从0到1聊聊kubernetes service 到 pod的网络链路定位
从0到1聊聊kubernetes service 到 pod的网络链路定位
- 导语
- 认识service
- service使用场景
- 1. ClusterTpye
- 2. NodePort
- 3. Headless
- 4. LoadBalancer
- 5. 无标签选择
- service底层实现
- service到pod网络链路示例分析
- 1. 确认当前环境是iptables 或 ipvs
- 2. 获取service ip地址
- 3. 根据service ip 地址追寻pod ip负载均衡
- 参考:
导语
最近一个环境出现pod尚在not ready状态时就开始有业务流量进入;定位此问题也让我进一步加深对kubernetes集群内(service 到 pod)的网络链路的了解。另外当前kubernetes越来越普及,遇到一些关于kubernetes网络问题也会越频繁。本文将从认识kuberneres service 到kubernetes service 使用场景再到kubernetes service底层实现原理,最后通过示例方式展示如何从service到pod网络链路一步步定位分析。
认识service
Service 是 kuberneres将一组Pod暴露给外界访问的一种机制。为什么引入service?直接pod进行交互不行吗?引入service主要原因有二:
- pod 生命周期是短暂的,会随着发布新版本而被销毁,pod ip不固定;
- 一组pod负载均衡需求
而service恰好能通过标签选择器或直接与endpoint关联将一组pod进行绑定做为一组pod的统一入口和提供负载均衡能力。Service 有两种类型:service和Headless Service, Service 通常应用在无状态服务上;Headless Service 则应用在有状态服务。Service和Headless Service有什么区别呢?Service 和 Headless Service主要有如下表象区别:
- service 有一个cluster ip(虚拟ip)作为一组pod的统一入口,而headless service 则没有这个cluster ip;
- 通过service 名访问时,coredns或者kubedns会解析到service的vip地址,而headless service 则通常需要headless service 名前加上pod_name,有状态服务pod_name 都会带编号,这样coredns或者kubedns就可以直接解析到具体的pod实例。
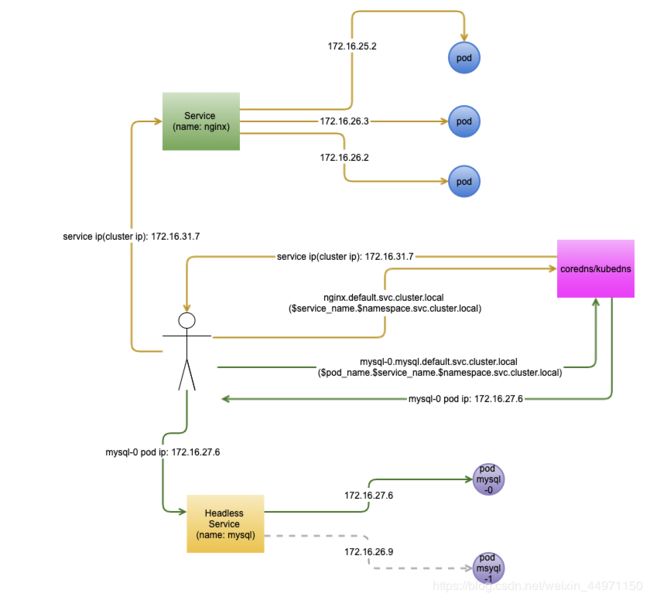
为什么有了service还需要引入headless service呢?引入headless service为了解决有状态服务既要解决pod ip不固定并且还需要固定访问具体的pod(mysql 的主或者备)的问题。service 会采用负载均衡的方式引流到后端,无法固定;而headless service 通过结合coredns/kubedns解析后直接对接具体的pod。上面聊了这么多,接下来看看Service面纱背后面目:
apiVersion: v1
kind: Service # 定义当前kuernetes资源类型为Service
metadata:
name: my-service # service 名称
spec:
selector: # 标签选择器与一组pod进行绑定
app: MyApp # Pod上定义的一组标签
ports:
- protocol: TCP # 对外暴露的协议
port: 80 # service 的端口
targetPort: 9376 # pod监听端口
上面是通常使用的Service定义,那headless service又如何定义?其实只需要spec.clusterIP值设置为"None" 即可。
service使用场景
对Service有了一定认识,接下来聊聊Service的使用场景。
1. ClusterTpye
clusterType 场景很普遍,通常集群内通信几乎均采用clusterType类型场景;clusterType类型会创建一个虚拟ip地址作为一组pod的统一入口以及负载均衡。例子:
apiVersion: v1
kind: Service
metadata:
labels:
app: kibana
heritage: Tiller
release: kibana
name: kibana-kibana
namespace: default
spec:
ports:
- name: http # 当一个service需要对外暴露多个端口时,需要加名称加以区分
port: 5601
protocol: TCP
targetPort: 5601
selector:
app: kibana
release: kibana
sessionAffinity: None # 默认时rr(round-robin轮询),可以设置为: ClientIP,基于客户端ip的会话保持类似ha的source ip,nginx的ip_hash
type: ClusterIP # 定义为cluster Type类型的service,ClusterIP也是默认的service类型
