为什么神经网络能以任意精度拟合任意复杂度的函数?——转自简书
本文转自简书,作者朱新威。原文链接如下:
https://www.jianshu.com/p/9ed784e7557b?utm_campaign=maleskine&utm_content=note&utm_medium=reader_share&utm_source=weixin
在开始之前,我们先来看一下维基百科给出的万能近似定理(Universal approximation theorem)描述:
In the mathematical theory of artificial neural networks, the universal approximation theorem states that a feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of R, under mild assumptions on the activation function.
Universal approximation theorem(Hornik et al., 1989;Cybenko, 1989)定理表明:前馈神经网络,只需具备单层隐含层和有限个神经单元,就能以任意精度拟合任意复杂度的函数。这是个已经被证明的定理。下面我们用一种轻松的方式解释,为什么神经网络(理论上)可以拟合任何函数?
1. 线性回归(Linear Regression): 一道小学题
看过《神偷奶爸》这部电影的同学都知道,小黄人(Minions)非常喜欢吃香蕉。不过,现在它只有12个苹果,但它对苹果不感兴趣,想着如果谁能用香蕉换它的苹果就好了。不经意间,它发现了一个神奇的小屋。
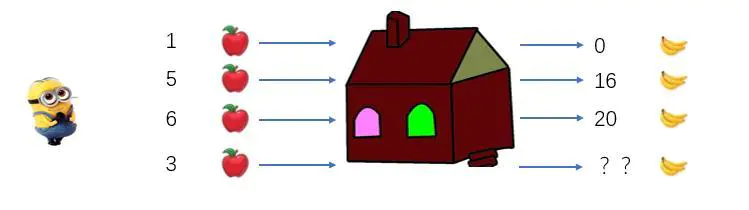
图1.1 神奇小屋
小黄人向神奇小屋的窗户里放进一个苹果,神奇小屋什么也不会给它。小黄人又尝试向小屋的窗户里放进5个苹果,神奇小屋突然吐出16个香蕉!这下小黄人可高兴坏了。然后,小黄人又尝试扔给神奇小屋6个苹果,神奇小屋又吐出来20个香蕉。
现在,小黄人的12个苹果用完了,它抱着换来的香蕉想:如果我给它3个苹果,小屋会吐出来多少香蕉呢?
这是一道小学题(找规律),如何解答?
你可能脱口而出,8个香蕉!!OK,好吧,说明你的智商可以学习AI这么高深的学科了~
如何使用机器学习的步骤解答这道小学生做的题目呢(你可能觉得这是杀鸡用了宰牛刀)。
我们使用变量 x 表示扔给神奇小屋的苹果数量(输入input),使用变量 ŷ 表示神奇小屋吐出来的香蕉数量(输出Output),那么我们就得到了一个数据集(Data set):
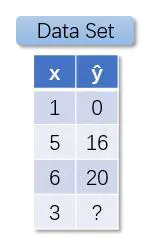
图1.2 数据集
我们的目标是,构建一个数学模型(Model),使得该模型满足数据集的隐含规律。即,向模型输入 x 的值,模型会输出对应的 ŷ 值。
小学生应该学过一元函数(y = wx + b)。既然是小学题目,那么使用比较简单的函数应该就能模拟数据集的规律。所以我们定义了一个一元一次函数模型:

图1.3 一元函数模型
那么问题来了,我们怎样才能确定函数的两个参数w,b?
聪明的你可能又会脱口而出,是y = 4x + (-4) !!OK,你再次证明了你的智商已经超过小学生或者初中生。
但是小黄人没有你那么聪明,它只能猜。如果w=1, b=0,结果会是怎样?
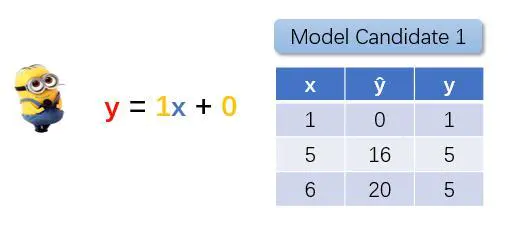
图1.4 候选模型1
很明显,模型的输出(预测)值 y 与实际数据集中的真实值 ŷ 相差很大。小黄人不满意,又随机猜了一次。w=2,b=2,结果又是怎样呢?
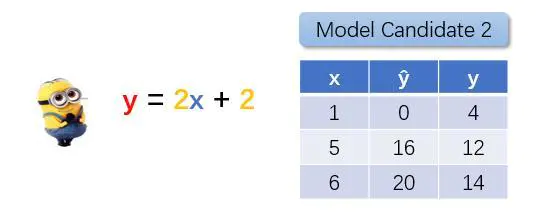
图1.5 候选模型2
嗯,这次模型的输出值 y 与数据集中的真实值 ŷ 相差似乎不那么大了。小黄人就想,这两个候选模型,哪一个更好呢(更能模拟数据集中的规律)?如何将”更好“量化?
