模拟Ajax请求爬取4000部豆瓣电影
进入准备爬取的网页:
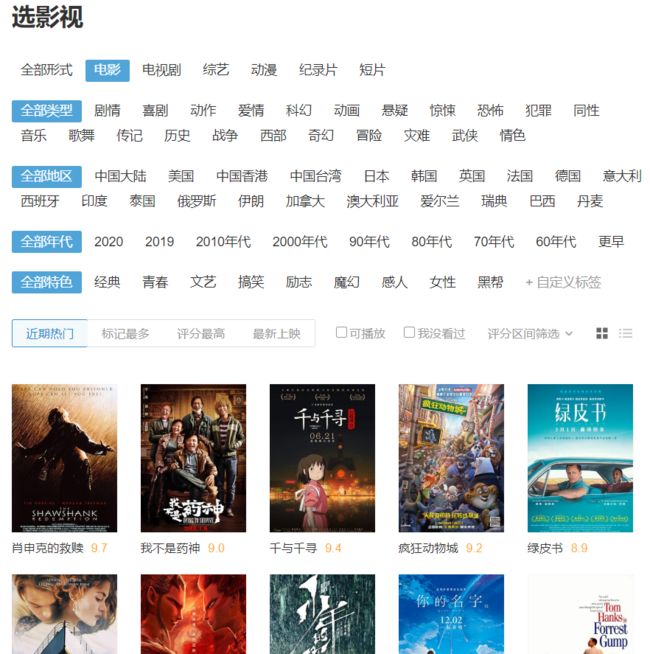
编写一个获取页面的函数:
def get_html(url, proxies):
"""
@功能: 获取页面
@参数: URL链接、代理IP列表
@返回: 页面内容
"""
failed = 1 # 请求失败参数
headers = [
{'User-Agent': "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"},
{'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"},
{'User-Agent': "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)"},
{'User-Agent': "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)"},
{'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko"},
{'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36"}
]
while True:
try:
if failed % 5 == 0:
proxies = get_proxy()
print("请求失败次数太多,更新代理IP!")
time.sleep(1)
res = requests.get(url, headers=random.choice(headers), proxies=random.choice(proxies))
if res.status_code == 200:
return res.text
except:
print("请求失败")
failed = failed + 1
打开 Chrome 的开发者工具,并通过点击下面的 加载更多,捕获 Ajax 请求,并发现其规律:

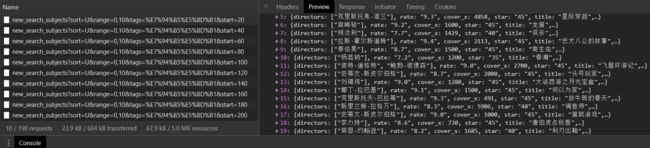
可以发现请求 URL 的规律是 https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start= + 20的整数倍 ,每个 Ajax 请求会加载 20 部电影的数据,且数据是 json 格式,因此我们可以通过程序模拟 Ajax 请求,从而获取所需的电影数据:
def crawl_movies(num):
"""
@功能: 爬取电影相关信息
@参数: 电影数量/20(一共是20*num部电影)
@返回: 电影的相关信息(json格式)
"""
movies_lists = []
update = 0 # 更新代理IP的参数
for i in range(num):
if update % 40 == 0:
proxies = get_proxy()
print("更新代理IP!")
url = "https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=" + str(i*20) # 每个电影列表的URL(一个页面20部电影)
while True:
data = get_html(url, proxies) # 获取电影列表页面
dicts = json.loads(data) # 把数据转换成json格式
if dicts != {"msg":"检测到有异常请求从您的IP发出,请登录再试!","r":1}:
break
try:
movies_lists.append(dicts['data'])
print("成功获取20部电影的网页!")
update = update + 1
except:
print("获取资源失败")
return movies_lists
{"data":[{"directors":["弗兰克·德拉邦特"],"rate":"9.7","cover_x":2000,"star":"50","title":"肖申克的救赎","url":"https:\/\/movie.douban.com\/subject\/1292052\/","casts":["蒂姆·罗宾斯","摩根·弗里曼","鲍勃·冈顿","威廉姆·赛德勒","克兰西·布朗"],"cover":"https://img9.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p480747492.webp","id":"1292052","cover_y":2963},{"directors":["文牧野"],"rate":"9.0","cover_x":2810,"star":"45","title":"我不是药神","url":"https:\/\/movie.douban.com\/subject\/26752088\/","casts":["徐峥","王传君","周一围","谭卓","章宇"],"cover":"https://img9.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2561305376.webp","id":"26752088","cover_y":3937},...
通过分析上述 json 格式的数据,我们可以进行解析和提取:
def parse_movies(movies_lists):
"""
@功能: 解析电影信息
@参数: 电影的相关信息(json格式)
@返回: 电影信息列表
"""
movies = [] # 存储每部电影
update = 0 # 更新代理IP的参数
count = 1 # 日志参数
for i in range(len(movies_lists)):
for j in movies_lists[i]:
name = j['title'] # 电影名称
rate = j['rate'] # 电影评分
try:
directors = j['directors'][0] # 导演
except:
directors = None
dataID = j['id'] # 电影ID
url = j['url'] # 电影链接
pic = j['cover'] # 电影海报
actors = ' '.join(j['casts']) # 主演
if update % 40 == 0:
proxies = get_proxy()
print("更新代理IP!")