通过使用
kubectl get svc $SERVICE_NAME -n $NAME_SPACES
[root@VM_70_26_centos ~]# kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-master ClusterIP 172.x.y.127 9200/TCP,9300/TCP 6d6h
elasticsearch-master-headless ClusterIP None 9200/TCP,9300/TCP 6d6h
kafka ClusterIP 172.x.y.142 9092/TCP 6d6h
kafka-headless ClusterIP None 9092/TCP 6d6h
kafka-manager ClusterIP 172.x.y.198 9000/TCP 6d6h
kafka-zookeeper ClusterIP 172.x.y.86 2181/TCP 6d6h
kafka-zookeeper-headless ClusterIP None 2181/TCP,3888/TCP,2888/TCP 6d6h
kibana-kibana ClusterIP 172.x.y.143 5601/TCP 6d6h
获取当前namespace下的service 列表. 使用
kubectl describe svc $SERVICE_NAME -n $NAME_SPACES
[root@VM_70_26_centos ~]# kubectl describe svc kibana-kibana -n pot
Name: kibana-kibana
Namespace: pot
Labels: app=kibana
heritage=Tiller
release=kibana
Annotations:
Selector: app=kibana,release=kibana
Type: ClusterIP
IP: 172.x.y.143
Port: http 5601/TCP
TargetPort: 5601/TCP
Endpoints: 172.x.z.8:5601 # pod ip+port
Session Affinity: None
Events:
查看service事件信息。使用
kubectl get svc $SERVICE_NAME -n $NAME_SPACES -o yaml
查看当前service配置内容。
2. NodePort
当一组pod需要跨集群或需要提供集群外访问能力时可以采用NodePort模式,使用NodePort方式会在集群内所有节点占用一个宿主机端口(默认值:30000-32767),可以通过–service-node-port-range设置端口范围段,为此使用此场景需要注意端口规划;访问时直接访问kubernetes集群中任意节点IP+映射的宿主机端口即可。
apiVersion: v1
kind: Service
labels:
app: kibana
heritage: Tiller
release: kibana
name: kibana-kibana
namespace: default
spec:
- name: http
port: 5601
protocol: TCP
targetPort: 5601
selector:
app: kibana
release: kibana
sessionAffinity: None
type: NodePort # 只需要将type 类型改为NodePort即可。
3. Headless
Headless service 主要应用在statefulset(有状态服务),对于有状态服务有的需要固定访问,比如mysql主从模式时需要写的时候通过service 访问时候不能轮训模式,因为只有主节点可以写,这时候就需要headless service,通过访问$pod_name.$headless_service_name.$namespace.svc.cluster.local coredns/kubedns就会将此域名解析到具体的pod ip实现固定访问。
apiVersion: v1
kind: Service
metadata:
labels:
app: kibana
heritage: Tiller
release: kibana
name: kibana-kibana
namespace: default
spec:
clusterIP: None # 只需要将clusterIP设置为None即可
ports:
- name: http
port: 5601
protocol: TCP
targetPort: 5601
selector:
app: kibana
release: kibana
sessionAffinity: None
type: ClusterIP
4. LoadBalancer
当一组pod需要跨集群或需要提供集群外访问除了上述提到的NodePort方式,还可以对接IaaS层的负载均衡器,当然这个是需要编写对应的driver实现注册到IaaS的LoadBalancer,这种场景在云上(腾讯云,阿里云,华为云,ucloud等)已经做好了集成;不同厂商需要添加的annotations不一样,annotations届时看所应用的厂商配置说明即可,但根还是一样的。这种方式就解决了NodePort端口规划以及当某个节点异常了也会导致统一入口的高可用问题。以下annotations 以腾讯云tke为例:
apiVersion: v1
kind: Service
metadata:
annotations: # annotations 部分需要根据不同厂商而定
service.kubernetes.io/loadbalance-id: lb-xxx
service.kubernetes.io/qcloud-loadbalancer-clusterid: cls-xxx
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid: subnet-xxx
labels:
app: kibana
heritage: Tiller
release: kibana
name: kibana-kibana
namespace: default
spec:
ports:
- name: http
port: 5601
protocol: TCP
targetPort: 5601
selector:
app: kibana
release: kibana
sessionAffinity: None
type: LoadBalancer # 将类型设置为LoadBalancer 即可。
5. 无标签选择
kubernetes集群需要对接一些外部的服务,比如mysql,redis等,此时无标签选择场景就很适合使用。此场景使用分两步走,第一步先创建endpoints, 然后再创建没有标签选择的service,这种service是一种特殊的service。这样就解决了集群内的服务通过service即可访问集群外的服务。
定义endpoints:
apiVersion: v1
kind: Endpoints
metadata:
name: my-service # 注意Endpoints 需要和service的名称保持一致
subsets:
- addresses:
- ip: 192.0.2.42 # 外部服务IP地址,这是一个数组
ports:
- port: 9376 # 外部服务端口
定义service
apiVersion: v1
kind: Service
metadata:
name: my-service # 注意service 需要和Endpoints的名称保持一致
spec:
ports:
- protocol: TCP
port: 80 # service 端口
targetPort: 9376 # 外部服务端口
无标签选择场景还有一种特殊的使用externalName。
service底层实现
从认识到使用,那service到底是如何实现?实际上,Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。举个例子,对于如下创建的名叫 elasticsearch-master 的 Service 来说,一旦它被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它),如下所示::
[root@VM_197_156_centos /data/helms/business]# kubectl get svc -n pot
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-master ClusterIP 172.16.31.63 9200/TCP,9300/TCP 5d20h
elasticsearch-master-headless ClusterIP None 9200/TCP,9300/TCP 5d20h
kibana-kibana ClusterIP 172.16.31.144 5601/TCP 5d20h
nginx-ingress-nginx-ingress ClusterIP 172.16.31.177 80/TCP,443/TCP 5d20h
sgikes-sg-helm ClusterIP 172.16.31.73 5601/TCP 5d17h
sgikes-sg-helm-clients ClusterIP 172.16.31.141 9200/TCP,9300/TCP 5d17h
sgikes-sg-helm-discovery ClusterIP 172.16.31.50 9300/TCP 5d17h
[root@VM_197_156_centos ~]# iptables-save | grep 172.16.31.63
-A KUBE-SERVICES -d 172.16.31.63/32 -p tcp -m comment --comment "pot/elasticsearch-master:transport cluster IP" -m tcp --dport 9300 -j KUBE-SVC-B3S4WZAGNU4F7PKP
-A KUBE-SERVICES -d 172.16.31.63/32 -p tcp -m comment --comment "pot/elasticsearch-master:http cluster IP" -m tcp --dport 9200 -j KUBE-SVC-HXMF37AORSHYWP2V