于是,我们引出损失函数(lost function)的概念。
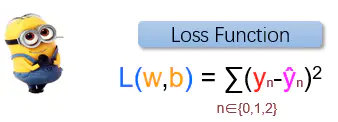
图1.6 损失函数
将预测值 y 与真实值 ŷ 之间的差值平方和,作为“更好”的一种量化。损失函数越小,即,预测值与真实值之间的差值越小,说明参数w,b越能模拟数据集中的规律。
扩展:
最小二乘法(least square method):如果你对机器学习有所了解,应该听过这个概念。在线性回归中,最小二乘法就是试图找到一条直线,使所有样本(数据集)到直线上的欧式距离之和最小。突然冒出两个概念,可能让你感觉有点不适。没关系,我们先来看一下图1.3,让你有个直观感受。
你可以这样理解。欧式距离就是每个点到函数直线上的最短距离。中文翻译的“最小二乘法”不容易理解。它的英文名称是“least square method“。least的意思是“最小、最少”,这个容易理解;“square”的意思是“平方”,也就对应上面损失函数中的预测值与真实值的差值平方。其实“二乘”就是“平方”的意思。
所以,最小二乘法就是设法找到模型参数w、b,使得上面定义的损失函数值最小。最小二乘法是一种数学优化技术,对应下文讲到的优化器。
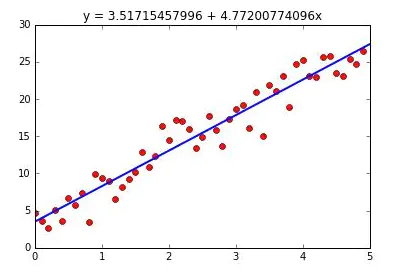
图1.3 最小二乘法
有了损失函数,我们来看一看,上面两个候选模型的损失函数值各是多少。
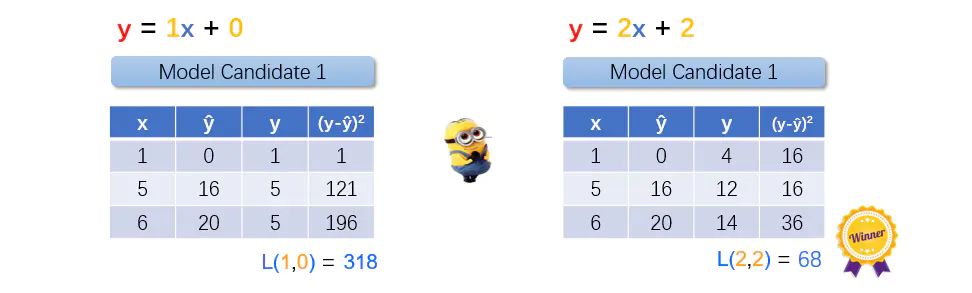
图1.7 候选模型比较
模型 y = 2x + 2 的损失函数值L(2,2) = 68,小于L(1,0) = 318,所以候选模型y = 2x + 2胜出。
小黄人是一个追求极致的人。损失函数值68虽然小于318,但是它还是很大呀,有没有其他参数w,b使得损失函数L(w,b)的值比68还小。
所以,我们又引出了优化器(Optimizer)的概念。

图1.8 优化器
想办法找出使得损失函数值L(w,b)最小的参数w,b。由于小黄人没有学过梯度下降法(一种凸函数优化算法,不懂也没关系,现在用不到),所以它只能使用....”随机尝试法“。

图1.9 "随机尝试法"
小黄人从参数w=2,b=2,开始,以步长为1进行随机尝试。即,在“加一减一”的范围内,尝试坐标点(2,2)周围的四个点 : (3,2)、(2,3)、(1,2)、(1,1)。结果发现,在点(3,2)处,损失函数值小于其他三个点和原先点处的损失值。
所以,小黄人发现了一个更好的候选模型 y = 3x + 2,其损失函数值为26,比68小的多。小黄人,很兴奋,用同样的方式又开始了尝试。以此类推,它接着发现了L(3,1) =17、L(3,0) =14 两个坐标点。然而,在点(3,0)周围的尝试,都没有发现比14更小的损失函数值。

图1.10 结束了?
这样就结束了吗?
