Networking 基本术语/概念
目录
文章目录
- 目录
- 基本概念
- 全双工
- 通用路由封装(GRE)
- 安全隧道(IPSec)
- 数据中心 I/O 聚合
- InfiniBand 架构
- 数据中心 I/O 聚合
- 以太网光纤通道 FCoE
- NVMe Over Fabrics
- 虚拟链路聚合技术 vPC
- 自动标签技术 MPLS、VPLS
- 二层多路径技术 TRILL/FabricPath
- 二层 Overlay 技术 OTV
- 虚拟化精确定位技术 LISP
基本概念
什么是链接?链接是指两个设备之间的连接。它包括用于一个设备能够与另一个设备通信的电缆类型和协议。
什么是骨干网?骨干网络是集中的基础设施,旨在将不同的路由和数据分发到各种网络。它还处理带宽管理和各种通道。
什么是点对点链接?它是指网络上两台计算机之间的直接连接。除了将电缆连接到两台计算机的 NIC 卡之外,点对点连接不需要任何其他网络设备。
UTP 电缆允许的最大长度是多少?UTP 电缆的单段具有 90 到 100 米的允许长度。这种限制可以通过使用中继器和开关来克服。
什么是 RIP?RIP,路由信息协议的简称,路由器用于将数据从一个网络发送到另一个网络。它通过将其路由表广播到网络中的所有其他路由器来有效地管理路由数据。它以跳数为单位确定网络距离。
什么是代理服务器,它们如何保护计算机网络?代理服务器主要防止外部用户识别内部网络的 IP 地址。不知道正确的 IP 地址,甚至无法识别网络的物理位置。代理服务器可以使外部用户几乎看不到网络。
实施容错系统的重要性是什么?有限吗?容错系统确保持续的数据可用性。这是通过消除单点故障来实现的。但是,在某些情况下,这种类型的系统将无法保护数据,例如意外删除。
10Base-T 是什么意思?10 是指数据传输速率,在这种情况下是 10Mbps。Base 是指基带。T 表示双绞线,这是用于该网络的电缆。
什么是 NOS?NOS 网络操作系统是专门的软件,其主要任务是向计算机提供网络连接,以便能够与其他计算机和连接的设备进行通信。
什么是 DoS?DoS 拒绝服务攻击是试图阻止用户访问互联网或任何其他网络服务。这种攻击可能有不同的形式,由一群永久者组成。这样做的一个常见方法是使系统服务器过载,使其无法再处理合法流量,并将被强制重置。
OSPF 的主要目的是什么?OSPF 开放最短路径优先,是使用路由表确定数据交换的最佳路径的链路状态路由协议。
什么是网关?网关提供两个或多个网段之间的连接。它通常是运行网关软件并提供翻译服务的计算机。该翻译是允许不同系统在网络上通信的关键。
如何使用路由器管理网络?路由器内置了控制台,可让您配置不同的设置,如安全和数据记录。您可以为计算机分配限制,例如允许访问的资源,或者可以浏览互联网的某一天的特定时间。您甚至可以对整个网络中看不到的网站施加限制。
光纤与其他介质有什么优势?光纤的一个主要优点是不太容易受到电气干扰。它还支持更高的带宽,意味着可以发送和接收更多的数据。长距离信号降级也非常小。
CSMA/CD 和 CSMA/CA 有什么区别?CSMA/CD 碰撞检测,每当碰撞发生时重新发送数据帧。CSMA/CA 碰撞避免,将首先在数据传输之前广播意图发送。
