Spark 笔录
Spark
文章目录
- Spark
- 一、Spark 概述
- 二、Spark 运行模式
- 2.1 集群角色
- 1.Master 和 Worker
- 2.Driver 和 Executor
- 2.2 Local 模式
- 2.3 Spark 核心概念
- 2.4 Standalone 模式
- 2.5 Yarn 模式
- 2.6 集中运行模式对比
- 三、Spark Core
- 3.1 RDD
- 3.2 RDD 编程
- 1.RDD 创建
- 2.RDD 的 transformation 操作
- 单 Value 类型
- 1. map(func)
- 2. mapPartitions(func)
- 3. mapPartitionsWithIndex(func)
- 4. flatMap(func)
- 5. map() 和 mapPartition() 区别
- 6. glom()
- 7. groupBy(func)
- 8. filter(func)
- 9. sample(withReplacement, fraction, seed)
- 10. distinct([numTasks]))
- 11. coalesce(numPartitions, boolean)
- 12. repartition(numPartitions)
- 13. coalasce 和 repartition 区别
- 14. sortBy(func,[ascending], [numTasks])
- 15. pipe(command, [envVars])
- 双 Value 类型交互
- 1. union(otherDataset)
- 2. subtract (otherDataset)
- 3. intersection(otherDataset)
- 4. cartesian(otherDataset)
- 5. zip(otherDataset)
- Key-Value 类型
- 1. partitionBy
- 2. reduceByKey(func, [numTasks])
- 3. groupByKey()
- 4. reduceByKey 和 groupByKey 区别
- 5. aggregateByKey(zeroValue)(seqOp, combOp,[numTasks])
- 6. foldByKey
- 7. combineByKey[C]
- 8. 四个聚合算子的关系
- 9. sortByKey
- 10. mapValues
- 11. join(otherDataset, [numTasks])
- 12. cogroup(otherDataset, [numTasks])
- 3. RDD 的 action 操作
- 1. reduce(func)
- 2. collect
- 3. count()
- 4. take(n)
- 5. first
- 6. takeOrdered(n, [ordering])
- 7. aggregate
- 8. fold
- 9. countByKey()
- 10. foreach(func)
- 11. foreachPartition(func)
- 12. saveAsTextFile(path)
- 13. saveAsSequenceFile(path)
- 14. saveAsObjectFile(path)
- 4. RDD 中函数的传递
- 5. RDD 中的依赖关系
- 6. Spark 中的 Job 调度和划分
- 7. RDD 的持久化
- 8. checkpoint
- 3.3 Key-Value RDD 的分区器
- 1. 查看RDD的分区器
- 2. HashPartitioiner
- 3. RangePartitioner
- 4. 自定义分区器
- 3.4 RDD 读取和写入数据
- 1.读写 Text 文件
- 2.读取 Json 文件
- 3.读写 SequenceFile 文件
- 4.读写 objectFile 文件
- 5.从 HDFS 读写文件
- 6.从 MySQL 读写数据
- 7.从 HBase 读写文件
- 3.5 RDD 编程进阶
- 1. 共享变量问题
- 2. 累加器(Accumulator)
- 3. 广播变量
- 3.6 Spark Core 案例
- 1. 数据准备
- 2. 求 Top10 热门品类
- 3. 求 Top10 热门品类的 Top10 Session
- 4. 求各级页面跳转率
- 四、Spark SQL
- 4.1 Spark SQL概述
- 4.2 Spark SQL 编程
- 1. SparkSession
- 2. DataFrame 编程
- 3. DataSet 编程
- 3. DataSet 编程实战:分组求和
- 3. DataSet 编程实战:over() 开窗
- 3. DatSet 编程实战:拉链表制作
- 4. DataFrame 和 DataSet 转换
- 5. RDD、DataFrame、DataSet 联系
- 6. 自定义 SparkSQL 函数
- 4.3 SparkSQL 数据源
- 1. 通用读取和保存
- 2. 读取 JSON 文件
- 3. 读取 Parquet 文件
- 4. JDBC 读写
- 5. Hive 读写(Spark 集成 Hive)
- 4.4 Spark SQL 案例
- 1. 数据准备
- 2. 需求:求各区域热门商品 Top3
- 五、Spark Streaming
- 5.1 Spark Streaming 概述
- 5.2 DStream 创建
- 1. Socket 数据源
- 2. RDD 队列数据源
- 3. 自定义数据源
- 4. Kafka 数据源(常用)
- 5.3 DStream 转换
- 1. 无状态转换
- 2. 有状态转换
- updataStateByKey
- window
- 5.4 DStream 输出
- 5.5 DStream 编程进阶
- 六、Structured Streaming
- 6.1 Structured Streaming 编程模型
- 1. 基本概念
- 2. Window 和 Watermark
- 3. 容错语义
- 6.2 Structured Streaming 数据源
- 1. socket source
- 2. file source
- 3. kafka source(常用)
- 4. Rate source
- 6.3 Structured Streaming 操作
- 1. 基本操作
- 2. 基于 Event-time 的 Winodw 操作
- 3. 基于 Window 的 Watermark 处理延迟数据
- 4. 流数据去重
- 5. 流数据 Join
- 6. Structured Streaming 不支持的操作
- 6.3 Structured Streming 输出
- 1. 输出模式(output mode)
- 2. 输出管道(output sink)
- 1. FileSink
- 2. Kafka Sink(常用)
- 3. Memory Sink
- 4. Foreach Sink(常用)
- 5. ForeachBatch Sink
- 6.4 Trigger 触发器
- 1. 微批处理模式 ProcessingTime
- 2. 连续处理模式 Continuous
一、Spark 概述
Spark(http://spark.apache.org/history.html) 是一个快速(基于内存), 通用, 可扩展的集群 计算引擎
Spark 特点:快速(Spark 基于内存运算,MapReduce 的100 倍)
易用(支持 Scala、Java、Python、R 和 SQL脚本,Scala 和 Python 的 Shell 交互,80多种算子等)
通用(结合 SQL、DataFrames, 机器学习(MLlib), 图计算(GraphicX), 实时流处理(Spark Streaming) )
可融合性(YARN 和 Mesos 可作为其调度器,支持处理 HDFS, HBase 的数据)
内置模块:

