr and "ClientComponentHasNoStatus" not in stderr:
self.logger.info("Status command for {0} failed:\n{1}".format(component_name, stderr))
result = {
'serviceName': service_name,
'componentName': component_name,
'command': command_name,
'status': status,
'clusterId': cluster_id,
}
if status != self.reported_component_status[cluster_id]["{0}/{1}".format(service_name, component_name)][command_name]:
logging.info("Status for {0} has changed to {1}".format(component_name, status))
self.recovery_manager.handle_status_change(component_name, status)
if report:
with self.reports_to_discard_lock:
self.reports_to_discard.append(result)
self.send_updates_to_server({cluster_id: [result]})
return result
return None
其中
requestComponentStatus()做组件状态请求,然后返回component_status_result结果集
component_status_result = self.customServiceOrchestrator.requestComponentStatus(command_dict)
DEBUG后将这个component_status_result 取了出来,如下
{
'structuredOut': {
u'version': u'3.1.0.0-78',
u'repository_version_id': 1
},
'stdout': "2020-07-08 11:10:24,938 - Action afix 'pre_get_version' not present\n2020-07-08 11:10:24,938 - Action afix 'post_get_version' not present\nPackages:\n accumulo-client\n accumulo-gc\n accumulo-master\n accumulo-monitor\n accumulo-tablet\n accumulo-tracer\n atlas-client\n atlas-server\n beacon\n beacon-client\n beacon-server\n druid-broker\n druid-coordinator\n druid-historical\n druid-middlemanager\n druid-overlord\n druid-router\n druid-superset\n falcon-client\n falcon-server\n flume-server\n hadoop-client\n hadoop-hdfs-client\n hadoop-hdfs-datanode\n hadoop-hdfs-journalnode\n hadoop-hdfs-namenode\n hadoop-hdfs-nfs3\n hadoop-hdfs-portmap\n hadoop-hdfs-secondarynamenode\n hadoop-hdfs-zkfc\n hadoop-httpfs\n hadoop-mapreduce-client\n hadoop-mapreduce-historyserver\n hadoop-yarn-client\n hadoop-yarn-nodemanager\n hadoop-yarn-registrydns\n hadoop-yarn-resourcemanager\n hadoop-yarn-timelinereader\n hadoop-yarn-timelineserver\n hbase-client\n hbase-master\n hbase-regionserver\n hive-client\n hive-metastore\n hive-server2\n hive-server2-hive\n hive-server2-hive2\n hive-webhcat\n hive_warehouse_connector\n kafka-broker\n knox-server\n livy-client\n livy-server\n livy2-client\n livy2-server\n mahout-client\n oozie-client\n oozie-server\n phoenix-client\n phoenix-server\n pig-client\n ranger-admin\n ranger-kms\n ranger-tagsync\n ranger-usersync\n shc\n slider-client\n spark-atlas-connector\n spark-client\n spark-historyserver\n spark-schema-registry\n spark-thriftserver\n spark2-client\n spark2-historyserver\n spark2-thriftserver\n spark_llap\n sqoop-client\n sqoop-server\n storm-client\n storm-nimbus\n storm-slider-client\n storm-supervisor\n superset\n tez-client\n zeppelin-server\n zookeeper-client\n zookeeper-server\nAliases:\n accumulo-server\n all\n client\n hadoop-hdfs-server\n hadoop-mapreduce-server\n hadoop-yarn-server\n hive-server\n2020-07-08 11:10:25,023 - Command: /usr/bin/hdp-select status hadoop-hdfs-datanode > /tmp/tmpTAl577\nOutput: hadoop-hdfs-datanode - 3.1.0.0-78\n\n2020-07-08 11:10:25,024 - Version for component hadoop-hdfs-datanode: 3.1.0.0-78",
'stderr': '',
'exitcode': 0
}
requestComponentStatus()如下
def requestComponentStatus(self, command_header, command_name="STATUS"):
"""
Component status is determined by exit code, returned by runCommand().
