All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirections.
计算机科学中,任何问题都可以通过增加一层抽象(间接寻址)来实现,当然除了间接问题太多。 英文水平比较渣 ,只能翻译成到这种'只可意会不可言传'的程度。
那我们从直接寻址开始说起。内存就是一维数组,数据和代码片段存在其中,要找到这些数据和代码片段 (数据和代码片段只是人为的划分) 只需要知道它所处位置的地址(编号)即可。代码中的变量名和函数名在经过编译和链接后转换成对应的内存地址(编号)。c语言中就是这样的:
int add(int a,int b)
{
return a + b;
}
typedef int (*FUNC_POINTER)(int,int);
int main(int argc, const char * argv[]) {
long fun_address = (long)add;
printf("函数地址为:%ld\n",fun_address);
FUNC_POINTER f_p = (FUNC_POINTER)fun_address;
printf("1 + 2 = %d\n",(*f_p)(1,2));
printf("Hello, World!\n");
return 0;
}
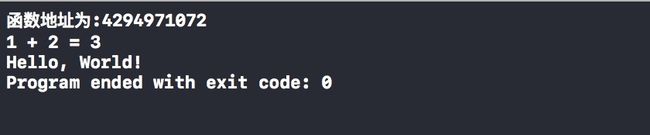
运行的结果很直白,我们将 add(函数名)转换成long型后赋值给另一个长整型变量并打印,然后我们将这个长整型变量再转换成函数指针(地址 编号)赋值给另一个指针变量。最后通过这个指针(地址 编号)成功调用了我们定义的add函数。很直接吧,直接奔着指针(地址 编号)去。
接下来我们谈一个初级的"间接"问题。如何实现一个结构体。我们有一万个理由去使用结构体。比如说 有些数据就是要放在一起才有意义 ;放在一起方便处理:记录学生各科成绩数据,如果没有结构体,我们可能需要很多个一维数组,每个数组按照序号储存学生的单科成绩,这时候如果遇到需要排序的功能要求,那就相当蛋疼了,需要调整N多个数组。很容易出差错;......等等诸如此类的原因吧。还是一个很简单的小栗子:
struct Scores
{
int math;
int English;
int physics;
};
typedef struct Scores Student;
int main(int argc, const char * argv[]) {
// insert code here...
Student zhangyu;
zhangyu.math = 100;
zhangyu.english = 66;
zhangyu.physics = 100;
int * score = &zhangyu;
printf("math score = %d\n",*score);
printf("english score = %d\n",*(score+1));
printf("physics score = %d\n",*(score+2));
printf("Hello, World!\n");
return 0;
}
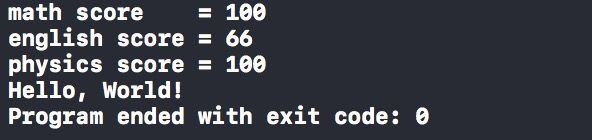
(这里只列了几个成绩,绝对只是因为我懒,个人相当不赞成用成绩来衡量一个人的全部,即使是学生。)既然变量名可以被转换为地址,结构体中的成员聚在一块,我们有了这么一大块内存的地址,自然也就很方便的可以找到各个成员的具体地址(指针 编号)了。代码中我们就是这么干的,& 是C语言中取地址的符号,我们取得了结构体变量的指针后赋值给了一个int型的指针变量,然后通过这个变量分别获得了结构体中第二个成员和第三个成员的内容。这不就是间了个接么。
数据有放到一块的需要,代码段(函数)自然也有需求。当程序规模大了,很多的函数,恐怕程序员就有点吃不消了。如果能将这些函数整理整理,分门别"类","类",“类” 该多好。这些个函数是跟键盘有关的,就先写个 KeyBoard(类名,告诉函数的使用者,接下来这些函数是跟KeyBoard相关的) 随后用大括号将它们括起来。当然了 为了清楚的说明这些情况,我们用Class关键字来开门见山的指明,我们要 分门别“类”了。
class KeyBoard
{
void func1();
void func2();
void func3();
......
