大数据笔试真题集锦---第二章:Spark面试题
我会不间断的更新,维护,希望可以对正在找大数据工作的朋友们有所帮助.
第二章目录


第二章 Spark
2.1 Spark 原理
2.1.1 Shuffle 原理
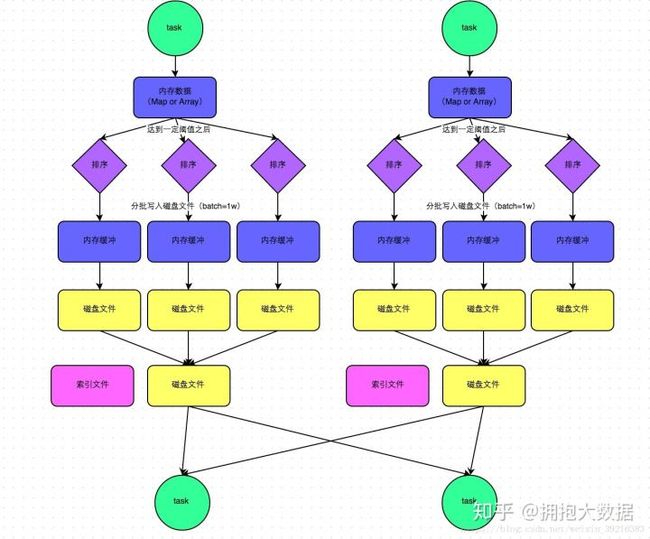
2.1.1.1 SortShuffle
- mapTask将map(聚合算子)或array(join算子)写入内存
- 达到阀值发生溢写,溢写前根据key排序,分批写入磁盘,最终将所有临时文件合并成一个最终文件,并建立一份索引记录分区信息。一个mapTask最终形成一个文件。
- reduceTask拉取各个task中自己的分区数据去计算。
2.1.1.2 和hadoop shuffle的区别
- MR没有所谓的DAG划分,一次MR任务就意味着一次shuffle;spark则是RDD驱动的,行动算子触发时才会按宽窄依赖划分阶段,只有宽依赖才会发生shuffle
- MR在reduce端还会进行一次合并排序,spark则在map端就完成了排序,采用Tim-Sort排序算法
- MR的reduce拉取的数据直接放磁盘再读,spark则是先放内存,放不下才放磁盘
- MR在数据拉取完毕后才开始计算,spark则是边拉边计算(reduceByKey原理)
- 基于以上种种原因,MR自定义分区器时往往还需要自定义分组,spark则不需要(或者说map结构已经是自定义分组了)。
2.1.2 job 提交流程(重点)
2.1.2.1 standalone

- driver端:通过反射获取主类执行main方法 -> 创建sparkconf和sparkContext,创建通信环境、后端调度器(负责向master发送注册信息、向excutor发送task的调度器)、task调度器、DAG(根据宽窄依赖划分stage)调度器 ->封装任务信息提交给Master
- Master端:缓存任务信息并将其放入任务队列 -> 轮到该任务时,调用调度方法进行资源调度 ->发送调度信息给对应的worker
- Worker端:worker将调度信息封装成对象 -> 调用对象的start方法,启动excutor进程
- Excutor进程:启动后向driver端反向注册(driver端拿到信息后注册excutor,向其发送任务) -> 创建线程池,封装任务对象 -> 获取池中线程执行任务 -> 反序列化TastSet,执行给定的各种算子步骤
2.1.2.2 yarn-client
- 客户端向yarn的RM申请启动AM,同时在自身的sparkContext中创建DAGScheduler和TASKScheduler(创建driver)
- 按照正常Yarn流程,一个NM领取到AM任务作为AM与客户端的driver产生连接(在yarn-cluster中该AM直接作为driver而不是连接driver)
- driver根据任务信息通过AM向RM申请资源(计算容器)
- AM通知领取到任务的NM向driver的sparkContext反注册并申请Task
- driver的sparkContext分配Task给各个计算节点,并随时掌握各个任务运行状态
- 应用程序运行完成后,sparkContext向RM申请注销并关闭自己。
总结:与standalone区别是,AM只作为中间联系,实际作为AM的是driver的sparkContext
2.1.2.3 yarn-cluster
- 先将driver作为一个AM在一个NM中启动
- 由AM创建应用程序,走正常的yarn流程启动Executor运行Task,直到运行完成
总结:与yarn client相比只是把driver端由客户端变成了集群中的某个NodeManager节点。
2.1.3 Job 运行原理

阶段一:我们编写driver程序,定义RDD的action和transformation操作。这些依赖关系形成操作的DAG。
阶段二:根据形成的DAG,DAGScheduler将其划分为不同的stage。
阶段三:每一个stage中有一个TaskSet,DAGScheduler将TaskSet交给TaskScheduler去执行,TaskScheduler将任务执行完毕之后结果返回给DAGSCheduler。
阶段四:TaskScheduler将任务分发到每一个Worker节点去执行,并将结果返回给TaskScheduler。
2.1.4 Task 重试与本地化级别
TaskScheduler遍历taskSet,调用launchTask方法根据数据"本地化级别"发送task到指定的Executor
task在选择Executor时,会优先第一级,如果该Executor资源不足则会等待一段时间(默认3s),然后逐渐降级。
2.1.4.1 本地化级别
PROCESS_LOCAL 进程本地化
NODE_LOCAL 节点本地化
NO_PREF 非本地化
RACK_LOCAL 机架本地化
ANY 任意
2.1.4.2 重试机制
taskSet监视到某个task处于失败或挣扎状态时,会进行重试机制
当某个task提交失败后,默认会重试3次,3次之后DAGScheduler会重新提交TaskSet再次尝试,总共提交4次,当12次之后判定job失败,杀死Executor
挣扎状态:当75%的Task完成之后,每隔100s计算所有剩余task已执行时间的中位数,超过这个数的1.5倍的task判定为挣扎task。
2.1.5 DAG原理(源码级)
- sparkContext创建DAGScheduler->创建EventProcessLoop->调用eventLoop.start()方法开启事件监听
- action调用sparkContext.runJob->eventLoop监听到事件,调用handleJobSubmitted开始划分stage
