Hadoop核心组件之HDFS的安装与配置
教程目录
- 0x00 教程内容
- 0x01 Hadoop的获取
- 1. 官网下载
- 2. 添加微信:shaonaiyi888
- 3. 关注公众号:邵奈一
- 0x02 上传安装包到集群
- 1. 上传安装包到虚拟机
- 0x02 安装与配置Hadoop
- 1. 解压Hadoop
- 2. 配置Hadoop
- 3. 同步Hadoop到slave1、slave2
- 4. 校验HDFS
- 0x03 简便配置
- 1. 环境变量配置
- 2. 域名映射配置
- 0xFF 总结
0x00 教程内容
- Hadoop的获取
- 上传安装包到集群
- 安装与配置Hadoop
- 简便配置
0x01 Hadoop的获取
1. 官网下载
a. 为了统一,此处下载Hadoop-2.7.5版本 :
http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/
选择hadoop-2.7.5.tar.gz进行下载
PS:
HDFS、MapReduce、YARN均是Hadoop核心组件,所以均使用Hadoop安装包,然后再配置即可!
2. 添加微信:shaonaiyi888
3. 关注公众号:邵奈一
a. 回复hadoop获取
0x02 上传安装包到集群
1. 上传安装包到虚拟机
a. 可以用XFtp软件上传到master(~/software/)
0x02 安装与配置Hadoop
1. 解压Hadoop
a. 进入安装包路径下:
cd ~/software/
b. 解压hadoop安装包到~/bigdata路径下(如果没有此文件夹,则先创建)
tar -zxvf hadoop-2.7.5.tar.gz -C ~/bigdata/
2. 配置Hadoop
a. 进入hadoop配置文件目录
cd ~/bigdata/hadoop-2.7.5/etc/hadoop/
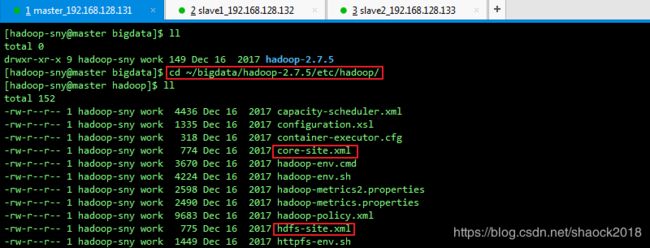
b. 修改配置文件:vi core-site.xml
添加内容:
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9999value>
<description>表示HDFS的基本路径description>
property>

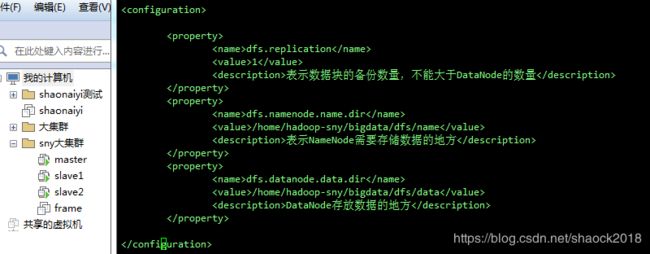
c. 修改配置文件:vi hdfs-site.xml
添加内容:
<property>
<name>dfs.replicationname>
<value>1value>
<description>表示数据块的备份数量,不能大于DataNode的数量description>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop-sny/bigdata/dfs/namevalue>
<description>表示NameNode需要存储数据的地方description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop-sny/bigdata/dfs/datavalue>
<description>DataNode存放数据的地方description>
property>
d. 修改配置文件:vi hadoop-env.sh
修改JAVA_HOME:
export JAVA_HOME=/usr/local/lib/jdk1.8.0_161
![]()
e. 修改配置文件:vi slaves
删除里面的localhost,添加从节点的hostname:
slave1
slave2

f. 创建存放数据的文件夹
mkdir -p ~/bigdata/dfs/name
mkdir -p ~/bigdata/dfs/data
![]()
3. 同步Hadoop到slave1、slave2
a. 在slave1和slave2节点中的hadoop-sny用户下的主目录下创建bigdata目录:
mkdir bigdata
b. 复制master节点上的hadoop主目录到slave1、slave2:
scp -r ~/bigdata/hadoop-2.7.5 hadoop-sny@slave1:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-sny@slave2:~/bigdata
c. 复制master节点上的数据文件目录到slave1、slave2:
scp -r ~/bigdata/dfs hadoop-sny@slave1:~/bigdata
scp -r ~/bigdata/dfs hadoop-sny@slave2:~/bigdata
d. 复制完成后,可以看到slave1、slave2上已经有hadoop了
ls ~/bigdata/


4. 校验HDFS
a. 在master上执行格式化HDFS:
cd ~/bigdata/hadoop-2.7.5/bin
./hdfs namenode -format
b. 执行成功后可以看到格式化成功的字样:

c. 启动HDFS:
cd ../sbin
./start-dfs.sh
d. 查看三台服务器的进程情况:

![]()

PS:发现有进程,已经成功了99%啦!还有1%要上传了文件才知道!
e. 查看Web UI界面
在window用浏览器打开端口(master的ip地址是192.168.128.131)
http://192.168.128.131:50070
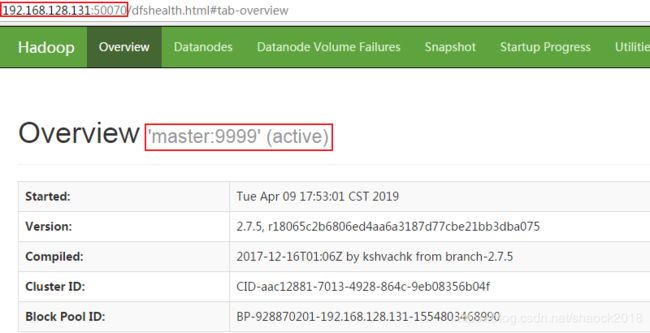
f. 截止,HDFS就已经安装好了,但是,我们还发现了两个问题:
- 启动HDFS的时候,要进入到Hadoop的主目录,比较麻烦
- 访问Web UI的时候要输入ip地址,再加端口号,记住ip地址比较困难
0x03 简便配置
1. 环境变量配置
a. 现在我们想要执行hadoop与start-dfs.sh等命令是要进入到相应的路径才可以执行的,我们可以将相关的路径配置到环境变量
b. 配置master的环境变量(hadoop-sny用户)
vi ~/.bash_profile
export HADOOP_HOME=~/bigdata/hadoop-2.7.5
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

c. 使环境变量生效
source ~/.bash_profile
d. 校验环境变量是否生效
echo $HADOOP_HOME
which hdfs
均有内容输出:

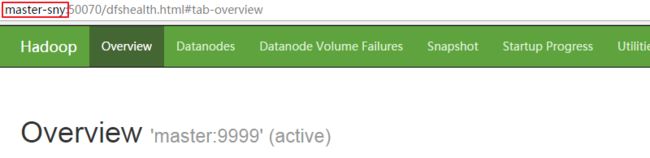
2. 域名映射配置
a. 修改windows的域名映射(与教程:IDEA2018安装与配置 中的道理是一样的
):
C:\Windows\System32\drivers\etc\hosts

b. 配置好后,我们就可以在windows的浏览器上用配置的用户名访问了
0xFF 总结
- 因为之前我们的专栏 复制粘贴玩转大数据系列专栏 用docker安装Hadoop环境时我们没有常规的安装HDFS,所以就补上了这个。
- 感谢您的阅读,我是邵奈一,很高兴认识您。
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
复制粘贴玩转大数据系列专栏 已经更新完成,请跳转学习!