**Spark Core:**实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore 中还包含了对 弹性分布式数据集 (Resilient Distributed DataSet,简称RDD)的API定义。
**Spark SQL:**是 Spark 用来操作结构化数据的程序包。我们可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
Spark Streming: Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
**Spark MLlib:**常见的机器学习 (ML) 功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
二、Spark 运行模式
2.1 集群角色
1.Master 和 Worker
**Master:**Spark 特有资源调度系统的 Leader。掌管着整个集群的资源信息,类似于 Yarn 框架中的 ResourceManager,主要功能:
- 监听 Worker,看 Worker 是否正常工作;
- Master 对 Worker、Application 等的管理(接收 Worker 的注册并管理所有的Worker,接收 Client 提交的 Application,调度等待的 Application 并向Worker 提交)。
**Worker:**Spark 特有资源调度系统的 Slave,有多个。每个 Slave 掌管着所在节点的资源信息,类似于 Yarn 框架中的 NodeManager,主要功能:
- 通过 RegisterWorker 注册到 Master;
- 定时发送心跳给 Master;
- 根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的临时进程)
2.Driver 和 Executor
Driver(驱动器):Spark 的驱动器是执行开发程序中的 main 方法的线程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果你是用Spark Shell,那么当你启动Spark shell的时候,系统后台自启了一个 Spark 驱动器程序,就是在 Spark shell 中预加载的一个叫作 sc 的SparkContext 对象。如果驱动器程序终止,那么Spark应用也就结束了。主要负责:
- 将用户程序转化为作业(Job);
- 在 Executor 之间调度任务(Task);
- 跟踪 Executor 的执行情况;
- 通过 UI 展示查询运行情况。
Executor(执行器):Spark Executor 是一个工作节点,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。主要负责:
- 负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器程序;
- 通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在 Executor 内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结:Master 和 Worker 是 Spark 的守护进程,即 Spark 在特定模式下正常运行所必须的进程。Driver 和 Executor 是临时程序,当有具体任务提交到 Spark 集群才会开启的程序。
2.2 Local 模式
Local 模式就是指的只在一台计算机上来运行 Spark,用多线程来模拟多个节点。
语法:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
-
–master 指定 master 的地址,默认为 local。表示在本机运行
-
–class 启动类名 (如 org.apache.spark.examples.SparkPi)
-
–deploy-mode 发布驱动到 worker节点(cluster 模式) 或者本地客户端 (client 模式) (default: client)
-
–conf: 任意的Spark 配置属性, 格式key=value. 如果值包含空格,可以加引号"key=value"
-
application-jar: 打包好的应用 jar,包含依赖. 这个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的 path 都包含同样的 jar
-
application-arguments: 传给 main() 方法的参数
-
–executor-memory 1G 指定每个 executor 可用内存为1G
-
–total-executor-cores 6 指定所有 executor使用的 cpu 核数为6个
-
–executor-cores 表示每个 executor 使用的 cpu 的核数
-
关于 Master URL 的说明
local 表示在本地运行;local[k] 表示在本地使用 k 个核心运行;local[*] 表示在本地使用尽可能多的核心运行;
spark://HOST:PORT 表示 standalone 模式默认的 Master 的地址,默认端口为 7077
mesos://HOST:PORT 表示 mesos 作为调度器时,mesos 的地址
yarn 表示在 yarn 上运行不用写地址,默认已经配置过了
2.3 Spark 核心概念
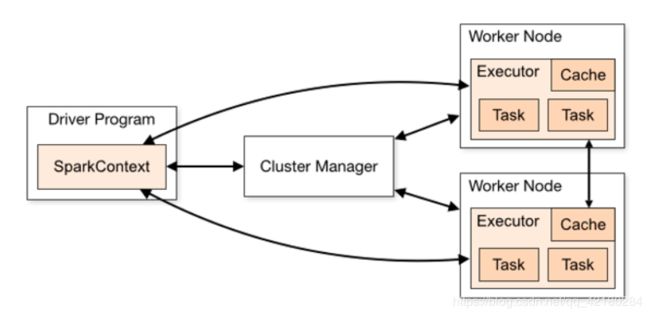
**driver program(驱动程序):**每个 Spark 应用程序都包含一个驱动程序, 驱动程序负责把并行操作发布到集群上。
**RDDs(Resilient Distributed Dataset) 弹性分布式数据集:**Spark 中的数据集。
**cluster managers(集群管理器):**SparkContext 对象需要连接到集群管理器上,例如 Yarn,Mesos 等。
**executor(执行器):**SparkContext 连接到集群管理器,就可以获取到每台节点上的 executer,名为 ExecutorBackend 的进程, 运行在 Worker 上, 用来执行计算和为应用程序存储数据。
2.4 Standalone 模式
只用 Spark 来搭建一个集群, 由 Master + Worker 构成的 Spark 集群。
-
进入配置文件目录 conf ,配置 spark-env.conf
cd conf/ cp spark-env.sh.template spark-env.sh配置内容如下
SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077 # 默认端口就是7077, 可以省略不配 -
修改 slaves 文件,添加 worker 节点
cp slaves.template slaves # 在slaves文件中配置如下内容: hadoop102 hadoop103 hadoop104 -
分发配置文件
xsync spark-standalone -
启动 Spark 集群
sbin/start-all.sh启动后 jps 可以看到 一个 Master 和 三个 Worker 进程。
如果启动报错:JAVA_HOME is not set, 在sbin/spark-config.sh中添加入JAVA_HOME变量即可。分发修改的文件
-
在网页中查看 Spark 集群情况
地址: http://hadoop102:8080
-
使用 Standalone 模式计算 PI
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077 \ --executor-memory 1G \ --total-executor-cores 6 \ --executor-cores 2 \ ./examples/jars/spark-examples_2.11-2.1.1.jar 100 -
在 Standalone 模式下启动 Spark-Shell
bin/spark-shell \ --master spark://hadoop102:7077 -
配置 Spark 任务历史服务器
cp spark-defaults.conf.template spark-defaults.conf # 在spark-defaults.conf文件中, 添加如下内容: # hdfs://hadoop102:9000/spark-job-log 目录必须提前存在, 名字随意 spark.master spark://hadoop102:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:9000/spark-job-log修改 spark-env.sh 文件,添加如下配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/spark-job-log"分发配置文件
xsync conf重启历史服务,需要先启动 HDFS
UI 地址: http://hadoop201:18080
-
为 Master 配置HA
给 spark-env.sh 添加如下配置
# 注释掉如下内容: #SPARK_MASTER_HOST=hadoop102 #SPARK_MASTER_PORT=7077 # 添加上如下内容: export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop102:2181,hadoop103:2181,hadoop104:2181 -Dspark.deploy.zookeeper.dir=/spark"分发配置文件
xsync spark-env.sh启动 zookeeper
zk.sh start启动spark全部节点
sbin/start-all.sh在另一个节点也启动 master
sbin/start-master.sh默认第一个启动的 master 的为 ACTIVE 状态,第二个启动的 master 的为 STANDBY,当 kill 掉 ACTIVE 的 master,另一个 master 会成为 ACTIVE 状态。
2.5 Yarn 模式
Spark 客户端可以直接连接 Yarn,不需要额外构建 Spark 集群。
Yarn 的两种工作模式:
yarn-client:Driver 程序运行在客户端,适用于交互、调试,希望立即看到 app 的输出。
yarn-cluster:Driver 程序运行在由 ResourceManager 启动的 AM(AplicationMaster)上,适用于生产环境。
Yarn 模式配置
-
修改 hadoop 配置文件 yarn-site.xml
<property> <name>yarn.nodemanager.pmem-check-enabledname> <value>falsevalue> property> <property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> property>分发配置文件
-
修改 spark-env.sh
去掉 master 的 HA 配置,保留日志服务的配置
# 告诉 spark 客户端 yarn 相关配置 YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop如果hadoop的core文件中配置了压缩格式,那么 spark-env.sh 中也要指定压缩格式的本地库,否则会找不到本地库
# hadoop-core.xml 中配置了 lzo,故在 spark-env.sh 中配置 lzo 的本地库变量 export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:/opt/module/hadoop-2.7.2/lib/native export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar -
日志服务
http://hadoop102:8088 页面中点击 history 无法跳转到 spark 的日志,可以在 spark-default.conf 中配置:
spark.yarn.historyServer.address=hadoop102:18080 spark.history.ui.port=18080如果在 yarn 日志端无法查看到具体的日志, 则在 yarn-site.xml 中添加如下配置
<property> <name>yarn.log.server.urlname> <value>http://hadoop102:19888/jobhistory/logsvalue> property>
2.6 集中运行模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 |
|---|---|---|---|
| Local | 1 | 无 | Spark |
| Standalone | 多台 | Master 及 Worker | Spark |
| Yarn | 1 | Yarn 及 HDFS | Hadoop |
三、Spark Core
3.1 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象。在代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
RDD 的五个属性:
- A list of partitions 多个分区,分区可以看成是数据集的基本组成单位。
- A function for computing each split 计算每个切片(分区)的函数,RDD 的计算是以分片为单位的。
- A list of dependencies on other RDDs 其他 RDD 之间的依赖关系。
- Optionally, a Partitioner for key-value RDDs 键值对的 RDD, 有一个可选的分区器。
- Optionally, a list of preferred locations to compute each split on 存储每个切片优先位置的列表。
理解 RDD:
- RDD 可以简单的理解为一个分布式的元素集合
- RDD 表示只读的分区的数据集,RDD 进行改动,只能得到新的 RDD
- 每个 RDD 被切成多个分区,每个分区可能会在不同的节点上进行计算
RDD 的特点:
-
弹性:内存与磁盘切换的存储弹性;数据丢失可恢复的容错弹性;计算出错可重试的计算弹性;根据需要重新分片的分片弹性。
-
分区:RDD 逻辑上是分区的,每个分区的数据都是抽象存在的。计算的时候通过 compute 函数得到每个分区数据。
-
只读:RDD 是只读的,通过 transfromation 转换、action 行动两种算子进行操作。
-
依赖:RDD 之间进行转换并包含与其他 RDD 之间的关系,也叫作血缘关系
窄依赖,RDD 之间分区是一一对应的;宽依赖,下游 RDD 的每一个分区与上游 RDD 分区之间是多对多的关系。
-
缓存:计算时多次使用同一个 RDD,该 RDD 会被缓存起来,只有在第一次计算时会根据血缘关系得到分区数据,在后续用到该 RDD 时,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
-
checkpoint:RDD 支持 checkpoint,在计算的某个环节中,会将数据持久化,之后的计算可以直接使用该持久化的数,无需关注之前的血缘关系。
3.2 RDD 编程
在 Spark 中,RDD 被表示为对象,通过对象上的方法调用来对 RDD 进行转换。经过一些列 transformations 后调用 action,才会执行 RDD 的计算(延迟计算)。
1.RDD 创建
RDD 的创建方式有三种:从集合中创建 RDD;从外部存储创建 RDD;从其他 RDD 转换得来。
-
从集合中创建 RDD
// 使用 parallelize 函数创建 val arr = Array(10,20,30,40,50,60) val rdd1 = sc.parallelize(arr) // 使用 madkeRDD 函数创建 val rdd1 = sc.makeRDD(Array(10,20,30,40,50,60))parallezie 和 makeRDD 还有一个重要的参数可以指定数据集的分区数,默认情况下,Spark 会根据集群配设置分区
-
从外部创建 RDD
Spark 也可以从任意 Hadoop 支持的存储数据源来创建分布式数据集,HDFS, Cassandra, HVase, Amazon S3 等。
Spark 也支持 文本文件, SequenceFiles, 和其他所有的 Hadoop InputFormat
var distFile = sc.textFile("words.txt") distFile.collectURL 可以是本地文件系统,hdfs://…,s3n://… 等等
如果使用本地文件系统的路径,则必须每个节点都要存在这个路径
textFile 中的 URL 支持压缩格式文件,* 号。同时 textFile 还有第二个参数,表示分区数,默认使用 HDFS 的块大小进行分区划分。
2.RDD 的 transformation 操作
Spark 中对 RDD 所有的 tarnsformations 都是懒执行(lazy),也就是不会立即执行,只有 action 后才开始执行。
默认情况下, 一次 action 会将前面的每个 tarnsformations 执行一遍,但是我们可以通过 persist(or cache)的方法来持久化一个 RDD 在内存或磁盘中。
单 Value 类型
1. map(func)
返回一个新的 RDD, 该 RDD 是由原 RDD 的每个元素经过函数转换后的值而组成. 就是对 RDD 中的数据做转换
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1 to 10)
val rdd2: RDD[Int] = rdd1.map(x => x * x)
println(rdd2.collect().mkString(","))
2. mapPartitions(func)
类似于map(func), 但是是独立在每个分区上运行
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1 to 10)
val rdd2: RDD[Int] = rdd1.mapPartitions(it => it.map(_ * 2))
println(rdd2.collect.mkString(","))
3. mapPartitionsWithIndex(func)
和 mapPartitions(func) 类似. 但是会给func多提供一个 Int 值来表示分区的索引
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(1 to 10)
val rdd2: RDD[(Int, Int)] = rdd1.mapPartitionsWithIndex((index, it) => it.map((index, _)))
println(rdd2.collect.mkString(","))
4. flatMap(func)
类似于map,但是每一个输入元素会返回一个序列,最后所有序列被扁平化到一个大的集合中
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9))
val rdd2: RDD[Int] = rdd1.flatMap(x => Array(x, x * x, x * x * x))
println(rdd2.collect.mkString(","))
5. map() 和 mapPartition() 区别
map():每次处理一条数据;mapPartition():每次处理一个分区的数据,这个分区的数据处理完后,原 RDD 中该分区的数据才能释放,可能导致 OOM。当内存空间较大的时候建议使用mapPartition(),以提高处理效率。
6. glom()
将每一个分区的元素合并成一个数组,形成新的 RDD 类型是RDD[Array[T]]
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9), 4)
// glom 将每一个分区的元素合并成一个数组,形成新的 RDD 类型是RDD[Array[T]]
rdd1.glom.collect.foreach(a => println(a.mkString(",")))
7. groupBy(func)
按照 func 的返回值进行分组,func 返回值作为 key,对应的值放入一个迭代器中。返回的 RDD: RDD[(K, Iterable[T]) 每组内元素的顺序不能保证,并且甚至每次调用得到的顺序也有可能不同。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9))
// 按照元素的奇偶性进行分组
val rdd2: RDD[(Boolean, Iterable[Int])] = rdd1.groupBy(x => x % 2 == 0)
rdd2.collect.foreach(println)
8. filter(func)
过滤,返回一个新的 RDD 是由 func 的返回值为 true 的那些元素组成
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9))
// 过滤. 返回一个新的 RDD 是由func的返回值为true的那些元素组成
val rdd2: RDD[Int] = rdd1.filter(x => x % 2 == 0)
rdd2.collect.foreach(println)
9. sample(withReplacement, fraction, seed)
指定的随机种子随机抽样出比例为 fraction 的数据,(抽取到的数量是: size * fraction)。需要注意的是得到的结果并不能保证准确的比例。
withReplacement 表示是抽出的数据是否放回,true 为有放回的抽样,false 为无放回的抽样。
seed 用于指定随机数生成器种子。 一般用默认的, 或者传入当前的时间戳
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9))
val rdd2: RDD[Int] = rdd1.sample(withReplacement = false, 0.2)
rdd2.collect.foreach(println)
10. distinct([numTasks]))
对 RDD 中元素执行去重操作。参数表示任务的数量.默认值和分区数保持一致。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9, 9, 9))
val rdd2: RDD[Int] = rdd1.distinct
println(rdd2.collect.mkString(","))
11. coalesce(numPartitions, boolean)
缩减分区数到指定的数量,用于大数据集过滤后,提高小数据集的执行效率。第二个参数表示是否 shuffle,如果不传或者传入的为 false,则表示不进行 shuffle,此时分区数减少有效,增加分区数无效。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9, 9, 9), 4)
val rdd2: RDD[Int] = rdd1.coalesce(2)
println(rdd2.collect.mkString(","))
12. repartition(numPartitions)
根据新的分区数,重新 shuffle 所有的数据,这个操作总会通过网络,新的分区数相比以前可以多, 也可以少。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9, 9, 9), 4)
val rdd2 = rdd1.repartition(6)
println(rdd2.getNumPartitions)
println(rdd2.collect.mkString(","))
13. coalasce 和 repartition 区别
- coalesce 重新分区,可以选择是否进行 shuffle 过程。由参数 shuffle: Boolean= false/true 决定。
- repartition 实际上是调用的 coalesce,进行 shuffle。
- 如果是减少分区, 尽量避免 shuffle。
14. sortBy(func,[ascending], [numTasks])
使用 func 先对数据进行处理,按照处理后结果排序,默认为正序。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 22, 31, 60, 14, 25, 9, 9, 9))
val rdd2: RDD[Int] = rdd1.sortBy(x => x, true)
println(rdd2.collect.mkString(","))
15. pipe(command, [envVars])
管道,针对每个分区,把 RDD 中的每个数据通过管道传递给 shell 命令或脚本,返回输出的 RDD。一个分区执行一次这个命令。如果只有一个分区, 则执行一次命令。
-
创建一个脚本文件pipe.sh
echo "hello" while read line;do echo ">>>"$line done -
创建只有 1 个分区的RDD
scala> val rdd1 = sc.parallelize(Array(10,20,30,40), 1) scala> rdd1.pipe("./pipe.sh").collect res1: Array[String] = Array(hello, >>>10, >>>20, >>>30, >>>40) -
创建有 2 个分区的 RDD
scala> val rdd1 = sc.parallelize(Array(10,20,30,40), 2) scala> rdd1.pipe("./pipe.sh").collect res2: Array[String] = Array(hello, >>>10, >>>20, hello, >>>30, >>>40)
双 Value 类型交互
1. union(otherDataset)
求并集。对源 RDD 和参数 RDD 求并集后返回一个新的 RDD,union 和 ++ 是等价的。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 25, 31, 60, 9))
val rdd2: RDD[Int] = sc.parallelize(Array(14, 25, 9, 16, 31))
val rdd3: RDD[Int] = rdd1.union(rdd2)
println(rdd3.collect.mkString(","))
2. subtract (otherDataset)
计算差集。从原 RDD 中减去 原 RDD 和 otherDataset 中的共同的部分。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 25, 31, 60, 9))
val rdd2: RDD[Int] = sc.parallelize(Array(14, 25, 9, 16, 31))
val rdd3: RDD[Int] = rdd1.subtract(rdd2)
println(rdd3.collect.mkString(","))
3. intersection(otherDataset)
计算交集。对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 25, 31, 60, 9))
val rdd2: RDD[Int] = sc.parallelize(Array(14, 25, 9, 16, 31))
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
println(rdd3.collect.mkString(","))
4. cartesian(otherDataset)
计算 2 个 RDD 的笛卡尔积。尽量避免使用
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 25, 31, 60, 9))
val rdd2: RDD[Int] = sc.parallelize(Array(14, 25, 9, 16, 31))
val rdd3: RDD[(Int, Int)] = rdd1.cartesian(rdd2)
println(rdd3.collect.mkString(","))
5. zip(otherDataset)
拉链操作。需要注意的是, 在 Spark 中, 两个 RDD 的元素的数量和分区数都必须相同,否则会抛出异常。
val conf: SparkConf = new SparkConf().setAppName("CreateRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 25, 31, 60, 9))
val rdd2: RDD[Int] = sc.parallelize(Array(14, 25, 9, 16, 31))
//两个 RDD 的元素的数量和分区数都必须相同, 否则会抛出异常.(在 scala 中, 两个集合的长度可以不同)
val rdd3: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(rdd3.collect.mkString(","))
Key-Value 类型
1. partitionBy
对 pairRDD 进行分区操作,如果原有的 partionRDD 的分区器和传入的分区器相同, 则返回原 pairRDD,否则会生成 ShuffleRDD,即会产生 shuffle 过程。
val conf: SparkConf = new SparkConf().setAppName("ParcticeRDD").setMaster("local[3]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[(Int, String)] = sc.parallelize(Array((1, "a"), (2, "b"), (3, "c"), (4, "d")))
println(rdd1.partitions.length) // 3
val rdd2: RDD[(Int, String)] = rdd1.partitionBy(new HashPartitioner(partitions = 6))
println(rdd2.partitions.length) // 6
2. reduceByKey(func, [numTasks])
对 pairRDD 进行操作,返回一个 pairRDD,使用指定的 reduce 函数,将相同 key 的 value 聚合到一起,reduce 任务的个数可以通过第二个可选的参数来设置。
val conf: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hello", "world", "hello", "atguigu", "hello", "atguigu", "atguigu"))
val wordOne: RDD[(String, Int)] = rdd1.map((_, 1))
val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_ + _, 3) // 预聚合
wordCount.collect.foreach(println)
sc.stop()
3. groupByKey()
只按照 key 进行分组,不进行聚合
val conf: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hello", "world", "hello", "atguigu", "hello", "atguigu", "atguigu"))
val rdd2: RDD[(String, Iterable[Int])] = rdd1.map((_, 1)).groupByKey // 只进行分组操作
val rdd3: RDD[(String, Int)] = rdd2.map {
case (key, valueIt) => (key, valueIt.sum)
}
rdd3.collect.foreach(println)
sc.stop()
4. reduceByKey 和 groupByKey 区别
- reduceByKey:按照 key 进行聚合,在 shuffle 之前有 combine(预聚合)操作,返回结果是RDD[k,v]。
- groupByKey:按照 key 进行分组,直接进行 shuffle,返回 RDD[k,迭代器]。
- reduceByKey 比 groupByKey 性能更好,建议使用。但是需要注意是否会影响业务逻辑。
5. aggregateByKey(zeroValue)(seqOp, combOp,[numTasks])
使用给定的 combine 函数和一个初始化的 zero value, 对每个 key 的 value 进行聚合。返回值的类型是由初始化的 zero value 来定的。seqOp 用于分区内聚合,combOp 用于分区间聚合。
// 需求:求每个分区相同 key 对应值的最大值最小值的和,(B, (maxSum, minSum))
val config: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(config)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),numSlices = 2)
val rdd2: RDD[(String, (Int, Int))] = rdd1.aggregateByKey((Int.MinValue, Int.MaxValue))(
(MaxMin, x) => (MaxMin._1.max(x), MaxMin._2.min(x)),
(MaxMin1, MaxMin2) => (MaxMin1._1 + MaxMin2._1, MaxMin2._2 + MaxMin2._2)
)
rdd2.collect.foreach(println)
sc.stop
6. foldByKey
aggregateByKey 的简化操作,当 seqop 和 combop 相同时,即为 foldByKey
val conf: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hello", "world", "hello", "atguigu", "hello", "atguigu", "atguigu"))
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
val rdd3: RDD[(String, Int)] = rdd2.foldByKey(zeroValue = 0)(_ + _)
rdd3.collect.foreach(println)
sc.stop()
7. combineByKey[C]
针对每个 K,将 V 进行合并成 C, 得到 RDD[(K,C)]。分区内和分区间聚合的逻辑可以不一样。
createCombiner: combineByKey 会遍历分区中的每个 key-value 对,如果第一次碰到这个 key,则调用 createCombiner 函数,传入 value,得到一个 C 类型的值。(如果不是第一次碰到这个 key, 则不会调用这个方法)
mergeValue: 如果不是第一个遇到这个 key, 则调用这个函数进行合并操作,分区内合并
mergeCombiners 跨分区合并相同的key的值©。跨分区合并
// 需求:根据 key 计算每种 key 的value的平均值。
val conf: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(Array(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),numSlices = 2)
val rdd3: RDD[(String, Double)] = rdd1.combineByKey(
v => (v, 1),
(sumCount: (Int, Int), v: Int) => (sumCount._1 + v, sumCount._2 + 1),
(sumCount1: (Int, Int), sumCount2:(Int, Int)) => (sumCount1._1 + sumCount2._1,sumCount1._2 + sumCount2._2 )
).mapValues(sumCount => sumCount._1.toDouble / sumCount._2)
rdd3.collect.foreach(println)
sc.stop()
8. 四个聚合算子的关系
combineByKey(
计算零值
分区内聚合 // 书写聚合函数时,后面两个函数的参数类型要指定
分区间聚合
)
aggregateByKey(zero)(f1, f2)
// 如果分区内和分区间聚合的逻辑相同,则可以使用 foldByKey做替换
foldByKey(zero)(f)
// 如果不需要零值的时候,可以使用 reduceByKey 来替换 foldByKey
reduceByKey(f)
// 这四个聚合函数底层都调用了 combineByKeyWithClassTag,区别就在于传参
9. sortByKey
在一个 (k,v) 的 RDD 上调用,K 必须实现 Ordered[K] 接口(或者有一个隐式值: Ordering[K]),返回一个按照 key 进行排序的 (k,v) 的 RDD。sortByKey 是一个全局排序,会经过 shuffle,借助于磁盘。
val conf: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[(Int, String)] = sc.parallelize(Array((1, "a"), (10, "b"), (11, "c"), (4, "d"), (20, "d"), (10, "e")))
val rdd2: RDD[(Int, String)] = rdd.sortByKey(ascending = false)
rdd2.collect.foreach(println)
sc.stop()
10. mapValues
针对 (k,v) 形式的数据类型只对每一个 v 进行操作
11. join(otherDataset, [numTasks])
在类型为 (k,v) 和 (k,w) 的 RDD 上调用,返回一个相同 key 对应的所有元素对在一起的 (k,(v,w)) 的 RDD
常用的连接有3种:join / leftOuterJoin / fullOuterJoin
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc = new SparkContext(conf)
var rdd1 = sc.parallelize(Array((1, "a"), (1, "b"), (2, "c"), (4, "xx")))
val rdd2 = sc.parallelize(Array((1, "aa"), (3, "bb"), (2, "cc"), (2, "dd")))
// 内连接
// val rdd3: RDD[(Int, (String, String))] = rdd1.join(rdd2)
// 左外
// val rdd3 = rdd1.leftOuterJoin(rdd2)
// val rdd3 = rdd1.rightOuterJoin(rdd2)
// 全连接
val rdd3 = rdd1.fullOuterJoin(rdd2)
rdd3.collect.foreach(println)
sc.stop()
12. cogroup(otherDataset, [numTasks])
在类型为 (k,v) 和 (k,w) 的 RDD 上调用,返回一个 (K,(Iterable,Iterable)) 类型的 RDD
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc = new SparkContext(conf)
var rdd1 = sc.parallelize(Array((1, "a"), (1, "b"), (2, "c"), (4, "xx")))
val rdd2 = sc.parallelize(Array((1, "aa"), (3, "bb"), (2, "cc"), (2, "dd")))
var rdd3 = rdd1.cogroup(rdd2)
rdd3.collect.foreach(println)
sc.stop()
3. RDD 的 action 操作
1. reduce(func)
通过func函数聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据。
val config: SparkConf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc: SparkContext = new SparkContext(config)
val rdd1: RDD[String] = sc.parallelize(Array("hello", "hello", "world", "hello", "atguigu", "hello", "atguigu", "atguigu"))
println(rdd1.reduce(_ + _))
sc.stop
2. collect
以数组的形式返回 RDD 中的所有元素,所有的数据都会被拉到 driver 端,所以要慎用
3. count()
返回 RDD 中的元素的个数
4. take(n)
返回 RDD 中前 n 个元素组成的数组
5. first
返回 RDD 中的第一个元素,类似于 tabke(1)
6. takeOrdered(n, [ordering])
返回排序后的前 n 个元素,默认是升序排列,数据也会拉到 driver 端
7. aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
aggregate 函数将每个分区里面的元素通过 seqOp 和初始值进行聚合,然后用 combine 函数将每个分区的结果和初始值 (zeroValue) 进行 combine 操作。这个函数最终返回的类型不需要和 RDD 中元素类型一致。
注意:zeroValue 在分区内和分区间聚合的时候各会使用一次,总使用次数为 分区数+1
8. fold
折叠操作,aggregate 的简化操作,seqop 和 combop 一样的时候,可以使用 fold
9. countByKey()
针对 (k,v) 类型的 RDD,返回一个 (k,Int) 的 map,表示每一个 key 对应的元素个数。可以查看数据是否倾斜。
10. foreach(func)
针对 RDD 中的每个元素都执行一次 func,每个函数是在 Executor 上执行的, 不是在 driver 端执行的
11. foreachPartition(func)
针对 RDD 中的每个分区的每个元素都执行一次 func,函数在 Executor 上执行的,多用于和外界交互。
12. saveAsTextFile(path)
将数据集的元素以 textFile 的形式保存到 HDFS 或者其他文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本。
13. saveAsSequenceFile(path)
将数据集中的元素以 Hadoop sequenceFile 的格式保存到指定的目录下,可以使用 HDFS 或者其他支持文件系统。
14. saveAsObjectFile(path)
用于 将 RDD 中的元素序列化成对象,存储到文件中。
4. RDD 中函数的传递
在 RDD 调用算子中,传递一个类的函数或者属性时,都需要这个类继承序列化接口:Serializable。
传递函数中自定义的局部变量无需序列化。
Spark的序列化:
Spark 对于性能的考虑,支持一种序列化机制: kryo (2.0开始支持)。kryo 比较快和简洁。
// 在SparkConf中配置序列化框架
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher]))
即使使用 kryo 序列化,RDD 传入函数或属性的类也要继承 Serializable 接口
5. RDD 中的依赖关系
-
查看 RDD 的血缘关系
scala> rdd4.toDebugString res4: String = (2) ShuffledRDD[4] at reduceByKey at:30 [] +-(2) MapPartitionsRDD[3] at map at :28 [] | MapPartitionsRDD[2] at flatMap at :26 [] | ./words.txt MapPartitionsRDD[1] at textFile at :24 [] | ./words.txt HadoopRDD[0] at textFile at :24 [] // 圆括号中的数字表示 RDD 的并行度,也就是有几个分区 -
查看 RDD 的依赖关系
scala> rdd3.dependencies res30: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@4776f6af) scala> rdd4.dependencies res31: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@4809035f)RDD 之间的关系可以从两个维度来理解:一个是 RDD 是从哪些 RDD 转换而来, 也就是 RDD 的 parent RDD(s)是什么;另一个就是 RDD 依赖于 parent RDD(s)的哪些 Partition(s)。这种关系就是 RDD 之间的依赖。
-
窄依赖
父 RDD 的每个分区最多被一个 RDD 的分区使用

窄依赖的时候,子 RDD 中的分区要么只依赖一个父 RDD 中的一个分区(比如map, filter操作),要么在设计时候就能确定子 RDD 是父 RDD 的一个子集(比如: coalesce)。
-
宽依赖
父 RDD 的分区被不止一个子 RDD 的分区依赖,就是宽依赖