- 首先对触发job的finalRDD调用createResultStage方法,通过getOrCreateParentStages获取所有父stage列表,然后创建自己。
如:父(stage1,stage2),再创建自己stage3 - getOrCreateParentStages内部会调用getShuffleDependencies获取所有直接宽依赖(从后往前推,窄依赖直接跳过)
在这个图中G的直接宽依赖是A和F,B因为是窄依赖所以跳过,所以最后B和G属于同一个stage - 接下来会循环宽依赖列表,分别调用getOrCreateShuffleMapStage:
-- 如果某个RDD已经被划分过会直接返回stageID;否则就执行getMissingAncestorShuffleDependencies方法,继续寻找该RDD的父宽依赖,窄依赖老规矩直接加入:
-- 如果返回的宽依赖列表不为空,则继续执行4,5的流程直到为空为止; -- 如果返回的宽依赖列表为空,则说明它没有父RDD或者没有宽依赖,此时可以直接调用createShuffleMapStage将该stage创建出来 - 因此最终的划分结果是stage3(B,G)、stage2(C,D,E,F)、stage1(A)
- 创建ResultStage,调用submitStage提交这个stage
- submitStage会首先检查这个stage的父stage是否已经提交,如果没提交就开始递归调用submitStage提交父stage,最后再提交自己。
- 每一个stage都是一个taskSet,每次提交都会提交一个taskSet给TaskScheduler
2.1.6 SparkContext 创建流程(源码级)
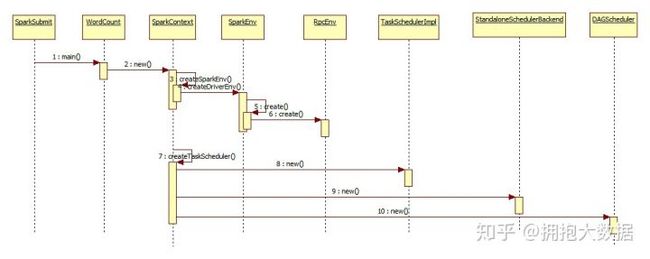
- SparkSubmit反射调用主类的main方法
- main方法中初始化SparkContext对象
- SparkContext开始初始化Spark通信环境 RpcEnv
- SparkContext创建TaskSchedulerImpl对象
- SparkContext创建StandaloneSchedulerBackend对象
- 最后创建DAGScheduler对象
2.1.7 Spark SQL 运行原理

- SQL语句封装到SQLContext对象中
- 调用分析器检查语义、调用翻译器翻译成RDD算子、调用优化器选择最佳算子
- 打包成jar包上传集群
- 走常规spark作业流程
2.1.8 Spark的内存模型

executor的内存分为4+1块:
Execution:计算用内存,用于执行各种算子时存放临时对象的内存
Storage:缓存用内存,主要存储catch到内存中的数据,广播变量也存在这里
User Memory:用户用内存,存储RDD依赖关系等RDD的信息
Reserved Memory:预留内存,用来存储Spark自己的对象
Off-heap Memory:堆外内存,开启之后计算和缓存的内存都分别可以存在堆外内存。堆外内存不受spark GC的影响。
Execution和Storage采用联合内存机制,可以互相借用对方的内存区域,但是Execution可以强制征收Storage的内存,反过来不行。
Task共用executor的内存区域,spark准备了一个hashMap用来记录各个task使用的内存,task申请新的内存时,如果剩余内存不够则会阻塞直到有足够的内存为止。每个task至少需要1/2N的内存才能被启动。
2.1.9 算子原理
2.1.9.1 foreach和foreachPartition的区别
两个算子都是属于Action算子,但是适用于场景不同,foreach主要是基于输出打印使用,进行数据的显示,而foreachPartition的适用于各种的connection连接创建时候进行使用,保证每个分区内创建一个连接,提高执行效率,减少资源的消耗。
2.1.9.2 map与mapPartitions的区别
两个算子都属于transformtion算子,转换算子,但是适用于场景不同,map是处理每一条数据,也就是说,执行效率稍低,而mapPartition是处理一个分区的数据,返回值是一个集合,也就是说,在效率方面后者效率更高,前者稍低,但是在执行安全性方面考虑,map更适合处理大数据量的数据,而mappartition适用于中小型数据量,如果数据量过大那么会导致程序的崩溃,或oom。
2.2 spark版本2.x 与1.6的区别
底层的执行内存模型发生改变,从之前的静态内存模型,改为动态内存模型,在spark2.X以后推出了一个全新的特性,叫DataSet,DataSet相当于整合了DF和RDD之间的关系,可以更容易的操作Spark的API。
2.3 Spark 概念
2.3.1 RDD
RDD是一个弹性分布式数据集,是一个只读的分区记录的集合,只能基于某个数据集或其他RDD上转换而来,因此具有高容错、低开销的特点。
2.3.2 Job
job 可以认为是我们在driver 或是通过spark-submit 提交的程序中一个action ,在我们的程序中有很多action 所有也就对应很多的jobs
2.3.3 Stage
stage是由DAGScheduler根据宽窄依赖划分spark任务所得到的一组可并行执行的task任务集合,存在依赖关系的stage之间是串行的,一个sparkJob可能产生多组stage。
Stage有两个子类:ResultStage和ShuffleMapStage
2.3.3.1 ResultStage
在RDD的某些分区上应用函数来计算action操作的结果,对应DAG原理中createResultStage()创建的对象
2.3.3.2 ShuffleMapStage
ShuffleMapStage 是中间的stage,为shuffle生产数据。它们在shuffle之前出现。当执行完毕之后,结果数据被保存,以便reduce 任务可以获取到。
