大米运维 -- 监控体系搭建
文章目录
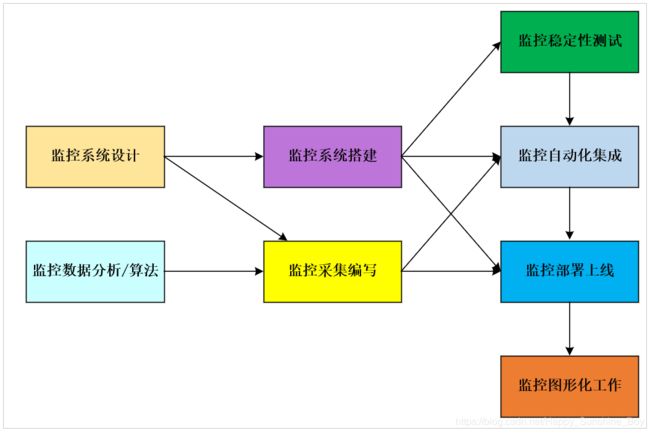
- 0.监控体系框架
- 1.监控系统设计
- 1.1 评估系统
- 1.2 监控种类
- 1.3 监控技术方案/软件选取(主观因素)
- 1.4 监控体系的人员安排
- 2.监控系统搭建
- 3.数据采集编写
- 3.1 可选用脚本作为采集途径
- 3.2 数据采集的形式分类
- 3.2.1 一次性采集
- 3.2.2 后台式采集
- 3.2.3 桥接式采集
- 4.监控数据分析和方法
- 5.监控稳定性测试
- 6.监控自动化
- 7.监控图形化工作
0.监控体系框架
1.监控系统设计
1.1 评估系统
评估系统的业务流程、业务种类、架构体系,各个企业的产品不同、业务方向不同、程序代码不同、系统架构更不同,对于各个地方的细节都需要有一定程度的认知,才可以开起设计的源头;
1.2 监控种类
监控项种类一般可分为:业务级别监控、系统级别监控、网络监控、程序代码监控、日志监控、用户行为分析监控、其他种类监控等;大的分类,嗨哟更多细小的分类;
例如:
业务监控: 可以包含,用户访问QPS(TPS 每秒钟request/事务 数量)、DAU(Daily Active User)日活跃用户数量、访问状态(http code)、业务接口(登录、注册、聊天、上传、留言、短信、搜索等)、产品转化率、充值额度、用户投诉等等,在宏观的概念层上;
系统监控: 主要跟操作系统相关,基本监控项包括:CPU、内存、硬盘、IO、TCP链接、流量等等;
网络监控: (IDC)对网络状态的监控(交换机、路由器、防火墙、VPN)互联网公司必不可少,但是很多时候又被忽略,例如:内网之间(物理内网、逻辑内网、可用区、创建虚拟机、内网IP)外网、丢包率、延迟等等;
日志监控: 监控中的重头戏(ELK),往往单独设计和搭建,全部种类的日志都有需要采集(syslog、soft、网络设备、用户行为);
程序监控: 一般需要和开发人员配合,程序中嵌入各种接口,直接获取数据或者特指的日志格式;
1.3 监控技术方案/软件选取(主观因素)
各种监控软件层出不穷,开源的、商业的、自行开发的,几百种可选方案,架构师凭借一些因素,开始选材。针对企业的架构特点,大小、种类、人员多少等等,选取合适的技术方案。
1.4 监控体系的人员安排
运维团队的任务划分,责任到人,分块进行;
开发团队的配合人员选取,很多监控涉及的工作,都需要跟开发人员配合才可以进行;
2.监控系统搭建
- 单点服务端的搭建(prometheus)
- 单点客户端的部署
- 单点客户端服务器测试
- 采集程序单点部署
- 采集程序批量部署
- 监控服务端HA/cloud(自己定制)
- 监控数据图形化搭建(Grafana)
- 报警系统测试
- 监控规则测试
- 监控+报警联合测试
- 正式上线部署
3.数据采集编写
3.1 可选用脚本作为采集途径
例如:shell、python、awk、lua(Nginx安全控制,功能分类)、php、perl、go等等;
shell:运维的入门脚本,任何和性能、后台、界面无关的逻辑,都可以实现最快速的开发(shell是在运维领域里,开发速度最快,难度最低的);
python:各种扩展功能,扩展库,功能丰富,伴随各种程序的展示+开发框架(如Django)等,可以实现快速的中高档次的平台逻辑开发,目前在运维界,除去shell这个所有人必须会的脚本外,火爆程度就属python了;
awk:本身是一个实用命令,也是一门庞大的编程语言,结合shell脚本,或者独立都可以使用。在为本和标准输出处理上,有很大优势;
lua:多用于nginx的模块结合;
php:在大型互联网开发中,目前有退潮的趋势,在运维中工具开发还是很依赖php;
perl:传说中对文本处理最快的脚本语言(但是代码可读性不强);
go:新型语言,目前在开发和运维中很火,工资高,开发速度快,成型早;
作为监控数据采集,首推shell+python;
3.2 数据采集的形式分类
3.2.1 一次性采集
例如:使用比较简单的shell ./monitor.sh(ps -ef | grep, netstats -an| wc) + crontab的形式,按10秒、30秒、一分钟 这样的频率去 单词采集;
优点: 一次性采集的模式,稳定性较好,不容易出现各种错误和性能瓶颈,且开发逻辑简单,实现快速;
缺点: 一次性采集,对于有些采集项目,实现起来不够智能,也不够到位。例如:日志的实时采集;
3.2.2 后台式采集
采集程序以守护进程运行在Linux后台,持续不断的采集数据:prometheus exporter;例如:python/go 开发的daemon程序,后台持续不断的采集;
优点: 后台采集程序,数据准确性高,采集密度精细,管理方便;
缺点: 后台采集程序,如果开发过程中不够仔细,可能会出现各种内存泄漏、僵尸进程、性能瓶颈等问题,且开发周期较长;
3.2.3 桥接式采集
本身以后台进程运行,但是采集不能独立,依然跟服务器关联,以桥接方式收集采集数据;
例如:NRPE for nagios
4.监控数据分析和方法
例如:采集CPU的七种等待状态参数,采集用户每秒访问请求量QPS;
对于这些 “基本单位” 的数据采集,本身是必须的,也是没有疑问的;
但是这里有一个问题?