什么是组播路由?组播路由是一种有针对性的广播形式,将消息发送到所选择的用户组,而不是将其发送到子网上的所有用户。
动态主机配置协议如何协助网络管理?网络管理员不必访问每台客户端计算机来配置静态 IP 地址,而是可以应用动态主机配置协议来创建称为可以动态分配给客户端的范围的 IP 地址池。
什么是 RSA 算法?RSA 是 Rivest-Shamir-Adleman 算法的缩写。它是目前最常用的公钥加密算法。
100Base-FX 网络的最大段长度是多少?使用 100Base-FX 的网段的最大允许长度为 412 米。整个网络的最大长度为 5 公里。
全双工
全双工(Full Duplex)是通讯传输的一个术语。通信允许数据在两个方向上同时传输,它在能力上相当于两个单工通信方式的结合。全双工指可以同时(瞬时)进行信号的双向传输(A→B 且 B→A)。
相对的,半双工(Half Duplex)就是指一个时间段内只有一个动作发生,半双工已经逐渐退出了历史舞台。而单工就是在只允许 A 方向 B 方传送信息,而 B 方不能向 A 方传送 ,比喻汽车的单行道。
全双工在微处理器与外围设备之间采用了发送线和接受线各自独立的方法,可以使数据在两个方向上同时进行传送操作。发送数据的同时也能够接收数据,两者同步进行。目前的网卡一般都支持全双工。
通用路由封装(GRE)
Linux 原生支持 5 种 IP 隧道:ipip、gre、sit、isatap、vti。
GRE(Generic Routing Encapsulation,通用路由封装)是一种隧道协议,与 VxLAN 类型,通过将其他协议封装在一个点对点的连接中,实现跨公网的网络互联。


如上图,一个 GRE 端点(e.g. Router1)可能存在多个隧道,因而需要有一个标志位来唯一标识当前网络包属于哪个隧道,这就是 GRE Header 中的 key,简称 gre key。

安全隧道(IPSec)
IPSec,安全隧道,意味着需要具有以下三个特点:
- 信息完整性(认证)
- 信息的私密性(加密)
- 信息不会被 Replay

IPSec 有一套协议来保证上述三点特性。
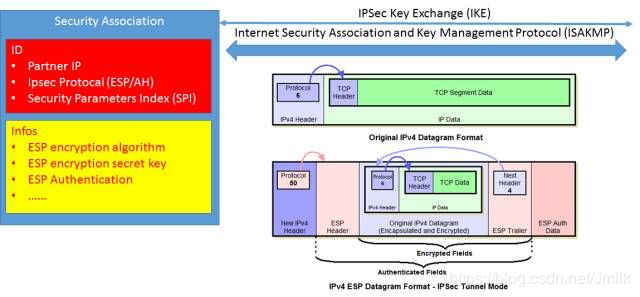
IPSec 隧道的连接同样具有两端的概念,两端之间通过对称加密来保证私密性。所以两端都要建立 Security Association,保存两边约定好的加密协议,对称秘钥,对方的 IP 地址等等信息,对称秘钥要通过协议互换(Exchange)。两端建立连接之后,就需要对原始的网络包进行认证和加密。通过在原始网络包外层添加 ESP Header 来实现加密。
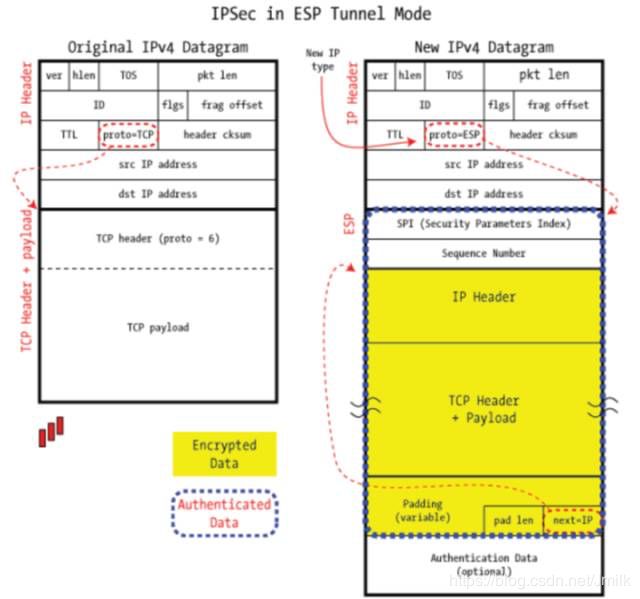
IPSec 隧道常被作为 VPN,用于打通两个 VPC,或者用于打通公有云和私有云。
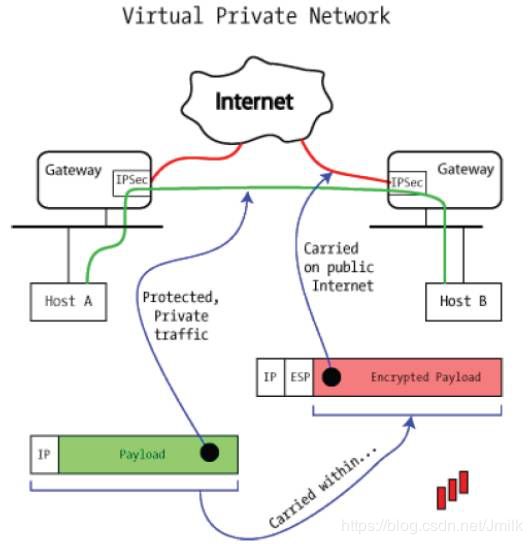
NOTE:GRE 可以和 IPSec 一起使用,网络包的结构如下。

数据中心 I/O 聚合
InfiniBand 架构