2.3.4 Task
task是执行spark job 的逻辑单元,运行在executor的Cpu Core中
2.3.4.1 ShuffleMapTask
shuffle操作发生后,那么Task会划分两种Task,其中,上游数据叫做ShuffleMapTask,主要是用于将数据进行上游处理,为下游数据拉取做准备。
2.3.4.2 ResultTask
下游数据,主要是基于上游数据的结果集,其实ResultTask会根据元数据索引进行拉取数据文件,然后根据Key聚合内部所有的value值。
2.3.5 Spark里kyro序列化了解多少?
Spark的序列化 默认为org.apache.spark.serializer.JavaSerializer,可选org.apache.spark.serializer.KryoSerializer,实际上只要是org.apache.spark.serializer的子类就可以了,不过如果只是应用,大概你不会自己去实现一个的。
序列化对于spark应用的性能来说,还是有很大影响的,在特定的数据格式的情况下,KryoSerializer的性能可以达到JavaSerializer的10倍以上,当然放到整个Spark程序中来考量,比重就没有那么大了,但是以Wordcount为例,通常也很容易达到30%以上的性能提升。而对于一些Int之类的基本类型数据,性能的提升就几乎可以忽略了。KryoSerializer依赖Twitter的Chill库来实现,相对于JavaSerializer,主要的问题在于不是所有的Java Serializable对象都能支持。
需要注意的是,这里可配的Serializer针对的对象是Shuffle数据,以及RDD Cache等场合,而Spark Task的序列化是通过spark.closure.serializer来配置,但是目前只支持JavaSerializer。
2.3.6 持久化
spark通过catch和persist方法对结果进行一个持久化,persist方法共有5个参数,对应12个缓存级别,这12个级别分别从磁盘存储、内存存储、堆外内存存储、是否反序列化和备份数五个角度设定。其中catch使用的是Memory_Only,只在内存持久化。
2.3.7 检查点
spark通过checkPoint方法将RDD状态保存在高可用存储中,与持久化不同的是,它是对RDD状态的一个复制持久化,执行checkPoint后不再保存依赖链。此外,持久化存储的缓存当程序运行结束后就会被自动删除,检查点保存的RDD状态只能手动清理。
2.3.8 广播变量
正常情况下spark为每个Task都复制了一份它需要的数据,如果有大量Task都需要用到一份相同的数据,这种做法就会导致一个节点Excutor(内含多个Task)从driver端拉取大量重复数据,占用网络IO和内存资源。使用广播变量后,Task会惰性加载数据,加载时,先在本地Excutor的BlockManager中寻找,如果找不到再到最近节点的BlockManager中查找,直到找到数据后将数据传输到本地存储起来,同一节点的多个Task就可以复用这份数据,大幅减少内存占用和IO时间。
2.3.9 累加器
spark提供了一个累加器用于在整个流程中额外执行一个MR任务,它可以在driver端被初始化发送给各个Task,然后在每个Task中为它添加数据,最终经过reduce将结果聚合后返回driver端。可以自定义累加器的类型,通过实现一个聚合方法来创建自定义累加器。除此之外spark2还支持特殊的累加器-收集器,它不需要执行reduce,会将数据原原本本存放在集合中返回。注意:如果累加操作在transform算子并且action算子有多个时,需要catch该转换算子,否则可能造成重复累加。
2.3.10 分区
2.3.10.1 概念
分区是RDD内部并行计算的一个计算单元,是RDD数据集的逻辑分片,分区的格式决定并行计算的粒度,分区的个数决定任务的个数。
2.3.10.2 作用
通过将相同的key放在相同的节点,避免不同节点聚合key时进行shuffle操作产生的网络IO;此外,事先分区好的数据在join时就可以只由另一张表shuffle,自身不shuffle,这常常用在大表join小表上。
2.3.10.3 默认分区器
HashPartitioner:将key的哈希值/分区数量进行分区可选分区器RangePartitioner:范围分区器,按照字典顺序或数字大小排序后/分区数量来分区
2.3.10.4 自定义分区器
通过实现get分区总数方法和get分区数方法,指定自定义规则的key分区方式;使用自定义分区器创建的RDD进行复杂的聚合或join操作效率更高。
2.3.11 并行度
spark作业的最大并行度=excutor个数*每个excutor的cpu core数但spark的当前并行度取决于task数,而task数=分区数。分区数可以通过spark.default.parallelism设置默认分区数,也可以在使用算子时显示地指定分区器和分区数量。spark官方推荐设置分区数为最大并行度的2-3倍,这样可以保证提前计算的线程立刻被后面的task使用,并且每个task处理的数据量会更少。
2.4 Spark 调优
- spark1.6以下的版本中execution和storage的内存是各自固定的,执行内存负责transform算子和shuffle算子,storage负责catch部分和广播变量的存储。通过以下两个参数改变它们的大小。spark.shuffle.memoryFraction=0.2 spark.storage.memoryFraction=0.6
- spark1.6以上的版本时使用联合内存机制,两者可以互相借用内存,但是如果执行内存不够时会强制回收storage借走的内存。因此如果要进行大缓存任务时建议手动设置固定内存机制。
- 1.6以上的版本还额外增加了堆外内存,调用persist方法时指定StorageLevel.OFF_HEAP参数,配合分布式内存文件系统Tachyon将需要缓存很久的数据存放到堆外内存,大幅降低full GC的发生频率。. 使用repartition增加分区数量,降低每个task的大小
- 当合并分区的数据量过大时,可以使用repartition并手动指定使用shuffle来进行带shuffle的合并操作,可以在合并前先进行一次聚合。
- 使用shuffle算子时指定分区数量或指定自定义分区器避免数据倾斜
- 当某个数据重复很多时,尽量用一个对象来代表这些数据,可以是string,也可以是带计数器的map。
- 使用mapPartition代替map可以提升效率,但要注意内存紧缺时不能使用。
- map端join:当join小表时,可以先用collect将数据收集到driver端,然后用广播变量的方式发送到各个节点上,避免大数据的迁移。
- 可以使用map端reduce的方式进一步减少网络IO。调用combineByKey算子。
- 内存不足时使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER),直接缓存到磁盘。
- spark集群节点应该覆盖hbase,因为spark读取hbase时是按region读取,在同一个节点上可以避免大量数据迁移
- 参数设置: spark.driver.memory (default:1G) 设置driver端内存 spark.rdd.compress 设置压缩内存的rdd数据,减少内存的占用,但是增加CPU负担 spark.serializer 设置默认kyro spark.memory.storageFraction 设置storage在内存中的比例,根据缓存的大小决定 spark.locality.wait 设置等待任务的等待时间,如果某个任务等待数据到达的时间超过该时间,就会被下调优先级 spark.speculation 设置空闲节点是否执行某个长时间未结束的task,有点类似hive的预测执行,建议开启。
总结
减少GC:增加计算用的内存;把频繁使用的大缓存缓存到堆外内存;使用计数器存储重复的数据
增加并行度:shuffle时指定分区数量、repartition增加分区(可用线程的2-3倍)、减小分区可以指定带shuffle的repartition进行局部聚合
减少shuffle:使用指定的分区器进行分区,使得相同的key都处于同一分区中(主要用在数据清洗时按自定义分区器存储数据)
map端join:先读取小表到driver端存成广播变量,再读取大表使用广播变量进行join
map端reduce:使用combineByKey算子
指定persist : 内存不足时用persisit指定缓存磁盘来代替catch
参数调优:设置压缩RDD(节约内存,加重CPU)、设置kyro序列化、延长下调本地化级别的等待时间、开启预测执行等等
2.5 其它
2.5.1 SparkSQL和Hive区别
- SparkSQL实际上是使用sql解释器将sql语句转化为一系列的RDD转换与落地过程,而hive SQL则是将sql语句转换成多个MR job顺序执行
- 受限于MR模型,hive sql只能将sql语句按map和reduce的粒度切分,无法对其中的更细粒度的input、sort、shuffle等进行自由组合;相反spark RDD是一系列细粒度算子的转换流程,因此可以方便地对各个部分进行细致的优化和自由组合。
- Spark RDD尽管会在不得已时将中间结果落地磁盘(shuffle),但它不会将RDD的转换结果主动落地磁盘,因此在多个RDD之间变换时不需要重新进行IO;而HQL在多个job间必须不断重复IO过程
- 由于以上原因,SparkSql在实战时对子查询的执行效率远比HQL高,这也使得它很适合迭代型的sql统计
举例
HQL的窗口函数的发生时间在having之后,因此它的窗口函数可以统计group聚合后的数据,相反Spark没有job之间的先后关系,因此它的窗口函数只能使用聚合前的数据。
这在统计排名函数时可以很直观的看出来:
--以下统计各省用户登录次数前3
HQL:
select * from (
select id,province,time,row_number() over(
partition by province
order by count(1) DESC
) as rank
from table
group by id,province
)t
where rank<=3
上述HQL不能在sparkSQL中运行,会提示count(1)不属于可用的字段
而下述语句SparkSQL:
select id,province,row_number() over(
partition by province
order by total DESC
) as rank
from table
having rank<=3
在HQL中不能运行,会提示having字段错误
因此我推荐采用DSL+SQL的混合写法书写SparkSQL,将普通的转换算子和聚合算子用DSL风格书写,将窗口函数用SQL风格书写,可以避开二者的不同之处。
2.5.2 DF和DS的区别
DataFrame = DataSet[Row]DataSet是强类型JVM object的集合,DataFrame则是由每行弱类型的JVM object组成,二者都是按列存储,前者是结构化数据集,后者则是半结构化数据集