int a;
int b;
int c;
};
此时 我们将三个函数和三个成员变量给聚到一块去了,分门别了个“类”。函数要怎么处理呢?函数能不能也想变量那样,简单给凑合凑合捆绑在一块呢,然后根据偏移来计算地址呢?似乎不那么容易吧。结构体是由基本数据类型组成的,而基本数据类型的大小(在内存中所占的字节数)是固定的。这显然在计算偏移的时候是容易的。而代码段就不那么容易了。稍加思索,可以想到,如果我们给函数名加上个标记,一个 “类”中的函数都有着同样的标记,至于函数地址嘛,还是该怎么样就怎么样。函数名到地址间的映射由编译器来为我们完成。于是Student中的sleep函数可以被重命名为Student_sleep,Principal(校长)的sleep函数可以被重命名为Principal_sleep。同样是睡觉 校长的“睡姿”跟你可是完全不同的。接下来还有一个问题,这些类中也有成员变量,类中的函数要处理成员变量,同一个类所用的成员函数是一样的,可是处理的变量肯定不能相同,如果Principal类有个成员变量 bed,当某个具体的Principal对象 (王校长)在执行sleep的时候,他就得睡自个儿的床,睡别人的那是隔壁老王。要找到自个儿的成员变量,就需要自己的变量地址。于是每一个类的成员函数都在原型的基础上多加一个参数 Principal_sleep(Principal * p)。这个参数为编译器自动添加。完全是不知不觉得。
说到这里,还得再多说一个,c++的虚函数。之所以要提虚函数。是因为面向对象的特征不仅有刚刚说的封装,还有多态,多态是因为继承。我们单独说这个多态。大概是要解决这样的问题,我们设计好了某个“类”,有个类似的功能模块 大部分跟已有的这个类很像,然而有个别的行为(方法,函数)有些不同,我不想再写一遍了。想声明一下,除了某几个方法是不一样的,其余的沿用。另外我还想实现,原有类的指针可以指向自己的对象也可以指向新类的对象,通过指针去调用两个类中同名函数时,根据指针所指向的具体对象的不同,调用不同的函数(方法)。说的有点乱了(似乎跳过了继承去说多态,不太合适,我尽力吧)。认真读完上一小节的朋友,可能会说,那不是一样的么,不同的类的函数有不同的前缀,根据变量类型的不同,分别去调用呗。但是思考的深一点就会想到,变量类型是由编译器在编译的时候为我们保存的,编译完的代码中可不包括这样的信息。运行中的机器码,两个指针无非就是两个不同的长整型数据而已(长整型一般等于CPU的字长)。通过指针我们仅能获得不同对象的地址而已,普通的对象(结构体)中只保存了成员标量。如果我们能多保存一些帮助我们找到适当函数的信息就好了。实际上 前文已经提及,有了函数片段的地址(指针),就可以进行调用了。因为一个类的虚函数不止一个,所以我们想象下,有一张虚函数地址的表(也就是表,或者联想为数组),如果有了这个数组的首地址,我们就可以找到所有这些数据了。于是,在对象内存的前面,留出8(32位机器是4字节)个字节用来保存这个表地址。
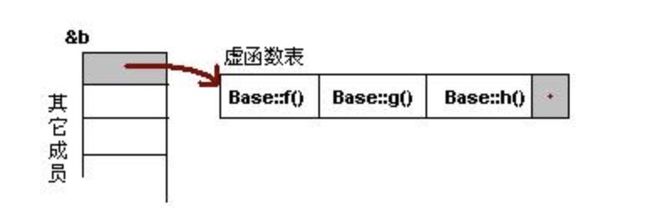
对象的内存空间大约如图这个样子,本人很难,图是网上截取的。接下来我们贴一段代码验证一下这个事实。
#include
using namespace std;
class Parent
{
public:
virtual void func1()
{
cout << "this is Parent::fun1" <func1();
Parent * p2 = new Son;
p2->func1();
/////// 多态
///////虚函数表
Son p3;
cout << "虚函数表地址:" << (long*)(&p3) << endl;
cout << "虚函数表 — 第一个函数地址:" <<(long*)*(long*)(&p3) << endl;
P_FUN pFun;
pFun = (P_FUN)*((long*)*(long*)(&p3));
pFun();
///////虚函数表
std::cout << "Hello, World!\n";
return 0;
}
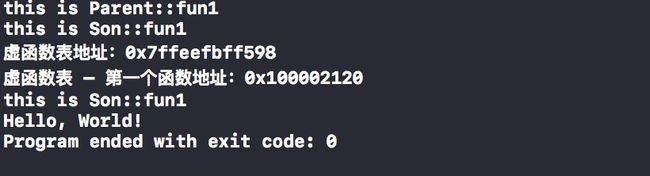
运行结果如图,当我们通过不同的指针去调用时,将会调用不同的函数,这是编译器帮我们完成的多态。接下来我们通过去除对象内存空间中前八个字节的内容,然后找到了相应的虚函数表的位置。也成功的调用了函数。
读者可自行尝试获得Son::func2的地址并调用。
没办法 本来打算一片写完的,结果吃完晚饭写到现在 才写了这么点。至于objc_runtime的多态 运行时绑定 只能下回分解了。
不要怀疑 ,文章中的所有错别字都是我故意的。