可以看到,这条 iptables 规则的含义是:凡是目的地址是 172.16.31.63、目的端口是 9200 的 IP 包,都应该跳转到另外一条名叫KUBE-SVC-HXMF37AORSHYWP2V 的 iptables 链进行处理。而我们前面已经看到,172.16.31.63 正是这个 Service 的 VIP。所以这一条规则,就为这个 Service 设置了一个固定的入口地址。并且,由于 172.16.31.63 只是一条 iptables 规则上的配置,并没有真正的网络设备,所以你 ping 这个地址,是不会有任何响应的。那么,我们即将跳转到的 KUBE-SVC-HXMF37AORSHYWP2V 规则,又有什么作用呢?实际上,它是一组规则的集合,如下所示:
-A KUBE-SVC-HXMF37AORSHYWP2V -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-5CBHBRMC3HLKEFQM
-A KUBE-SVC-HXMF37AORSHYWP2V -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-FUG6U5TLAHSW77BL
-A KUBE-SVC-HXMF37AORSHYWP2V -j KUBE-SEP-KT57KYP65COAGJLX
可以看到,这一组规则,实际上是一组随机模式(–mode random)的 iptables 链。而随机转发的目的地,分别是 KUBE-SEP-5CBHBRMC3HLKEFQM、KUBE-SEP-FUG6U5TLAHSW77BL 和 KUBE-SEP-KT57KYP65COAGJLX。而这三条链指向的最终目的地,其实就是这个 Service 代理的三个 Pod。所以这一组规则,就是 Service 实现负载均衡的位置。需要注意的是,iptables 规则的匹配是从上到下逐条进行的,所以为了保证上述三条规则每条被选中的概率都相同,我们应该将它们的 probability 字段的值分别设置为 1/3(0.333…)、1/2 和 1。这么设置的原理很简单:第一条规则被选中的概率就是 1/3;而如果第一条规则没有被选中,那么这时候就只剩下两条规则了,所以第二条规则的 probability 就必须设置为 1/2;类似地,最后一条就必须设置为 1。你可以想一下,如果把这三条规则的 probability 字段的值都设置成 1/3,最终每条规则被选中的概率会变成多少。
通过查看上述三条链的明细,我们就很容易理解 Service 进行转发的具体原理了,如下所示:
-A KUBE-SEP-5CBHBRMC3HLKEFQM -s 172.16.0.18/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-5CBHBRMC3HLKEFQM -p tcp -m tcp -j DNAT --to-destination 172.16.0.18:9200
-A KUBE-SEP-FUG6U5TLAHSW77BL -s 172.16.1.8/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-FUG6U5TLAHSW77BL -p tcp -m tcp -j DNAT --to-destination 172.16.1.8:9200
-A KUBE-SEP-KT57KYP65COAGJLX -s 172.16.2.7/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-KT57KYP65COAGJLX -p tcp -m tcp -j DNAT --to-destination 172.16.2.7:9200
可以看到,这三条链,其实是三条 DNAT 规则。但在 DNAT 规则之前,iptables 对流入的 IP 包还设置了一个“标志”(通过KUBE-MARK-MASQ链设置–set-xmark)。这个“标志”的作用对于符合条件的包 set mark 0x4000, 有此标记的数据包会在KUBE-POSTROUTING chain中统一做MASQUERADE为SNAT做准备 。而 DNAT 规则的作用,就是在 PREROUTING 检查点之前,也就是在路由之前,将流入 IP 包的目的地址和端口,改成–to-destination 所指定的新的目的地址和端口。可以看到,这个目的地址和端口,正是被代理 Pod 的 IP 地址和端口。这样,访问 Service VIP 的 IP 包经过上述 iptables 处理之后,就已经变成了访问具体某一个后端 Pod 的 IP 包了。不难理解,这些 Endpoints 对应的 iptables 规则,正是 kube-proxy 通过监听 Pod 的变化事件,在宿主机上生成并维护的。
以上,就是 Service 最基本的工作原理。
此外,你可能已经听说过,Kubernetes 的 kube-proxy 还支持一种叫作 IPVS 的模式。这又是怎么一回事儿呢?
其实,通过上面的讲解,你可以看到,kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。
不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