Exit code 0 means that component is running and any other exit code means that
component is not running
"""
override_output_files = True
if logger.level == logging.DEBUG:
override_output_files = False
# make sure status commands that run in parallel don't use the same files
status_commands_stdout = self.status_commands_stdout.format(uuid.uuid4())
status_commands_stderr = self.status_commands_stderr.format(uuid.uuid4())
status_structured_out = self.status_structured_out.format(uuid.uuid4())
try:
res = self.runCommand(command_header, status_commands_stdout,
status_commands_stderr, command_name,
override_output_files=override_output_files, is_status_command=True,
tmpstrucoutfile=status_structured_out)
#add debug log
logger.debug('=====gaofeng=====requestComponentStatus=====status_commands_stdout=== %s',status_commands_stdout)
logger.debug('=====gaofeng=====requestComponentStatus=====status_commands_stderr=== %s',status_commands_stderr)
logger.debug('=====gaofeng=====requestComponentStatus=====status_structured_out=== %s',status_structured_out)
logger.debug('=====gaofeng=====requestComponentStatus=====res=== %s',res)
finally:
try:
os.unlink(status_commands_stdout)
os.unlink(status_commands_stderr)
os.unlink(status_structured_out)
except OSError:
pass # Ignore failure
return res
DEBUG 2020-07-08 11:10:25,050 CustomServiceOrchestrator.py:541 - =====gaofeng=====requestComponentStatus=====status_commands_stdout=== /var/lib/ambari-agent/data/status_command_stdout_ce21f1b2-d80d-46aa-949c-5576a2ef6755.txt
DEBUG 2020-07-08 11:10:25,050 CustomServiceOrchestrator.py:542 - =====gaofeng=====requestComponentStatus=====status_commands_stderr=== /var/lib/ambari-agent/data/status_command_stderr_73644f49-c8d8-4f3f-8841-6e733271ce40.txt
DEBUG 2020-07-08 11:10:25,050 CustomServiceOrchestrator.py:543 - =====gaofeng=====requestComponentStatus=====status_structured_out=== /var/lib/ambari-agent/data/status_structured-out-a9bc749d-c09a-49a5-b722-cd26502b5ea3.json
DEBUG 2020-07-08 11:10:25,050 CustomServiceOrchestrator.py:544 - =====gaofeng=====requestComponentStatus=====res=== {'structuredOut': {u'version': u'3.1.0.0-78', u'repository_version_id': 1}, 'stdout': "2020-07-08 11:10:24,938 - Action afix 'pre_get_version' not present\n2020-07-08 11:10:24,938 - Action afix 'post_get_version' not present\nPackages:\n accumulo-client\n accumulo-gc\n accumulo-master\n accumulo-monitor\n accumulo-tablet\n accumulo-tracer\n atlas-client\n atlas-server\n beacon\n beacon-client\n beacon-server\n druid-broker\n druid-coordinator\n druid-historical\n druid-middlemanager\n druid-overlord\n druid-router\n druid-superset\n falcon-client\n falcon-server\n flume-server\n hadoop-client\n hadoop-hdfs-client\n hadoop-hdfs-datanode\n hadoop-hdfs-journalnode\n hadoop-hdfs-namenode\n hadoop-hdfs-nfs3\n hadoop-hdfs-portmap\n hadoop-hdfs-secondarynamenode\n hadoop-hdfs-zkfc\n hadoop-httpfs\n hadoop-mapreduce-client\n hadoop-mapreduce-historyserver\n hadoop-yarn-client\n hadoop-yarn-nodemanager\n hadoop-yarn-registrydns\n hadoop-yarn-resourcemanager\n hadoop-yarn-timelinereader\n hadoop-yarn-timelineserver\n hbase-client\n hbase-master\n hbase-regionserver\n hive-client\n hive-metastore\n hive-server2\n hive-server2-hive\n hive-server2-hive2\n hive-webhcat\n hive_warehouse_connector\n kafka-broker\n knox-server\n livy-client\n livy-server\n livy2-client\n livy2-server\n mahout-client\n oozie-client\n oozie-server\n phoenix-client\n phoenix-server\n pig-client\n ranger-admin\n ranger-kms\n ranger-tagsync\n ranger-usersync\n shc\n slider-client\n spark-atlas-connector\n spark-client\n spark-historyserver\n spark-schema-registry\n spark-thriftserver\n spark2-client\n spark2-historyserver\n spark2-thriftserver\n spark_llap\n sqoop-client\n sqoop-server\n storm-client\n storm-nimbus\n storm-slider-client\n storm-supervisor\n superset\n tez-client\n zeppelin-server\n zookeeper-client\n zookeeper-server\nAliases:\n accumulo-server\n all\n client\n hadoop-hdfs-server\n hadoop-mapreduce-server\n hadoop-yarn-server\n hive-server\n2020-07-08 11:10:25,023 - Command: /usr/bin/hdp-select status hadoop-hdfs-datanode > /tmp/tmpTAl577\nOutput: hadoop-hdfs-datanode - 3.1.0.0-78\n\n2020-07-08 11:10:25,024 - Version for component hadoop-hdfs-datanode: 3.1.0.0-78", 'stderr': '', 'exitcode': 0}
再回到check_component_status()中
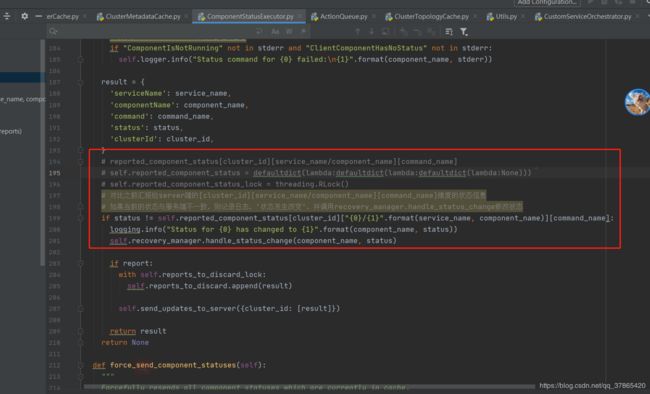
对比之前汇报给server端的
[cluster_id][service_name/component_name][command_name]维度的状态信息
如果当前的状态与服务端不一致,则记录日志,’状态发生改变’,
并调用recovery_manager.handle_status_change修改状态
5、总结
前提准备
InitializerModule.py中初始化metadata_cache、topology_cache等属性
(/var/lib/ambari-agent/cache/cluster_cache获取的)
在ComponentStatusExecutor.run()中
1、循环topology_cache中的所有cluster_ids
2、循环topology_cache中当前cluster_id的所有components
3、循环metadata_cache中status_commands_to_run所有的command_name(其实就一个status)
4、check_component_status()检查组件结果状态,如果组件状态已更改,
则给server返回组件状态,否则等待20s执行下一个ComponentStatusExecutor.run()。