EDVR介绍
git repo | project | open SR
概述
EDVR框架是适用于多种视频重建任务(如超分、去模糊)的统一框架。
- 该模型赢得了NTIRE19视频重建和增强挑战赛的四项冠军。并与第二名拉开了较大差距。
- 作者创新性的提出了 PCD 对齐模块和 TSA 融合模块,使得视频重建的效果大大提高。
面临的困难
REDS是在NTIRE19发布的新的数据集,从两个方面给现有的视频重建方法带来了挑战。
- 如何在有大幅度运动的情况下对齐多个帧。
- 如何有效的融合带有不同动作和模糊的不同帧。
现有的方法
早期的研究将视频重建看做是图像重建的简单拓展,这样的话相邻帧之间的时间冗余信息未被充分利用。最近的研究通过更精细的管道流程解决了上述问题,这些管道流程通常由四个部分组成,即特征提取,对准,融合和重建。
当视频包含遮挡,大运动和严重模糊时,该任务的挑战在于对齐和融合模块的设计。 为了获得高质量的输出,必须在多个帧之间对齐并建立准确的对应关系,以及有效地融合对准的特征以进行重建。
现有的方法多数采用在参考帧和相邻帧间的光流场来对齐;另一个研究分支是采用动态滤波和形变卷积。而REDS在时间消耗和精准性上对基于光流的方法提出了挑战。
大多数现存的方法使用卷积在处理的早期进行融合或者采用rnn逐渐融合多个帧。这些现有方法都没有考虑每个帧的潜在视觉信息。不同的帧和位置对重建的信息和增益不是相同的,因为一些帧或区域受到不完美对齐和模糊的影响
EDVR的方法
作者提出了EDVR框架处理这些挑战。首先设计了金字塔级联变形对齐模块处理大的运动,其中使用形变卷积以由粗到细的方式在特征级别进行帧对齐。其次,作者提出了时空注意力融合模块,在这个模块中,时间和空间的注意力都被应用,以强调后续重建的重要特征。
算法原理
EDVR
给定 2N+1 个连续低质量帧 ,定义中间帧 作为参考帧,其他帧作为相邻帧。视频重建的目标是得到一个与GT帧 足够相似的高质量参考帧输出 。结构如图所示:

EDVR将2N+1个LR帧作为输入并产生1个输出,每一个相邻帧都被PCD对齐模块与参考帧对齐,TSA融合模块融合了不同帧的图像信息,融合后的特征传到重建模块,重建模块是连续的残差块,并可以容易的被其他单一图像超分的高级模块替换。上采样操作在网络的末端增加图像的空间尺寸大小,最后高分辨率帧由预测图像残差和上采样图像相加得到。
虽然单独的EDVR模型可以达到最好的表现,为了在比赛中取得更好的表现,作者采用了2-stage的策略,在深层的EDVR模型后面接了一个浅层的EDVR模型。
PCD(Pyramid, Cascading and Deformable convolutions)
思路简述
PCD由TDAN(Temporally deformable alignment network for video super-resolution)启发,TDAN使用形变卷积在特征级别对齐相邻的帧。
Different from TDAN, we perform alignment in a coarse-to-fine manner to handle large and complex motions. Specifically, we use a pyramid structure that first aligns features in lower scales with coarse estimations, and then propagates the offsets and aligned features to higher scales to facilitate precise motion compensation, similar to the notion adopted in optical flow estimation.