采集回来的单位数据,如果没有懂行的人,将它们形成监控公式和报警阈值,那采集数据就没有任何意义了。
CPU来举例:

CPU采集回来的平均负载数值,以及CPU的时间片分步百分比 nagios top
如果不懂得Linux中CPU各种参数得深入原理:平均负载是如何计算得、CPU的时间片分步是如何分类的、什么叫做用户态/内核态、CPU等待/处理时间、什么是 Interruptable(可中断)/uniterruptable(不可中断)CPU等待等等这些概念。那么即便数据被采集回来的再精细准确,也利用不好。
所以,监控的数据分析和算法,其实非常依赖架构师对Linux操作系统的各种底层知识的掌握;
如果使用老式的傻瓜式监控如:nagios,里面的监控脚本很全面(shell sh return, bin),生成报警规则和阈值也很简单,缺点显而易见:监控的太粗糙,实用性不强,另外,也不利于开发人员的提高;
例如:nagios监控中对CPU高不高的监控判断,就依据一个当前的load值 >5 就告警 >10 就报警,请问这种方式的CPU报警有什么意义?有利于通过监控找到真正的问题吗??
举个例⼦:如果想通过Prometheus实现对⽤户访问QPS的精确监控,那么对于监控图形、曲线、QPS上涨、QPS下跌、QPS凸起、QPS和历史数据的⽐较⽅法等等这些,都属于业务级别的监控阈值类型 ,需要有专业的数据分析⼈员的协助才可以算出优良的算法。
例如: 如果现在想针对当前QPS下跌率进⾏报警计算, 那么⽤什么样的公式,针对我们的业务类型更贴切?
是选择计算当前5分钟内的平均值,当 < ⼀个固定数值的时候报警合适?
还是选择计算当前10分钟的总量,然后和前⼀个⼩时同⼀时段⽐较合适?
还是选择计算当前⼀⼩时的平均值和过去⼀周内,每⼀天的同⼀时段的时间⽐较合适?
。。。。
以此类推,这些数据算法本⾝跟Linux⽆关,只有⾮常专业的数据计算团队才可以给出⼀个最合理的算 法协助完成报警规则的制定;
5.监控稳定性测试
不管是⼀次性采集,还是后台采集,只要是在Linux上运⾏的东西,都会多多少少对系统产⽣⼀定的影响;
稳定性测试:就是通过⼀段时间的单点部署观察,对线上有没有任何影响;
6.监控自动化
监控客户端的批量部署,监控服务端的HA再安装,监控项⽬的修改,监控项⽬的监控集群变化,种种这些地⽅都需要⼤量的⼈⼯;
⾃动化的引进,会很⼤程度上缩短我们对监控系统的维护成本;
这⾥给出⼏个实例: Puppet(配置⽂件部署),Jenkins(CI 持续集成部署) , CMDB(运维⾃动化的最⾼资源管理平台和理念 )。。。。等等 利⽤好如上这⼏个聚的例⼦,就可以实现对监控⾃动化的掌控;
7.监控图形化工作
采集的数据和准备好的监控算法,最终需要⼀个好的图形展⽰,才能发挥最好的作⽤,监控的设计搭建需要⼤量的技术知识,但是对于⼀个观察者来说(⽼板),往往不需要多少技术,只要能看懂图就好(例如:⽼板想看看,当前⽤户访问量状况,想看看 整体CPU⾼不⾼ 等等)所以 ,监控的成图(Grafana)⼯作也是很重要的⼀个内容;