InfiniBand 是一种基于交换结构和点到点通信的 I/O 接口,是一种长缆线的连接方式,具有高速、低延迟的传输特性。InfiniBand 以极高的传输速度将服务器、存储设备和网络设备连接在一起。基于 InfiniBand 技术的网卡的单端口带宽可达 20Gbps,最初主要用在高性能计算系统中,近年来随着设备成本的下降,InfiniBand 也逐渐被用到企业数据中心。
InfiniBand 由 4 中基本设备组成,包括主机通道适配器 HCA、目标通道适配器 TCA、交换机及路由器。其中 HCA 功能较强,具有微处理器,参与管理。TCA 功能比较简单。交换机和路由器是用于连接的设备。

为了发挥 InfiniBand 设备的性能,需要一整套的软件栈来驱动和使用,这其中最著名的就是 OFED(OpenFabrics Enterprise Distribution),基于 InfiniBand 的设备实现了 RDMA(Remote Direct Memory Access)。RDMA 的最主要的特点就是零拷贝和旁路操作系统,数据直接在外部设备和应用程序内存之间传递,这种传递不需要 CPU 的干预和上下文切换。OFED 还实现了一系列的其它软件栈:IPoIB(IP over InfiniBand)、SRP(SCSI RDMA Protocol)等,这就为 InfiniBand 聚合存储网络和互联网络提供了基础。OFED 现已经被主流的 Linux 发行版本支持,并被整合到微软的 Windows Server 中。

数据中心 I/O 聚合
以太网光纤通道 FCoE
就在大家认为 InfiniBand 是数据中心连接技术的未来时,10Gb 以太网的出现让人看到了其它选择,以太网的发展好像从来没有上限,目前它的性能已经接近 InfiniBand,而从现有网络逐渐升级到 10Gb 以太网也更易为用户所接受。
FCoE(FiberChannel Over Ethernet)的出现为数据中心互联网络和存储网络的聚合提供了另一种可能。FCoE 可将传统的 FC 存储网络功能融合到以太网中,思路是将光纤信道直接映射到以太网线上,这样光纤信道就成了以太网线上除了互联网网络协议之外的另一种网络协议。FCoE 能够很容易的和传统光纤网络上运行的软件和管理工具相整合,因而能够代替光纤连接存储网络。虽然出现的晚,但 FCoE 发展极其迅猛。与 InfiniBand 技术需要采用全新的链路相比,企业 IT 更愿意升级已有的以太网。在两者性能接近的情况下,采用 FCoE 方案似乎性价比更高。
大型数据中心利用 FCoE 等新技术将存储传输和 IP 传输融合到以太网连接上,而标准的 STP 将不再适合融合网络或超大型数据中心的扩展。随着 FCoE 采用率的提高,企业存储开始考虑加入 IP 网络上的其他协议,从存储的角度来看,TRILL 可以代替 STP。
NVMe Over Fabrics
NVMe 传输是一种抽象协议层,旨在提供可靠的 NVMe 命令和数据传输。为了支持数据中心的网络存储,通过 NVMe over Fabric 实现 NVMe 标准在 PCIe 总线上的扩展,以此来挑战 SCSI 在 SAN 中的统治地位。NVMe over Fabric 支持把 NVMe 映射到多个 Fabrics 传输选项,主要包括 FC、InfiniBand、RoCE v2、iWARP 和 TCP。