高智商的你,一定能想到,在点(4,-4)处,损失函数值最小:L(4,-4) =0。但是,用上述尝试方法并不能找到坐标点(4, -4)。
问题出在了哪儿?是初始点选择的问题。

图1.11 换个初始点开始
小黄人发现,如果从坐标点(-2,-4)开始上述方式的尝试,最终会找到使得损失函数最小的(4,-4)点。如果深入研究,将涉及到最优搜索问题,超出本片文章的范围。
我们当前只需知道,能够通过最优方法(如,最小二乘法),找到使得损失函数最小的模型参数w,b。
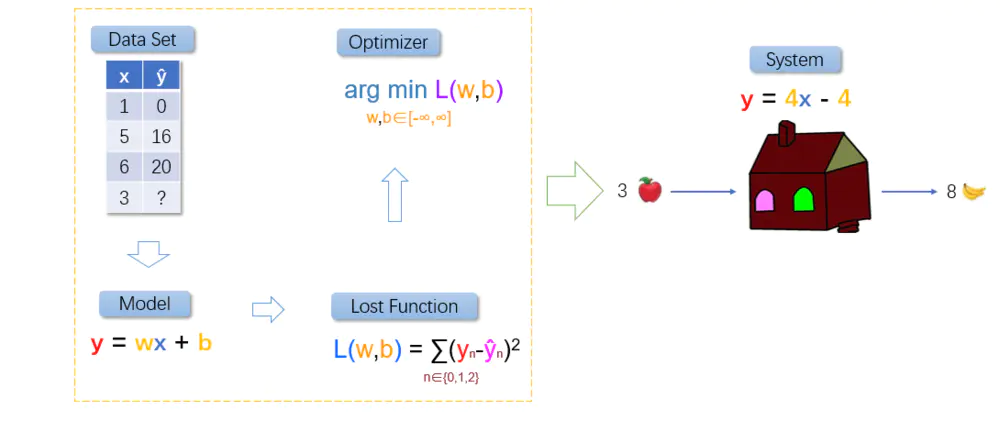
图1.12 整体流程
上面这个故事就是线性回归??
我们需要给出一个稍微严谨点的定义,来说明什么是线性回归。下面是《机器学习》(周志华著)中给出的一句话:
“线性回归”(linear regression)试图学得一个线性模型以尽可能准确地预测实值输出标记。
将这句话对应到我们的模型中。模型函数 y = 4x - 4 就是句中学得的“线性模型”。然后,在我们的故事中,不是尽可能准确地预测真实值输出标记,而是百分百预测了真实值输出标记....损失函数值能够达到最小0。
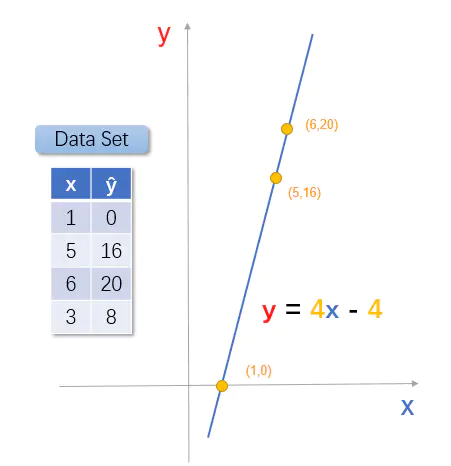
图1.13 线性回归
其实,没那么简单......我们稍微扩展一下。
有一天,小黄人发现,如果给神奇小屋1个苹果、2个香蕉、3个梨,神奇小屋就会吐给它一只猫咪~ 喵喵喵~。真的太神奇了。。。。
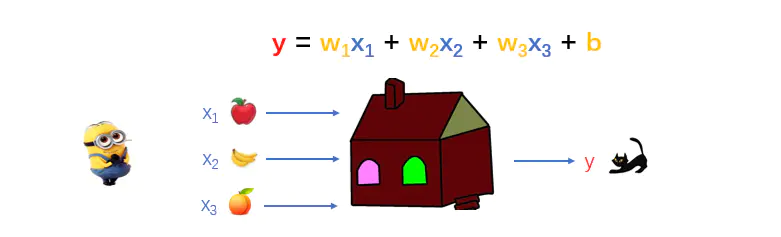
图 猫咪
这时,模型函数不再是简单的一元函数,而是三元函数,有三个输入变量 (x1, x2, x3),和4个参数 (w1, w2, w3, b) 需要优化。我们将这种情况称之为“多元线性回归(multivariate linear regression)”。其实这是图像识别的原型模型,我们不再深入探讨。