而 IPVS 模式的 Service,就是解决这个问题的一个行之有效的方法。
IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址,如下所示:
[root@VM_27_156_centos ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hpa-metrics-service ClusterIP 172.16.159.69 443/TCP 83d
kube-dns ClusterIP 172.16.158.116 53/TCP,53/UDP 83d
[root@VM_27_156_centos ~]# ip ad | grep ipv
4: kube-ipvs0: ,NOARP> mtu 1500 qdisc noop state DOWN
inet 172.16.159.69/32 brd 172.16.159.69 scope global kube-ipvs0
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示:
[root@VM_27_156_centos ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 127.0.0.1:30762 rr
-> 172.16.128.181:80 Masq 1 0 0
TCP 127.0.0.1:31017 rr
-> 172.16.128.239:80 Masq 1 0 0
TCP 127.0.0.1:31244 rr
-> 172.16.129.7:1358 Masq 1 0 0
TCP 172.16.128.129:30263 rr
TCP 172.16.128.129:30344 rr
-> 172.16.128.196:80 Masq 1 0 0
可以看到,这三个 IPVS 虚拟主机的 IP 地址和端口,对应的正是三个被代理的 Pod。
这时候,任何发往 172.16.128.181:80 的请求,就都会被 IPVS 模块转发到某一个后端 Pod 上了。
而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。这也正印证了我在前面提到过的,“将重要操作放入内核态”是提高性能的重要手段。
不过需要注意的是,IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
所以,在大规模集群里,我非常建议你为 kube-proxy 设置–proxy-mode=ipvs 来开启这个功能。它为 Kubernetes 集群规模带来的提升,还是非常巨大的。
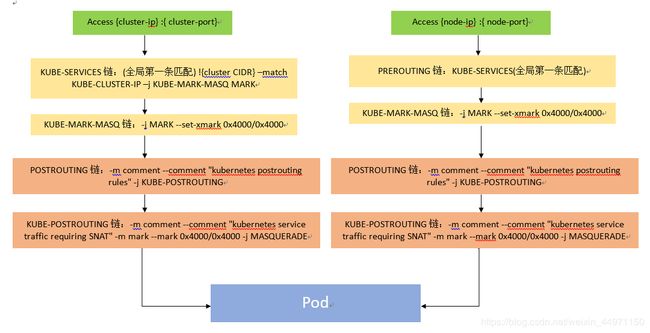
原理已介绍完毕,接下来看下大概的流量流程图, 如下图所示:
service到pod网络链路示例分析
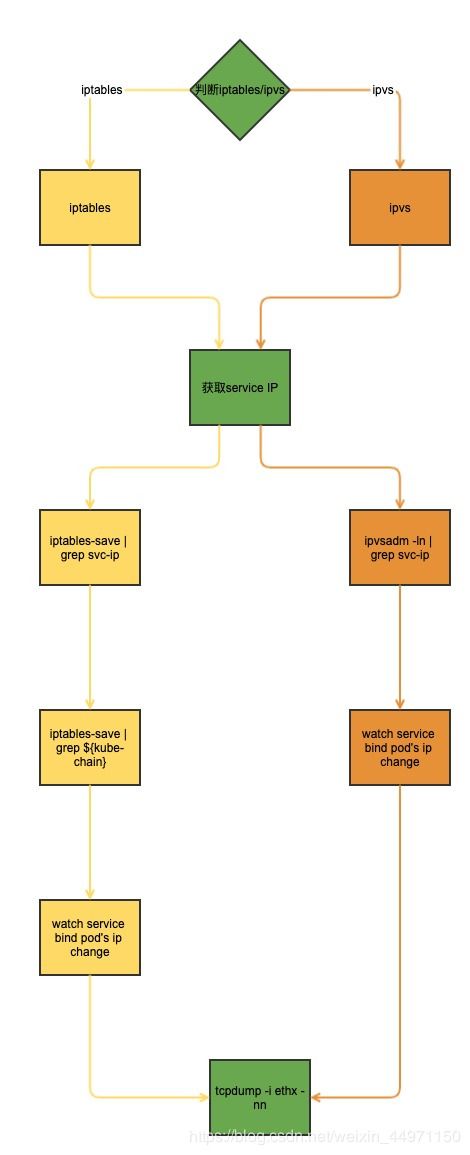
原理已掌握,那如何配合原理解决实际问题?下图是service 到 pod 网络链路分析的流程图:
接下来通过pod尚在not ready状态时就开始有业务流量进入例子实战分析。
1. 确认当前环境是iptables 或 ipvs
通过查看kube-proxy 配置文件确认是否开启ipvs:
# 开启ipvs
[root@VM_27_156_centos ~]# cat /etc/kubernetes/kube-proxy
MASQUERADE_ALL="--masquerade-all=true"
IPVS_SCHEDULER="--ipvs-scheduler=rr" # ipvs 负载均衡策略
IPVS_MIN_SYNC_PERIOD="--ipvs-min-sync-period=1s"
HOSTNAME_OVERRIDE="--hostname-override=1x.x.x.y"
KUBECONFIG="--kubeconfig=/etc/kubernetes/kubeproxy-kubeconfig"
IPVS_SYNC_PERIOD="--ipvs-sync-period=5s"
V="--v=2"
PROXY_MODE="--proxy-mode=ipvs" # 启动了ipvs,若是iptables则不会有这个设置
# 使用iptables
[root@VM_24_43_centos ~]# cat /etc/kubernetes/kube-proxy
V="--v=2"
HOSTNAME_OVERRIDE="--hostname-override=10.26.24.43"
KUBECONFIG="--kubeconfig=/etc/kubernetes/kubeproxy-kubeconfig"
kube-proxy 配置文件不一定是在/etc/kubernetes/目录下,也有可能直接通过configmap方式挂载,为此通过kube-proxy 配置文件查看需要根据实际情况找到kube-proxy配置文件。有没有更快速方法确定到底使用的是ipvs还是iptables呢? 当然有,其实只需要通过iptables-save命令查看即可快速确认是否采用哪种模式。如下所示:
# 使用iptables
...