NVMe Over Fabrics 使用 RDMA 或光纤通道(FC)架构等 Fabric 技术取代 PCIe 传输。如图所示,除了基于 RDMA 架构的传输包括以太网(ROCE),InfiniBand 和 iWARP,当然,采用基于原生 TCP(非 RDMA)传输也是可能的(截至 2018 年 7 月,TCP 技术仍在研发阶段)。
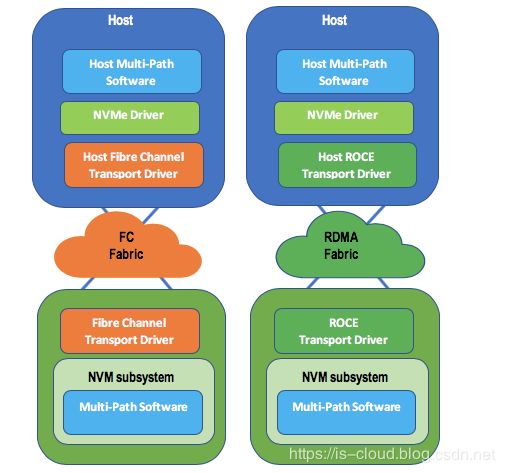
图中所示的 NVM 子系统是一个或多个物理结构接口(端口)的集合,每个单独的控制器通常连接到单个端口。多个控制器可以共享一个端口。尽管允许 NVM 子系统的端口支持不同的 NVMe 传输,但实际上,单个端口可能仅支持单个传输类型。NVM 子系统包括一个或多个控制器,一个或多个命名空间,一个或多个 PCI Express 端口,非易失性存储器存储介质,以及控制器和非易失性存储器存储介质之间的接口。
详细资料请参考:
- https://mp.weixin.qq.com/s/gl-RbUUtdtxK3o17nFNcxA
- https://mp.weixin.qq.com/s/2LTuDRDGeSPefCJdWnLH7w
虚拟链路聚合技术 vPC
传统三层网络架构的链路冗余是通过双链路上连的方式来实现的,这种方式明显会具有一个环路,为了避免广播风暴的出现,会应用 STP 生成树协议来将其中一条链路 Block 掉。显然,这种方式实现的冗余是不会增加网络带宽的。如果想用链路聚合的方式来做双链路连到不同的设备上,但是 Port Channel 功能又不支持跨设备聚合。由此,就产生了与服务器虚拟化对单个网卡承载的流量变大的冲突,解决这个问题的技术就是 vPC。

**vPC(Virtual Port Channel,虚拟链路聚合)**可以实现网络冗余,可以跨设备进行端口聚合,增加链路带宽,当链路故障时比生成树协议收敛时间还快。简单来说,vPC 功能即解决了 Port Channel 不能跨设备的问题,又提供了上联设备级的冗余,解决了存在 STP 的问题)即增强网络冗余又能增加网络带宽)。

vPC 与传统链路聚合相比的优势:
- 允许下行设备通过 Port Channel 跨两个不同的上行设备。
- 避免了以太网环路,也就不再需要增加生成树(STP)的功能。
- 增加了上行带宽。
- 当链路或是设备出现故障可以实现快速的故障恢复。
- 确保高可靠性。
- 双活工作机制。
- 实现网络拓扑简单化。
PS:Port Group 是交换机配置层面上的一个物理端口组,配置到 Port Group 里面的物理端口才可以参加端口聚合,并成为 Port Channel 里的某个成员端口。在逻辑上,Port Group 并不是一个端口,而是一个端口序列。加入 Port Group 中的物理端口满足某种条件时进行端口聚合,形成一个 Port Channel,这个 Port Channel 具备了逻辑端口的属性,才真正成为一个独立的逻辑端口。端口聚合是一种逻辑上的抽象过程,将一组具备相同属性的端口,抽象成一个逻辑端口。Port Channel 是一组物理端口的集合体,在逻辑上被当作一个物理端口。对用户来讲,完全可以将这个 Port Channel 当作一个端口使用,因此不仅能增加网络的带宽,还能提供链路的备份功能,以及负载均衡。