与TDAN不同,我们以粗到细的方式执行对齐以处理大而复杂的运动。具体来说,我们使用金字塔结构,首先将较低比例的特征与粗略估计对齐,然后将偏移和对齐特征传播到更高的比例,以便于精确的运动补偿,类似于光流估计中采用的概念。
并且后面在金字塔对齐操作之后加了额外的形变卷积用来提高对齐的鲁棒性。模块图如下:

细节原理
定义每一帧的特征为,给定一个有K个采样点的变形卷积核,我们定义和作为第k个位置的权重和偏移。举例而言,3x3的卷积核则K=9,p为{(-1,-1),(-1,0),...,(1,0),(1,1)}。在每个p0位置的对齐的特征可以由下面的公式得到:
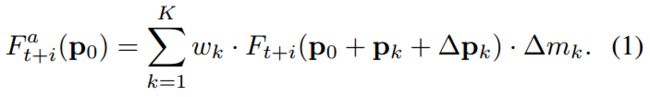
可学习的偏移量和调制标量都可以从相邻帧和参考帧连接的特征得到:
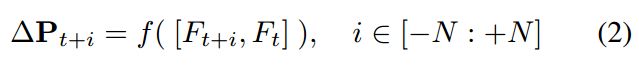
其中,f 是由多个卷积层组成的通用方法,[.,.]表示连接操作。为了简单起见,在描述和图表中只考虑可学习的偏移值忽略。在DCN中的双线性插值法提到。
为了处理在对齐中的复杂的动作和视差问题,
we propose PCD module based on wellestablished principles in optical flow: pyramidal processing and cascading refinement.
我们提出了基于光流中完善的原理的PCD模块:金字塔形处理和级联细化
在模块图中用黑色虚线展示,产生在第l层的特征。作者使用步长为2的卷积核在l-1层金字塔层级对特征降采样,在第l层,偏移和对齐后的特征被预测,使用x2上采样的偏移和对齐特征,图中用紫色虚线表示。
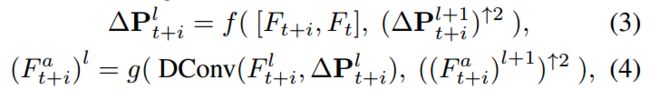
是上采样s倍,DConv是形变卷积,g 是由数个卷积层组成的通用方法,Bilinear interpolation是上采样2倍。作者在EDVR中使用3级金字塔(L=3)。为了减小计算消耗,没有随着空间大小的减小而增加通道数量。
Following the pyramid structure, a subsequent deformable alignment is cascaded to further refine the coarsely aligned features (the part with light purple background in Fig. 3)
在金字塔结构之后,后续的的可变形对齐可以进一步细化、提纯粗对齐特征(在图中的浅紫色背景展示)。
PCD模块在这种粒度从粗到细的处理提高了像素对齐的精确性。作者在消融实验部分阐述了PCD模型的有效性,值得注意的是,PCD对齐模块是随着整个网络一起训练的,而没有如光流一样的额外的监督或者在其他任务上的预训练。
TSA(Temporal and Spatial Attention)
TSA是一个融合模块,帮助融合多个对齐特征的信息。为了更好的考虑每一帧的视觉信息,我们引入了时间注意力机制,通过计算参考帧和相邻帧之间的元素级相关性。相关系数对每个位置处的每个相邻特征进行赋权,指示重建参考图像的信息量。所有帧中被赋权的特征会卷积、融合到一起。在带有时间注意力的融合之后,还引入了空间注意力为每一个通道的每一个位置分配权重,去更有效的利用跨通道和空间信息。模块图如下所示:
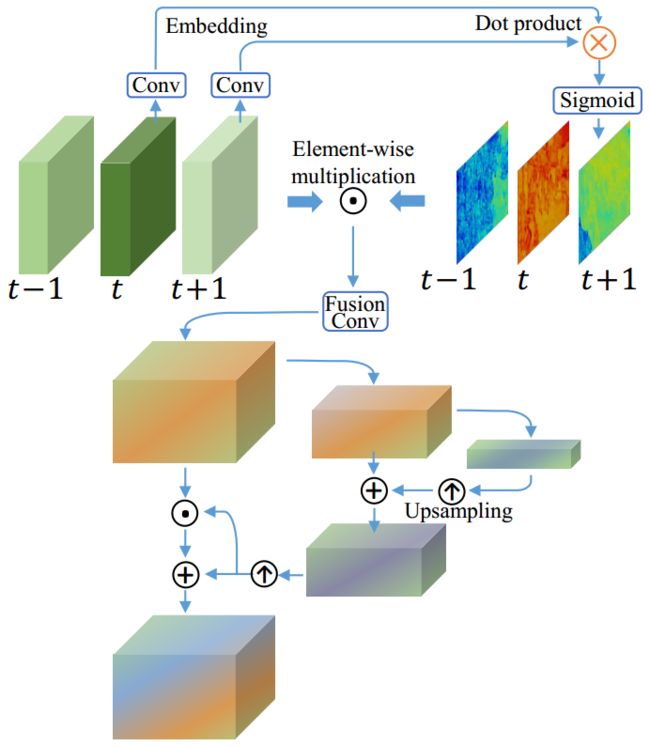
帧间的时序相关和帧内的空间相关性在融合中是很重要的,因为:
- different neighboring frames are not equally informative due to occlusion,blurry regions and parallax problems;
- misalignment and unalignment arising from the preceding alignment stage adversely affect the subsequent reconstruction performance.