2.5.2.1 RDD与DataFrame区别,什么场景用RDD什么场景用DataFrame?
区别:
RDD是分布式的不可变的抽象的数据集,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是以RDD为基础的分布式的抽象数据集,也就是分布式的Row类型的集合(每个Row对象代表一行记录),提供了详细的结构信息,即Schema信息。Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
应用场景:
RDD的使用场景:
你需要使用low-level的transformation和action来控制你的数据集;
你得数据集非结构化,比如,流媒体或者文本流;
你想使用函数式编程来操作你得数据,而不是用特定领域语言(DSL)表达;
你不在乎schema,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
你放弃使用DataFrame和Dataset来优化结构化和半结构化数据集;DataFrame的使用场景:
你想使用丰富的语义,high-level抽象,和特定领域语言API,那你可DataFrame或者Dataset;
你处理的半结构化数据集需要high-level表达, filter,map,aggregation,average,sum ,SQL 查询,列式访问和使用lambda函数,那你可DataFrame或者Dataset;
你想利用编译时高度的type-safety,Catalyst优化和Tungsten的code生成,那你可DataFrame或者Dataset;
你想统一和简化API使用跨Spark的Library,那你可DataFrame或者Dataset;
如果你是一个R使用者,那你可DataFrame或者Dataset;
如果你是一个Python使用者,那你可DataFrame或者Dataset;2.5.3 自定义函数
spark支持三种自定义函数,UDF、UDAF(用户自定义聚合函数)、UDTF(用户自定义生成函数)
UDAF和UDTF都需要继承对应的自定义函数类,实现相应的抽象方法才可以使用
UDF则可以在spark.udf.register方法中使用函数直接注册使用。
2.5.4 线上Spark Job如何停止?
- SparkContext提供了一个取消job的api
class SparkContext(config: SparkConf) extends Logging with ExecutorAllocationClient {
/** Cancel a given job if it's scheduled or running */
private[spark] def cancelJob(jobId: Int) {
dagScheduler.cancelJob(jobId)
}- 那么如何获取jobId呢?
Spark提供了一个叫SparkListener的对象,它提供了对spark事件的监听功能
trait SparkListener {
/**
* Called when a job starts
*/
def onJobStart(jobStart: SparkListenerJobStart) { }
/**
* Called when a job ends
*/
def onJobEnd(jobEnd: SparkListenerJobEnd) { }
}因此需要自定义一个类,继承自SparkListener,即:
public class DHSparkListener implements SparkListener {
private static Logger logger = Logger.getLogger(DHSparkListener.class);
//存储了提交job的线程局部变量和job的映射关系
private static ConcurrentHashMap jobInfoMap;
public DHSparkListener() {
jobInfoMap = new ConcurrentHashMap();
}
@Overrid
public void onJobEnd(SparkListenerJobEnd jobEnd) {
logger.info("DHSparkListener Job End:" + jobEnd.jobResult().getClass() + ",Id:" + jobEnd.jobId());
for (String key : jobInfoMap.keySet()) {
if (jobInfoMap.get(key) == jobEnd.jobId()) {
jobInfoMap.remove(key);
logger.info(key+" request has been returned. because "+jobEnd.jobResult().getClass());
}
}
}
@Override
public void onJobStart(SparkListenerJobStart jobStart) {
logger.info("DHSparkListener Job Start: JobId->" + jobStart.jobId());
//根据线程变量属性找到该job是哪个线程提交的
logger.info("DHSparkListener Job Start: Thread->" + jobStart.properties().getProperty("thread", "default"));
jobInfoMap.put(jobStart.properties().getProperty("thread", "default"), jobStart.jobId());
}
……
}
那么用户如何知道该job是哪个线程提交的呢?需要在提交job的时候设置线程局部变量属性,如下:
SparkConf conf = new SparkConf().setAppName("SparkListenerTest application in Java");
String sparkMaster = Configure.instance.get("SparkMaster");
String sparkExecutorMemory = "16g";
String sparkCoresMax = "4";
String sparkJarAddress = "/tmp/cuckoo-core-1.0-SNAPSHOT-allinone.jar";
conf.setMaster(sparkMaster);
conf.set("spark.executor.memory", sparkExecutorMemory);
conf.set("spark.cores.max", sparkCoresMax);
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.addJar(sparkJarAddress);
DHSparkListener dHSparkListener = new DHSparkListener();
jsc.sc().addSparkListener(dHSparkListener);
List listData = new ArrayList();
listData = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
JavaRDD rdd1 = jsc.parallelize(listData, 1);
JavaRDD rdd2 = rdd1.map(new Function() {
public Integer call(Integer v1) throws Exception {
//do something then return
}
});
//在触发action提交job之前设置提交线程的局部属性,供SparkListener获取
jsc.setLocalProperty("thread", "client");
rdd2.count();
这样在jobInfoMap中记录了job和job提交者的映射关系,当发现某个job迟迟没有结束的时候,可以调用SparkContext的cancelJob取消,但是仅仅到这里就够了吗?接着往下看,excutor取消job最终调用的是:
def kill(interruptThread: Boolean) {
_killed = true
if (context != null) {
context.markInterrupted()
}
if (interruptThread && taskThread != null) {
taskThread.interrupt()
}
}最终调用到Thread.interrupt函数,给启动task的线程设置interrupt标记位,因此在长时间允许的task中,需要针对Thread的interrupt标记位进行判断,当被置位的时候,需要退出,并且做一些清理,即存在类似的代码段:
if(Thread.interrupted()){
//……线程被中断,清理资源
}
// 或者调用sleep,wait函数时会抛出InterruptedException异常,需要进行捕获,然后做对应的处理- 最后一步,配置job kill的动作
除了以上操作之外,还需要再配置针对每个job调用kill的动作,即spark.job.interruptOnCancel属性为true
//在触发action提交job之前设置提交线程的局部属性,供SparkListener获取
jsc.setLocalProperty("thread", "client");
//配置该job接受到kill之后的动作,即task线程收到interrupt信号
jsc.setLocalProperty("spark.job.interruptOnCancel", "true");
rdd2.count();2.5.5 Spark的数据放到Redis中代码是什么?