在排序 (sort) 的时候,数据必须被分区,同样范围的 key 必须在同一个分区内。具有宽依赖的 transformations 包括:sort, reduceByKey, groupByKey, join, 和调用 rePartition函数的任何操作。
6. Spark 中的 Job 调度和划分
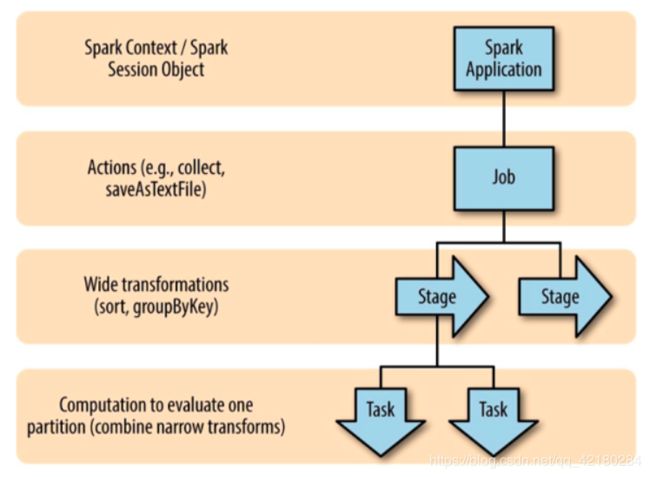
**application:**一个 Spark 应用,启动一个 SparkContext 的时候,就开启了一个 Spark 应用。
**job:**一个 Spark 应用中会有多个 job,每调用一个 action 算子,就会启动一个 job,每个 job 由多个 stages 组成。
**stage:**阶段,每经过一个 shuffle 算子(宽依赖),就会开启一个 stage,阶段内部的算子并行,阶段之间是串行的,每个 stage 由多个 tasks 来组成,每个 stage 的所有 task 在下一个 stage 开启之前必须全部完成。stage 的执行顺序时从前往后,但是 Spark 对 stage 的推导顺序是从后往前。
**task:**task 是最小的执行单位。每个 stage 的 task 的数量对应着分区的数量,即每个 Partition 都被分配一个 Task,每一个 task 表现为一个本地计算。
DAG (Directed Acyclic Graph) 有向无环图:Spark 的顶层调度为每个 job 创建一个由 task 组成的 DAG。
7. RDD 的持久化
每调用一次 collect,会创建一个新的 job,每个 job 总是从它血缘的起始开始计算。中间的计算过程都会重复执行。
Spark 这样做的原因是因为 RDD 记录了整个计算过程。如果计算的过程中出现哪个分区的数据损坏或丢失,则可以从头开始计算来达到容错的目的。
然而 Spark 也提供了另一个重要的功能,持久化数据集在内存中,其他的 action 可以重用这些数据,将来的 action 计算起来更快,对于迭代算法和快速交互式查询来说,缓存(Caching)是一个关键的工具。
可以使用方法 persist() 或者 cache() 来持久化一个 RDD。第一个 action 算子会计算这个 RDD,然后把结果的存储到它的节点的内存中。
**容错:**Spark 的 Cache 有容错能力,如果 RDD 的任何一个分区的数据丢失了, Spark 会自动的重新计算。RDD 的各个 Partition 是相对独立的,因此只需要计算丢失部分的即可,并不需要重算全部 Partition。
**存储级别:**persist() 可以设定存储级别。cache() 使用默认存储级别(StorageLevel.MEMORY_ONLY)
rdd.persist ( newLevel: StorageLevel ) 中可以传入存储级别 StorageLevel
new StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication)
// StorageLevel 有五个属性(磁盘、内存、堆外内存、序列化、备份数)来控制存储级别。
// StorageLevel 的常见对象
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true) // 最常使用:进内存存储
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
Spark 也会自动对一些 shuffle 操作的中间数据做持久化操作 (比如: reduceByKey)。这样做的目的是为了当一个节点 shuffle 失败了避免全部重新计算。
8. checkpoint
RDD 的 Lineage 过长会造成容错成本过高,检查点通过将数据写入到 HDFS 文件系统实现了 RDD 的 checkpoint。
rdd.checkpoint ( ):该函数将会创建一个二进制的文件,并存储到 checkpoint 目录中,该目录在SparkContext.setCheckpointDir() 中设置。checkpoint 会对这个 RDD 进行再次计算,并保存结果到磁盘,并将该 RDD 的血缘关系切断。
- cache:使用已经计算好的结果直接做缓存,仍然保留着 RDD 的血缘关系
- checkpoint:重新启动一个新的 job 来做 chekpoint,保存结果到磁盘,会切断 RDD 的血缘关系
- 在使用时,为了 避免 checkpoint 重新计算,会在 chekpoint 前使用 cache,chekpoint 新开启的 job 就会使用 cache 的结果,不会重新计算。
3.3 Key-Value RDD 的分区器
1. 查看RDD的分区器
-
value 的分区器
scala> val rdd1 = sc.parallelize(Array(10)) scala> rdd1.partitioner res8: Option[org.apache.spark.Partitioner] = None -
key-value 的分区器
import org.apache.spark.HashPartitioner scala> val rdd1 = sc.parallelize(Array(("hello", 1), ("world", 1))) scala> rdd1.partitioner res11: Option[org.apache.spark.Partitioner] = None // 导入分区器,进行分区 import org.apache.spark.HashPartitioner scala> val rdd2 = rdd1.partitionBy(new HashPartitioner(3)) scala> rdd2.partitioner res14: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
2. HashPartitioiner
HashPartitioner 分区的原理:对于给定的 key,计算其 hashCode(hashCode可能为负值),并对分区的个数取余,如果余数小于 0,则用余数+分区的个数(否则加0),最后返回的值就是这个 key 所属的分区 ID。
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array((10, "a"), (20, "b"), (30, "c"), (40, "d"), (50, "e"), (60, "f")))
// 把分区号取出来, 检查元素的分区情况
val rdd2: RDD[(Int, String)] = rdd1.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2)))
println(rdd2.collect.mkString(","))
// 把 RDD1使用 HashPartitioner重新分区
val rdd3 = rdd1.partitionBy(new HashPartitioner(5))
// 检测RDD3的分区情况
val rdd4: RDD[(Int, String)] = rdd3.mapPartitionsWithIndex((index, it) => it.map(x => (index, x._1 + " : " + x._2)))
println(rdd4.collect.mkString(","))
}
}
3. RangePartitioner
HashPartitioner 的弊端: 可能导致每个分区中数据量的不均匀,比如会使所有 0 值进入同一个分区。
RangePartitioner 作用:根据水塘抽样算法获取多个分区的界限,将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序。
比如,根据水塘抽样获得一个分区界限[1,100,200,300,400],然后对比传进来的 key 在哪个区间内,并返回分区号。
4. 自定义分区器
自定义分区器要 继承 org.apache.spark.Partitioner,并实现如下方法
1. numPartitions // 该方法返回分区数,必须要大于0
2. getPartition(key) // 返回指定key的分区号(从 0 到 numPartitions-1)
3. equals // Spark 通过这个方法检查自定义分区器和其他分区器是否相同,进而可以判断两个RDD的分区方式是否相同
4. hashCode // 如果覆写了 equals,则也应该覆写这个方法
3.4 RDD 读取和写入数据
1.读写 Text 文件
// 读取本地文件
val rdd1 = sc.textFile("./words.txt")
val rdd2 = rdd1.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ +_)
// 保存数据到 hdfs 上.
scala> rdd2.saveAsTextFile("hdfs://hadoop201:9000/words_output")
2.读取 Json 文件
RDD 读取 JSON 文件处理很复杂,SparkSQL 很好的处理 JSON 文件,实际应用是采用 SparkSQL 处理 JSON 文件。
// 读取 json 数据的文件, 每行是一个 json 对象
scala> val rdd1 = sc.textFile("/opt/module/spark-local/examples/src/main/resources/people.json")
// 导入 scala 提供的可以解析 json 的工具类
scala> import scala.util.parsing.json.JSON
import scala.util.parsing.json.JSON
// 使用 map 来解析 Json, 需要传入 JSON.parseFull
scala> val rdd2 = rdd1.map(JSON.parseFull)
// 解析到的结果其实就是 Option 组成的数组, Option 存储的就是 Map 对象
scala> rdd2.collect
3.读写 SequenceFile 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(Flat File)。
SparkContext 中可以调用 sequenceFile,SequenceFile 文件只针对 PairRDD
// 写入 SequenceFile 文件
scala> val rdd1 = sc.parallelize(Array(("a", 1),("b", 2),("c", 3)))
scala> rdd1.saveAsSequenceFile("hdfs://hadoop201:9000/seqFiles")
// 读取 SequenceFile 文件
scala> val rdd1 = sc.sequenceFile[String, Int]("hdfs://hadoop201:9000/seqFiles")
scala> rdd1.collect
注意: 需要指定泛型的类型 sc.sequenceFile[String, Int]
4.读写 objectFile 文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。
// 写入 objectFile 文件
scala> val rdd1 = sc.parallelize(Array(("a", 1),("b", 2),("c", 3)))
scala> rdd1.saveAsObjectFile("hdfs://hadoop201:9000/obj_file")
// 读取 objectFile 文件
scala> val rdd1 = sc.objectFile[(String, Int)]("hdfs://hadoop201:9000/obj_file")
scala> rdd1.collect
5.从 HDFS 读写文件
HadoopRDD 和 newHadoopRDD 是针对于 Hadoop 不同版本的两个新旧 API,多数情况下使用新 API,其中包含四个参数:
输入格式(InputFormat):指定数据输入的类型
键类型:指定[K,V]键值对中K的类型
值类型:指定[K,V]键值对中V的类型
分区值:指定由外部存储生成的 RDD 的 partition 数量的最小值
在 Hadoop 中以压缩形式存储的数据,不需要指定解压方式就能够进行读取,因为 Hadoop 本身有一个解压器会根据压缩文件的后缀推断解压算法进行解压。
如果用 Spark 从 Hadoop 中读取某种类型的数据不知道怎么读取的时候,上网查找一个使用 map-reduce 的时候是怎么读取这种这种数据的,然后再将对应的读取方式改写成上面的 hadoopRDD 和 newAPIHadoopRDD 两个类就行了。
6.从 MySQL 读写数据
-
引入 pom.xml 依赖
<dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <version>5.1.27version> dependency> -
从 MySQL 读取数据
import java.sql.DriverManager import org.apache.spark.rdd.JdbcRDD import org.apache.spark.{SparkConf, SparkContext} object JDBCDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) //定义连接 mysql 的参数 val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop102:3306/rdd" val userName = "root" val passWd = "maben996" val rdd = new JdbcRDD( sc, () => { Class.forName(driver) DriverManager.getConnection(url, userName, passWd) }, "select id, name from user where id >= ? and id <= ?", 1, 20, 2, result => (result.getInt(1), result.getString(2)) ) rdd.collect.foreach(println) } } -
向 MySQL 写入数据
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import java.sql.{Connection, DriverManager, PreparedStatement} object JDBCDemo2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) //定义连接mysql的参数 val driver = "com.mysql.jdbc.Driver" val url = "jdbc:mysql://hadoop102:3306/rdd" val userName = "root" val passWd = "maben996" val rdd: RDD[(Int, String)] = sc.parallelize(Array((110, "police"), (119, "fire"))) // 对每个分区执行 参数函数 val sql = "insert into user values(?, ?)" rdd.foreachPartition(it => { Class.forName(driver) val conn: Connection = DriverManager.getConnection(url, userName, passWd) it.foreach(x => { val statement: PreparedStatement = conn.prepareStatement(sql) statement.setInt(1, x._1) statement.setString(2, x._2) statement.executeUpdate() }) }) } }
7.从 HBase 读写文件
由于 org.apache.hadoop.hbase.mapreduce.TableInputForamt 类的实现,Spark 可以通过 Hadoop 输入格式访问 HBase。
这个输入格式会 返回键值对 数据,其中 键的类型 为 org.apache.hadoop.hbase.io.ImmutableBytesWritable,而 值的类型为 org.apache.hadoop.hbase.clent.Result。
-
引入 pom.xml 依赖
<dependency> <groupId>org.apache.hbasegroupId> <artifactId>hbase-serverartifactId> <version>1.3.1version> dependency> <dependency> <groupId>org.apache.hbasegroupId> <artifactId>hbase-clientartifactId> <version>1.3.1version> dependency> -
从 HBase 读取数据
import org.apache.hadoop.conf.Configuration import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object HBaseDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) // hbase 配置文件 val hbaseConf: Configuration = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104") hbaseConf.set(TableInputFormat.INPUT_TABLE, "student") // 设置输入格式、表名 val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD( hbaseConf, // 配置文件 classOf[TableInputFormat], // 输入格式 classOf[ImmutableBytesWritable], // 键类型 classOf[Result] // 值类型 ) val rdd2: RDD[String] = rdd.map { case (key, result) => Bytes.toString(result.getRow) // 接收返回的键值对 val cells = result.listCells() // 导包,其中包含隐式函数,内置了 java 和 scala 集合互转的方法 import scala.collection.JavaConversions._ for (cell <- cells ){ println(Bytes.toString(CellUtil.cloneQualifier(cell))) } } rdd2.collect sc.stop() } } -
向 HBase 写数据
import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.mapreduce.Job import org.apache.spark.{SparkConf, SparkContext} object HBaseDemo2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Practice").setMaster("local[2]") val sc = new SparkContext(conf) val hbaseConf = HBaseConfiguration.create() hbaseConf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104") hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "student") // 设置输出格式、表名 // 通过 job 来设置输出的格式的类 val job = Job.getInstance(hbaseConf) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Put]) val initialRDD = sc.parallelize(List(("100", "apple", "11"), ("200", "banana", "12"), ("300", "pear", "13"))) val hbaseRDD = initialRDD.map(x => { val rowkey = new ImmutableBytesWritable() // 封装 rowkey val put = new Put(Bytes.toBytes(x._1)) put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(x._2)) put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("weight"), Bytes.toBytes(x._3)) (rowkey, put) }) hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration) // 指定输出格式 sc.stop } }
3.5 RDD 编程进阶
1. 共享变量问题
正常情况下,传递给 Spark 算子的函数都是在远程的集群节点上执行,函数中用到的所有变量都是独立拷贝的变量。这些变量被拷贝到集群上的每个节点上,在其他节点上对变量的操作不会传递回驱动程序。
支持跨 task 之间共享变量通常是低效的,但是 Spark 对共享变量也提供了两种支持:1. 累加器 2. 广播变量
累加器主要用于共享变量写的问题
广播变量主要用于共享变量读的问题
2. 累加器(Accumulator)
累加器是一种变量,仅仅支持“add”,支持并发。累加器用于实现计数器或者求和。Spark 内部支持数字类型的累加器,开发者可以自行添加其他类型的支持。
-
内置累加器
// 记录文件中的空行 object Accumulator { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("practice").setMaster("local[2]") val sc = new SparkContext(conf) val rdd = sc.textFile("d://words.txt") // 在驱动程序中通过 sc.longAccumulator 的方式获得Long类型的累加器,还有一个Double类型的累加器 val emptyLineCount: LongAccumulator = sc.longAccumulator rdd.foreach(s => if (s.trim.length == 0) emptyLineCount.add(1)) // 通过 add 来添加值 // 通过 value 来访问累加器中的值 println(emptyLineCount.value) } }累加器的更新操作最好放在 action 中,Spark 可以保证每个 task 只执行一次。如果放在 transformations 操作中则不能保证只更新一次,有可能会被重复执行。建议在行动算子 foreach 中执行,如果非要在转换算子中使用累加器,建议给该 RDD 做一个 cache 和 checkpoint,防止重复运算。
-
定义累加器
通过继承类 AccumulatorV2 来自定义累加器。
累加器可以用于在程序运行过程中收集一些文本类信息,最终以 List[String] 的形式返回。
class MyAcc extends AccumulatorV2[String, util.List[String]] { private val _list: java.util.List[String] = Collections.synchronizedList(new util.ArrayList[String]()) // 判断零值 override def isZero: Boolean = _list.isEmpty // 复制累加器到 execute override def copy(): AccumulatorV2[String, util.List[String]] = { val newAcc = new MyAcc _list.synchronized { newAcc._list.addAll(_list) // 复制当前缓存的值 } newAcc } // 重置累加器 override def reset(): Unit = _list.clear() // 核心功能:累加 override def add(v: String): Unit = _list.add(v) // 合并:合并累加器 override def merge(other: AccumulatorV2[String, util.List[String]]) = other match { case o: MyAcc => _list.addAll(o.value) // 模式匹配,当 other 是 MyAcc 类型时,与 this 的值合并 case _ => throw new UnsupportedOperationException(s"Cannot merge ${this.getClass.getName} with ${other.getClass.getName}") } // 返回最终的累加后的值 override def value: util.List[String] = util.Collections.unmodifiableList(new util.ArrayList[String](_list)) }测试,在使用自定义累加器时,要进行注册
object MyAccumulator { def main(args: Array[String]): Unit = { val pattern = """^\d+$""" val conf = new SparkConf().setAppName("practice").setMaster("local[2]") val sc = new SparkContext(conf) val rdd = sc.parallelize(Array("abc", "a30b", "aaabb2", "60", "20")) val acc = new MyAcc sc.register(acc) // 向sc注册累加器,否则会报 Task not serializable val rdd1 = rdd.filter(x => { val flag: Boolean = x.matches(pattern) if (!flag) acc.add(x) flag }).map(_.toInt) println(rdd1.reduce(_ + _)) println(acc.value) } } -----------输出 80 [abc, a30b, aaabb2]
3. 广播变量
当一个节点上有多个 task,每个 task 都需要某个变量,那么可以在这个节点上做一个广播变量,让每个 task 读取。
广播变量在每个节点上保存一个只读变量的缓存,而不用给每个 task 传送一个 copy。
广播变量通过调用 SparkContext.broadcast(v) 来创建。广播变量是对 v 的包装,通过调用广播变量的 value 方法可以访问。
// 发送广播变量:发送到 execute 上
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
// 读取广播变量
scala> broadcastVar.value
/*
对一个 T 类型的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。
任何可序列化的类型都可以这么实现。
通过 value 属性访问该对象的值(在Java中为value()方法)。
变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
*/
总结:累加器解决了 task 之间共享变量的写的问题,广播变量解决了 task 之间共享变量的读的问题。
3.6 Spark Core 案例
1. 数据准备
采集自电商的用户行为数据,主要包含用户的 4 种行为: 搜索, 点击, 下单和支付。数据格式如下

数据说明:
数据字段采用 _ 分隔
每行表示用户的一个行为,所以每一行只能是四种行为的一种
如果搜索关键字为 “null”,代表本次行为不是搜索
如果点击的品类id和产品id是 -1,表示本次行为不是点击
单行为来说一次可以下单多个产品, 所以品类 id 和产品 id 都是多个, id 之间使用逗号分割。如果本次不是下单行为, 则他们相关数据用 “null“ 来表示。
支付行为和下单行为类似
2. 求 Top10 热门品类
按照每个品类的 点击、下单、支付 的量来统计热门品类。
思路:
遍历全部日志数据, 根据品类 id 和操作类型分别累加. 需要用到自定义累加器
当碰到订单和支付行为的时候注意拆分字段才能得到品类 id
遍历完成之后就得到每个品类 id 和操作类型的数量
按照点击、下单、支付的数量排序
取出 Top 10

