Python爬虫学习-豆瓣电影TOP250数据爬取(存入mongo数据库中)
利用了晚上的闲暇时间,想对正则表达式+requests进行爬虫练习,故决定对豆瓣电影top(https://movie.douban.com/top250)排名进行数据爬取。因为是简单的网络页面,所以使用requests更为方便。
爬虫的思路还是分为三步:爬取页面、提取数据、保存数据。
爬取页面
爬取的过程中并没有遇到反爬措施,所以较为页面爬取相对简单。
提取数据
通过观察每类数据的共同之处,再用正则表达式对数据进行字符匹配,从而获取数据。
保存数据
数据我是使用了mongo数据库进行存储,在之前的数据库“db”中增加了一个“movie_rank”表,在使用pymongo的方法写入数据。
原代码如下:
import re
import pymongo
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url1):
try:
kv = {'user-agent': 'Mozilla/4.0'}
r=requests.get(url1,headers=kv)
#设置浏览器的类型,进行迷惑
r.raise_for_status()
r.encoding='utf-8'
return r.text
except:
print("爬取失败")
def fillList(demo):
datalist=[]
soup = BeautifulSoup(demo, 'html.parser')
namelist=soup.findAll('div',class_="item")
for i in range(25):
# 电影排名
num=(re.findall(r'\d{1,3}', namelist[i].text))[0]
num=int(num)
# 电影名字
name = (re.findall(r'[\u4e00-\u9fa5]{2,10}', namelist[i].text))[0]
# 电影评分
grade=(re.findall(r'\d{1}[.]\d{1}', namelist[i].text))[0]
# 电影年份
year=(re.findall(r'\d{4}', namelist[i].text))[-2]
# 电影评价人数
evaluate=(re.findall(r'.+评价', namelist[i].text))[0]
# 电影导演
actor=(re.findall(r'导演: .+', namelist[i].text))
actor=str(actor).split('\\xa0')[0][2:]
style=(re.findall(r'[/].*', namelist[i].text))[-1]
# 电影所属国家
country=str(style).split('\xa0')[1]
# 电影类型
style=str(style).split('\xa0')[3]
datalist.append([num,name,actor,year,country,style,grade,evaluate])
return datalist
def PrintFllist(datalist):
# 建立连接
client = pymongo.MongoClient('localhost', 27017)
# 连接数据库
db = client['mydb']
# 连接表
collection = db['movie_rank']
for i in range(len(datalist)):
u = datalist[i]
# 插入数据
collection.insert_one({'排名': u[0], '电影名称': u[1],'导演': u[2],'年份': u[3],'所属国家': u[4],'电影类型': u[5],'评分': u[6], '评价人数': u[7]})
if __name__ == '__main__':
count=0
url = "https://movie.douban.com/top250"
#对所有的页数进行遍历
long=10 #10页
for i in range(long):
bat="?start="+(i*25).__str__()
url1=url+bat
demo=getHTMLText(url1)
datalist=fillList(demo)
PrintFllist(datalist)
count+=1
print('\r当前进度:{:.2f}% '.format(count*100/long),end='')
print('爬取成功')
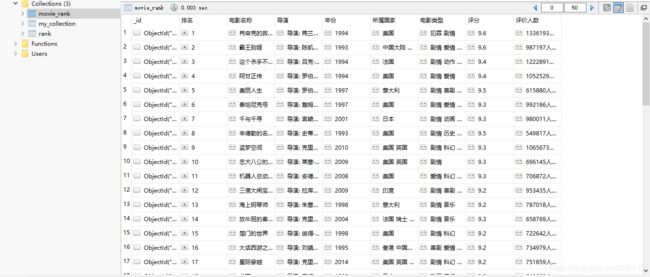
结果图
如需转载请注明。