object SaveData2RedisDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]")
.setAppName("SaveData2RedisDemo")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
// 此处为业务逻辑 。。。。
resRDD.foreachPartition(it => {
val jedis = JedisConnectionPool.getConnection()
it.foreach(t => {
jedis.set(t._1, t._2)
})
jedis.close()
})
sc.stop()
}
}
/**
* 获取Redis连接
*/
object JedisConnectionPool{
val conf = new JedisPoolConfig()
//最大连接数,
conf.setMaxTotal(20)
//最大空闲连接数
conf.setMaxIdle(10)
//当调用borrow Object方法时,是否进行有效性检查 -->
conf.setTestOnBorrow(true)
//10000代表超时时间(10秒)
val pool = new JedisPool(conf, "node02", 6379, 10000)
def getConnection(): Jedis = {
pool.getResource
}
}
2.5.6 Spark如何连接到HBase中,代码是什么?
// 配置HBASE的基本信息
val load = ConfigFactory.load()
val hbaseTableName = load.getString("hbase.table.name")
// 配置HBASE的连接
val configuration = sc.hadoopConfiguration
configuration.set("hbase.zookeeper.quorum",
load.getString("hbase.zookeeper.host"))
val hbConn = ConnectionFactory.createConnection(configuration)
//获得操作对象
val hbadmin = hbConn.getAdmin
if (!hbadmin.tableExists(TableName.valueOf(hbaseTableName))) {
// 创建表对象
val tableDescriptor = new HTableDescriptor(TableName.valueOf(hbaseTableName))
//创建一个列簇
val columnDescriptor = new HColumnDescriptor("tags")
//将列簇放入到表中
tableDescriptor.addFamily(columnDescriptor)
hbadmin.createTable(tableDescriptor)
hbadmin.close()
hbConn.close()
}
// 创建Job对象
val jobConf = new JobConf(configuration)
// 指定输出类型
jobConf.setOutputFormat(classOf[TableOutputFormat])
// 指定输出到哪张表中
jobConf.set(TableOutputFormat.OUTPUT_TABLE, hbaseTableName)
// 此处是app的业务逻辑 。。。。
// 写入到HBASE中
res.map {
case (userid, userTags) => {
val put = new Put(Bytes.toBytes(userid))
val tags = userTags.map(t => t._1 + ":" + t._2).mkString(",")
put.addImmutable(Bytes.toBytes("tags"),
Bytes.toBytes(s"$day"), Bytes.toBytes(tags))
(new ImmutableBytesWritable(), put)
}
}.saveAsHadoopDataset(jobConf)2.5.7 Spark作业提交时如果出现依赖冲突怎么解决?
当用户应用与 Spark 本身依赖同一个库时可能会发生依赖冲突,导致程序崩溃。这种情况 不是很常见,但是出现的时候也让人很头疼。
通常,依赖冲突表现为 Spark 作业执行过 程中抛出 NoSuchMethodError、ClassNotFoundException,或其他与类加载相关的 JVM 异 常。
对于这种问题,主要有两种解决方式:
一是修改你的应用,使其使用的依赖库的版本 与 Spark 所使用的相同。
二是使用通常被称为“shading”的方式打包你的应用。
Maven 构 建工具通过使用shading插件(事实上,shading 的功能也是这个插件取名为 maven- shade-plugin 的原因)进行高级配置来支持这种打包方式。shading 可以让你以另一个命名 空间保留冲突的包,并自动重写应用的代码使得它们使用重命名后的版本。这种技术有些 简单粗暴,不过对于解决运行时依赖冲突的问题非常有效。
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
2.5.8 Spark可以用什么作业提交方式?
提交方式有:
Local模式(一般测试用)
Standalone模式(Spark自带的集群模式)
Spark-On-Yarn模式(将Spark App提交到Yarn上执行,较常用)
Mesos(Apache的一个独立的资源调度,不常用)
2.5.9 叙述Spark的资源动态调整方式。
为什么要动态资源分配和动态控制速率呢?
默认情况下,Spark是先分配好资源,然后在进行计算,也就是粗粒度的资源分配 。粗粒度的好处:资源是提前给分配好的,所以计算任务的时候,直接使用这些资源 。粗粒度的缺点:从Spark Streaming的角度讲,有高峰值和低峰值,高峰和低峰的时候,需要的资源是不一样的;如果按照高峰值的角度去分配,低峰值的时候,有大量的资源的浪费。
资源的动态分配是由一个定时器,不断的扫描Executor的情况,例如:有段时间之内,Executor没收到任何任务,所以会把这个Executor移除掉。
动态资源调整的时候,最好不要设置太多的Core,Core设置的太多,假如资源调整太过频繁的话,是比较麻烦的(Core 的个数一般设置为奇数:3、5、7)。
Spark Streaming要进行处理资源的动态调整,就是Executor的动态调整 。Spark Streaming是Batch Duration的方式执行的,这个Batch Duration里需要很多资源,下一个Batch Duration里不需要那么多资源,可能想调整资源的时候,还没来得及调整完资源,当前的这个Batch Duration的运行已过期的情况,这个时候的资源调整就是浪费的。
资源动态申请
spark streaming是基于spark core的,spark core也支持资源动态分配。可以在spark.dynamicAllocation.enabled中进行配置是否开启动态分配。如果开启就new ExecutorAllocationManager。
通过配置参数:spark.dynamicAllocation.enabled看是否需要开启Executor的动态分配。
你可以在程序运行时不断设置spark.dynamicAllocation.enabled参数的值,如果支持资源动态分配的话就使用ExecutorAllocationManager类。
2.5.10 斐波那契数列能用spark做出来吗?
Spark本来就是将海量数据进行批量处理的,如果用Spark实现兔子数列就是个伪命题,用Scala实现会简洁很多:
/**
* 递归实现兔子数列
* @param n
* @return
*/
def m1(n: Int): Int = {
if (n == 0) 0
if (n == 1 || n == 2) 1
else m2(n - 1) + m2(n - 2)
}
/**
* 采用动态规划思想实现兔子数列 ,比递归实现要高效
* @param n
* @return
*/
def m2(n: Int): Int = {
var n1 = 0
var n2 = 1
var res = 0
if (n <= 0) 0
else if (n == 1) return 1
else {
for (i <- 2 to n) {
res = n1 + n2
n1 = n2
n2 = res
}
res
}
}2.6 SparkStreaming
2.6.1 原理
2.6.1.1 DStream
DStream是Spark Streaming的基础抽象,代表持续的数据流,它由一系列连续的RDD组成,一个批次间隔接收的数据只会存放在一个block中,因此每个批次间隔都只会产生一个RDD。
DStream与RDD同样是不可变的,每个算子都会创建一个新的DStream,因此一个批次可能会有多个DStream。
对同一个DStream连续window没有意义,因为foreach只会按照最后一个window生成的DStream来对待RDD。
2.6.3.2 窗口
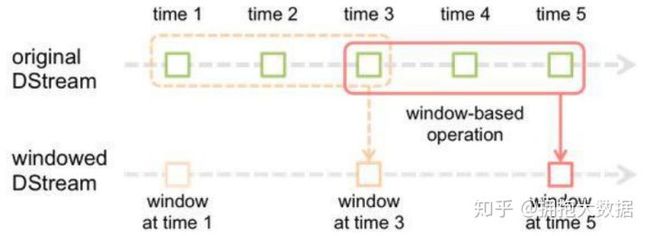
窗口的模型看起来是这样的:
假设批次间隔interval=1,窗口长度length=3,滑动间隔window_interval=2,每个批次数据为A,B,C,D,E,F,G
则统计的窗口为(A,B,C),(C,D,E),(E,F,G)
- 一开始先按interval的速度一路往前,直到走过length为止停下,执行第一个foreachRDD,因此第一个RDD是基于批次间隔的
- 接着每经过一个window_interval,就将从终点往前的length长度纳入本次的统计范围,但是实质上DStream只走了window_interval的距离,因此从第二个RDD开始都是基于滑动间隔的。
每个DStream实质上都是个窗口,只不过初始的DStream是基本窗口,它的窗口大小=滑动间隔=批次间隔。
代码演示
/**
推荐使用reduceByKeyAndWindow+foreachRDD进行窗口聚合操作:
@param mergeFunc 对窗口期间的数据进行聚合的方法,只传入该函数可以直接实现聚合
@param invFunc 利用上个窗口聚合的数据进行统计的高效算法,步骤如下:
1.先执行mergeFunc方法统计本次滑动间隔产生的数据nowValue
2.把新数据与上批数据累加:newValue = nowValue+oldValue
3.调用用户传入的invFunc方法,只保留两个窗口间重复的数据:invFunc(newValue - 上个批次的滑动数据)
*/
reduceByKeyAndWindow(mergeFunc,invFunc,windowLength,slideInterval)当滑动间隔=窗口长度时,传入invFunc是没有意义的,但如果两者不相等,传入invFunc对性能的提升很大。