-
用来封装用户行为的样例类
/** * 用户访问动作表 * * @param date 用户点击行为的日期 * @param user_id 用户的ID * @param session_id Session的ID * @param page_id 某个页面的ID * @param action_time 动作的时间点 * @param search_keyword 用户搜索的关键词 * @param click_category_id 某一个商品品类的ID * @param click_product_id 某一个商品的ID * @param order_category_ids 一次订单中所有品类的ID集合 * @param order_product_ids 一次订单中所有商品的ID集合 * @param pay_category_ids 一次支付中所有品类的ID集合 * @param pay_product_ids 一次支付中所有商品的ID集合 * @param city_id 城市 id */ case class UserVisitAction(date: String, user_id: Long, session_id: String, page_id: Long, action_time: String, search_keyword: String, click_category_id: Long, click_product_id: Long, order_category_ids: String, order_product_ids: String, pay_category_ids: String, pay_product_ids: String, city_id: Long) case class CategoryCountInfo(categoryId: String, clickCount: Long, orderCount: Long, payCount: Long) -
自定义累加器
需要统计每个品类的点击量,下单量和支付量,在累加器中使用 map 来存储数据
Map((cid, “click”) -> 100, (cid, “order”) -> 50, …))
class CategoryAcc extends AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]] { // 初始化一个 map,map((cid,"click"), count) val map: mutable.Map[(String, String), Long] = mutable.Map[(String, String), Long]() // 判断初始化是否成功 override def isZero: Boolean = map.isEmpty // 拷贝累加器到其他 task override def copy(): AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]] = { val acc: CategoryAcc = new CategoryAcc map.synchronized { acc.map ++= map } acc } // 清空累加器 override def reset(): Unit = map.clear // 执行累加操作 override def add(v: UserVisitAction): Unit = { if (v.click_category_id != -1) { // 判断是否为点击行为 map += (v.click_category_id.toString, "click") -> (map.getOrElse((v.click_category_id.toString, "click"), 0L) + 1) // 存入点击行为元素 } else if (v.order_category_ids != "null") { // 判断是否为下单行为 val orderIds = v.order_category_ids.split(",") orderIds.foreach(orderId => { // 遍历并存入下单行为元素 map += (orderId, "order") -> (map.getOrElse((orderId, "order"), 0L) + 1) }) } else if (v.pay_category_ids != "null") { // 判断是否为支付行为 val payIds = v.pay_category_ids.split(",") payIds.foreach(payId => { // 遍历并存入支付行为元素 map += (payId, "pay") -> (map.getOrElse((payId, "pay"), 0L) + 1) }) } } override def merge(other: AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]]): Unit = { val o = other.asInstanceOf[CategoryAcc] // 强转累加器 o.map.foreach { // 合并累加器中的元素 case (cidAction, count) => this.map += cidAction -> (this.map.getOrElse(cidAction, 0L) + count) } } override def value: mutable.Map[(String, String), Long] = map // 返回 map } -
外部入口
object ProjectApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("ProjectApp").setMaster("local[2]") val sc = new SparkContext(conf) // 读取文件 val lineRDD = sc.textFile("D:\\atguigu\\25_Spark\\user_visit_action.txt") // 封装成 UserVisitActionRDD val userVisitActionRDD: RDD[UserVisitAction] = lineRDD.map(line => { val splits = line.split("_") UserVisitAction( splits(0), splits(1).toLong, splits(2), splits(3).toLong, splits(4), splits(5), splits(6).toLong, splits(7).toLong, splits(8), splits(9), splits(10), splits(11), splits(12).toLong ) }) // 需求1:top10 的热门品类 val categoryTop10: List[CategoryCountInfo] = CategoryTop10App.statCategoryTop10(sc, userVisitActionRDD) categoryTop10.foreach(println) sc.stop } } -
求 Top10 热门品类的具体实现
object CategoryTop10App { def statCategoryTop10(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction]) = { val acc: CategoryAcc = new CategoryAcc sc.register(acc) userVisitActionRDD.foreach(action => { // 调用累加器处理 acc.add(action) }) // 按获取累加结果并按照Cid分组 val actionGroupByCid: Map[String, mutable.Map[(String, String), Long]] = acc.value.groupBy(_._1._1) // 封装成 CategoryCountInfo 对象的List val CategoryCountInfoList: List[CategoryCountInfo] = actionGroupByCid.map { case (cid, map) => { CategoryCountInfo( cid, map.getOrElse((cid, "click"), 0L), map.getOrElse((cid, "order"), 0L), map.getOrElse((cid, "pay"), 0L)) } }.toList // 排序 val categoryTop10: List[CategoryCountInfo] = CategoryCountInfoList.sortBy(categoryCountInfo => (-categoryCountInfo.clickCount, -categoryCountInfo.orderCount, -categoryCountInfo.payCount)) .take(10) categoryTop10 } }结果:category,click_count,order_count,pay_count

3. 求 Top10 热门品类的 Top10 Session
对于排名前 10 的品类,分别获取每个品类点击次数排名前 10 的 sessionId。
该功能,可以让体现出,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的 session 的行为。
// 思路1
1. 需要用到需求1的 category Top10 的结果
2. 过滤留下 Top10 的 categoryId 和 sessionId
3. map 转换结果为 RDD[(categoryId, sessionId), 1]
4. reduceByKey => RDD[(categoryId, sessionId), count]
5. map => RDD[categoryId, (sessionId, count)]
6. groupBy => RDD[categoryId, Iterable[(sessionId, count)]]
// toList 会将数据全部拉取到内存,容易造成OOM
7. 对每个 Iterable[(sessionId, count)].toList 进行排序,取前10
8. map => 把数据封装到 RDD[CategorySession] // CategorySession(cId.toString, sessionId, count)
9. 返回 RDD[CategorySession],即为 Top10 每个 cid 的 top10 session
// 思路2:优化
1. 需要用到需求1的 category Top10 的结果
2. 过滤留下 Top10 的 categoryId 和 sessionId
3. map 转换结果为 RDD[(categoryId, sessionId), 1]
4. reduceByKey => RDD[(categoryId, sessionId), count] // 使用定义分区器,按cid分区
5. map => 把数据封装到 RDD[CategorySession] // CategorySession(cId.toString, sessionId, count)
6. CategorySession类 继承 Ordered 实现 campare()
// 每个分区内使用 mapPartitions、TreeSet 处理,获取 Top10
7. mapPartitions => 内部定义 TreeSet,遍历迭代器,添加 categorySession 对象到 TreeSet
取前10,重新封装到 TreeSet,再 toIterator 以迭代器形式返回
8. 返回 RDD[CategorySession],即为 Top10 每个 cid 的 top10 session
-
求 Top10 热门品类的 Top10 Session 的具体实现
object SessionTop10OfCategoryTop10 { def statSessionTop10(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], categoryTop10: List[CategoryCountInfo]) = { val categoryTop10List: List[String] = categoryTop10.map(_.categoryId) val categorySessionRDD = userVisitActionRDD .filter(action => categoryTop10List.contains(action.click_category_id.toString)) // cid Top10 的数据 .map(action => ((action.click_category_id, action.session_id), 1)) // RDD[(categoryId, sessionId), 1] .reduceByKey(new CategoryIdPartitioner(categoryTop10List), _ + _) // 传入自定义分区,按cid分区 RDD[(categoryId, sessionId), count] .map { // 将 RDD[(categoryId, sessionId), count] 封装到样例类 CategorySession 中 case ((cId, sessionId), count) => CategorySession(cId.toString, sessionId, count) } // 使用 mapPartitions 以迭代器的方式处理 categorySessionRDD 的每个分区(每个cid) val resultRDD: RDD[CategorySession] = categorySessionRDD.mapPartitions(it => { // 使用 TreeSet 存储 categorySession 对象(继承 ordered 实现 compare) var treeSet: mutable.Set[CategorySession] = new mutable.TreeSet[CategorySession]() it.foreach(categorySession => { // 遍历后取前10个 treeSet += categorySession if (treeSet.size > 10) { treeSet = treeSet.take(10) } }) treeSet.toIterator // 重新封装,再以迭代器形式返回 }) resultRDD } } -
自定义比较器 CategoryIdPartitioner
class CategoryIdPartitioner(categoryTop10List: List[String]) extends Partitioner { // 将top10的商品cid和索引做成一个map,用cid获取索引,即返回分区号 private val cidIndex = categoryTop10List.zipWithIndex.toMap override def numPartitions: Int = categoryTop10List.length override def getPartition(key: Any): Int = { key match { // 接收算子的key,即cid,根据cidIndex返回cid的索引号为分区号 case (cid: Long, _) => cidIndex(cid.toString) } } } -
添加样例类 CategorySession
case class CategorySession(categoryId: String, sessionId: String, clickCount: Long) extends Ordered[CategorySession] { override def compare(that: CategorySession): Int = { // 注:若返回0则相等,导致TreeSet插入失败 // 降序 if (that.clickCount >= this.clickCount) 1 else -1 }
总结:
- 迭代器中的数据转换成 List 之后再进行排序,存在 OOM 的可能。
- RDD 排序可以避免内存溢出风险,因为 RDD 的排序需要 shuffle,是采用了内存+磁盘来完成的排序。
- 但是 RDD 排序是对所有的数据整体排序,所以一次只能针对一个 CategoryId 进行排序操作。
- 把同一个品类数据放入同一个分区,在分区内进行排序,要用到自定义分区器。
4. 求各级页面跳转率
单页面跳转率:用户在一次 Session 中一共访问了 3,5,7,8,9 这5个页面。
3 -> 5 单页面跳转率 = 符合条件的 Session 访问3页面的次数 / 符合条件的 Session 访问了3之后紧接着访问5的次数
要注意的是页面在访问时有先后顺序,做好排序。
思路:
1. 读取到要计算的目标页面,例如:1,2,3,4,5,6,7
2. 统计出来目标页面的访问次数
3. 计算页面跳转流:1->2, 2->3, 3->4, 4->5, 5->6, 6->7
4. 按照 Session 统计页面的跳转次数,并按 action_time 排序
5. 获取分组内的page_id,内制作跳转流
6. 过滤出和统计目标一致的跳转流
7. 统计每个跳转流的次数
8. 目标页面访问次数 / 页面跳转流次数 = 该页面的跳转率