2. 逻辑回归(Logistic Regression): 一个压缩函数
当小黄人发现了神奇小屋交换香蕉的规律后,非常非常高兴。它又找来了好多苹果,准备和神奇小屋交换香蕉。可是....生活就是这样。在你最得意的时候,往往会给你浇一盆凉水。

图2.1
(注,这里将之前的数据集调整了一下,由x=1,5,6改为x=1,2,3。方便画图啦)
小黄人又尝试给神奇小屋4个和5个苹果,结果分别得到9个和10个香蕉。似乎哪里有点不对??!如果按照之前发现的规律,应该分别得到12和20个香蕉呀。小黄人,百思不得其解。
这时,神奇小屋吐出来一张纸条,上面写着:如果你扔进来的苹果太多,我给你的香蕉将会减少。小黄人,有点郁闷。
如果按照之前一元函数的方式建模,将会得到如下函数模型。
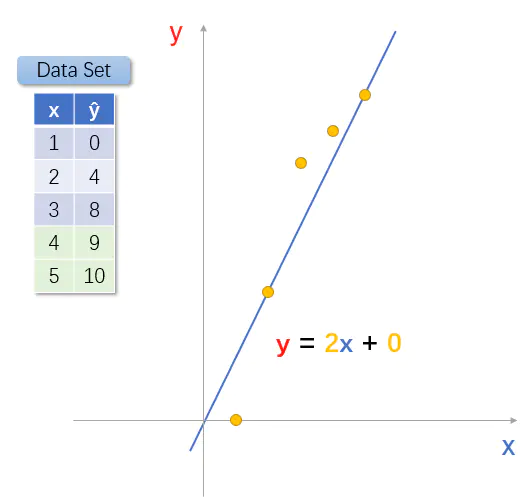
图2.2
你可能比小黄人聪明多了,一眼就看出来上面的模型函数好像不太合适。损失函数永远取不到最小值0。
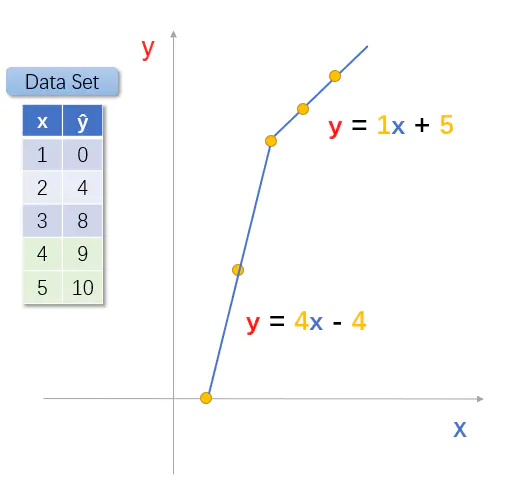
图2.3
如果模型函数是这样就好了,那么对应的损失函数值将会取到最小值0。可是,这好像是两个模型函数。一山不容二虎,能不能将这两个函数合成一个函数。
这时,你又脱口而出,分段函数!!事实证明,你的智商已经达到高中生水平。
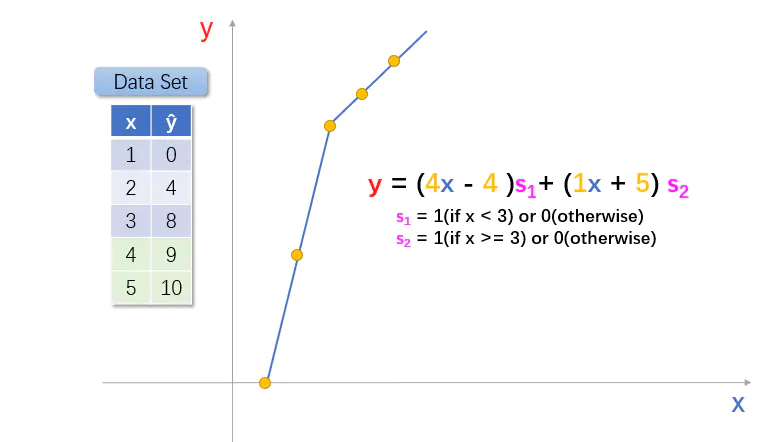
图2.4
当 x < 3 时,s1 等于1,s2 等于0,函数 y = 4x - 4;
当 x >= 3 时,s1 等于0,s2 等于1,函数 y=1x + 5;
这才是完美的组合函数。
那么,问题又来了。s1和s2是什么?怎么确定?