-A KUBE-SVC-WXR6WDM6ASCPSYWK -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ZVKDBRHJUGWWPSCX
-A KUBE-SVC-WXR6WDM6ASCPSYWK -j KUBE-SEP-3NB7RG36OMJ2OTYG
-A KUBE-SVC-WYEU5GYTOACWWH2H -j KUBE-SEP-RZOYF7X4QTGHRIUZ
-A KUBE-SVC-WYPG2HFD6NQWUD3O -m statistic --mode random --probability 0.25000000000 -j KUBE-SEP-ZN4XLDVG3UXF3BYX
-A KUBE-SVC-WYPG2HFD6NQWUD3O -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-YQSJFJLDPNMWWAG2
-A KUBE-SVC-WYPG2HFD6NQWUD3O -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-EMAQR5ULITZF3NZ3
-A KUBE-SVC-WYPG2HFD6NQWUD3O -j KUBE-SEP-GRJIGAH5VYJMAB5G
-A KUBE-SVC-WYQJ3DTTDOGESYBK -j KUBE-SEP-6AJEHI5DMIZPR5MF
...
若采用了iptables模式的service一般都带以上这些iptables 规则。
# 使用ipvs
A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
-A KUBE-SERVICES -m comment --comment "Kubernetes service lb portal" -m set --match-set KUBE-LOAD-BALANCER dst,dst -j KUBE-LOAD-BALANCER
-A KUBE-SERVICES -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
-A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT
ipvs 并没有类似iptables 那样关于pod相关的iptables规则,并且ipvs的iptables 规则很精简,通常就包含了一些主要的链相关的iptables规则设置。
2. 获取service ip地址
获取service ip地址是为了通过iptables-save命令/ipvsadm 命令查看当前kube 自定义链(KUBE-SERVICE或KUBE_NODEPORT等)链与pod ip 负载均衡的相关规则。
# iptables 模式
[root@VM_197_156_centos ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
log-test-svc ClusterIP 172.16.31.250 80/TCP 38s
# ipvs 模式
[root@VM_27_156_centos /data/cyh]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
log-test-svc ClusterIP 172.16.153.144 80/TCP 9s
3. 根据service ip 地址追寻pod ip负载均衡
我们先来看iptables 模式下的iptables 负载均衡:
[root@VM_197_156_centos ~]# iptables-save | grep 172.16.31.250
-A KUBE-SERVICES -d 172.16.31.250/32 -p tcp -m comment --comment "default/log-test-svc:tcp-80-80 cluster IP" -m tcp --dport 80 -j KUBE-SVC-AQE36IJ35YYI2EX3
# 根据service ip 可以获取到service ip 下一跳的 iptables 链 KUBE-SVC-AQE36IJ35YYI2EX3, 我们再根据KUBE-SVC-AQE36IJ35YYI2EX3 链即可找到pod ip 目标 iptables 规则:
[root@VM_197_156_centos ~]# iptables-save | grep KUBE-SVC-AQE36IJ35YYI2EX3
:KUBE-SVC-AQE36IJ35YYI2EX3 - [0:0]
-A KUBE-SERVICES -d 172.16.31.250/32 -p tcp -m comment --comment "default/log-test-svc:tcp-80-80 cluster IP" -m tcp --dport 80 -j KUBE-SVC-AQE36IJ35YYI2EX3
-A KUBE-SVC-AQE36IJ35YYI2EX3 -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-3UCY2DW22C7NZ2EC
-A KUBE-SVC-AQE36IJ35YYI2EX3 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-5DWF3POVR3KORS2S
-A KUBE-SVC-AQE36IJ35YYI2EX3 -j KUBE-SEP-V3THYN75ZNVYIPX6
从以上结果我们可以看到service 的下一跳链对应的pod 链负载均衡模式以及流量的负载的比例;我们再根据具体的pod的链查看pod 链的明细,比如KUBE-SEP-3UCY2DW22C7NZ2EC的明细:
[root@VM_197_156_centos ~]# iptables-save | grep KUBE-SEP-3UCY2DW22C7NZ2EC
:KUBE-SEP-3UCY2DW22C7NZ2EC - [0:0]
-A KUBE-SEP-3UCY2DW22C7NZ2EC -s 172.16.0.27/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-3UCY2DW22C7NZ2EC -p tcp -m tcp -j DNAT --to-destination 172.16.0.27:80
-A KUBE-SVC-AQE36IJ35YYI2EX3 -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-3UCY2DW22C7NZ2EC