object PageConversionApp {
def calcPageConversion(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], pages: String) = {
//1. 得到目标跳转流
val splits: Array[String] = pages.split(",")
val prePages: Array[String] = splits.slice(0, splits.length - 1) // slice函数左闭右开
val postPages: Array[String] = splits.slice(1, splits.length)
val pageFlow: Array[String] = prePages.zip(postPages).map {
case (pre, post) => pre + "->" + post
}
// 添加广播变量
val broadcastVar: Broadcast[Array[String]] = sc.broadcast(pageFlow)
//2. 计算每个目标页面的点击量
val targetPageCount: collection.Map[Long, Long] = userVisitActionRDD
// 过滤出 page_id = 1,2,3,4,5,6 的页面
.filter(action => prePages.contains(action.page_id.toString))
.map(action => (action.page_id, 1L)) // RDD[(page_id, 1)]
// .reduceByKey(_ + _).collect() 聚合,计算页面的访问数,数据量不大,可以直接拉到dirver端
.countByKey // 直接使用行动算子,计算每个key的个数
//3. 计算每个跳转流的数量
val totalPageFlows: collection.Map[String, Long] = userVisitActionRDD
.groupBy(_.session_id) // 按照session_id分组
.flatMap{
case (_, actionIt) => {
val page_ids: List[Long] = actionIt
.toList
.sortBy(_.action_time) // 按照操作时间排序
.map(action => action.page_id) // 只拿出每个条数据的 page_id
val preAction: List[Long] = page_ids.slice(0, page_ids.length - 1)
val postAction: List[Long] = page_ids.slice(1, page_ids.length)
// 制作页面跳转流
val actionFlow: List[String] = preAction.zip(postAction).map(action => action._1 + "->" + action._2)
// 过滤目标跳转页面流; 获取广播变量,RDD[List("1-2","2-3"...)]
actionFlow.filter(flow => broadcastVar.value.contains(flow))
}
} // flatmap 扁平化目标跳转流 RDD["1->2","1->2","2->3"...]
.map(flow => (flow, 1)) // 做成map形式,跳转流作为key
.countByKey() // 行动算子,计算每个跳转流的个数
//4. 计算跳转率
val pageConversionRate: collection.Map[String, String] = totalPageFlows.map {
case (flow, flowCount) =>
val prePage: String = flow.split("->")(0) // 获取跳转流的起始页码
// 跳转率 = 1->2 的跳转次数 / 1 的访问次数
val ConversionRate: Double = flowCount.toDouble / targetPageCount.getOrElse(prePage.toLong, Long.MaxValue)
val formater: DecimalFormat = new DecimalFormat(".00%") // 创建一个百分比格式转换器
(flow, formater.format(ConversionRate))
}
pageConversionRate
}
}
四、Spark SQL
4.1 Spark SQL概述
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
Spark SQL 它提供了 2 个编程抽象, 类似 Spark Core 中的 RDD:DataFrame、DataSet
Spark SQL 特点:无缝集成 SQL 查询;使用相同的方式连接不同的资源;集成Hive;连接JDBC
DataFrame:一个分布式数据容器,DataFrame 像传统数据库的二维表格,按行(Row)封装数据,不会检查数据的具体字段,所以在编译的时候无法得知字段类型是否正确,但是 DataFrame 为数据提供了类似元数据的 Schema 视图,可以记录数据的类型。DataFrame 是懒执行的,通过 Spark catalyst optimiser 进行优化,性能比 RDD 高很多。
DataSet:DataFrame API 的一个扩展,具有数据类型检查,支持编解码器。样例类被用来在 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称。DataSet 是强类型的,比如可以有DataSet[Car],DataSet[Person]。DataFrame 是 DataSet 的特列,DataFrame = DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。
4.2 Spark SQL 编程
1. SparkSession
SparkSession 是 Spark 2.0以后的 SQL 查询起始点,实质上是 SQLContext 和 HiveContext 的组合。
// 以下用到样例类 User
case class User(name: String, age: Long, gender: String)
2. DataFrame 编程
-
创建 DataFrame
object DFDemo { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() // 获取SparkSession构建器 .master("local[2]") // 配置 master .appName("DFDemo") // 配置 appName .getOrCreate() // 创建 val df: DataFrame = spark.read.json("D:\\user.json") // 读取 json 文件 df.show } } ================ +---+------+--------+ |age|gender| name| +---+------+--------+ | 23| male| maben| | 23|famale|chengfan| | 32|famale| lisi| +---+------+--------+ -
SQL 语法风格
SQL 语法查询,必须要有临时视图或者全局视图来辅助
object DFDemo { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("DFDemo") .getOrCreate() val df: DataFrame = spark.read.json("D:\\user.json") /* df.createTempView("user") // 临时视图只能在当前 Session 有效, 在新的 Session 中无效 df.createGlobalTempView("user") // 可以创建全局视图. 访问全局视图需要全路径:如 global_temp.xxx */ df.createOrReplaceTempView("user") // 常用 spark.sql("select * from user where age < 25").show } } ========== +--------+---+------+ | name|age|gender| +--------+---+------+ | maben| 23| male| |chengfan| 23|famale| +--------+---+------+ -
DSL 语法风格
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据,DSL 不需要创建视图。
object DFDemo { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("DFDemo") .getOrCreate() val df: DataFrame = spark.read.json("D:\\user.json") // df.printSchema // 查看 dataframe 的 schema df.select("name", "age", "gender").filter("age < 25").show } } ============ root |-- age: long (nullable = true) |-- gender: string (nullable = true) |-- name: string (nullable = true) +--------+---+------+ | name|age|gender| +--------+---+------+ | maben| 23| male| |chengfan| 23|famale| +--------+---+------+ -
RDD => DataFrame
涉及到数据转换时需要导入:import spark.implicits._ 这里的spark不是包名,而是表示 SparkSession 的对象
- 手动转换
object RDD2DF { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("RDD2DF") .getOrCreate() val rdd1 = spark.sparkContext.textFile("D:\\user.txt") .map(line => { val paras = line.split(",") (paras(0), paras(1).toInt, paras(2))}) import spark.implicits._ // 导入spark对象的隐式转换 // RDD => DataFrame 需要手动指定字段名 rdd1.toDF("name", "age", "gender").show } }- 通过样例类反射转换(最常用)
object RDD2DF2 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("RDD2DF2") .getOrCreate() val rdd1 = spark.sparkContext.textFile("D:\\user.txt") .map(line => { val paras = line.split(",") (paras(0), paras(1).toLong, paras(2))}) import spark.implicits._ rdd1.toDF.show // 通过样例类转换 } }- 通过 API 方式转换
object RDD2DF3 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("RDD2DF3") .getOrCreate() val rdd1 = spark.sparkContext.textFile("D:\\user.txt") .map(line => { val paras = line.split(",") (paras(0), paras(1).toInt, paras(2))}) import spark.implicits._ // 1.映射出来一个RDD[Row] val rowRDD = rdd1.map(x => Row(x._1, x._2, x._3)) // 2.创建 StructType 类型 val types = StructType(Array(StructField("name", StringType), StructField("age", IntegerType), StructField("gender", StringType))) // 3.传入 RDD[Row] 和 StructType 创建df val df = spark.createDataFrame(rowRDD, types) df.show } } -
DataFrame => RDD
object DF2RDD { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[2]") .appName("DF2RDD") .getOrCreate() val df: DataFrame = spark.read.json("D:\\user.json") val rdd = df.rdd rdd.collect.foreach(println) } }
3. DataSet 编程
-
创建 DataSet
使用 基本类型 或 样例类 的序列得到 DataSet
object DSDemo { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .master("local[2]") .appName("DSDemo") .getOrCreate() import spark.implicits._ // val ds = Seq(1,2,3,4,5,6).toDS val ds = Seq(User("maben", 23, "male"), User("chengfan", 23, "female"), User("lisi", 35, "female")).toDS ds.show } } -
通过 RDD 来得到 DataSet(常用)
为 Spark SQL 设计的 Scala API 可以自动的把包含样例类的 RDD 转换成 DataSet
object RDD2DS { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("RDD2DS") .master("local[2]") .getOrCreate() val rdd= spark.sparkContext.textFile("d:\\user.txt") import spark.implicits._ val ds = rdd.map(line => { val splits = line.split(",") User(splits(0), splits(1).toLong, splits(2)) // 用样例类封装 }).toDS ds.show } } -
DataSet => RDD
导入 SparkSession 对象的隐式转换,使用 ds.rdd
object DS2RDD { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .master("local") .appName("DS2RDD") .getOrCreate() val rdd = spark.sparkContext.parallelize(Seq(User("maben", 23, "male"), User("chengfen", 23, "female"), User("lisi", 35, "female"))) import spark.implicits._ val ds = rdd.toDS // ds 转换为 rdd ds.rdd.collect.foreach(println) } }
3. DataSet 编程实战:分组求和
// 1.统计不同注册来源url的人数
result.mapPartitions(partition => {
partition.map(item => (item.appregurl + "_" + item.dt + "_" + item.dn, 1))
}).groupByKey(_._1) // KeyValueGroupedDataset[String,(String, Int)]
.mapValues(_._2) // KeyValueGroupedDataset[String, Int]
.reduceGroups(_ + _) // Datatset[String, Int]
.map(item => {
val keys = item._1.split("_")
val appregurl = keys(0)
val dt = keys(1)
val dn = keys(2)
(appregurl, item._2, dt, dn)
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_appregurlnum")
3. DataSet 编程实战:over() 开窗
// 7. 统计各分区网站、用户级别下(website、memberlevel)的top3用户
import org.apache.spark.sql.functions._ // 导入隐式转换
result.filter(_.sitename != null)
.withColumn("rownum", row_number().over(Window.partitionBy( "memberlevel","dn").orderBy(desc("paymoney"))))
.where("rownum<4").orderBy("memberlevel", "sitename", "rownum")
.select("uid", "memberlevel", "register", "appregurl", "regsourcename", "adname",
"sitename", "vip_level", "paymoney", "rownum", "dt", "dn")
.coalesce(1).write.mode(SaveMode.Overwrite).insertInto("ads.ads_register_top3memberpay")
3. DatSet 编程实战:拉链表制作
// 查询当天增量数据,并封装为样例类
val dayResult = sparkSession.sql(
s"""
|SELECT a.uid, sum(cast(a.paymoney as decimal(10, 4))) as paymoney, max(b.vip_level) as vip_level,
|from_unixtime(unix_timestamp("$time", 'yyyyMMdd'), 'yyyy-MM-dd') as start_time, '9999-12-31' as end_time,
|first(a.dn) as dn
|FROM dwd.dwd_pcentermempaymoney a JOIN dwd.dwd_vip_level b ON a.vip_id=b.vip_id AND a.dn=b.dn
|WHERE a.dt="$time"
|GROUP BY uid
""".stripMargin)
.as[MemberZipper]
// 查询历史拉链表数据,并封装为样例类
val historyResult = sparkSession.sql("SELECT * FROM dws.dws_member_zipper")
.as[MemberZipper]
// 两份数根据用户id进行join,对end_time和paymoney进行修改
dayResult.union(historyResult).groupByKey(item => item.uid + "_" + item.dn)
.mapGroups{
case (key, iters) =>
val keys = key.split("_")
val uid = keys(0)
val dn = keys(1)
val list = iters.toList.sortBy(_.start_time)(Ordering.String) // 对开始时间进行排序
// 判断集合中有值,且集合中倒数第2条数据的结束时间为 9999-12-31(倒数第一条必然是9999-12-31)
if (list.size > 1 && "9999-12-31".equals(list(list.size - 2).end_time)) {
// 进入判断说明,存在历史数据,需要对end_time进行修改
val oldLastModel = list(list.size-2)
val lastModel = list.last
// 将最后一条数据的开始时间赋给倒数第2条数据的结束时间
oldLastModel.end_time = lastModel.start_time
// 更新最终的付费金额
lastModel.paymoney = (BigDecimal.apply(lastModel.paymoney) + BigDecimal.apply(oldLastModel.paymoney)).toString
}
// 每个用户在不同网站的所有消费记录都作为一个list,并用样例类封装
MemberZipperResult(list)
}
.flatMap(_.list)
.coalesce(3)
.write.mode(SaveMode.Overwrite).insertInto("dws.dws_member_zipper") // 重组对象打散,刷新拉链表
4. DataFrame 和 DataSet 转换
-
DataFrame => DataSet
object DF2DS { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .master("local[2]") .appName("DF2DS") .getOrCreate() val df = spark.read.json("d:/user.json") import spark.implicits._ // ds.as[样例类] val ds = df.as[User] ds.show } } -
DataSet => DataFrame
object DS2DF { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("DS2DF") .master("local[2]") .getOrCreate() val rdd = spark.sparkContext.parallelize(Seq(User("maben", 23, "male"), User("chengfen", 23, "female"), User("lisi", 35, "female"))) import spark.implicits._ val ds = rdd.toDS ds.toDF.show } }
5. RDD、DataFrame、DataSet 联系
从版本的产生上来看:RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
-
共同点
1. RDD、DataFrame、Dataset全都是 Spark 平台下的分布式弹性数据集 2. 三者都是惰性求值,只有遇到 action 操作时才会开始计算 3. 三者都有 partition 的概念 4. DataFrame 和 Dataset 进行转换操作时,需要导入 SparkSession 对象的隐式转换(import spark.implicits._) 5. DataFrame 和 Dataset 均可使用模式匹配获取各个字段的值和类型 -
区别
-
RDD
RDD 一般和 Spark MLlib 同时使用
RDD 不支持 SparkSQL 操作
-
DataFrame
每一行的类型固定为 Row,每一列的值需要通过解析才能访问
DataFrame 和 DataSet 均支持 SparkSQL 操作,还能注册临时表
DataFrame 和 DataSet 支持溢写特别方便的保存方式,比如 csv,可以注明每个字段
-
DataSet
DataSet 和 DataFrame 具有完全相同的成员函数,DataFrame 就是 DataSet 的一个特例
DataFrame 就是 DataSet[Row],每个元素的类型是 Row,需要使用 getAS 或者 匹配模式拿出特定的字段
DataSet 在定义了 case class 之后,可以很方便的获取每一个字段的信息
-
-
三者的转换
三者转换时需要导入依赖: import spark.implict._
-
RDD 与 DF 转换
RDD ——> DF
//1. 方式一 rdd.toDF(colName, colName, ...) //2. 方式二,数据封装样例类中,然后存入 RDD,样例类的属性,自动变成字段名 rdd.toDFDF ——> RDD
df.rdd -
RDD 与 DS 转换
RDD ——> DS
// 数据封装样例类中,然后存入 RDD rdd.DSDS ——> RDD
ds.rdd -
DF 与 DS 转换
DF ——> DS
// DF 中的数据已经有对应的样例类 df.as[样例类]DS ——> DF
ds.toDF
-
6. 自定义 SparkSQL 函数
-
自定义一个简单的 UDF 函数
scala> val df = spark.read.json("examples/src/main/resources/people.json") // 注册一个 udf 函数: toUpper是函数名, 第二个参数是函数的具体实现 scala> spark.udf.register("toUpper", (s: String) => s.toUpperCase) // 创建视图 scala> df.createOrReplaceTempView("people") // 在 SparkSQL 中使用自定义函数 scala> spark.sql("select toUpper(name), age from people").show -
自定义一个 UDAF(UserDefineAggregateFuction) 函数
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。
自定义函数需要继承 UserDefineAggregateFuction 类
示例:自定义一个 MyAvg 函数
class MyAvg extends UserDefinedAggregateFunction { // 1.输入数据类型 override def inputSchema: StructType = StructType(StructField("inputColumn", DoubleType)::Nil) // 2.缓冲区数据类型 override def bufferSchema: StructType = StructType(Array(StructField("sum", DoubleType), StructField("count", LongType))) // 3.最终输出数据类型 override def dataType: DataType = DoubleType // 4.确定性:比如同样的输入是否返回同样的输 override def deterministic: Boolean = true override def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0) = 0D // 存储数据的总和 buffer(1) = 0L // 存储数据的个数 } // 5.分区内(同executor)计算 override def update(buffer: MutableAggregationBuffer, input: Row): Unit = { if (!input.isNullAt(0)) { buffer(0) = buffer.getDouble(0) + input.getDouble(0) buffer(1) = buffer.getLong(1) + 1L } } // 6.分区间(不同executor)计算 override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0) buffer1(1) = buffer1.getDouble(1) + buffer2.getLong(1) } // 7.汇总并返回结果 override def evaluate(buffer: Row): Any = { // 格式化器,保留两位 val formater = new DecimalFormat(".00") val result = buffer.getDouble(0) / buffer.getLong(1) // 求平均值 formater.format(result) } }
4.3 SparkSQL 数据源
1. 通用读取和保存
Spark 读取和保存的默认数据格式是 parquet,也可以通过使用:spark.sql.sources.default 来设置。
-
通用的读取方法:spark.read.load
-
通用的保存方法:df.write.save
-
读取和保存指定格式的数据,要使用 format 指定数据类型
// 读取json数据 spark.read.format("json").load("examples/src/main/resources/people.json") // 以parquet格式保存数据 df.write.format("parquet").save("文件名.parquet") -
读取和SQL一步完成
以上三种方式都是使用 API 先把文件加载到 DataFrame,然后再查询。其实也可以直接在文件上进行查询
spark.sql("select * from json.`examples/src/main/resources/people.json`")json 表示文件的格式。后面的文件具体路径需要用反引号括起来。
-
文件保存的方式
使用 mode(SaveMode.xxx) 方法来设置保存的方式,SaveMode 是一个枚举类,以下是它的四个属性
ErrorIfExists(default):文件存在时,抛出异常 Append:文件存在时,进行追加操作
Overwrite:文件已存在时,进行覆盖操作 Ignore:文件存在时,不操作
2. 读取 JSON 文件
方式一:SparkSession.read.json(“path”)
方式二:SparkSession.read.format(“json”).load(“path”)
object DataSourceDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("Test")
.getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read.json("target/classes/user.json")
val ds: Dataset[User] = df.as[User]
ds.foreach(user => println(user.friends(0)))
}
}
case class User(name:String, age: Long, friends: Array[String])
注意:读取的 JSON 文件不是一个传统的 JSON 文件,要求每一行都是一个完整的 JSON 串。
3. 读取 Parquet 文件
Parquet 是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。Spark SQL 提供了直接读取和存储 Parquet 格式文件的方法。
object DataSourceDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("Test")
.getOrCreate()
import spark.implicits._
val jsonDF: DataFrame = spark.read.json("target/classes/user.json")
jsonDF.write.mode(SaveMode.Overwrite).parquet("target/classes/user.parquet")
val parDF: DataFrame = spark.read.parquet("target/classes/user.parquet")
val userDS: Dataset[User] = parDF.as[User]
userDS.map(user => {user.name = "mbaen"; user.friends(0) = "aaa";user}).show()
}
}
case class User(var name:String, age: Long, friends: Array[String])
Parquet 格式的文件是 Spark 默认格式的数据源,当使用通用的方式时可以直接保存和读取。而不需要使用 format。
spark.sql.sources.default 这个配置可以修改默认数据源。
4. JDBC 读写
Spark SQL 也支持使用 JDBC 从其他的数据库中读取数据的方式创建 DataFrame。通过对 DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。
注:如果想在 spark-shell 操作 JDBC, 需要把相关的 jdbc 驱动 copy 到 jars 目录下
-
JDBC 读数据
object jdbcRead { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("jdbcRead") .master("local[2]") .getOrCreate() // 方式一:read.load val jdbcDF = spark.read .format("jdbc") .option("url", "jdbc:mysql://hadoop102:3306/spark") .option("user", "root") .option("password", "maben996") .option("dbtable", "user") .load() // 方式二:read.jdbc /* val props = new Properties() props.setProperty("user", "root") props.setProperty("password", "maben996") val jdbcDF = spark.read.jdbc("jdbc:mysql://hadoop102:3306/spark","user",props) */ jdbcDF.show } } -
JDBC 写数据
object jdbcWrite { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("jdbcWrite") .master("local[2]") .getOrCreate() import spark.implicits._ val df = spark.read.json("d:/user.json") val ds = df.as[User] // 方式一:write.save ds.write.format("jdbc") .option("url", "jdbc:mysql://hadoop102:3306/spark") // 注意:最后要写上库名 .option("user", "root") .option("password", "maben996") .option("dbtable", "user") .mode(SaveMode.Append) // 追加模式 .save() // 方式二:write.jdbc /* val props = new Properties() props.setProperty("user", "root") props.setProperty("password", "maben996") ds.write.mode(SaveMode.Append)jdbc("jdbc:mysql://hadoop102:3306/spark", "user", props) */ } } case class User(name: String, age: Long, gender: String)
5. Hive 读写(Spark 集成 Hive)
-
内置的 Hive(测试时使用一次)
Spark 内置的 Hive 可以直接使用,Hive 的元数据存储在 derby 中, 仓库地址:$SPARK_HOME/spark-warehouse
scala> spark.sql("show tables").show scala> spark.sql("create table aa(id int)") scala> spark.sql("load data local inpath './ids.txt' into table aa") scala> spark.sql("show tables").show ...... -
Spark 集成一个已经部署好的 Hive (正确的打开方式)
Spark 集成 Hive
-
将 hive-site.xml 复制(或软连接) 到 Spark 的 conf/ 目录下;
在 hive-site.xml 中配置 Hive 表的存储位置为 HDFS。
<property> <name>hive.metastore.warehouse.dirname> <value>/user/hive/warehousevalue> <description>location of default database for the warehousedescription> property> -
将 hive-site.xml 中指定的数据驱动(Mysql 的驱动)复制到 Spark 的 jars/目录下
-
如果访问不到 HDFS,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/ 目录下
若 hive-site.xml 配置了其他引擎(Tez等),要注释掉,否则会报错 error configuration object
若 core-site.xml 配有压缩格式也要注释掉,或者在 spark-env.xml 中配置压缩格式本地库地址
# hadoop-core.xml 中配置了 lzo,故在 spark-env.sh 中配置 lzo 的本地库变量 export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:/opt/module/hadoop-2.7.2/lib/native export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar
客户端方式
Spark 提供了书写 HiveQL 的工具:hiveserver2 + beeline
// 1.启动 thrift 服务器 sbin/start-thriftserver.sh --master yarn --hiveconf hive.server2.thrift.bind.host=hadoop102 --hiveconf hive.server2.thrift.port=10000 // 2.启动 beeline 客户端 bin/beeline !connect jdbc:hive2://hadoop102:10000 // 按照提示输入本次登录的账号密码 // 注意:若连接失败,查看日志yarn日志,查看元数据是否在derby上,检查如上配置,尝试重新启动. 登录失败日志 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY 登录正常日志 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL代码中访问
-
拷贝 hive-site.xml 到 resources 目录下
-
添加依赖
<dependency> <groupId>org.apache.sparkgroupId> <artifactId>spark-hive_2.11artifactId> <version>2.1.1version> dependency> -
object HiveDemo { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "maben996") // 配置访问HDFS权限 val spark = SparkSession .builder() .appName("HiveDemo") .master("local[*]") // 如果 hive-site.xml 中没有配置 hive 的存储路径,需要添加以下参数 //.config("spark.sql.warehouse.dir", "hdfs://hadoop102:9000/user/hive/warehouse") .enableHiveSupport() .getOrCreate() // 建表查询... spark.sql("use spark") spark.sql( """ |CREATE TABLE `user`( | `name` string, | `age` int, | `gender` string) |row format delimited fields terminated by '\t' """.stripMargin).show spark.sql("...") }
-
4.4 Spark SQL 案例
1. 数据准备
在 Hive 中创建表, 并导入数据,一共有 3 张表: 1 张用户行为表, 1 张城市表, 1 张产品表。
CREATE TABLE `user_visit_action`(
`date` string,
`user_id` bigint,
`session_id` string,
`page_id` bigint,
`action_time` string,
`search_keyword` string,
`click_category_id` bigint,
`click_product_id` bigint,
`order_category_ids` string,
`order_product_ids` string,
`pay_category_ids` string,
`pay_product_ids` string,
`city_id` bigint)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/user_visit_action.txt' into table spark.user_visit_action;
CREATE TABLE `product_info`(
`product_id` bigint,
`product_name` string,
`extend_info` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/product_info.txt' into table spark.product_info;
CREATE TABLE `city_info`(
`city_id` bigint,
`city_name` string,
`area` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/city_info.txt' into table sparkprsparkactice.city_info;
2. 需求:求各区域热门商品 Top3
计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。
| 地区 | 商品名称 | 点击次数 | 城市备注 |
|---|---|---|---|
| 华北 | 商品A | 100000 | 北京21.2%,天津13.2%,其他65.6% |
| 华北 | 商品P | 80200 | 北京63.0%,太原10%,其他27.0% |
| 华北 | 商品M | 40000 | 北京63.0%,太原10%,其他27.0% |
| 东北 | 商品J | 92000 | 大连28%,辽宁17.0%,其他 55.0% |
思路:使用 SQL 来完成。对复杂的需求,可以使用 UDF 或 UDAF
1.查询出来所有的点击记录, 并与 city_info 表连接, 得到每个城市所在的地区. 与 Product_info 表连接得到产品名称
2.按照地区和商品 id 分组, 统计出每个商品在每个地区的总点击次数
3.每个地区内按照点击次数降序排列
4.只取前三名. 并把结果保存在数据库中
5.城市备注需要自定义 UDAF 函数
前四步代码实现
object SqlProject {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "maben996")
val spark = SparkSession
.builder()
.appName("SqlProject")
.master("local[*]")
.config("spark.sql.warehouse.dir", "hdfs://hadoop102:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
// 第五步:自定义UDAF函数,计算 "城市备注"
spark.udf.register("remark", new CityRemarkUDAF)
spark.sql("use spark1")
spark.sql(
"""
|select
| c.*,
| p.product_name,
| u.click_product_id
|from user_visit_action u join city_info c join product_info p
|on u.city_id=c.city_id and u.click_product_id=p.product_id
""".stripMargin).createOrReplaceTempView("t1")
spark.sql(
"""
|select
| area,
| product_name,
| count(*) click_count,
| remark(city_name) remark
|from t1
|group by area, product_name
""".stripMargin).createOrReplaceTempView("t2")
spark.sql(
"""
|select
| *,
| rank() over(partition by area order by click_count desc) `rank`
|from t2
""".stripMargin).createOrReplaceTempView("t3")
spark.sql(
"""
|select
| area,
| product_name,
| click_count,
| remark
|from t3
|where `rank`<=3
""".stripMargin).show(100, false)
spark.close
}
}
自定义UDAF函数的
class CityRemarkUDAF extends UserDefinedAggregateFunction {
// StringType 北京
override def inputSchema: StructType = StructType(StructField("city_name", StringType)::Nil)
// 缓冲数据的数据类型
override def bufferSchema: StructType = {
// Map(cityname, count), 总点击数
StructType(StructField("city_count", MapType(StringType, LongType))::StructField("total", LongType)::Nil)
}
// 最终结果的类型
override def dataType: DataType = StringType
// 确定性
override def deterministic: Boolean = true
// 缓存的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 缓存map对象 (北京 -> 1000 天津 -> 2000....)
buffer(0) = Map[String, Long]()
// 某地区某商品总点击量
buffer(1)=0L
}
// 分区内聚合
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
val cityName: String = input.getString(0)
var cityCountMap: collection.Map[String, Long] = buffer.getMap[String, Long](0)
cityCountMap += cityName -> (cityCountMap.getOrElse(cityName, 0L) + 1L)
buffer(0) = cityCountMap
buffer(1) = buffer.getLong(1) + 1L
}
}
// 分区间聚合
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
val map1: collection.Map[String, Long] = buffer1.getMap[String, Long](0)
val map2: collection.Map[String, Long] = buffer2.getMap[String, Long](0)
val resultMap: collection.Map[String, Long] = map2.foldLeft(map1) {
case(map, (cityName, count)) => map + (cityName -> (map.getOrElse(cityName, 0L) + count))
}
buffer1(0) = resultMap
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 返回值
// 北京21.2%,天津13.2%,其他65.6%
override def evaluate(buffer: Row): Any = {
val total: Long = buffer.getLong(1)
val cityCount: collection.Map[String, Long] = buffer.getMap[String, Long](0)
var top2: List[CityRemark] = cityCount.toList.sortBy(_._2).take(2).map {
case (cityName, count) => CityRemark(cityName, count.toDouble / total)
}
top2 :+= CityRemark("其他", top2.foldLeft(1D)((rate, cr) => rate - cr.rate))
top2.mkString(",")
}
}
case class CityRemark(cityName: String, rate: Double) {
val formater: DecimalFormat = new DecimalFormat(".00%")
override def toString: String = s"$cityName:${formater.format(rate)}"
}
五、Spark Streaming
5.1 Spark Streaming 概述
Spark Streaming 是 Spark 核心 API 的扩展, 用于构建弹性, 高吞吐量, 容错的在线数据流的微批处理程序。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。