如果把s2看成函数,那么理想情况下,应该是这样的阶跃函数。
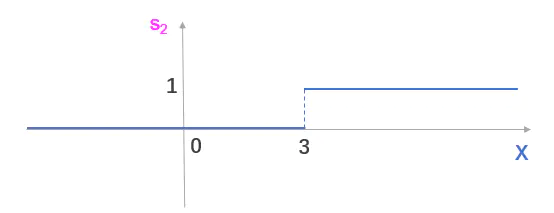
图2.5 阶跃函数
然而阶跃函数具有不连续、不光滑等不太好的性质。
这时,小黄人悠悠地说,我好像见过一个跟这个函数有点像的连续函数,叫Sigmoid函数。
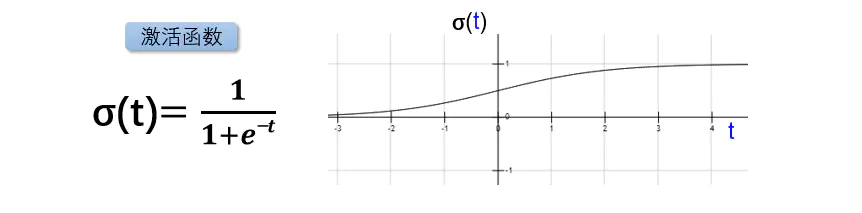
图2.6 激活函数
看到这个Sigmoid函数后,你很生气。对着小黄人说:人笨就少说话,这个函数和阶跃函数,哪里相像了,差的也太远吧!!怎么看怎么不像。
小黄人:你给变量t一个参数不就行了,改成σ(1000t)。(抠鼻)
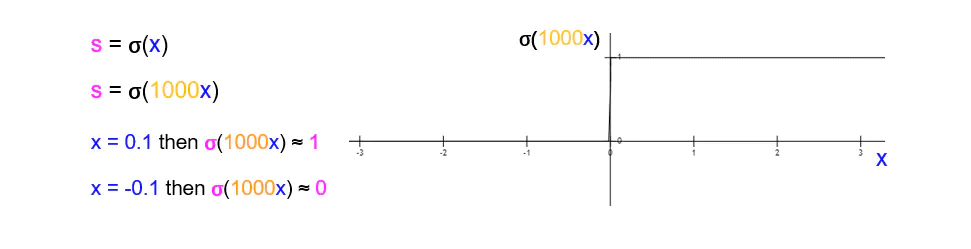
图2.7 激活函数2
如果不仔细看,几乎看不出在纵轴0到1之间,有个非常陡峭的曲线。你顿时无语,对小黄人刮目相看。
当 x = 0.1 时,s = σ(100) ≈ 1;
当 x = - 0.1 时,s = σ(100) ≈ 0;
稍微对这个Sigmoid函数做些调整,就能得到我们需要的各种阶跃函数。
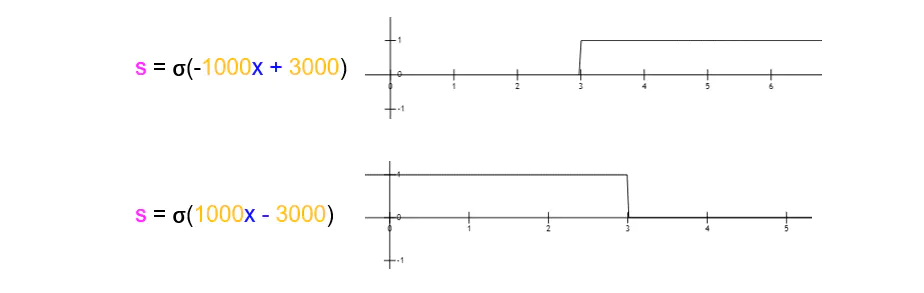
sigmoid函数模拟阶跃函数
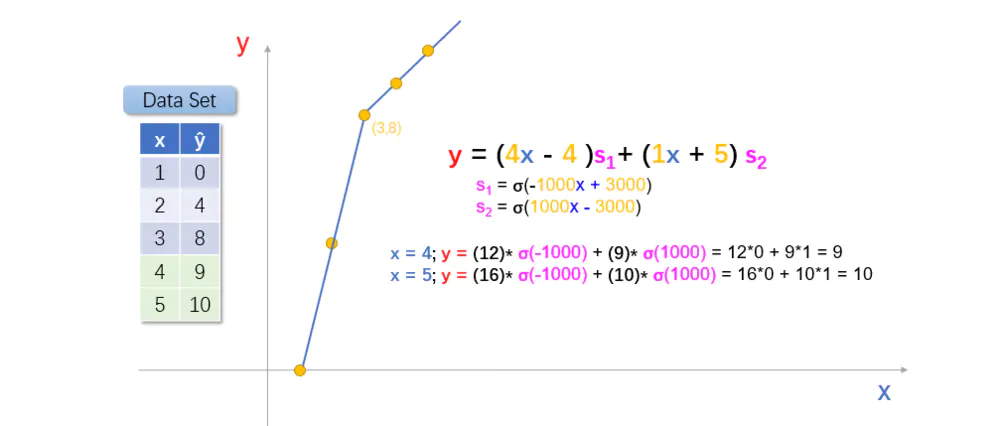
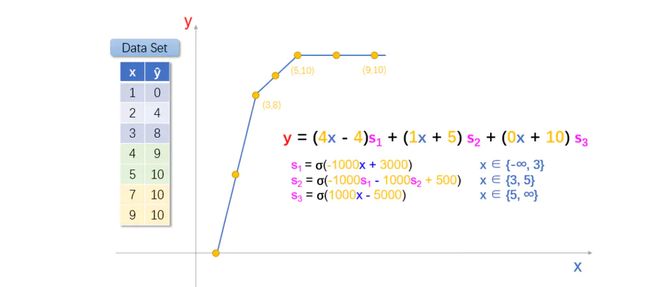
这样的话,我们就得到了新的模型函数,y = (4x - 4)σ(-1000x + 3000)+ (1x + 5)σ(1000x - 3000);