其实当定位pod 尚处于 not ready状态时就有流量进入只需要到service 的下一跳链即可,无需查看pod明细链,因为service 的下一跳链 的明细我们就可以观察当新的pod处于ready状态时薪的负载规则的创建和旧的pod负载规则删除。
定位pod尚处于not ready 状态就有流量进入问题,需要注意将健康检查时间的initialDelaySeconds参数设置足够长时间比如:180,用来准备观察操作,比如新pod 访问日志以及service 下一跳链变化wathc,当然服务副本数设置为1更有利于定位分析。
比如:
测试服务健康检查设置:
livenessProbe:
failureThreshold: 2
initialDelaySeconds: 180
periodSeconds: 3
successThreshold: 1
httpGet:
port: 80
path: /
timeoutSeconds: 2
readinessProbe:
failureThreshold: 2
initialDelaySeconds: 180
periodSeconds: 3
successThreshold: 1
httpGet:
port: 80
path: /
timeoutSeconds: 2
我们改变下deployment一个配置,比如健康检查时间或者镜像什么的用来触发新版本pod的创建:
[root@VM_197_156_centos ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
log-test-6c4dd57c6d-jdcbs 0/1 Running 0 4s
log-test-f99d7d6fb-h7947 1/1 Running 0 2m28s
已经触发新版本创建,接下来我们观察新版pod的访问日志:
[root@VM_197_156_centos ~]# kubectl exec -ti log-test-6c4dd57c6d-jdcbs /bin/bash
root@log-test-6c4dd57c6d-jdcbs:/# cd /data/logs/nginx/logs/
root@log-test-6c4dd57c6d-jdcbs:/data/logs/nginx/logs# ls
access.log error.log
root@log-test-6c4dd57c6d-jdcbs:/data/logs/nginx/logs# tail -f access.log
此时暂时没有流量进入新pod。
观察service 下一跳链的iptables规则变化:
[root@VM_197_156_centos ~]# for i in {1..10000}; do iptables-save | grep KUBE-SVC-AQE36IJ35YYI2EX3 && sleep 1 ;done
:KUBE-SVC-AQE36IJ35YYI2EX3 - [0:0]
-A KUBE-SERVICES -d 172.16.31.250/32 -p tcp -m comment --comment "default/log-test-svc:tcp-80-80 cluster IP" -m tcp --dport 80 -j KUBE-SVC-AQE36IJ35YYI2EX3
-A KUBE-SVC-AQE36IJ35YYI2EX3 -j KUBE-SEP-EDYWNHLXPB6XYTC5
当新pod处于ready状态后,可以发现新pod有访问日志,另外service 下一跳链的iptables规则也发生了变更:
[root@VM_197_156_centos ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
log-test-6c4dd57c6d-jdcbs 1/1 Running 0 3m01s
log-test-f99d7d6fb-h7947 1/1 Terminating 0 5m25s
root@log-test-6c4dd57c6d-jdcbs:/data/logs/nginx/logs# tail -f access.log
{"time_local":"2020-06-14T09:54:12+00:00","client_ip":"","remote_addr":"x.x.199.56","remote_user":"","request":"GET / HTTP/1.1","status":"200","body_bytes_sent":"612","request_time":"0.000","http_referrer":"","http_user_agent":"kube-probe/1.16","request_id":"8d4d649f5cd7551ca7173c96e967b0fb"}
...
[root@VM_197_156_centos ~]# for i in {1..10000}; do iptables-save | grep KUBE-SVC-AQE36IJ35YYI2EX3 && sleep 1 ;done
:KUBE-SVC-AQE36IJ35YYI2EX3 - [0:0]
-A KUBE-SERVICES -d 172.16.31.250/32 -p tcp -m comment --comment "default/log-test-svc:tcp-80-80 cluster IP" -m tcp --dport 80 -j KUBE-SVC-AQE36IJ35YYI2EX3
-A KUBE-SVC-AQE36IJ35YYI2EX3 -j KUBE-SEP-EDYWNHLXPB6XYTC5
...
:KUBE-SVC-AQE36IJ35YYI2EX3 - [0:0]
-A KUBE-SERVICES -d 172.16.31.250/32 -p tcp -m comment --comment "default/log-test-svc:tcp-80-80 cluster IP" -m tcp --dport 80 -j KUBE-SVC-AQE36IJ35YYI2EX3
-A KUBE-SVC-AQE36IJ35YYI2EX3 -j KUBE-SEP-MCLJ6WU2SKYADXJ3
接下来再看看ipvs负载均衡:
[root@VM_27_156_centos /data/cyh]# ipvsadm -ln | grep 172.16.153.144
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
...
TCP 172.16.153.144:80 rr
-> 172.16.128.185:80 Masq 1 0 0
-> 172.16.128.241:80 Masq 1 0 0
-> 172.16.129.16:80 Masq 1 0 0
...