2.6.2 实战
2.6.2.1 对接Kafka
receiver方式
sparkStream启动一个单独的线程receiver定时使用kafka高阶API向kafka拉取数据,并自动地更新zk的offsets。
优点:用户专注于业务,不需要关心偏移量的维护,代码简洁。
缺点:定时拉取数据可能造成sparkStream处理速度跟不上,导致数据丢失。
启动wal预写日志后,receiver会额外将数据写一份到本地,数据丢失的情况可以自动到日志中恢复,但是这种方式会重复写数据造成性能大幅浪费。此外,receiver与业务不在同一线程,但两者却又相互依赖,这导致我们在对业务进行高并发高吞吐的优化时不得不受制于receiver。
direct方式
sparkStream在业务代码中使用kafka低阶API直接连接kafka拉取数据进行消费。优点:
简化并行:kafka分区与RDD分区一致,可以一对一并行消费;
高效:数据的拉取与消费是顺序关系,不存在数据丢失问题,避免wal预写日志
稳定:处理完才拉取下一批数据,不会造成任务积压导致程序崩溃
强一致语义:可以通过手动维护偏移量的方式自定义实现一致性。
缺点:需要采用checkpoint或第三方平台维护偏移量,开发成本较高;实现监视需要额外人工开发。
2.6.2.2 解决数据积压
起因
sparkStream作为一个微流处理框架,每批次处理数据的时间应尽可能地接近批次间隔时间,才能保证流处理的高效和稳定。批处理时间<<批间隔时间:流量太小,集群闲置,浪费资源批处理时间>>批间隔时间:流量太大,集群繁忙,数据积压导致系统崩溃
流量控制
通过设置spark.streaming.kafka.maxRatePerPartition可以静态调整每次拉取的最大流量,但是需要重启集群。
反压机制
不需要重启集群就能根据当前系统的处理速度智能地调节流量阈值的方案
设置spark.streaming.backpressure.enabled为true开启反压机制后,sparkStreaming会根据上批次和本批次的处理速率,自动估算出下批次的流量阀值,我们可以通过改变几个增益比例来调控它的自动估算模型。
它的底层采用的是Guava的令牌桶算法实现的限流:程序到桶里取令牌,如果取到令牌就缓存数据,取不到就阻塞等待。通过改变放令牌的速度即可实现流量控制。
其它方案
- 如果增加kafka的分区数,spark也会增加相应数目的消费者去拉取,可以提升拉取效率;
- 如果降低批次间隔时间,每次拉取的数据量会减少,可以提升处理数据的速度,差距的间隔时间可以通过窗口来弥补。
2.6.2.3 批次累加
updataStateBykey
updataStateBykey是特殊的reduceByKey,
相当于oldValue+reduceByKey(newValue1,newValue2),通过传入一个updateFunc来实现批次间数据累加的操作。
实现它必须设置checkPoint路径,updataStateBykey会自动将每次计算的结果持久化到磁盘,批次间的数据则是缓存在内存中。
缺点:大量占用内存,大量产生小文件
mapwithState
mapwithState是spark1.6新增的累加操作,目前还在测试中,它的原理网上查不到,只知道是updataStateBykey的升级版,效率提升10倍。
缺点:资料不全,社区很小
不建议使用状态流累加操作,建议用窗口+第三方存储(redis)来达到同样的效果。
Spark Streaming中的updateStateByKey和mapWithState的区别和使用。
UpdateStateByKey:统计全局的key的状态,但是就算没有数据输入,他也会在每一个批次的时候返回之前的key的状态。这样的缺点就是,如果数据量太大的话,而且我们需要checkpoint数据,这样会占用较大的存储。
如果要使用updateStateByKey,就需要设置一个checkpoint目录(updateStateByKey自己是无法保存key的状态的),开启checkpoint机制。因为key的state是在内存维护的,如果宕机,则重启之后之前维护的状态就没有了,所以要长期保存它的话需要启用checkpoint,以便恢复数据。
实现案例:
object LoadKafkaDataDemo {
def main(args: Array[String]): Unit = {
val checkpointDir = "d://cp-20190810-2"
val ssc = StreamingContext.getOrCreate(checkpointDir, () => createContext)
ssc.start()
ssc.awaitTermination()
}
/**
* 该方法包含主要计算逻辑,返回StreamingContext
*/
def createContext = {
// 创建上下文
val conf = new SparkConf().setAppName("LoadKafkaDataDemo").setMaster("local[2]")
val ssc = new StreamingContext(conf, Milliseconds(5000))
ssc.checkpoint("hdfs://out-20190810-3")
// 指定请求kafka的配置信息
val kafkaParam = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
// 指定key的反序列化方式
"key.deserializer" -> classOf[StringDeserializer],
// 指定value的反序列化方式
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
// 指定消费位置
"auto.offset.reset" -> "latest",
// 如果value合法,自动提交offset
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("test1")
// 消费数据
val logs: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, kafkaParam)
)
// 对消费的数据做单词计数
// 其中key的数据不需要,仅仅留下value,因为value是实际的log日志数据
val lines: DStream[String] = logs.map(_.value())
val tups: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
val res = tups.updateStateByKey(func, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
res.print
ssc
}
val func = (it: Iterator[(String, Seq[Int], Option[Int])]) => {
it.map{
case (a,b,c) => {
(a, b.sum + c.getOrElse(0))
}
}
}
}
MapWithState:也是用于全局统计key的状态,但是它如果没有数据输入,便不会返回之前的key的状态,有一点增量的感觉。
这样做的好处是,我们可以只关心那些已经发生变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。这样即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储。
实现案例:
object MapWithState {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StreamingMapWithState")
.setMaster("local[2]")
val sc = SparkContext.getOrCreate(conf)
val ssc = new StreamingContext(sc, Seconds(2))
// 当调用updateStateByKey函数API的时候,必须给定checkpoint dir
// 路径对应的文件夹不能存在
ssc.checkpoint("hdfs://out-20190810-3")
/**
* key DStream的key数据类型
* values DStream的value数据类型
* state 是StreamingContext中之前该key的状态值
*/
val mappingFunction = (key: String, values: Option[Int], state: State[Long]) => {
// 获取之前状态的值
val preStateValue = state.getOption().getOrElse(0L)
// 计算出当前值
val currentStateValue = preStateValue + values.getOrElse(0)
// 更新状态值
state.update(currentStateValue)
// 返回结果
(key, currentStateValue)
}
val spec = StateSpec.function[String, Int, Long, (String, Long)](mappingFunction)
// 指定请求kafka的配置信息
val kafkaParam = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
// 指定key的反序列化方式
"key.deserializer" -> classOf[StringDeserializer],
// 指定value的反序列化方式
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
// 指定消费位置
"auto.offset.reset" -> "latest",
// 如果value合法,自动提交offset
"enable.auto.commit" -> (true: java.lang.Boolean)
)
// 指定topic
val topics = Array("test1")
// 消费数据
val logs: DStream[String] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topics, kafkaParam)
).map(_.value)
val resultWordCount: DStream[(String, Long)] = logs
.filter(line => line.nonEmpty)
.flatMap(line => line.split(" ").map((_, 1)))
.reduceByKey(_ + _)
.mapWithState(spec)
resultWordCount.print()
// 启动开始处理
ssc.start()
ssc.awaitTermination()