自动标签技术 MPLS、VPLS
MPLS 的标签功能是通过 L3 路由技术在发送 L2 数据帧之前就事先走了一遍将要经过的每一个路由器,继而确定好并把标签事前设置好(通过标准交换的专用协议,或者经过扩展的 BGP 协议)。如此的,数据帧再经过路由器时就只需要经过 L2 的硬件转发,而不再需要 L3 的硬件路由了,从而大大提高了转发效率。MPLS 主要用在广域网中。
VPLS(Virutal Private Lan Service,虚拟私有网络服务)有点类似于 MPLS,只不过 VPLS 中的 PE 设备除了基本的隧道建立之外,还要负责 MAC 地址的学习。
二层多路径技术 TRILL/FabricPath
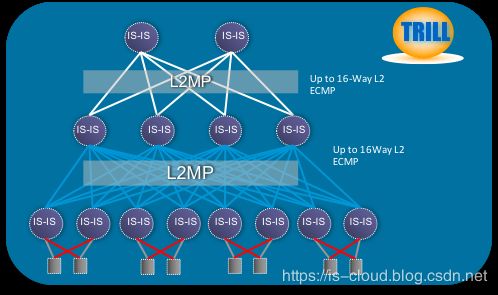
在 Spine-Leaf 的二层架构中,核心层与接入层设备有两个问题是必须要解决的,一是拓扑无环路,二是多路径转发。但在传统 Ethernet 转发中只有使用 STP 才能确保无环,但 STP 导致了多路径冗余中部分路径被阻塞浪费带宽,给整网转发能力带来了瓶颈。因此云计算中需要新的技术在避免环路的基础上提升多路径带宽利用率,这是推动 TRILL 这些新技术产生的根本原因。TRILL 目标是在大型 Ethernet 网络中解决多路径而无 STP 环路的方案。控制平面上 TRILL 引入了 ISIS 做为 L2 寻址协议,TRILL 封装是 MAC in MAC 方式。
- TRILL(Transparent Interconnection of lots of links,多链路透明互联):是 IETF 为实现数据中心大二层扩展制定的一个标准,该协议的核心思想是将成熟的三层路由的控制算法引入到二层交换中,为原先的 L2 报文加一个新的封装(隧道封装),转换到新的地址空间上进行转发。而新的地址有与 IP 类似的路由属性,具备大规模组网、最短路径转发、等价多路径、快速收敛、易扩展等诸多优势,从而规避 STP/MSTP 等技术的缺陷,实现健壮的大规模二层组网。
FabricPath 和 TRILL 同样用于在大二层实现多路径,但 FabricPath 是 Cisco 的私有标准。在二层实现一个类似三层的控制平面,基于 Switch ID 进行路由,还添加了一个 TTL 字段,在交换中转发一次就减自动 1 从而不会形成环路,也就不再需要再运行 STP 协议了。最后,引入简化的 IS-IS 协议来建立全网设备的拓扑,并基于这个拓扑来计算出最优路径来对数据进行转发(这样转发不再依赖 MAC 地址,在转发前就已经确定了路径)。
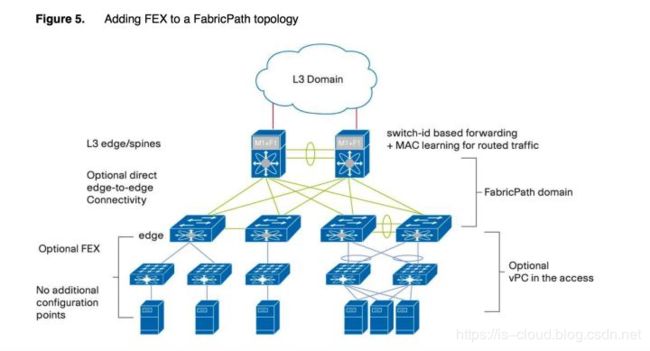
虚拟机要在数据中心漂移解决的方案有 FEX 和 FabricPath,FEX 能将虚拟机的漂移范围扩展到同一对汇聚交换机之间,而 FabricPath 可以将虚拟机漂移的范围拓展到整个数据中心,当然前提都是在二层的情况下。
二层 Overlay 技术 OTV