- 由于遮挡,模糊区域和视差问题,不同的相邻帧不能提供相同的信息;
- 由前一对齐阶段引起的错误对齐和未对齐对随后重建的性能产生不利影响。
因此,在像素级动态的融合相邻帧在融合的效果和效率上是必不可少的。为了处理以上的问题,作者提出了TSA融合模块去为每一帧分配像素级别的融合权重。特别的,作者在融合过程中使用了时间和空间的注意力机制。
时间注意力是在embedding空间中计算帧的相似性,直觉上,在嵌入空间中,一个相邻帧与相邻帧更相似,则应该拥有更多的注意力。对于每一帧,相似性距离可以被计算为:
和是两个嵌入,可以被简单的卷积层实现。sigmoid激活函数用来约束输出值到0-1,稳定梯度的反向传播。对于每一个空间位置,时间注意力都可以用空间来描述,比如空间大小和相同。
时间注意力映射在像素级别和原始对齐后的特征相乘,一个额外的融合卷积层被采用去融合这些注意力化的特征可以计算为:
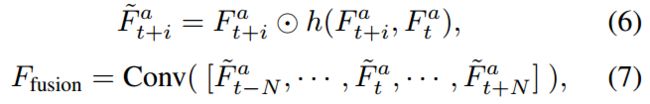
和[.,.,.]是元素级相乘和连接。
空间注意力mask从融合后的特征计算。一个金字塔设计可以增加注意力的感受野。在这止呕,融合的特征被mask用元素级相乘和连接调制。TSA的有效性在消融实验有阐述。
形变卷积 DCN
Deformable convolutional networks:其中学习额外的偏移以允许网络从其常规局部邻域获得信息,从而提高常规卷积的能力。可变形卷积广泛用于各种任务,如视频目标检测(Object detection in video with spatiotemporal sampling networks.),动作识别(Trajectory convolution for action recognition),语义分割[Deformable convolutional networks]和视频超分辨率。
特别地,TDAN使用可变形卷积来在特征级别对齐输入帧而无需显式运动估计或图像变形。 受TDAN的启发,PCD模块采用可变形卷积作为对齐的基本操作。
Attention 机制
在论文 Robust video super-resolution with learned temporal dynamics 中,学习了一系列权重图为不同时间分支的特征赋权。非局部运算(Non-local neural networks)计算位置处的响应,以获取远程范围依赖的所有位置处的特征的加权和。由这些成功的工作启发,作者将时空注意力机制引入到TSA融合模块。
实验
训练的细节
- 网络配置:PCD对齐模块采用5个RBs(residual blocks,残差块)做特征提取,用40个RBs做重建,20个RBs在第二个stage,卷积通道的大小都设置为128,使用64*64和256*256的图作为视频超分和去模糊的输入,mini-batch的大小为32,使用五个连续帧作为网络的输入,使用水平翻转和旋转90度做数据扩增,使用charbonnier作为损失函数。
- 训练过程:使用adam优化器,参数为0.9和0.999,学习率为4*10e-4,为了快速收敛,深层网络通过浅层网络得到。
- 论文中使用pytorch实现网络,用8个NVIDIA Titan Xp GPU训练,迭代了600000次,用时约40小时。
实验结果对比

自己训练模型迭代了146000次在Vid4上的实验结果:
| Clip Name | Average PSNR | Center PSNR | Border PSNR |
|---|---|---|---|
| calendar | 23.821341 | 23.845426 | 23.680849 |
| city | 27.669887 | 27.669345 | 27.672416 |
| foliage | 26.114071 | 26.109127 | 26.149501 |
| walk | 30.673578 | 30.671510 | 30.687713 |
| Average | 27.069719 | 27.073852 | 27.047620 |

由于采用Vimeo90k测试集的全部数据做测试会消耗很多时间,我取了Vimeo90k测试集中的前1000个clip做测试集。
实验结果如下:
| 模型迭代次数(iter) | PSNR(db) |
|---|---|
| 公开模型EDVR_Vimeo90K_SR_L.pth | 21.212242 |
| 公开模型EDVR_REDS_SR_L.pth | 22.271980 |
| 26000 | 25.502264 |
| 48000 | 25.502447 |
| 86000 | 25.509339 |
| 96000 | 25.550892 |
| 100000 | 25.573008 |
| 120000 | 25.604280 |
总结实验结果
- 在Vid4上基本达到了论文中的结果。