如,当 x = 4 时, y = (12) σ(-1000) + (9)σ(1000) = 12*0 + 9*1 = 9,与数据集相符。
在这个过程中,小黄人还是有功劳的,提出了激活函数的概念。
下面我们看一下稍微严谨点的逻辑回归定义。
逻辑回归 (logistic regression ),是一种广义线性回归(generalized linear regression model)。
这一句话就够了。在第一节中我们已经学习线性回归模型 y = wx + b。观察图,能够发现,逻辑回归其实就是在线性回归的结果上在再使用一次激活函数 y = σ(wx + b)。线性回归模型 (y = wx + b) 的预测值y可以是一个任意实数{-∞, ∞},而逻辑回归模型 (y = σ(wx + b)) 的预测值y只能是{0, 1}之间的实数。如果能够搞明白线性回归与逻辑回归的联系,说明你已经掌握两者的本质含义。
3. 多层感知机(Multilayer perceptron):
小黄人想,虽然给的香蕉数量少了些,最起码小屋吐出来的香蕉比扔进去的苹果多嘛。于是,小黄人又尝试向神奇小屋里扔进去了7个和9个苹果。
结果,神奇小屋两次都只返还出来10个香蕉。这下小黄人傻眼了。
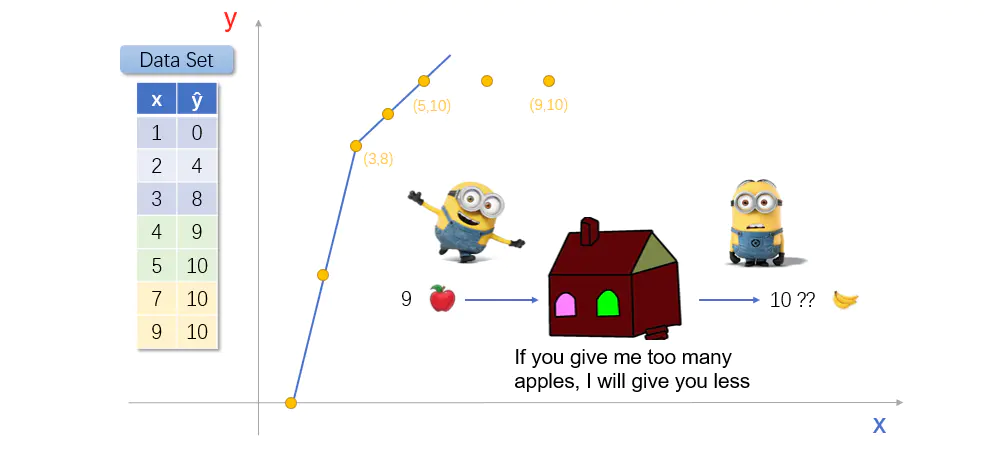
图 傻眼
虽然小黄人在其他事情上比较笨,但是只要与香蕉相关,它可精明的多。刚刚5个苹果就能换10个香蕉,现在9个苹果才能换10个香蕉!!明显自己吃亏了。但是,它又非常不喜欢吃苹果,只能强忍怨气,攒着一股劲,一定要把里面的规律找出来。
经过之前的套路,机智的你,一定能想到解决办法。