OTV (Overlay Transport Virtualization)是一项 MAC in IP 技术,最早提出控制面和转发面分离,基于 ISIS 做为控制协议实现 MAC 地址路由表交换和管理,OTV 可提供一种 Overlay 网络,能够在分散的二层域之间实现二层连接。数据平面 OTV 以 MAC in IP 方式封装原始 Ethernet 报文,报文结构非常类似 VxLAN 技术。
OTV 使得局域网可以跨越数据中心,很多应用需要使用广播和本地链路进行多播,OTV 技术能够跨地域的处理广播流和多播,这使得这些应用所在的虚拟机在数据中心之间迁移后仍然能够正常工作。OTV 扩展了数据链路层网络,实际上也扩展了其相关的 IP 子网,需要 IP 路由同样的做改变,这就引出了新的问题,这个问题就由 LISP 来解决了。
OTV 的核心思想是通过 MAC in IP 的方式,通过隧道技术穿越 L3 层网络实现 L2 层网络的互通。白话一点就是通过软件方式重新定义 L2 层帧头,再通过 L3 层的遂道如 GRE 等发送给接收方,接收方再通过软件方式解析数据帧。很多虚拟交换机都是通过这种方式实现的,如 Hyper-v。它和 FabricPath 等一样仍然是自定义二层帧会在建立邻居关系之后通过广播或多播交换各自的 MAC 地址表从而计算出一张路由表,在发送第一个数据帧时就已经确定了路径。且对三层网关(HSRP/VRRP/GLBP)进行优化具备内置的负载均衡。
- HSRP(Host Standby Router Protocol,热备份路由协议)
- VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)
- GLBP(Gateway Load Balancing protocol,网关负载均衡协议)
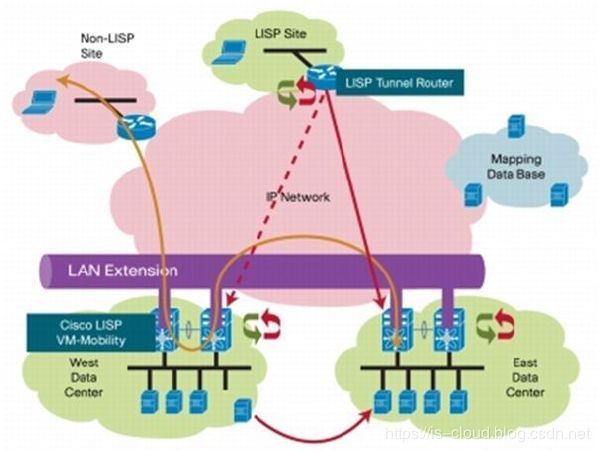
虚拟化精确定位技术 LISP
传统的网络地址 IP 蕴含了两个含义:
- 一个是你是谁(ID)
- 另一个是你在哪里(Locator)
这样带来的一个问题就是如果虚拟机的 Locator 变了,那么 IP 就必须跟着变化。LISP 的目标是将 ID 和 Locator 分开,再通过维护一个映射系统将两者关联。这样虚拟机和服务器在网络不同位置进行迁移时 依然可以保持相同的 IP 地址。LISP 可以保证虚机移动到新的数据中心后保持原来的 IP 地址,同时对外发布的网关也随之移动到新地址,这个过程无需更新 DNS 配置,或者部署专用的流量负载均衡设备。
LISP(Locator/Identifier Separation Protocol,位置/身份分离协议),主要用于解决外部访问在多数据中心寻址的问题。在 LISP 中,原有的网络 IP 地址被分成 EID(End-identifier)和 RLOC(Routing-locator)。其中,EID 用于标志主机,不具备全局路由功能;RLOC 用于全网路由。名址分离网络自然会引入名与址的映射,即 LISP 中 EID-to-RLOC 映射。
利用 OTV 和 LISP 结合可以很好的用于支持虚机扩展、集群以及在线 VMotion 的场景,当扩展子网时,LISP 目的是解决服务器或虚机的位置信息并提供的最佳径路;在当时通过 LISP 和 OTV 的组合可以解决虚拟化资源的迁移和业务连续等技术难题。