- 在vimeo90k上,效果和论文中的差距较大,超过了提供出来的预训练模型。实验结果相比论文给出的结果较差的原因应该是训练的迭代次数不够,以及DCN训练不稳定所导致。论文中使用2-stage分别迭代了600000次,而这里只迭代了120000次。论文中进行一次完整训练需要用到的时间是40小时,这里训练120000次就耗费近50小时,自己的实验迭代的次数远远不够。另外,查阅了github的issue发现,其他的人复现论文时遇到训练不收敛的问题,无法得到很好的测试结果。作者给出的回答主要是由变形卷积引起,不易收敛,这也是该模型的缺陷之一。
参考
SRCNN: 最初使用神经网络做SR
TOFlow: 揭露了光流不是最佳的运动表示
比较新的模型:
EDSR
WDSR
SPMC
DBPN
DUF 和TDAN :通过隐式运动补偿来规避问题并超越基于流的方法
光流:
Realtime video super-resolution with spatio-temporal networks and motion compensation
Frame-recurrent video super-resolution
Detail-revealing deep video super-resolution
Enhanced deep residual networks for single
image super-resolution
Ntire 2017 challenge on single image super-resolution: Methods and results
Photorealistic single image super-resolution using a generative adversarial network
Non-local recurrent network for image restoration
Path-restore: Learning network path selection for image restoration.
Crafting a toolchain for image restoration by deep reinforcement learning
Robust video super-resolution with learned temporal dynamics
其他问题
为什么在残差中不加BN层
现在一般的残差块是卷积层、激活函数层、BN层的结构,但是在EDVR的代码实现中残差块没有BN层。作者说,他试过全部加BN层,但是结果要差于不加BN的结构。他认为即使在某些地方加了,也只能带来少量的提升。所以就没有在BN上面做过多的尝试。
训练不稳定的问题 参考
由于DCN训练的时候无法稳定的收敛,导致整个网络不好收敛,这是作者认识到的一个问题,也是这个模型存在的训练上的缺陷。
在实验中,如果训练不稳定则会输出 Offset mean is larger than 100
作者自己实验的时候的方法是,遇到了不收敛,就退回到上一个checkpoint继续训练。
有以下这些点可以去尝试,但是也不一定有效:
先训练一个可以收敛的小模型,再通过小模型转去大模型。
- 对DCN使用更小的学习率。
- 有人尝试这样做:先把DCN转成普通conv,训练得到初始模型,再用这个模型训练网络,然后冻结某些层继续训练。
参考:
训练的细节
理论的细节
失真的问题
https://github.com/xinntao/EDVR/issues/28
为什么要用CharbonnierLoss函数 https://github.com/xinntao/EDVR/issues/40
创建lmdb需要内存较大
创建lmdb的脚本需要很大内存,不能依次读入,分别创建。
字幕区域无法处理
字幕区域subtitle region无法对齐,由于使用了邻域的信息,在跳到另一句话的时候,字幕会有残影。用SISR方法处理。或者拿什么方法单独处理并发现字幕的区域。
实验记录 0 参考这里
安装依赖
git clone https://github.com/xinntao/EDVR.git
cd EDVR
# python requirement , 最好是 python3
# 安装合适版本的pytorch 参考 https://pytorch.org/get-started/locally/
pip install numpy opencv-python lmdb pyyaml
# TensorBoard:
# PyTorch >= 1.1:
pip install tb-nightly future
# PyTorch == 1.0:
pip install tensorboardX
Vimeo90K数据集准备
- 下载数据集
点击下载 Ground-Truth(GT) 数据集 Septuplets dataset --> The original training + test set (82GB) - 将GT数据集转化为lmdb格式