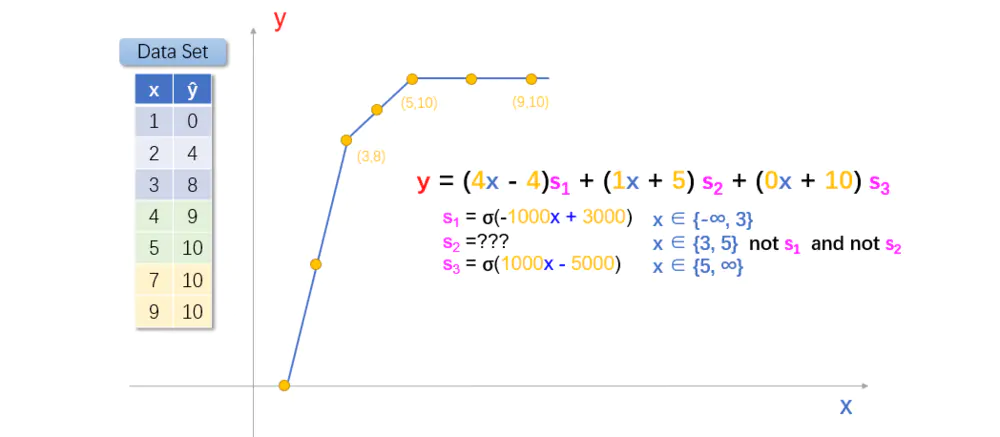
图
对,就是这样。将数据集分成三块,分别构建线性模型函数,然后利用激活函数,组合起来。
问题再次出现。
当 x < 3 时,s1 = σ(-1000x + 3000) = 1,其他情况为0;
当 x >= 5 时,s3 = σ(1000x - 5000) = 1,其他情况为0;
当 3 <= x < 5 时,s2 = ??
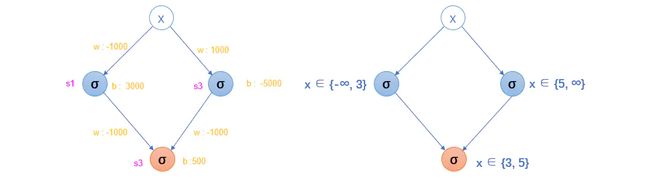
不知道聪明的你有没有注意到,函数 s1 和 s3 都是以 x 作为未知变量。如果我们转换一下思路,将 s2 看成是 s1 和 s3的二元函数。即,s2是否等于1或0,由 s1 和 s2 的值决定。
s2 = σ(-1000s1 - 1000s2 + 500)

图
虽然得到的香蕉数目不再增加,但是这么复杂的问题都能解决掉(使用线性回归和逻辑回归相结合,对数据集建模),小黄人还是有点小高兴。反正它手里还有些苹果,于是它又尝试向神奇小屋里丢进去了10、11、12个苹果。结果...小黄人崩溃了!!
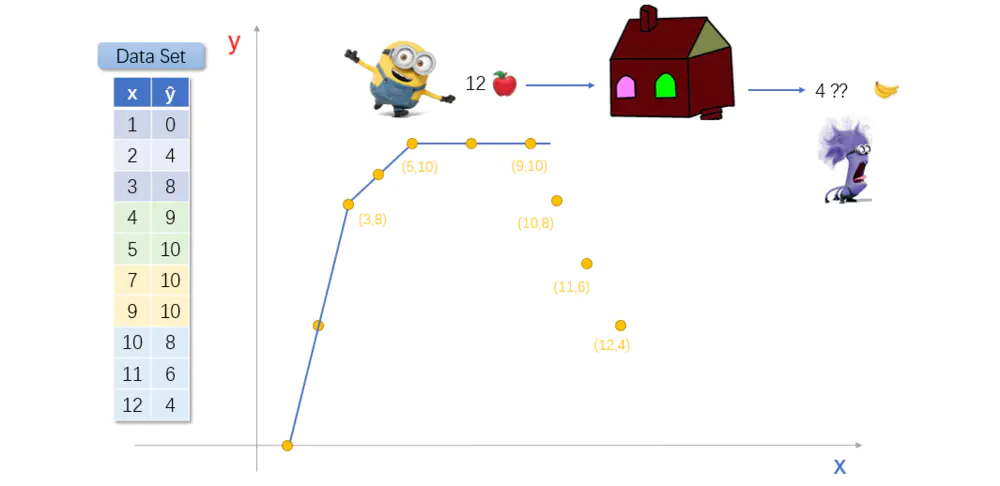
图
神奇小屋传出来纸条说:做人不能贪得无厌,要见好就收,知足常乐。小黄人崩溃了。现在只留下一个未被解决的难题----怎么对数据集进行建模。
即使你很聪明,似乎也只能解决其中的两步。
取 s1 = σ(-1000x + 3000),即,当 x < 3 时,s1 = 0;
取 s4 = σ(1000x - 9000),即,当 x >= 9 时,s4 = 0;
那么 s1 和 s2 该如何确定?