Spark Streaming 提供了一个高级抽象:discretized stream(DStream),DStream 表示一个连续的数据流。DStream 内部是由一个 RDD 序列来表示的。
缺点:Spark Streaming 是一种“微量批处理”架构,和基于"一次处理一条记录"架构的系统相比,延迟会高一些。
Spark Streaming 架构图

从 1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据 JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
通过属性 spark.streaming.backpressure.enabled 来控制是否启用 backpressure 机制,默认值 false,即不启用。
direct 方式
5.2 DStream 创建
StreamingContext 是 Spark Streaming 的一个入口StreamingContext(conf, Seconds(5)),第一个参数是 SparkConf,第二个参数表示批处理的时间间隔。
关于 StreamingContext 的说明:
1.StreamingContext 已经启动,则不能再添加添加新的 StreamingContext
2.StreamingContext 已经停止(StreamingContext.stop()),也不能再重启
3.一个 JVM 内,同一时间只能启动一个StreamingContext
4.top() 的停止方式 StreamingContext 会把 SparkContext 停掉,如果仅仅要停止 StreamingContext,要使用:stop(false)
5.一个 SparkContext 可以取创建多个 StreamingContext,前提是上一个 StreamingContext 已经停掉。
添加 Maven 依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.1version>
dependency>
1. Socket 数据源
/*
使用 netcat 工具向 9999 端口不断的发送数据,通过 Spark Streaming 读取端口数据并统计不同单词出现的次数
*/
object Socket {
def main(args: Array[String]): Unit = {
//1. 创建StreamingContext
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount1")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(4))
//2. 核心数据集:DStreaming
val socketStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//3. 对DStraming做WordCount各种操作
val wordCountDStream: DStream[(String, Int)] = socketStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//4. 最终数据的处理:打印
wordCountDStream.print(100)
//5. 启动StreamingContext
ssc.start()
//6. 阻止当前线程退出
ssc.awaitTermination()
}
}
2. RDD 队列数据源
object RDDQueue {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount2")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
// 创建一个可变的RDD队列
val rddQueue: mutable.Queue[RDD[Int]] = mutable.Queue[RDD[Int]]()
// ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
// false 参数,表示每次计算间隔时间内的所有RDD,每次计算一个RDD
val resultDstream: DStream[Int] = ssc.queueStream(rddQueue, false).reduce(_ + _)
resultDstream.print(100) // 每次打印100行
ssc.start()
// 每秒向队列中推送一个1到100的RDD
while (true) {
rddQueue.enqueue(ssc.sparkContext.parallelize(1 to 100))
Thread.sleep(1000)
}
ssc.awaitTermination()
}
}
3. 自定义数据源
自定义数据源本质就是自定义接收器
object CustomRecevier {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("CustomRcevier")
//1. 创建SparkStreaming的入口对象,参数2表示时间间隔
val ssc = new StreamingContext(conf, Seconds(5))
//2. 创建一个DSteram
val lines = ssc.receiverStream(new MyRecevier("hadoop102", 9999))
//3. 处理数据 wordcount
lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print(100)
//4. 启动任务
ssc.start()
//5. 等待计算结果,退出程序
ssc.awaitTermination()
ssc.stop(false) // 关闭 StreamingContext,但是不关闭 SparkContext
}
}
/*
自定义数据源本质就是自定义接收器
从 socket 来接收数据
*/
class MyRecevier(val host: String, val port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
/*
接收器启动的时候调用的方法,用来初始化一些读取数据必须的资源
该方法不能阻塞,所以要启动一个子线程来读取数据
*/
override def onStart(): Unit = {
// 启动一个新的线程来及接收资源
new Thread("Socket Receiver") {
override def run(): Unit = recevierData()
}.start()
}
// 接收数据
def recevierData(): Unit = {
try{
// 从socket读数据
val socket = new Socket(host, port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, "utf-8"))
var line = reader.readLine()
// 当 receiver 没有关闭,且 reader 读到了数据则循环发送给 spark
while (line != null) {
// 发送数据给spark
store(line)
line = reader.readLine()
}
// 关闭资源
reader.close()
socket.close()
} catch {
case e: Exception => e.printStackTrace()
} finally {
// 当读取报错时,重启任务
restart("重新连接")
}
}
override def onStop(): Unit = {}
}
4. Kafka 数据源(常用)
需要用到 spark-streaming-kafka_2.11 来使用它,包内提供的 KafkaUtils 对象可以在 StreamingContext 和 JavaStreamingContext 中用 Kafka 消息创建出 DStream。
两个核心类:KafkaUtils、KafkaCluster
引入依赖:spark-streaming-kafka-0-8_2.11,spark 2.3.0 之后可以引入spark-streaming-kafka-0-10_2.11 的依赖。
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
-
Kafka高级API,自动维护 offset
object HighKafka { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("HighKafka") val ssc = new StreamingContext(conf, Seconds(3)) //kafka 参数声明 val topic = "first" val group = "bigdata" val brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092" val kafkaParams = Map( // 配置 ConsumerConfig.GROUP_ID_CONFIG -> group, ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers ) // 泛型1和2:key-value的类型;泛型3和4:key-value的解码器 val sourceDStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, Set(topic)) sourceDStream.print ssc.start() ssc.awaitTermination() } } -
改进以上代码,保存offset到checkpoint中,重启进程后继续消费,实现 Excatly Once
object HighKafka2 { def createSSC(): StreamingContext = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("HighKafka") val ssc: StreamingContext = new StreamingContext(conf, Seconds(3)) ssc.checkpoint("./ck1") // 保存到本地文件,也可以选择保存到 HDFS,后面介绍 //kafka 参数声明 val brokers: String = "hadoop102:9092,hadoop103:9092,hadoop104:9092" val topic: String = "first" val group: String = "bigdata" val kafkaParams: Map[String, String] = Map( ConsumerConfig.GROUP_ID_CONFIG -> group, ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers ) // 泛型1和2:key-value的类型;泛型3和4:key-value的解码器 val sourceDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder]( ssc, kafkaParams, Set(topic)) sourceDStream.print ssc } def main(args: Array[String]): Unit = { val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck1", createSSC) ssc.start() ssc.awaitTermination() } } -
Kafka低级API,手动维护Offset
object LowKafka { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LowKafka") val ssc: StreamingContext = new StreamingContext(conf, Seconds(3)) // 1. kafka 参数声明 val topic = "first" val group = "bigdata" val broker = "hadoop102:9092,hadoop103:9092" val kafkaParams = Map { ConsumerConfig.GROUP_ID_CONFIG -> group ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> broker } // 2. 创建KafkaCluster,用户读取Offset val kafkaCluster: KafkaCluster = new KafkaCluster(kafkaParams) val sourceDStream: InputDStream[String] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String]( ssc, kafkaParams, readOffset(kafkaCluster, topic, group), //读取Offset (messageHandler: MessageAndMetadata[String, String]) => messageHandler.message() ) // 3. 处理数据wordcount sourceDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print(100) // 4. 保存Offset saveOffset(sourceDStream, kafkaCluster, group) ssc.start() ssc.awaitTermination() } /* 读取 Offset */ def readOffset(kafkaCluster: KafkaCluster, topic: String, group: String): Map[TopicAndPartition, Long] = { // 最终要返回的 Map var resultMap: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long]() // 获取分区信息 val topicAndPartitionSetEither: Either[Err, Set[TopicAndPartition]] = kafkaCluster.getPartitions(Set(topic)) // 判断分区是否存在 topicAndPartitionSetEither match { // 不为空,则取出分区信息 case Right(topicAndPartitionSet) => val partitonAndOffsetMapEither: Either[Err, Map[TopicAndPartition, Long]] = kafkaCluster.getConsumerOffsets(group, topicAndPartitionSet) // 分区信息中的Map不为空 if (partitonAndOffsetMapEither.isRight) { // 取出分区信息中的Map[分区信息, 偏移量],赋给resultMap val TopicAndPartition2LongMap = partitonAndOffsetMapEither.right.get // 封装到 resultMap 中 resultMap ++= TopicAndPartition2LongMap // 分区信息中Map为空,表示目前是第一次消费 } else { // 遍历每一个分区偏移量都从 0 开始 topicAndPartitionSet.foreach { // 封装到 resultMap 中 topicAndPartition => resultMap += topicAndPartition -> 0L } } // 分区信息为空,不处理 case _ => } resultMap } /* 保存 Offset */ def saveOffset(sourceDStream: InputDStream[String], kafkaCluster: KafkaCluster, group: String): Unit = { sourceDStream.foreachRDD(rdd => { // 最后要返回的 Map var map: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long]() // 强转成HasOffsetRanges,包含了本次消费的offset起止范围 val hasOffsetRanges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges] // 获取 offsetRanges val ranges: Array[OffsetRange] = hasOffsetRanges.offsetRanges ranges.foreach(range => { // 封装每个分区最新的 offset 到 map map += range.topicAndPartition -> range.untilOffset }) // 设置集群偏移量 kafkaCluster.setConsumerOffsets(group, map) }) } }
5.3 DStream 转换
1. 无状态转换
无状态转化操作是分别应用到每个 RDD 上的,操作的范围在一个时间间隔内。例如:reduceByKey ( ) 只会聚合每个时间区间中的数据。同时,Key-Value 对类型的 DStream 拥有和 RDD 一样的与连接相关的转化操作,cogroup ( )、join ( )、leftOuterJoin ( ) 等。也可以像常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并一个时间间隔内的多个流。
transfrom 操作:每一个批次执行一次,对 DStream 中的 RDD 进行转换,使之可以进行一些 RDD操作。
class TransformDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformDemo")
val ssc = new StreamingContext(conf, Seconds(3))
val socketStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
// 转换操作
val resultStream: DStream[(String, Int)] = socketStream.transform(rdd => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
})
resultStream.print(100)
ssc.start()
// 阻止当前线程退出
ssc.awaitTermination()
}
}
2. 有状态转换
updataStateByKey
允许在使用新信息不断更新状态的同时能够保留他的状态
使用 updateStateByKey 更新状态,需要传入一个函数,规定泛型
object UpdateStateByKeyDemo {
def createSSC(): StreamingContext = {
// 1. 创建StreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("TransformDemo")
val ssc = new StreamingContext(conf, Seconds(3))
// 2. 设置检查点: 使用updateStateByKey必须设置检查点
ssc.checkpoint("hdfs://hadoop102:9000/checkpoint")
// 3. kafka 配置声明
val topic = "first"
val group = "bigdata"
val brokers = "hadoop102:9092"
val kafkaParams: Map[String, String] = Map {
ConsumerConfig.GROUP_ID_CONFIG -> group
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers
}
// 4.创建kafkaDStream
val kafkaDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
kafkaParams,
Set(topic))
// 5. wordcount处理数据 ,使用updateStateByKey更新状态,需要规定泛型,传入一个函数
val resultDStream: DStream[(String, Int)] =
kafkaDStream.map(kv => (kv._2, 1)).updateStateByKey[Int](updateFunction _)
// 6. 启动SparkStream,并打印结果
resultDStream.print(100)
// 返回 ssc
ssc
}
def main(args: Array[String]): Unit = {
// 设置HDFS用户名,否则会出现权限不够
System.setProperty("HADOOP_USER_NAME", "maben996")
val ssc = StreamingContext.getActiveOrCreate("hdfs://hadoop102:9000/checkpoint", createSSC)
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
}
/**
* @param newValue 接收上一个间隔内某个Key的value序列Seq(1,1,1,2,1,2,1,...)
* @param runningCount 本次间隔内这个Key的value封装为Option(有可能为None)传入该函数
* @return 求和后,同样封装为Option返回,作为Seq进入下一个间隔
*/
def updateFunction(newValue: Seq[Int], runningCount: Option[Int]): Option[Int] = {
Option(newValue.sum + runningCount.getOrElse(0))
}
}
window
窗口计算,一个窗口可以包含多个时间段,允许执行转换操作作用在一个窗口内的数据。
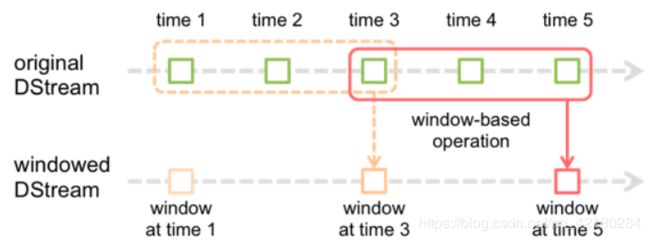
参数说明:windowDuration 窗口长度,slideDuration 滑动长度(每个时间间隔,窗口移动的速度)
这两个参数必须是 DStream 的 时间间隔 interval 的整数倍。
-
reduceByKeyAndWindow(reduceFunc: (V, V) => V,windowDuration: Duration, slideDuration: Duration)
//reduceByKeyAndWindow(reduceFunc: (V, V) => V,windowDuration: Duration, slideDuration: Duration) /* 参数1: reduce 计算规则 参数2: 窗口长度 参数3: 窗口滑动步长. 每隔这么长时间计算一次. */ object Window1 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("Window1") val ssc = new StreamingContext(conf, Seconds(4)) val socketDStream = ssc.socketTextStream("hadoop102", 9999) socketDStream.flatMap(_.split(" ")).map((_, 1)) // 如果省略 slideDuration 参数,默认 slideDuration=interval .reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(16), Seconds(8)) .print(100) ssc.start() ssc.awaitTermination() } } -
reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration),该函数加入了invReduceFunc,会利用旧值来进行计算,效率略高。
//reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration, filterFunc:(K, V)) => Boolean) /* 参数1: reduce 聚合,加上每一次新的interval的值 参数2: 逆聚合,减去上一次离开的interval的值 参数3: 窗口长度 参数4: 窗口滑动步长. 每隔这么长时间计算一次 参数5: 过滤掉计算结果为0的 */ object Window2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[*]").setAppName("Window1") val ssc = new StreamingContext(conf, Seconds(4)) ssc.checkpoint("./ck") val socketDStream = ssc.socketTextStream("hadoop102", 9999) socketDStream.flatMap(_.split(" ")).map((_, 1)) .reduceByKeyAndWindow(_ + _, _ - _, Seconds(16), Seconds(8), filterFunc = _._2 > 0) .print(100) ssc.start() ssc.awaitTermination() } } -
window(windowLength, slideInterval)
// window(windowLength, slideInterval) // 对源 DStream 进行窗口化操作,返回一个新的 Dstream,之后的操作就默认是在窗口内。 -
countByWindow(windowLength, slideInterval)
// countByWindow(windowLength, slideInterval) // 返回一个滑动窗口计数流中的元素的个数。
5.4 DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream’s contents as text files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream’s contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream’s contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
在使用 foreach 时,网络连接不能写在 driver 中(序列化);如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;使用 foreachPartion,在分区中中创建连接,按分区处理。
5.5 DStream 编程进阶
六、Structured Streaming
Spark 2.0 后引入了一套新的流式计算模型:Structured Streaming。该组件进一步降低了处理数据的延迟时间,实现了 Exectly One 语义,可以保证数据被精准消费。
Structured Streaming 基于 Spark SQl 引擎,是一个具有弹性和容错的流式处理引擎。在内部,Structured Streaming 查询使用微批处理引擎(micro-batch processing engine)处理,微批处理引擎把流数据当做一系列的小批job(small batch jobs ) 来处理。所以,延迟低至 100 毫秒,从 Spark2.3,引入了一个新的低延迟处理模型:Continuous Processing,延迟低至 1 毫秒。
6.1 Structured Streaming 编程模型
1. 基本概念
-
输入表
数据流一条一条追加到一个没有下界的 DataFrame 表中。这个 DataFrame 表叫做输入表(Input Table)。
-
结果表
作用在输入表上的查询将会产生“结果表(Result Table)”。每个触发间隔(trigger interval, 例如 1s),新行被追加到输入表,最终会更新结果表。无论何时更新结果表,我们都希望将更改的结果行写入到外部接收器(external sink)。

