带大家写一波微信公众号的爬取
开发工具
python版本 : 3.6.4
相关模块:
pdfkit模块;
requests模块;
以及一些Python自带的模块。
抓包工具: fiddler
环境搭建
- python 环境
安装Python并添加到环境变量,pip安装需要的相关模块即可。 - fiddler 环境
去官网下载最新版本的安装包直接安装。
fiddler官网
原理简介
首先,我们打开fiddler这个抓包软件,其界面如下:

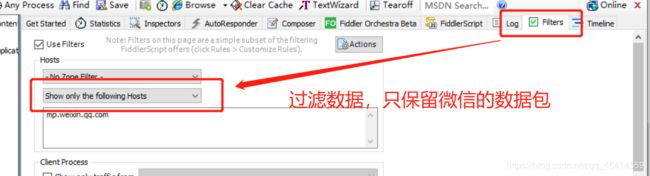
然后,我们设置一下过滤规则以过滤掉没用的数据包,因为我们只想抓取微信相关的数据包而已,而不想其他没用的数据包干扰我们的分析,就像这样:
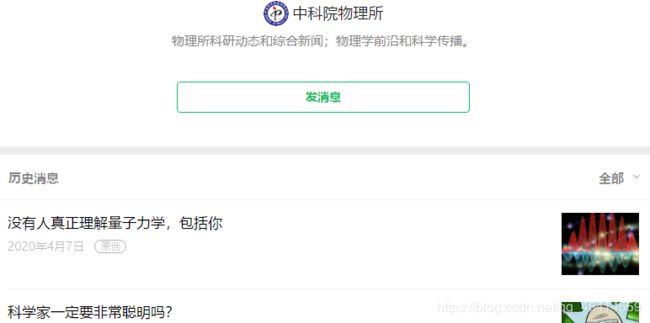
接着我们在电脑端登录微信,并随便找个公众号,查看它的历史文章列表。就像这样:
不断滚动鼠标滚轮,以查看该公众号更多的历史文章数据。此时,我们可以在fiddler里看到出现了类似如下图所示的情况:
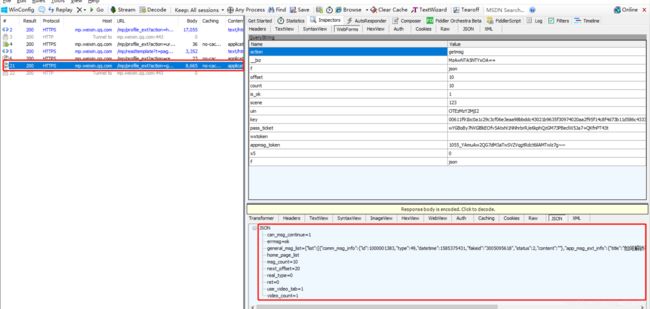
显然,红框里的https请求应该就是获得该微信公众号发的文章相关的数据的请求了。现在,我们来分析一下这个请求。显然,该请求的链接地址构成为:

接着看看请求头,请求头的话在这能看到:

感觉有个user-agent就足够了:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
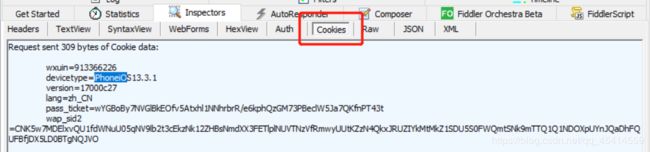
接着看看cookies,在这(应该直接复制到代码里就行了):
最后,再看看发送这个请求需要携带哪些参数吧,在这:

即:
action
__biz
f
offset
count
is_ok
scene
uin
key
pass_ticket
wxtoken
appmsg_token
x5
经过测试,我们可以发现如下参数是可以固定的:
action
f
is_ok
scene
uin
key
wxtoken
x5
其他参数的含义我们则可以根据经验和简单的测试进行判断:
1.offset
控制翻页的偏移量参数
2.count
每页的文章数量
3.__biz
公众号标识, 不同的__biz对应不同的公众号
4.pass_ticket
应该是微信登录之后返回的参数吧,
去年尝试模拟登录微信网页版的时候看到返回的参数里就好像有它,
但是现在微信网页版已经被官方封了T_T。
5.appmsg_token
应该也是微信登录之后的一个标识参数吧, 而且和阅读的微信公众号
有关,查看不同的微信公众号时该值也是不同的。
前面三个可变参数都好解决,后面两个参数似乎就比较难办了。不过经过测试,我们可以发现pass_ticket其实是一个可有可无的参数,所以我们可以不管它。而appmsg_token的有效期至少有10几个小时,这段时间足够我们爬取目标公众号的所有文章了,所以直接复制过来就可以了,没必要浪费时间分析这玩意(随便想想也应该知道白嫖腾讯肯定没那么容易的T_T)。写个代码简单测试一下:
import requests
session = requests.Session()
session.headers.update(headers)
session.cookies.update(cookies)
profile_url = '前面抓包得到的请求地址'
biz = 'MzAwNTA5NTYxOA=='
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g'
params = {
'action': 'getmsg',
'__biz': biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': pass_ticket,
'wxtoken': '',
'appmsg_token': appmsg_token,
'x5': '0'
}
res = session.get(profile_url, params=params, verify=False)
print(res.text)
运行之后可以发现返回的数据如下:

看来是没啥问题,重新调整封装一下代码,就可以爬取该公众号所有文章的链接啦。具体而言,核心代码实现如下:
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
运行之后,我们就可以获得目标公众号的所有文章链接啦:

现在,我们只需要根据这些文章链接来爬取文章内容就行啦。这里我们借助python的第三方包pdfkit来实现将每篇文章都保存为pdf格式的文件。具体而言,核心代码实现如下:
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
注意,使用pdfkit前需要先安装wkhtmltox。如下图所示:
运行的效果大概是这样子的:

全部源码
根据自己的抓包结果修改cfg.py文件:
## cfg.py
# 目标公众号标识
biz = 'MzAwNTA5NTYxOA=='
# 微信登录后的一些标识参数
pass_ticket = ''
appmsg_token = '1055_YAmuAw2QG7dM3aTwSVZVqgtRdct6ilAMTwlz7g~~'
# 安装的wkhtmltopdf.exe文件路径
wkhtmltopdf_path = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
## articlesSpider.py
import os
import time
import json
import pdfkit
import random
import requests
import warnings
warnings.filterwarnings('ignore')
'''微信公众号文章爬取类'''
class articlesSpider(object):
def __init__(self, cfg, **kwargs):
self.cfg = cfg
self.session = requests.Session()
self.__initialize()
'''外部调用'''
def run(self):
self.__getArticleLinks()
self.__downloadArticles()
'''获得所有文章的链接'''
def __getArticleLinks(self):
print('[INFO]: 正在获取目标公众号的所有文章链接...')
fp = open('links_tmp.json', 'w', encoding='utf-8')
article_infos = {}
params = {
'action': 'getmsg',
'__biz': self.cfg.biz,
'f': 'json',
'offset': '0',
'count': '10',
'is_ok': '1',
'scene': '123',
'uin': '777',
'key': '777',
'pass_ticket': self.cfg.pass_ticket,
'wxtoken': '',
'appmsg_token': self.cfg.appmsg_token,
'x5': '0'
}
while True:
res = self.session.get(self.profile_url, params=params, verify=False)
res_json = res.json()
can_msg_continue = res_json.get('can_msg_continue', '')
next_offset = res_json.get('next_offset', 10)
general_msg_list = json.loads(res_json.get('general_msg_list', '{}'))
params.update({'offset': next_offset})
for item in general_msg_list['list']:
app_msg_ext_info = item.get('app_msg_ext_info', {})
if not app_msg_ext_info: continue
title = app_msg_ext_info.get('title', '')
content_url = app_msg_ext_info.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if app_msg_ext_info.get('is_multi', '') == 1:
for article in app_msg_ext_info.get('multi_app_msg_item_list', []):
title = article.get('title', '')
content_url = article.get('content_url', '')
if title and content_url:
article_infos[title] = content_url
if can_msg_continue != 1: break
else: time.sleep(1+random.random())
json.dump(article_infos, fp)
fp.close()
print('[INFO]: 已成功获取目标公众号的所有文章链接, 数量为%s...' % len(list(article_infos.keys())))
'''下载所有文章'''
def __downloadArticles(self):
print('[INFO]: 开始爬取目标公众号的所有文章内容...')
if not os.path.exists(self.savedir):
os.mkdir(self.savedir)
fp = open('links_tmp.json', 'r', encoding='utf-8')
article_infos = json.load(fp)
for key, value in article_infos.items():
print('[INFO]: 正在抓取文章 ——> %s' % key)
key = key.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('<', '').replace('>', '').replace('|', '_')
pdfkit.from_url(value, os.path.join(self.savedir, key+'.pdf'), configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('[INFO]: 已成功爬取目标公众号的所有文章内容...')
'''类初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1295.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat'
}
self.cookies = {
'wxuin': '913366226',
'devicetype': 'iPhoneiOS13.3.1',
'version': '17000c27',
'lang': 'zh_CN',
'pass_ticket': self.cfg.pass_ticket,
'wap_sid2': 'CNK5w7MDElxvQU1fdWNuU05qNV9lb2t3cEkzNk12ZHBsNmdXX3FETlplNUVTNzVfRmwyUUtKZzN4QkxJRUZIYkMtMkZ1SDU5S0FWQmtSNk9mTTQ1Q1NDOXpUYnJQaDhFQUFBfjDX5LD0BTgNQJVO'
}
self.profile_url = 'https://mp.weixin.qq.com/mp/profile_ext'
self.savedir = 'articles'
self.session.headers.update(self.headers)
self.session.cookies.update(self.cookies)
'''run'''
if __name__ == '__main__':
import cfg
spider = articlesSpider(cfg)
spider.run()