}
}
2.6.3 其他
2.6.3.1 SparkStreaming一个批次有多久?一个批次有多少条数据?
关于批次间隔需要结合业务来确定的,如果实时性要求高,批次间隔需要调小。
每个批次的数据量是和每天产生的数据量有直接关系,在计算的时候需要考虑峰值的情况。需要注意的是,批次间隔越长,每个批次计算的数据量会越多。
2.6.3.2 SparkStreaming消费速度赶不上生产速度怎么办?
在默认情况下,Spark Streaming 通过receiver或者Direct方式以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长。越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 OOM 问题而出现失败的情况。
Spark Streaming 1.5 之后的体系结构:
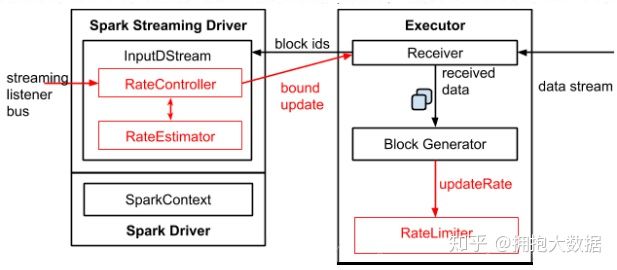
● 为了实现自动调节数据的传输速率,在原有的架构上新增了一个名为 RateController 的组件,这个组件继承自 StreamingListener,其监听所有作业的 onBatchCompleted 事件,并且基于 processingDelay、schedulingDelay 、当前 Batch 处理的记录条数以及处理完成事件来估算出一个速率;这个速率主要用于更新流每秒能够处理的最大记录的条数。速率估算器(RateEstimator)可以又多种实现,不过目前的 Spark 2.2 只实现了基于 PID 的速率估算器。● InputDStreams 内部的 RateController 里面会存下计算好的最大速率,这个速率会在处理完 onBatchCompleted 事件之后将计算好的速率推送到 ReceiverSupervisorImpl,这样接收器就知道下一步应该接收多少数据了。● 如果用户配置了 spark.streaming.receiver.maxRate 或 spark.streaming.kafka.maxRatePerPartition,那么最后到底接收多少数据取决于三者的最小值。也就是说每个接收器或者每个 Kafka 分区每秒处理的数据不会超过 spark.streaming.receiver.maxRate 或 spark.streaming.kafka.maxRatePerPartition 的值。详细的过程如下图所示:

如何启用?在 Spark 启用反压机制很简单,只需要将 spark.streaming.backpressure.enabled 设置为 true 即可,这个参数的默认值为 false。反压机制还涉及以下几个参数,包括文档中没有列出来的:● spark.streaming.backpressure.initialRate: 启用反压机制时每个接收器接收第一批数据的初始最大速率。默认值没有设置。● spark.streaming.backpressure.rateEstimator:速率估算器类,默认值为 pid ,目前 Spark 只支持这个,大家可以根据自己的需要实现。● spark.streaming.backpressure.pid.proportional:用于响应错误的权重(最后批次和当前批次之间的更改)。默认值为1,只能设置成非负值。weight for response to “error” (change between last batch and this batch)● spark.streaming.backpressure.pid.integral:错误积累的响应权重,具有抑制作用(有效阻尼)。默认值为 0.2 ,只能设置成非负值。weight for the response to the accumulation of error. This has a dampening effect.● spark.streaming.backpressure.pid.derived:对错误趋势的响应权重。 这可能会引起 batch size 的波动,可以帮助快速增加/减少容量。默认值为0,只能设置成非负值。weight for the response to the trend in error. This can cause arbitrary/noise-induced fluctuations in batch size, but can also help react quickly to increased/reduced capacity.● spark.streaming.backpressure.pid.minRate:可以估算的最低费率是多少。默认值为 100,只能设置成非负值。