-
输出
输出(Output)定义为写到外部存储.输出模式(outputMode)有 3 种:
-
Complete Mode 整个更新的结果会被写入到外部存储,整张结果表在每次触发时都会全量输出。
必须要有聚合操作。
-
Append Mode 仅仅把每个时间间隔(Trigger)里的新追加到结果表的行写到外部存储,类似无状态转换。
有聚合操作时,必须要有 Watermark。
-
Updata Mode 把每个时间间隔(Trigger)里结果表中更新的行写到外部存储。对于数据库类型的sink来说,这是一种理想的模式。
没有聚合操作时:Updata Mode = Append Mode
有聚合操作时:Updata Mode 与 Complete Mode 的不同在于只将更新的行输出
-
2. Window 和 Watermark
-
Window 处理 Event-time
Event-time 是指嵌入到数据本身的时间,或者指数据产生的时间。对于 Spark 来将更多的是想操作数据产生时的时间(event-time),而不是 Spark 接收他们的时间。Structured Streaming 采用 window 分组的方式处理 Evet-time。
Structured Streaming 的 Window 机制:通常数据中,每个设备中的事件是表中的一行,而 event-time 是行中的一个列值。这就允许将基于窗口的聚合(比如每分钟的事件数)看成是 event-time 列的分组和聚合的特殊类型 —— 每个时间窗口是一个组,每行可以属于多个窗口/组。因此,可以在静态数据集和数据流上进行基于事件时间窗口的聚合查询,从而使操作更加方便。
下图中的数据根据 window 分组,一行数据可以属于多个组,一旦确定分组,其中的 event-time 就是唯一的。
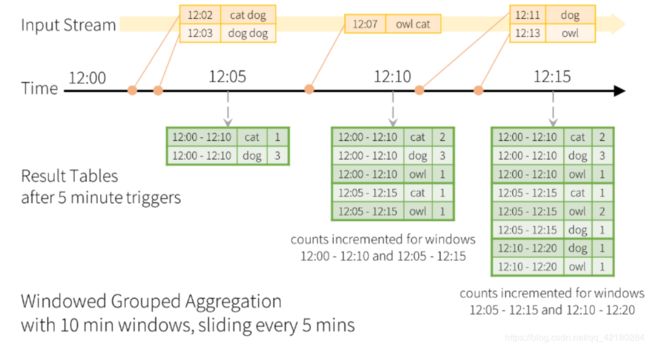
-
Watermark 处理 Late-date
Late-date 是指 Spark 在更新结果表时出现的延迟数据。在更新结果表时,Spark 会处理前期的聚合,并根据一个状态或者阈值来清理过期的聚合。从 Spark 2.1开始支持水印(watermarking ),它允许用户确定延迟的阈值,允许引擎相应地删除过期聚合。在非流数据集上使用 Watermark 是无效的。

3. 容错语义
提供端到端的 exactly-once 语义是 Structured Streaming 设计的主要目标。为了达成这一目的,Structured Streaming 设计了 接收器(sink)和 执行引擎(execution engine)来追踪数据的处理的具体进度,以便重启处理失败的进程。
结构化数据流都有偏移量(类似于 kafka 中的 offset),用来记录流的读取位置。执行引擎(execution engine)使用 checkpoint 和 WALs (write-ahead logs)来记录每个 trigger 中正在处理的数据的偏移量。结合可重用的数据源(replayable source)和幂等接收器(idempotent sink) 的使用,Structured Streaming 可以确保在任何失败的情况下端到端的 exactly-once 语义。

6.2 Structured Streaming 数据源
Structured Streaming 是基于 spark sql 引擎,需要引入spark-sql 依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.4.3version>
dependency>
1. socket source
object Socket {
def main(args: Array[String]): Unit = {
//1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Socket")
.getOrCreate()
import spark.implicits._
//2. 从 socket 中读取数据
val linesDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
//3. 把DF转为DS进行操作,并每一行数据为words
val words: Dataset[String] = linesDF.as[String].flatMap(_.split("\\W+"))
//4. 计算DS中的数据
val wordCounts: DataFrame = words.groupBy("value").count()
//5. 启动流计算,并将结果打印到控制台
val queryResult: StreamingQuery = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start
queryResult.awaitTermination()
spark.stop()
}
}
说明:
- complete 模式输出,必须要进行聚合操作;
- spark.readStream 得到的 DataFrame 就是一个列名为 value 的输入表;
- wordCounts 是一个流式 DataFrame, 它表示流中正在运行的单词数;
- 在流式数据 (streaming data) 上启动查询;
- 流式计算将会在后台启动。查询对象(query: StreamingQuery)可以激活流式查询(streaming query),然后通过awaitTermination() 来等待查询的终止,从而阻止查询激活之后进程退出。
2. file source
-
读取普通文件夹内的文件(略)
-
读取自动分区的文件夹内的文件
当文件夹被命名为 “key=value” 形式时,Structured Streaming 会自动递归遍历当前文件夹下的所有子文件夹,并根据文件名实现自动分区,同级目录下的文件夹的命名规则必须一致。

例如上图的文件夹结构
object fileSource {
def main(args: Array[String]): Unit = {
//1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark = SparkSession
.builder()
.master("local[*]")
.appName("fileSource")
.getOrCreate()
//2. 定义Schema,用于指定列名以及列中的数据类型
val userSchema: StructType = new StructType()
.add("name", StringType)
.add("sex", StringType)
.add("age", IntegerType)
//3. 读取本地目录下的文件
val userDF: DataFrame = spark.readStream
.schema(userSchema)
.csv("D:\\datas\\ss")
//4. 启动流式计算,查询结果表并打印到控制台
val queryResult: StreamingQuery = userDF.writeStream
.outputMode("append") // 没有进行聚合操作,不能用complete模式
.trigger(Trigger.ProcessingTime(1000)) //触发器,表示1000毫秒更新一次结果表
.format("console")
.start()
queryResult.awaitTermination()
spark.stop()
}
}
================由于目录下的文件夹格式满足要求,故结果自动分区
+-------+------+---+----+
| name| sex|age|year|
+-------+------+---+----+
| lisi| male| 18|2019|
|zhiling|female| 28|2019|
| lisi| male| 18|2018|
|zhiling|female| 28|2018|
| lisi| male| 18|2017|
|zhiling|female| 28|2017|
+-------+------+---+----+
3. kafka source(常用)
参考文档: http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
引入 spark-sql-kafka 依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.12artifactId>
<version>2.4.3version>
-
以 Streaming 模式创建 Kafka 工作流
object kafkaSource { def main(args: Array[String]): Unit = { //1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession val spark = SparkSession .builder() .master("local[*]") .appName("kafkaSource") .getOrCreate() import spark.implicits._ //2. kafka 中读到的输入表的 Schema 是固定的:key,value,topic,partition,offset,timestamp,timestampType val kafkaDF: DataFrame = spark.readStream .format("kafka") //设置 kafka 数据源 .option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092") .option("subscribe", "topic1") // 订阅多个主题用逗号隔开 // .option("subscribePattern", "topic.*") // 也可使用正则表达式匹配多个topic .load() //3. 转换为DS处理数据 // kafka的key、value列默认为字节,处理之前要转为string val wordCounts: DataFrame = kafkaDF.selectExpr("CAST(value AS String)") .as[String] .flatMap(_.split("\\W+")) .groupBy("value") .count() //4. 启动流式计算,读取结果表并打印到控制台 val queryResult: StreamingQuery = wordCounts.writeStream .outputMode("complete") // 聚合操作下使用complete .format("console") .trigger(Trigger.ProcessingTime(1000)) .start() queryResult.awaitTermination() spark.stop() } } -
通过 Batch 模式创建 Kafka 工作流
Batch 模式为一次性批量作业,处理一批数据就结束,而非持续性的处理数据。该模式可以设置消费开始和结束的具体偏移量,如果不设置 checkpoint 的情况下,默认起始偏移量 earliest,结束偏移量为 latest。
object kafkaSource2 { def main(args: Array[String]): Unit = { //1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession val spark = SparkSession .builder() .master("local[*]") .appName("kafkaSource2") .getOrCreate() import spark.implicits._ //2. 一次性读取,使用spark的read方法,而不是readStream // kafka 中读到的输入表的 Schema 是固定的:key,value,topic,partition,offset,timestamp,timestampType val kafkaDF: DataFrame = spark.read .format("kafka") // 设置kafka数据源 .option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092") .option("subscribe", "topic1") .option("startingOffsets", """{"topic1":{"0":12}}""") // 设置 读取offset的开始位置 .option("endingOffsets", "latest") // 设置 读取offset的结束位置 .load() //3. 转为DF处理数据 // kafka的key、value列默认为字节,处理之前要转为string val wordCount: DataFrame = kafkaDF.selectExpr("CAST(value AS String)") .as[String] .flatMap(_.split("\\W+")) .groupBy("value") .count() //4. 一次性写出DataFrame中的数据,使用write,而不是writeStream wordCount.write .format("console") .save() } }
4. Rate source
以固定的速率生成固定格式的数据, 用来测试 Structured Streaming 的性能
object RateSourceDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("RateSourceDemo")
.getOrCreate()
val rows: DataFrame = spark.readStream
.format("rate") // 设置数据源为 rate
.option("rowsPerSecond", 10) // 设置每秒产生的数据的条数, 默认是 1
.option("rampUpTime", 1) // 设置多少秒到达指定速率 默认为 0
.option("numPartitions", 2) /// 设置分区数 默认是 spark 的默认并行度
.load
rows.writeStream
.outputMode("append")
.trigger(Trigger.Continuous(1000))
.format("console")
.start()
.awaitTermination()
}
}
6.3 Structured Streaming 操作
1. 基本操作
-
弱类型操作(操作DataFrame,了解)
object weakTypeOption { def main(args: Array[String]): Unit = { //1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession val spark = SparkSession .builder() .master("local[*]") .appName("weakTypeOption") .getOrCreate() //2. 定义Schema,用于指定列名以及列中的数据类型 val userSchema: StructType = new StructType() .add("name", StringType) .add("age", IntegerType) .add("gender", StringType) //3. 读取 json 文件 val jsonDF: DataFrame = spark.readStream .format("json") .schema(userSchema) .load("D:\\datas\\json") //4. 直接操作DF(弱类型) val resultDF: Dataset[Row] = jsonDF.select("name", "age", "gender").where("age <=25") //5. 启动流式计算,查询结果表,并打印到控制台 val queryReuslt: StreamingQuery = resultDF.writeStream .outputMode("append") .format("console") .trigger(Trigger.ProcessingTime(1000)) .start() queryReuslt.awaitTermination() spark.stop() } } -
强类型操作(操作DataSet,了解)
object forceTypeOption { def main(args: Array[String]): Unit = { //1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession val spark = SparkSession .builder() .master("local[*]") .appName("forceTypeOption") .getOrCreate() import spark.implicits._ //2. 自定义Schema,用于指定列名以及列中的数据类型 val userSchema = new StructType() .add("name", StringType) .add("age", IntegerType) .add("gender", StringType) //3. 读取json 文件 val jsonDF: DataFrame = spark.readStream .schema(userSchema) .json("D:\\datas\\json") //4. 转为DS(强类型),进行操作 val resultDS: Dataset[User] = jsonDF .as[User] // 通过样例类转为DS .filter(_.age <= 25) //5. 开启流式计算,查询结果表,并将打印到控制台 val queryReslt: StreamingQuery = resultDS.writeStream .format("console") .outputMode("append") .trigger(Trigger.ProcessingTime(1000)) .start() queryReslt.awaitTermination() spark.stop() } } case class User(name: String, age: Int, gender: String) -
SQL 操作(重要)
object sqlOptioin { def main(args: Array[String]): Unit = { //1. Structured Streaming 是基于 spark sql 引擎, 所以需要先创建 SparkSession val spark = SparkSession .builder() .master("local[*]") .appName("sqlOptioin") .getOrCreate() import spark.implicits._ //2. 自定义Schema,用于指定列名以及列中的数据类型 val userSchema = new StructType() .add("name", StringType) .add("age", IntegerType) .add("gender", StringType) //3. 读取json 文件 val jsonDF: DataFrame = spark.readStream .schema(userSchema) .json("D:\\datas\\json") //4. 创建临时表,使用SQL处理数据 jsonDF.createOrReplaceTempView("user") val resultDF: DataFrame = spark.sql( """ |select | * |from user |where age <= 25 """.stripMargin) val queryResult: StreamingQuery = resultDF.writeStream .format("console") .outputMode("append") .start queryResult.awaitTermination() spark.stop() } }
2. 基于 Event-time 的 Winodw 操作
在实际生产中,有很多场景需要按照事件发生时的时间(event-time)对数据进行操作。使用 window 按照 event-time 进行分组处理数据,则不必考虑 Spark 陆续接收事件的顺序是否与事件发生的顺序一致,也不必考虑事件到达 Spark 的时间与事件发生时间的关系,在提高数据处理精度的同时,大大减少了开发者的工作量。
实现每过5分钟统计最近10分钟的单词数。
2019-09-25 09:45:00,dog
2019-09-25 09:49:00,cat
2019-09-25 09:53:00,dog
-------------kafka生产3条数据
object Window1 {
def main(args: Array[String]): Unit = {
//1. 获取sparkSession
val spark: SparkSession = SparkSession.builder()
.master("local[*]")
.appName("Window")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//2. 从kafka读取数据
val kafkaDF: DataFrame = spark.readStream
.format("kafka")
.option("subscribe", "topic1")
.option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092")
.load()
//3. 处理数据 2019-09-25 09:49:00,dog
val resultDF = kafkaDF.selectExpr("CAST(value AS String)") // 只获取value
.as[String]
.map(value => {
val splits = value.split(",")
(splits(0), splits(1))
})
// 需要一个Scheme的DataFrame,才能进行window聚合操作,并且其中有一列是event-time
.toDF("event-time", "word")
.groupBy(
// 进行window操作,取出event-time,设定窗口大小,滑动步长
window($"event-time", "10 minutes", "5 minutes"),
$"word"
).count()
.sort("window") // window操作event-time,聚合生成window列,按window排序
//4. 启动流式计算,输出到控制台
val resultQuery: StreamingQuery = resultDF.writeStream
.format("console")
.outputMode("complete") // 聚合操作,全量输出
.trigger(Trigger.ProcessingTime(1000))
.option("truncate", false) // 取消截断,完全显示每一列
.start
resultQuery.awaitTermination()
spark.stop()
}
}
================输出
Batch: 1
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 09:40:00, 2019-09-25 09:50:00]|dog |1 |
|[2019-09-25 09:45:00, 2019-09-25 09:55:00]|dog |1 |
+------------------------------------------+----+-----+
Batch: 2
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 09:40:00, 2019-09-25 09:50:00]|cat |1 |
|[2019-09-25 09:40:00, 2019-09-25 09:50:00]|dog |1 |
|[2019-09-25 09:45:00, 2019-09-25 09:55:00]|dog |1 |
|[2019-09-25 09:45:00, 2019-09-25 09:55:00]|cat |1 |
+------------------------------------------+----+-----+
Batch: 3
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 09:40:00, 2019-09-25 09:50:00]|cat |1 |
|[2019-09-25 09:40:00, 2019-09-25 09:50:00]|dog |1 |
|[2019-09-25 09:45:00, 2019-09-25 09:55:00]|dog |2 |
|[2019-09-25 09:45:00, 2019-09-25 09:55:00]|cat |1 |
|[2019-09-25 09:50:00, 2019-09-25 10:00:00]|dog |1 |
+------------------------------------------+----+-----+
event-time 窗口生成规则
截取 org.apache.spark.sql.catalyst.analysis.TimeWindowing 类中源码
// The windows are calculated as below:
maxNumOverlapping = ceil(windowDuration / slideDuration)
for (i <- 0 until maxNumOverlapping)
windowId <- ceil((timestamp - startTime) / slideDuration)
windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
windowEnd <- windowStart + windowDuration
return windowStart, windowEnd
windowStart 和 windowEnd 组成一个左闭右开的窗口,windowStart = 第一个大于 timestamp 时间的被 windowDuration 整除的时间,例如 windowDuration =10 minutes,slideDuration = 4 minutes,10:30:00 这个时间的数据的第一个窗口的 windowStart 就等于 10:32:00,windowEnd =10:36:00
最大窗口个数 = windowDuration / slideDuration 向上取整,startTime 代表一个偏移量,默认 “0 second”,例如为 “30 seconds” 时,窗口时间会向后偏移30秒。
例如:windowDuration =10 minutes,slideDuration = 4 minutes,startTime = 20 seconds
// 三条数据
2019-09-25 09:45:00,dog
2019-09-25 09:49:00,cat
2019-09-25 09:51:00,dog
// 第一条数据:09:45:00 它的时间窗口为:
09:36:20 - 09:40:20
09:40:20 - 09:44:20
09:44:20 - 09:48:20
// 第二条数据:09:49:00 它的时间窗口为:
09:40:20 - 09:44:20
09:44:20 - 09:48:20
09:48:20 - 09:52:20
// 第三条数据:09:51:00 它的时间窗口为:
09:40:20 - 09:44:20
09:44:20 - 09:48:20
09:48:20 - 09:52:20
3. 基于 Window 的 Watermark 处理延迟数据
从 spark2.1, 引入了 watermark(水印),执行引擎(execution engine)可以自动的跟踪当前的事件时间,并据此尝试删除旧状态。通过指定 event-time 列和预估事件的延迟时间上限来定义一个查询的 watermark,延迟时间在上限内的被聚合,延迟时间超出上限的数据被丢弃。
通过 withWatermark() 来定义 watermark,watermark时间 = MaxEventTime - Threshhod 即每个 trigger 中 evet-time 最大的数据减去延迟时间 Threshhod 就是本次 trigger 的水印时间,该水印时间对下一个 trigger 的数据生效。水印只会增加不会减小。
Structured Streaming 引入 Watermark 机制, 主要是为了解决以下两个问题:
- 处理聚合中的延迟数据
- 减少内存中维护的聚合状态
在不同输出模式(complete, append, update)中,Watermark 会产生不同的影响。
-
update 模式下使用 watermark,会把 event-time < watermark 的状态删除,因为这些状态之后不会再更新了。
官网:每次输出紫色部分的数据(在水印时间上方,且是更新的数据),便达到了计数的效果。
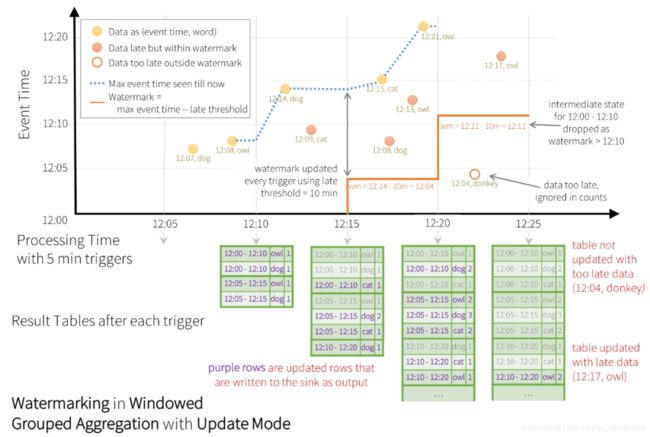
理解:Update 模式下,每次只输出更新的数据,当有延迟数据到达时,判断其时间窗口是否在水印时间之下,一条数据可能会有多个窗口,将该数据在水印时间之下的窗口丢弃,水印时间之上的窗口继续作为更新数据输出,图中紫色为输出。
示例:每次只输出水印时间右侧的数据,12:04|E 数据虽然更新了结果表,但是被水印丢弃,所以不会输出。同样满足计数的需求。

