针对豆瓣TOP前250电影做的简单的数据分析~
·~~~~~~内容参考如下使用python抓取豆瓣top250电影数据进行分析 - 简书
https://www.jianshu.com/p/720b193a5c2b
#导入库,三大常用数据分析库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
#读取保存本地的excel文件,我的存放地址就是当前文件夹打印出来
a = pd.read_excel(r'豆瓣电影top250.xls')
#设置每行内容太多,不换行,方便
pd.set_option('expand_frame_repr', False)
#输出查看使用a.head()进行,我这边head函数失效,不知道什么原因,下面统一用print打印出来。
print(a)

右边还有好多内容放不下。。。。。
#查看数据基本信息
a.info()
#查看是否有重复电影
a.duplicated().value_counts()
print(a)
#检查是否有重名电影
len(a.电影名.unique())
#筛选电影的国家或地区,有多个国家或地区时,按顺序并列
country = a['国家'].str.split(' ').apply(pd.Series)
print(country)

这是显示的数据类型

#将空值 NaN 替换为“0”,再按行汇总
all_country = country.apply(pd.value_counts).fillna('0')
all_country.columns = ['area1','area2','area3','area4']
all_country['area1'] = alall_country = country.apply(pd.value_counts).fillna('0')
all_country.columns = ['area1','area2','area3','area4']
all_country['area1'] = all_country['area1'].astype(int)
all_country['area2'] = all_country['area2'].astype(int)
all_country['area3'] = all_country['area3'].astype(int)
all_country['area4'] = all_country['area4'].astype(int)
#计算每个国家或地区制作电影总数并进行排序
all_country['all_counts'] = all_country['area1']+all_country['area2']+all_country['area3']+all_country['area4']
#降序,在这里加了一个inplace,将本体覆盖,默认的inplace为False,改为True,才能有效排序
all_country.sort_values(['all_counts'],ascending=False,inplace=True)
all_country.head()
print(all_country)
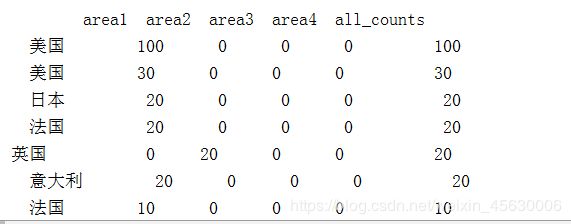
国家按照作品总数降序
#同样对电影类型进行分析
type = a['类型'].str.split(' ').apply(pd.Series)
print(type )
#将空值 NaN 替换为“0”,再按行汇总
all_type = type.apply(pd.value_counts).fillna('0')
all_type.columns = ['type1','type2','type3','type4']
all_type['type1'] = alall_type = type.apply(pd.value_counts).fillna('0')
all_type.columns = ['type1','type2','type3','type4']
all_type['type1'] = all_type['type1'].astype(int)
all_type['type2'] = all_type['type2'].astype(int)
all_type['type3'] = all_type['type3'].astype(int)
all_type['type4'] = all_type['type4'].astype(int)
all_type['all_counts'] = all_type['type1']+all_type['type2']+all_type['type3']+all_type['type4']
all_type = all_type.sort_values(['all_counts'],ascending=False )
all_type.head()
print(all_type)
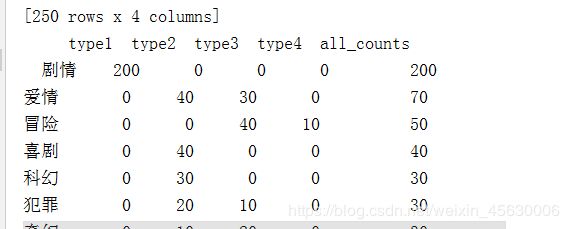
#去掉空值,这一步可不加
all_type = all_type.unstack().dropna().reset_index()
print(all_type)
#画图电影排名和评分的关系
#配置中文字体和修改字体大小
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 20
plt.figure(figsize=(20,5))
plt.subplot(1,2,1)
plt.scatter(a['评分'],a['豆瓣排名'])
plt.xlabel('movie_score')
plt.ylabel('movie rank')
#修改y轴为倒序
plt.gca().invert_yaxis()
#集中趋势的直方图
plt.subplot(1,2,2)
plt.show()
plt.hist(a['评分'],bins=15)
plt.show()
#电影排名和评分的相关性检测
a['评分'].corr(a['豆瓣排名'])
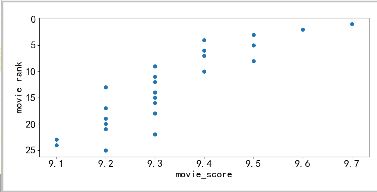
结果很清晰,分数越高,排名越高
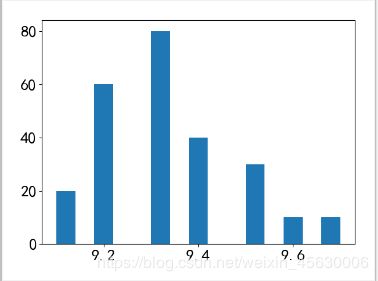
这是数量和评分的直方图,电影数量集中在9.2~9.4分,大约有180部,对比我参考的那篇分析中,那篇分析是2018年2月,过去了两年多,电影总体评分高了很多,说明这一两年有很多新的高分作品上榜。
#然后画各地区国家上榜情况
country_rank = pd.DataFrame({'counts':all_country['all_counts']})
country_rank
country_rank.sort_values(by='counts',ascending=False).plot(kind='bar',figsize=(14,6))
plt.show()
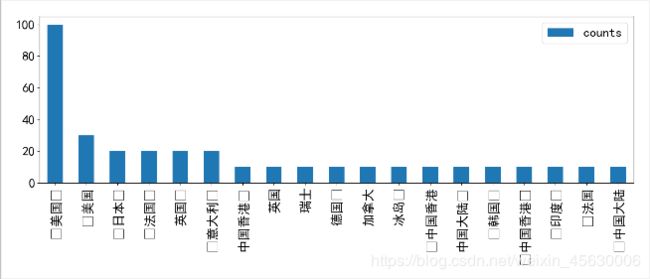
最后这张图中,很明显作品最多的是美国,但是中国的作品对比我参考的那篇增长了很多,说明这两年内国内出现了不少的优秀作品。
以上就是我进行的简单的数据分析,要继续加油学习鸭!