根据之前的经验,你大致可以确定s1和s2应该由s1和s4的值确定。
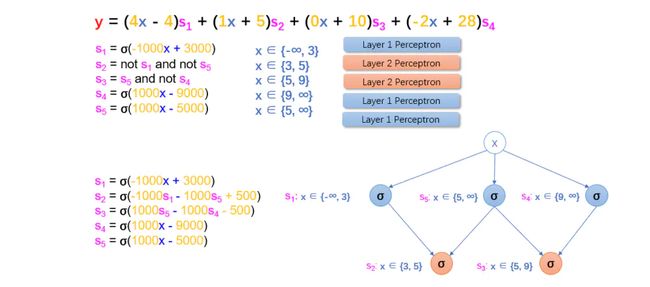
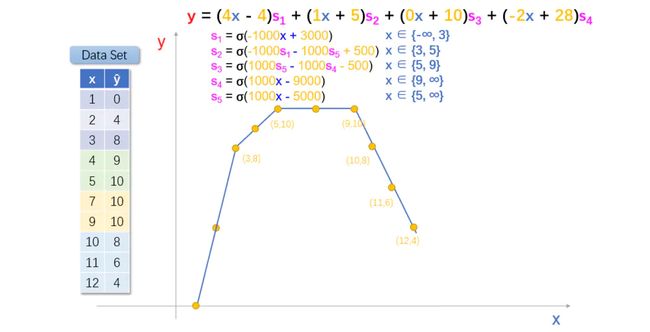
后续......
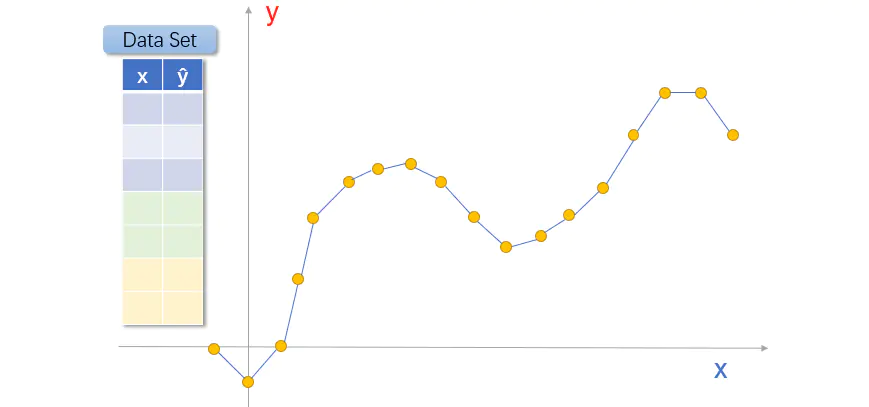
假设现在我们有许多数据集,
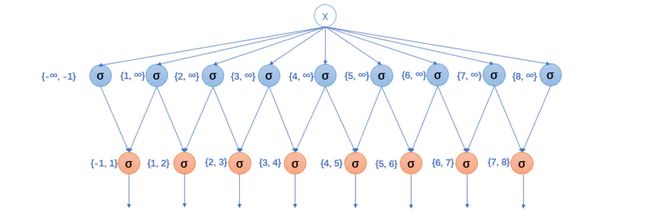
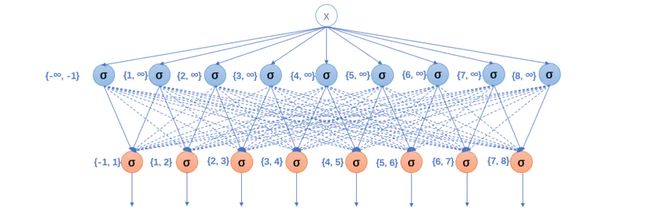
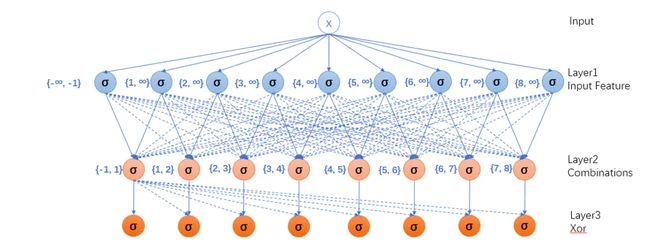
梳理一下流程
重点来了
免喷声明:本文借鉴(chao xi)牛津大学xDeepMind 自然语言处理公开课
作者:朱新威
链接:https://www.jianshu.com/p/9ed784e7557b
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。