使用 codes/data_scripts/create_lmdb_mp.py 生成lmdb文件,需要注意:(1)需要修改脚本中的配置信息(configuration),输入图片路径、输出路径、文件列表路径。(2)这个脚本会读取所有的图片到内存中,所以会占用很大的内存,如果想减小内存消耗,需要修改脚本,可以参照这里。 - 产生低分辨率的图像
在Vimeo90K测试集中的低分辨率图像(LR)是由matlab bicubic downsampling kernel生成的,在matlab中使用这个脚本产生低分辨率图像. - 将LR数据集转化为lmdb格式,参照第二点,修改配置信息
测试和训练 参考这里
测试
- 从这里下载预训练模型EDVR_Vimeo90K_SR_L.pth,放到experiment/pretrained_models文件夹下
- 从下载测试数据集,解压后将Vid4文件夹放到datasets文件夹下。
- 运行 codes/test_Vid4_REDS4_with_GT.py ,结果保存在results中。
训练
使用8GPU分布式训练
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 train.py -opt options/train/train_EDVR_woTSA_M.yml --launcher pytorch
python3 -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 train.py -opt options/train/train_EDVR_vimeo_M.yml --launcher pytorch
提供了一个适中的模型训练配置,channel=64,back residual block = 10
Train with the config train_EDVR_woTSA_M.yml
Train with the config train_EDVR_M.yml, whose initialization is from the model of Step 1.
排错指南
报图像尺寸问题,不能被4整除,需要把图片填充0或者切割。
编译DCN错误 见这里
作者已经上传了编译好的DCN,可以下载
一般都是gcc版本问题 1 2
NTIRE2019数据集
https://competitions.codalab.org/competitions/21482#participate-get-data
实验记录 1
imresize
作者提供了一个matlab的imresize方法(bicubic+抗锯齿),用来将GT缩小4倍产生LR的训练数据。python中常见的resize方法(opencv,skimage,PIL)不具备matlab中的抗锯齿效果。如果使用python中默认的resize,会使得缩小后的图片有锯齿,在神经网络学习的过程中,会让模型学习到带锯齿到不带锯齿的效果;而在正常实际拍摄、录制过程中不会出现带锯齿的图片,所以模型学到的这种映射是冗余的。
在对bicubic插值法研究后,结合现有的实现,将作者用matlab写的generate_LR_vimeo.m转成python实现。代码见data_script/generate_LR.py和imresize.py。
产生测试集
vimeo数据集中,训练集和测试集都存放在一个文件夹,通过sep_trainlist和sep_testlist文件来区分训练集和测试集。在EDVR项目中,测试数据存放在datasets/xxxx文件夹。文件夹内有BIx4子目录和GT子目录。BIx4是LR图像,GT是GroundTruth。由BIx4生成HR,与GT对比,计算得到PSNR和SSIM,用于评估模型。
为了方便起见,制作脚本,由sep_testlist文件将测试数据生成到datasets目录,方便直接运行现有的test程序。
另外,由于vimeo中图片文件命名为im1/im2/imx.png,而test中有一步操作需要将图片名字需要转成int型,故需要重命名图片名字。也加入了此功能到脚本中。代码见data_script/generate_test_datasets.py。
如何从浅模型载入到深模型
在论文中的实验部分,作者提到:
We initialize deeper networks by parameters from shallower ones for faster convergence
为了更快的收敛,我们用浅层的网络初始化深层的网络。40层的RB是直接将10层的RB的参数复制过来。
修改codes/model/basic_model.py中load_network(),在for k, v 前面加上一句 load_net_clean = network.state_dict() 即可实现。