以上为Spark的反压机制,再结合Spark资源的动态调整(在下面的题中有详细解释),就是该问题的完整解决方案
2.6.3.4 SparkStreaming的批次间隔,处理完的的数据存在哪里
批次间隔为SparkStreaming处理实时需求的时间间隔,需要根据业务需求来确定批次间隔。
实时需求的处理结果一般是保存在能快速读取的数据库中来提高效率,比如Redis、MongoDB、HBase。
2.6.3.5 Spark Streaming的窗口大小,每个窗口处理的数据量大小。
该问题一定要根据业务需求来确定,比如要实现的需求为:统计每分钟的前一个小时的在线人数。
上面需求的窗口大小(窗口长度)为1小时,然后再统计每个窗口需要处理的数据量。
窗口处理的数据量 = 每个批次处理的平均数据量 * 窗口的批次数量
2.6.3.7 MySQL的数据如何被Spark Streaming消费,假如:MySQL中用户名为张三,Spark已经消费了,但是此时我的名字改为了张小三,怎么办?如何同步?
Spark Streaming是批处理,每个批次的计算方式都是从MySQL中消费到数据进行统计,得到结果后会紧接着将结果持久化到对应的数据库,此时如果MySQL的某个字段值更新了,更新的值是无法影响以前批次的Streaming的结果的,只能影响以后批次的结果。除非是将之前的结果覆盖操作。
2.6.3.8 flink和spark streaming的区别
运行角色对比
Spark Streaming 运行时的角色(standalone 模式)主要有:
Master:主要负责整体集群资源的管理和应用程序调度;
Worker:负责单个节点的资源管理,driver 和 executor 的启动等;
Driver:用户入口程序执行的地方,即 SparkContext 执行的地方,主要是 DAG 生成、stage 划分、task 生成及调度;
Executor:负责执行 task,反馈执行状态和执行结果。
Flink 运行时的角色(standalone 模式)主要有:
Jobmanager: 协调分布式执行,他们调度任务、协调 checkpoints、协调故障恢复等。至少有一个 JobManager。高可用情况下可以启动多个 JobManager,其中一个选举为 leader,其余为 standby;
Taskmanager: 负责执行具体的 tasks、缓存、交换数据流,至少有一个 TaskManager;
Slot: 每个 task slot 代表 TaskManager 的一个固定部分资源,Slot 的个数代表着 taskmanager 可并行执行的 task 数。运行模型对比
Spark Streaming 是微批处理,运行的时候需要指定批处理的时间,每次运行 job 时处理一个批次的数据
Flink 是基于事件驱动的,事件可以理解为消息。事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入事件,通过触发计算更新状态,或外部动作对注入的事件作出反应。
编程模型对比
Spark Streaming
Spark Streaming 与 kafka 的结合主要是两种模型:
- 基于 receiver dstream;
- 基于 direct dstream。
以上两种模型编程机构近似,只是在 api 和内部数据获取有些区别,新版本的已经取消了基于 receiver 这种模式,企业中通常采用基于 direct Dstream 的模式。
val Array(brokers, topics) = args // 创建一个批处理时间是2s的context
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// 使用broker和topic创建DirectStream
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// 实现单词计数并打印
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print() // 启动流
ssc.start()
ssc.awaitTermination()通过以上代码我们可以 get 到:
- 设置批处理时间
- 创建数据流
- 编写transform
- 编写action
- 启动执行
Flink
Flink 与 kafka 结合是事件驱动,大家可能对此会有疑问,消费 kafka 的数据调用 poll 的时候是批量获取数据的(可以设置批处理大小和超时时间),这就不能叫做事件触发了。而实际上,flink 内部对 poll 出来的数据进行了整理,然后逐条 emit,形成了事件触发的机制。 下面的代码是 flink 整合 kafka 作为 data source 和 data sink:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableSysoutLogging();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
// create a checkpoint every 5 seconds
env.enableCheckpointing(5000);
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(parameterTool);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// ExecutionConfig.GlobalJobParameters
env.getConfig().setGlobalJobParameters(null);
DataStream input = env
.addSource(new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-topic"), new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.setParallelism(1).rebalance()
.keyBy("word")
.map(new RollingAdditionMapper()).setParallelism(0);
input.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("output-topic"), new KafkaEventSchema(),
parameterTool.getProperties()));
env.execute("Kafka 0.10 Example"); 从 Flink 与 kafka 结合的代码可以 get 到:
- 注册数据 source
- 编写运行逻辑
- 注册数据 sink
- 调用 env.execute 相比于 Spark Streaming 少了设置批处理时间,还有一个显著的区别是 flink 的所有算子都是 lazy 形式的,调用 env.execute 会构建 jobgraph。client 端负责 Jobgraph 生成并提交它到集群运行;而 Spark Streaming的操作算子分 action 和 transform,其中仅有 transform 是 lazy 形式,而且 DGA 生成、stage 划分、任务调度是在 driver 端进行的,在 client 模式下 driver 运行于客户端处。
任务调度对比
Spark Streaming任务调度
Spark Streaming 任务如上文提到的是基于微批处理的,实际上每个批次都是一个 Spark Core 的任务。对于编码完成的 Spark Core 任务在生成到最终执行结束主要包括以下几个部分:
- 构建 DGA 图;
- 划分 stage;
- 生成 taskset;
- 调度 task。
Flink 任务调度
对于 flink 的流任务客户端首先会生成 StreamGraph,接着生成 JobGraph,然后将 jobGraph 提交给 Jobmanager 由它完成 jobGraph 到 ExecutionGraph 的转变,最后由 jobManager 调度执行。
如上图所示有一个由 data source、MapFunction和 ReduceFunction 组成的程序,data source 和 MapFunction 的并发度都为 4,而 ReduceFunction 的并发度为 3。一个数据流由 Source-Map-Reduce 的顺序组成,在具有 2 个TaskManager、每个 TaskManager 都有 3 个 Task Slot 的集群上运行。
可以看出 flink 的拓扑生成提交执行之后,除非故障,否则拓扑部件执行位置不变,并行度由每一个算子并行度决定,类似于 storm。而 spark Streaming 是每个批次都会根据数据本地性和资源情况进行调度,无固定的执行拓扑结构。 flink 是数据在拓扑结构里流动执行,而 Spark Streaming 则是对数据缓存批次并行处理。
时间机制对比
流处理程序在时间概念上总共有三个时间概念:
处理时间
处理时间是指每台机器的系统时间,当流程序采用处理时间时将使用运行各个运算符实例的机器时间。处理时间是最简单的时间概念,不需要流和机器之间的协调,它能提供最好的性能和最低延迟。然而在分布式和异步环境中,处理时间不能提供消息事件的时序性保证,因为它受到消息传输延迟,消息在算子之间流动的速度等方面制约。
事件时间
事件时间是指事件在其设备上发生的时间,这个时间在事件进入 flink 之前已经嵌入事件,然后 flink 可以提取该时间。基于事件时间进行处理的流程序可以保证事件在处理的时候的顺序性,但是基于事件时间的应用程序必须要结合 watermark 机制。基于事件时间的处理往往有一定的滞后性,因为它需要等待后续事件和处理无序事件,对于时间敏感的应用使用的时候要慎重考虑。
注入时间
注入时间是事件注入到 flink 的时间。事件在 source 算子处获取 source 的当前时间作为事件注入时间,后续的基于时间的处理算子会使用该时间处理数据。
相比于事件时间,注入时间不能够处理无序事件或者滞后事件,但是应用程序无序指定如何生成 watermark。在内部注入时间程序的处理和事件时间类似,但是时间戳分配和 watermark 生成都是自动的。
Spark 时间机制
Spark Streaming 只支持处理时间,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据。
Flink 时间机制
flink 支持三种时间机制:事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。
容错机制及处理语义
Spark Streaming 保证仅一次处理
对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰一次处理语义。
对于 Spark Streaming 与 kafka 结合的 direct Stream 可以自己维护 offset 到 zookeeper、kafka 或任何其它外部系统,每次提交完结果之后再提交 offset,这样故障恢复重启可以利用上次提交的 offset 恢复,保证数据不丢失。但是假如故障发生在提交结果之后、提交 offset 之前会导致数据多次处理,这个时候我们需要保证处理结果多次输出不影响正常的业务。
由此可以分析,假设要保证数据恰一次处理语义,那么结果输出和 offset 提交必须在一个事务内完成。在这里有以下三种做法:
- repartition(1) Spark Streaming 输出的 action 变成仅一个 partition,这样可以利用事务去做
- 用幂等写入的方式实现
- 将结果和 offset绑定到 一起提交
也就是结果数据包含 offset。这样提交结果和提交 offset 就是一个操作完成,不会数据丢失,也不会重复处理。故障恢复的时候可以利用上次提交结果带的 offset。
Flink 与 kafka 0.11 保证仅一次处理
若要 sink 支持仅一次语义,必须以事务的方式写数据到 Kafka,这样当提交事务时两次 checkpoint 间的所有写入操作作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
在一个分布式且含有多个并发执行 sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一致性的结果。Flink 使用两阶段提交协议以及预提交(pre-commit)阶段来解决这个问题。