代码:
object Watermark {
def main(args: Array[String]): Unit = {
//1. 创建SaprkSeesion
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("Watermark")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//2. 从kafka读取数据
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
//3. 处理数据 2019-09-25 12:02:00|A
val resultDF: DataFrame = socketDF
.as[String]
.flatMap(line => {
val splits = line.split("\\|")
splits(1).split(",").map((Timestamp.valueOf(splits(0)), _))
})
.toDF("timestamp", "word") // timestamp 必须是Timestamp类型,或运行在window中
.withWatermark("timestamp", "10 minutes")
.groupBy(window($"timestamp", "10 minutes", "5 minutes"), $"word")
.count() // 注意:只有 Update 模式下,被聚合的数据流不能使用排序
//4. 启动流式计算,查询结果表并输出到控制台
val queryResult: StreamingQuery = resultDF.writeStream
.format("console")
.outputMode("update")
.trigger(Trigger.ProcessingTime(1000))
.option("truncate", false)
.start()
queryResult.awaitTermination()
spark.stop()
}
}
===================输出结果
batch 1 到达数据:2019-09-25 12:02:00|A
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 11:55:00, 2019-09-25 12:05:00]|A |1 |
|[2019-09-25 12:00:00, 2019-09-25 12:10:00]|A |1 |
+------------------------------------------+----+-----+
batch 2 到达数据:2019-09-25 12:16:00|B
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 12:15:00, 2019-09-25 12:25:00]|B |1 |
|[2019-09-25 12:10:00, 2019-09-25 12:20:00]|B |1 |
+------------------------------------------+----+-----+
batch 3 到达数据:2019-09-25 12:03:00|C
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 12:00:00, 2019-09-25 12:10:00]|C |1 |
+------------------------------------------+----+-----+
batch 4 到达数据:2019-09-25 12:22:00|D
+------------------------------------------+----+-----+
|window |word|count|
+------------------------------------------+----+-----+
|[2019-09-25 12:20:00, 2019-09-25 12:30:00]|D |1 |
|[2019-09-25 12:15:00, 2019-09-25 12:25:00]|D |1 |
+------------------------------------------+----+-----+
batch 5 到达数据:2019-09-25 12:04:00|E
+------+----+-----+
|window|word|count|
+------+----+-----+
+------+----+-----+
注:timestamp 必须是 Timestamp 类型,或运行在 window 中
-
append 模式下 watermark,把 event-time < watermark 的状态输出,并删除,这些状态以后不会再更新了。
官网:每次只输出紫色部分的数据

理解:Append 模式下,只输出确定不变的数据,如何理解确定不变呢?就是水印时间已经大于某个窗口的时间,后来的数据不会再是这个窗口的数据,即便是,也因为过了水印时间而丢弃,所以这个窗口的数据已经确定,图中紫色部分的数据就满足这样的条件,那么在 Append 模式下,这个窗口的数据就会输出,随着时间的推移,所有时间段的数据都会成为已不变的状态,然后依次输出,更新到数据库。
示例:

// 代码部分:较上面代码,写出时的模式设定改为 append 即可, outputMode("append") ==========输出结果 batch 1 到达数据:2019-09-25 12:02:00|A +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ batch 2 到达数据:2019-09-25 12:16:00|B 水印更新为 12:06:00 则 11:55-12:05 窗口已确定不变,此时输出 +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-09-25 11:55:00, 2019-09-25 12:05:00]|A |1 | +------------------------------------------+----+-----+ batch 3 到达数据:2019-09-25 12:03:00|C 11:55-12:05 窗口已经关闭,C在这个窗口的记录被抛弃,不会输出 +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ batch 4 到达数据:2019-09-25 12:22:00|D 水印更新为 12:12:00 则 12:00-12:10 窗口已确定不变,此时输出 +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-09-25 12:00:00, 2019-09-25 12:10:00]|C |1 | |[2019-09-25 12:00:00, 2019-09-25 12:10:00]|A |1 | +------------------------------------------+----+-----+ batch 4 到达数据:2019-09-25 12:04:00|E 水印为 12:12:00 E数据所在的两个窗口都已关闭,不会输出 +------+----+-----+ E数据相当于完全没有被统计上 |window|word|count| +------+----+-----+ +------+----+-----+ -
关于 watermark 使用的总结
- watermark 必须使用 Update 或 Append 模式,Complete 模式要求保留所有聚合数据,不能使用 watermark 丢弃中间状态的数据。
- watermark 一般情况下要配合 window 使用。
- 聚合必须使用在 event-time 列上,或基于 event-time 的 window 列上。
- 只有 Complete 模式下,被聚合的数据流才能使用排序操作。
- 在 Append 模式下,使用 watermark 的列必须是一个时间戳列,且会被聚合。
- 在 Append 模式下,必须在聚合操作之前使用 watermark。
- 在 Update 模式下,watermark 主要用具过滤过期数据并及时清理过期状态。
- watermark 会在处理当前批次时更新,并且会在处理下个批次时生效。如果节点出现故障,则可能延迟若干批次生效。
4. 流数据去重
对流数据使用 dropDuplicates(“列名”),可以过滤掉某一列数据重复记录,同时也可以配合水印使用。
object DropDuplication {
def main(args: Array[String]): Unit = {
//1. 创建SaprkSeesion
val spark: SparkSession = SparkSession
.builder()
.master("local[*]")
.appName("Watermark")
.getOrCreate()
import spark.implicits._
//2. 从socket读取数据
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
//3. 处理数据 2019-09-25 12:02:00|A,zhangsan
val resultDF: DataFrame = socketDF//
.as[String]
.map(line => {
val splits = line.split("\\|")
val words = splits(1).split(",")
// timestamp 必须是Timestamp类型,或运行在window中
(Timestamp.valueOf(splits(0)), words(0), words(1))
})
.toDF("timestamp", "level", "name")
.withWatermark("timestamp","10 minutes")
.dropDuplicates("name")
resultDF.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
spark.stop()
}
}
=====================输出
batch 1 到达数据:2019-09-25 12:02:00|A,zhangsan
+-------------------+-----+--------+
| timestamp|level| name|
+-------------------+-----+--------+
|2019-09-25 12:02:00| A|zhangsan|
+-------------------+-----+--------+
batch 2 到达数据:2019-09-25 12:19:00|A,lisi
+-------------------+-----+----+
| timestamp|level|name|
+-------------------+-----+----+
|2019-09-25 12:19:00| A|lisi|
+-------------------+-----+----+
batch 3 到达数据:2019-09-25 12:05:00|A,wangwu //水印时间之前:不输出
+---------+-----+----+
|timestamp|level|name|
+---------+-----+----+
+---------+-----+----+
batch 4 到达数据:2019-09-25 12:10:00|A,zhangsan // 水印时间之后,但name重复,不输出
+---------+-----+----+
|timestamp|level|name|
+---------+-----+----+
+---------+-----+----+
注意:
- dropDuplicates 不可用在聚合之后, 即通过聚合得到的 df/ds 不能调用dropDuplicates
- 使用 watermark 在 event-time 上定义水印,可以过滤过时数据。
5. 流数据 Join
-
流数据 Join 静态数据(Stream-StaticJoins)
object StreamJoinStatic { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("StreamJoinStatic") .master("local[*]") .getOrCreate() import spark.implicits._ // 1. 获取静态流(name,age,gender) val staticDF = spark.read .json("D:\\datas\\json") // 2. 获取动态流 val StreamDF: DataFrame = spark.readStream .format("socket") .option("host", "hadoop102") .option("port", 9999) .load() // 处理输入的流式数据 val handleDF: DataFrame = StreamDF.as[String] .map({ line => val splits = line.split(",") (splits(0), splits(1).toInt) }).toDF("name", "score") // 3. Join // StreamDF.join(staticDF) 内连接 val joinResult = handleDF.join(staticDF, Seq("name"), "left") // 左外连接 joinResult.writeStream .format("console") .outputMode("append") .start() .awaitTermination() spark.stop } } ==========输出 batch 1 输入:maben,99 +-----+-----+---+------+ | name|score|age|gender| +-----+-----+---+------+ |maben| 99| 23| male| +-----+-----+---+------+ batch 2 输入:chengfan,100 +--------+-----+---+------+ | name|score|age|gender| +--------+-----+---+------+ |chengfan| 100| 23|famale| +--------+-----+---+------+ -
流数据 Join 流数据(Stream-StreamJoin)
2 个流式数据进行 join 操作。输出模式仅支持append模式
-
内连接,不用watermark
object StreamJoinStream { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("StreamJoinStatic") .master("local[*]") .getOrCreate() import spark.implicits._ // 1. 获取静态流1(name,age,gender) val StreamDF1 = spark.readStream .format("socket") .option("host", "hadoop102") .option("port", 10000) .load() .as[String] .map(line => { val splits = line.split(",") (splits(0), splits(1), splits(2)) }).toDF("name", "age", "gender") // 2. 获取动态流2(name,score) val StreamDF2: DataFrame = spark.readStream .format("socket") .option("host", "hadoop102") .option("port", 9999) .load() .as[String] .map(line => { val splits = line.split(",") (splits(0), splits(1)) }).toDF("name", "score") //3. 流的Join val joinResult = StreamDF1.join(StreamDF2, Seq("name")) // 内连接 joinResult.writeStream .format("console") .outputMode("append") .trigger(Trigger.ProcessingTime(2000)) .start() .awaitTermination() spark.stop() } } 9999端口输入: maben,99 chengfan,100 10000端口输入: maben,23,male chengfan,23,female =====================输出 batch 1 +--------+---+------+-----+ | name|age|gender|score| +--------+---+------+-----+ |chengfan| 23|female| 100| | maben| 23| male| 99| +--------+---+------+-----+ -
内连接,使用watermark
object StreamInnerjoinStream { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("StreamJoinStatic") .master("local[*]") .getOrCreate() import spark.implicits._ // 1. 获取静态流1(name,age,gender) val StreamDF1 = spark.readStream .format("socket") .option("host", "hadoop102") .option("port", 10000) .load() .as[String] .map(line => { val splits = line.split("|") val words = splits(1).split(",") (words(0), words(1), words(2), Timestamp.valueOf(splits(0))) }).toDF("name", "age", "gender", "timestamp") .withWatermark("timestamp", "10 minutes") // 使用水印 // 2. 获取动态流2(name,score) val StreamDF2: DataFrame = spark.readStream .format("socket") .option("host", "hadoop102") .option("port", 9999) .load() .as[String] .map(line => { val splits = line.split("|") val words = splits(1).split(",") (words(0), words(1), Timestamp.valueOf(splits(0))) }).toDF("name", "score", "timestamp") .withWatermark("timestamp", "10 minutes") // 使用水印 //3. 流的Join val joinResult = StreamDF1.join(StreamDF2, Seq("name")) // 内连接 joinResult.writeStream .format("console") .outputMode("append") .trigger(Trigger.ProcessingTime(2000)) .start() .awaitTermination() spark.stop() } } -
外连接,只能使用watermark
// 和内连接代码一致,只需在连接时指定 joinType="left_join"
6. Structured Streaming 不支持的操作
到目前, DF/DS 的有些操作 Structured Streaming DF/DS 还不支持。
- 多个Streaming 聚合(例如在 DF 上的聚合链)目前还不支持
- limit 和取前 N 行还不支持
- distinct 也不支持
- 仅仅支持对 complete 模式下的聚合操作进行排序操作
- 仅支持有限的外连接
- 有些方法不能直接用于查询和返回结果。
-
6.3 Structured Streming 输出
在输出数据时一般要定义以下5个要素:
- 输出格式(format):数据格式类型。
- 输出模式(mode):指定写入输出接收器的内容。
- 输出格式配置(option):输出位置、kafka配置等。
- 触发间隔(trigger):可选择指定触发间隔。
- 检查点位置(checkpoint):对于可以保证端到端容错的某些输出接收器,请指定系统写入所有检查点信息的位置。这应该是与HDFS兼容的容错文件系统中的目录。
1. 输出模式(output mode)
**Append mode(default):**判断某条数据状态不再改变、从而将其输出。没有聚合操作时,每一条新数据的状态都不会改变,直接输出,与 Update mode 一致,有聚合操作时,过期的聚合状态(event-time **Complete mode:**全量输出,整个结果表的数据全部输出,仅支持聚合操作,由于全表输出,使用 watermark 无效。 **Update mode:**只输出更新的内容,适用于输出到数据库更新数据。没有聚合操作时,作用与 Append mode 一致,有聚合操作时,可以基于 watermark 清理过期的状态。 存储输出到目录中 仅仅支持 Append 模式 写入到 kafka 的数据时候应该包含:key(可选),value (必要),topic(可选),如果没有添加 topic option,则 topic 列必须有,Kafka Sink 支持所有输出模式。 使用 Streaming 的方式持续输出 使用 batch 方式输出到 kafka,只写一次就关闭,不是流式处理 该 Sink 与 Console Sink 都用于测试,将统计结果全部输入内中指定的表中,然后可以通过 sql 与从表中查询数据。 如果数据量非常大,可能会发送内存溢出 foreach sink 会遍历表中的每一行,允许将流查询结果按开发者指定的逻辑输出。 需求:将 wordcount 写入到 MySQL 引入驱动依赖 建表语句 ForeachBatch Sink 是 Spark 2.4 才新增的功能,该功能只能用于输出批处理的数据。 微批处理模式虽然实现了严格一次(exactly-once)的语义,但是最低有 100ms 的延迟。 连续处理是 Spark 2.3 引入,它可以实现低至 1ms 的处理延迟,并实现了至少一次(at-least-once)的语义。 连续处理支持的情况: 3 . Once 模式2. 输出管道(output sink)
1. FileSink
/*
把单词和单词的反转组成 json 格式写入到目录中
*/
object FileSink {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("FileSink")
.getOrCreate()
import spark.implicits._
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val words: DataFrame = socketDF.as[String].flatMap(line => {
line.split("\\W+").map(word => {
(word, word.reverse)
})
}).toDF("原单词", "反转单词")
words.writeStream
.outputMode("append")
.format("json")
.option("path", "./filesink") // 输出到当前目录下
.option("checkpointLocation", "./ck1") //必须指定 checkpoint
.start()
.awaitTermination()
spark.stop()
}
}
2. Kafka Sink(常用)
/*
将 wordcount 结果写入到 kafka
*/
object KafkaSink1 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("KafkaSink1")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val words: DataFrame = socketDF.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value")
.count()
.map(row => row.getString(0) + "," + row.getLong(1))
.toDF("value") // 写入kafka时至少有一列 value
words.writeStream
.outputMode("update")
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092")
.option("topic", "topic1")
.option("checkpointLocation", "./ck2") // 必须指定checkpoint
.start()
.awaitTermination()
spark.stop()
}
}
/*
将 wordcount 结果写入到 kafka
*/
object KafkaSink2 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.master("local[*]")
.appName("KafkaSink2")
.getOrCreate()
import spark.implicits._
// 读取文件数据
val words = spark.sparkContext.textFile("D:\\datas\\txt")
.toDS()
.flatMap(_.split("\\W+"))
.groupBy("value") // DS 默认的列名是 value
.count()
.map(row => row.getString(0) + "," + row.getLong(1))
.toDF("value") // 写入kafka时至少有一列 value
words.write
.format("kafka")
.option("kafka.bootstrap.servers", "hadoop102:9092,hadoop103:9092")
.option("topic", "topic1")
.save()
}
}
3. Memory Sink
object MemorySink {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("MemorySink")
.getOrCreate()
import spark.implicits._
val lines: DataFrame = spark.readStream
.format("socket") // 设置数据源
.option("host", "hadoop102")
.option("port", 9999)
.load
val words: DataFrame = lines.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value")
.count()
val query: StreamingQuery = words.writeStream
.outputMode("complete")
.format("memory")
.queryName("word_count") // 内存临时表名
.start()
// 配置一个定时器,定期查询临时表中的数据
val timer = new Timer
val task = new TimerTask {
override def run(): Unit = {
spark.sql("select * from word_count").show()
}
}
timer.scheduleAtFixedRate(task, 0, 2000) // 每两秒查询一次
query.awaitTermination()
spark.stop()
}
}
4. Foreach Sink(常用)
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.27version>
dependency>
create database ss;
use ss;
create table word_count(
word varchar(255) primary key not null,
count bigint not null
);
/*
将 wordcount 写入到 MySQL
*/
object ForeachSink {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("ForeachSink")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val wordCount: DataFrame = socketDF.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value") // DS 中默认的列名为 value
.count()
wordCount.writeStream
.outputMode("update")
.foreach(new ForeachWriter[Row] {
// on duplicate key update 当 key 重复时更新数据
val sql = "insert into word_count values(?, ?) on duplicate key update count=?"
var conn: Connection = _
//1. 连接数据库
override def open(partitionId: Long, epochId: Long): Boolean = { // 返回true,代表连接成功
Class.forName("com.mysql.jdbc.Driver")
conn = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/spark", "root", "maben996")
conn != null && !conn.isClosed
}
//2. 写入数据库
override def process(value: Row): Unit = {
val ps: PreparedStatement = conn.prepareStatement(sql)
ps.setString(1, value.getString(0))
ps.setLong(2, value.getLong(1))
ps.setLong(3, value.getLong(1))
ps.execute()
ps.close()
}
//3. 关闭资源
override def close(errorOrNull: Throwable): Unit = {
if (!conn.isClosed && conn != null) conn.close()
}
})
.start()
.awaitTermination()
spark.stop()
}
}
5. ForeachBatch Sink
/*
将统计结果同时输出到本地文件和 mysql 中
*/
object ForeachBatchSink {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("ForeachBatchSink")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val socketDF: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val wordCount: DataFrame = socketDF.as[String]
.flatMap(_.split("\\W+"))
.groupBy("value") // DS 中默认的列名为 value
.count()
// mysql 配置
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "maben996")
// 写出
wordCount.writeStream
.outputMode("complete")
.foreachBatch((df, batchId) => { // 当前当前批次id对应分区id
if (df.count() != 0) { // 若某个批次/分区内数据为0,就不用写
df.persist() // 做缓存,两次写出只计算一次
df.write.mode("overwrite").jdbc("jdbc:mysql://hadoop102:3306/spark", "word_count", props)
df.write.json(s"./foreachBatch/$batchId") // 同时写出到文件
df.unpersist() // 释放缓存
}
})
.trigger(Trigger.ProcessingTime(1000))
.start()
.awaitTermination()
spark.stop()
}
}
6.4 Trigger 触发器
1. 微批处理模式 ProcessingTime
df.writeStream.trigger(Trigger.ProcessingTime(1 seconds)) // 1 秒触发一次流式计算
2. 连续处理模式 Continuous
df.writeStream.trigger(Trigger.Continuous(1)) // 1 毫秒触发一次流式计算
操作: 支持 select, map, flatMap, mapPartitions, etc. 和 selections (where, filter, etc.)。不支持聚合操作
数据源:kafka source 和 rate source(测试用)
sink:Kafka sink、memorey sink、console sink
df.writeStream.trigger(Trigger.Once()) // 只处理一次,完毕后退出