[root@VM_27_156_centos /data/cyh]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
log-test-5cbd4bc5d5-db7ws 1/1 Running 0 38m 172.16.128.241 10.x.x.y
log-test-5cbd4bc5d5-j6jln 1/1 Running 0 38m 172.16.128.185 10.x.x.k
log-test-5cbd4bc5d5-tp2lq 1/1 Running 0 62m 172.16.129.16 10.x.x.z
我们可以发现service ip 172.16.153.144:80 通过rr 也就是轮询模式负载了172.16.128.241,172.16.128.185,172.16.129.16。对于pod尚在not ready 定位观察新pod的访问日志以及健康检查设置和iptables 类似,只不过观察service ip负载均衡pod ip 列表变化转化为通过ipvsadm -ln | grep ${service-ip} , 在这不在赘述。
tcpdump 命令我们可以用来定位流量,不过这个建议跨节点访问抓包,定位ipvs 模式下pod 处于Terminating 状态是否存在流量进入,我们可以通过如下操作进行定位:
[root@VM_27_156_centos /data/cyh]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
log-test-6c7d8575d5-59jk8 0/1 Running 0 87s 172.16.129.20 1x.x.27.165
log-test-cf8cf596f-nk52d 1/1 Running 0 10m 172.16.128.186 1x.x.27.156
log-test-cf8cf596f-npc8h 1/1 Running 0 10m 172.16.128.242 1x.x.27.146
log-test-cf8cf596f-rbvcb 1/1 Running 0 4m37s 172.16.129.19 1x.x.27.165
通过访问服务的service ip 测试pod 负载均衡情况:
for i in {1..10000};do curl -s -v http://172.16.153.144/ && sleep 1;done
针对不在当前节点的pod ip进行抓包:
tcpdump -i eth1 -nn host 172.16.129.19
18:40:13.921362 IP 1x.x.27.156.45606 > 172.16.129.19.80: Flags [.], ack 851, win 261, options [nop,nop,TS val 4271317408 ecr 3695053014], length 0
18:40:13.921551 IP 1x.x.27.156.45606 > 172.16.129.19.80: Flags [F.], seq 79, ack 851, win 261, options [nop,nop,TS val 4271317408 ecr 3695053014], length 0
18:40:13.921657 IP 172.16.129.19.80 > 1x.x.27.156.45606: Flags [F.], seq 851, ack 80, win 57, options [nop,nop,TS val 3695053014 ecr 4271317408], length 0
18:40:13.921681 IP 1x.x.27.156.45606 > 172.16.129.19.80: Flags [.], ack 852, win 261, options [nop,nop,TS val 4271317409 ecr 3695053014], length 0
查看当前ipvs service 负载列表变化情况:
for i in {1..10000};do ipvsadm -ln | grep 172.16.153.144 -A 5 && sleep 1; done
TCP 172.16.153.144:80 rr
-> 172.16.128.186:80 Masq 1 0 41
-> 172.16.128.242:80 Masq 1 0 40
-> 172.16.129.19:80 Masq 1 0 41
...
改变deployment触发新版变更:
[root@VM_27_156_centos /data/cyh]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
log-test-6c7d8575d5-59jk8 1/1 Running 0 2m30s 172.16.129.20 1x.x.27.165
log-test-6c7d8575d5-xr6j7 0/1 Running 0 27s 172.16.128.243 1x.x.27.146
log-test-cf8cf596f-nk52d 1/1 Running 0 11m 172.16.128.186 1x.x.27.156
log-test-cf8cf596f-npc8h 1/1 Running 0 11m 172.16.128.242 1x.x.27.146
log-test-cf8cf596f-rbvcb 1/1 Terminating 0 5m40s 172.16.129.19 1x.x.27.165
当抓包的Pod 处于Terminating 查看抓包是否还有流量?并且ipvs service 的负载均衡该pod ip 流量权重已变为0:
TCP 172.16.153.144:80 rr
-> 172.16.128.186:80 Masq 1 0 40
-> 172.16.128.242:80 Masq 1 0 40
-> 172.16.129.19:80 Masq 0 0 13
-> 172.16.129.20:80 Masq 1 0 27
至此已从初识service, service 应用场景,service实现原理到实战分析讲解完毕。
参考:
kubernetes-official-Services
k8s集群中ipvs负载详解
K8s网络实战分析之service调用
理解kubernetes环境的iptables
kubernetes-source-code-ipvs-kube-proxy
kubernetes-source-code-iptables-kube-proxy