如果需要提取另外的信息,我们可以获取电影的 URL,并提取其对应页面中的信息:

def parse_movies(movies_lists):
"""
@功能: 解析电影信息
@参数: 电影的相关信息(json格式)
@返回: 电影信息列表
"""
movies = [] # 存储每部电影
update = 0 # 更新代理IP的参数
count = 1 # 日志参数
for i in range(len(movies_lists)):
for j in movies_lists[i]:
name = j['title'] # 电影名称
rate = j['rate'] # 电影评分
try:
directors = j['directors'][0] # 导演
except:
directors = None
dataID = j['id'] # 电影ID
url = j['url'] # 电影链接
pic = j['cover'] # 电影海报
actors = ' '.join(j['casts']) # 主演
if update % 40 == 0:
proxies = get_proxy()
print("更新代理IP!")
text = get_html(url, proxies) # 获取每部电影的页面
html = etree.HTML(text) # 解析每部电影的页面
# 电影英文名称
english_name = html.xpath("//*[@id='content']/h1/span[1]/text()")[0]
# 判断字符串中是否存在英文
if bool(re.search('[A-Za-z]', english_name)):
english_name = english_name.split(' ') # 分割字符串以提取英文名称
del english_name[0] # 去除中文名称
english_name = ' '.join(english_name) # 重新以空格连接列表中的字符串
else:
english_name = None
info = html.xpath("//div[@class='subject clearfix']/div[@id='info']//text()") # 每部电影的相关信息
# 编剧
flag = 1
writer = []
for i in range(len(info)):
if info[i] == '编剧':
for j in range(i + 1, len(info)):
if info[j] == '主演':
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文或英文
if (u'\u4e00' <= ch <= u'\u9fff') or (bool(re.search('[a-z]', info[j]))):
writer.append(info[j].strip())
flag = 0
break
if flag == 0:
break
if flag == 0:
break
writer = ''.join(writer) # 转换为字符串形式
# 电影类型
flag = 1
style = []
for i in range(len(info)):
if info[i] == '类型:':
for j in range(i + 1, len(info)):
if (info[j] == '制片国家/地区:') or (info[j] == '官方网站:'):
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文
if u'\u4e00' <= ch <= u'\u9fff':
style.append(info[j])
if len(style) == 3:
flag = 0
break
break
if flag == 0:
break
if flag == 0:
break
# 把电影类型分开存储
if len(style) == 1:
style1 = style[0]
style2 = None
style3 = None
if len(style) == 2:
style1 = style[0]
style2 = style[1]
style3 = None
if len(style) == 3:
style1 = style[0]
style2 = style[1]
style3 = style[2]
# 国家
flag = 1
country = []
for i in range(len(info)):
if info[i] == r'制片国家/地区:':
for j in range(i + 1, len(info)):
if info[j] == '语言:':
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文
if u'\u4e00' <= ch <= u'\u9fff':
country.append(info[j].strip())
flag = 0
break
if flag == 0:
break
if flag == 0:
break
country = country[0].split(r'/')
country = country[0]
# 电影语言
flag = 1
language = []
for i in range(len(info)):
if info[i] == '语言:':
for j in range(i + 1, len(info)):
if info[j] == '上映日期:':
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文
if u'\u4e00' <= ch <= u'\u9fff':
language.append(info[j].strip())
flag = 0
break
if flag == 0:
break
if flag == 0:
break
try:
language = language[0].split(r'/')
language = language[0]
except:
language = None
# 电影上映日期
flag = 1
date = []
for i in range(len(info)):
if info[i] == '上映日期:':
for j in range(i + 1, len(info)):
if (info[j] == '片长:') or (info[j] == '又名:'):
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文或英文
if (u'\u4e00' <= ch <= u'\u9fff') or (bool(re.search('[a-z]', info[j]))):
date.append(re.search(r'\d+', info[j]).group(0))
flag = 0
break
if flag == 0:
break
if flag == 0:
break
date = ''.join(date) # 转换为字符串形式
# 电影片长
flag = 1
duration = []
for i in range(len(info)):
if info[i] == '片长:':
for j in range(i + 1, len(info)):
if (info[j] == '又名:') or (info[j] == 'IMDb链接:'):
flag = 0
break
for ch in info[j]:
# 判断字符串中是否存在中文
if u'\u4e00' <= ch <= u'\u9fff':
info[j] = info[j].split('/')[0]
duration.append(re.search(r'\d+', info[j].strip()).group(0))
flag = 0
break
if flag == 0:
break
if flag == 0:
break
duration = ''.join(duration) # 转换为字符串形式
# 电影简介
introduction = ''.join(html.xpath("//div[@class='related-info']/div[@id='link-report']/span/text()")).strip().replace(' ', '').replace('\n', '').replace('\xa0', '').replace(u'\u3000', u' ')
# 把每部电影的信息存入一个列表,再append进去movies总列表
movies.append(
[name, english_name, directors, writer, actors, rate, style1, style2, style3,
country, language, date, duration, introduction, dataID, url, pic]
)
update = update + 1
print("成功解析第" + str(count) + "部电影的信息!")
count += 1
return movies
完整源代码