数据中心网络架构演进 — CLOS 网络模型的第三次应用
目录
文章目录
- 目录
- 前文列表
- CLOS Networking
- 胖树(Fat-Tree)型网络架构
- Fat-Tree 拓扑
- Fat-Tree 的缺陷
- 叶脊(Spine-Leaf)网络架构
- Spine-Leaf 拓扑
- Spine-Leaf 与光模块
- Spine-Leaf 的优势
- Spine-Leaf 的缺陷
前文列表
《数据中心网络架构演进 — 从传统的三层网络到大二层网络架构》
《数据中心网络架构演进 — 从物理网络到虚拟化网络》
CLOS Networking
自从 1876 年电话被发明之后,电话交换网络历经了人工交换机、步进制交换机、纵横制交换机等多个阶段。20 世纪 50 年代,纵横制交换机处于鼎盛时期,纵横交换机的核心,是纵横连接器。
- 纵横制接线器

- 纵横连接器交叉点示意图
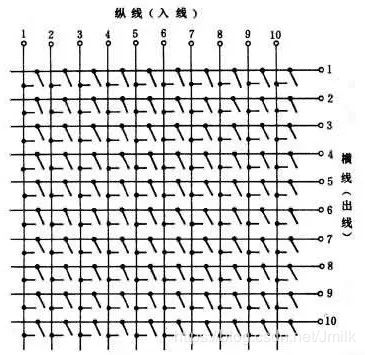
因为开关矩阵很像一块布的纤维,所以交换机的内部架构被称为 Switch Fabric(纤维),这是 Fabric 成为计算机网络专业术语的起源。最简单的 Switch Fabric 架构是 Crossbar 纵横模型,这是一个开关矩阵,每一个 Crosspoint(交点)都是一个开关,交换机通过控制开关来完成输入到特定输出的转发。一个 Crossbar 模型如下所示。
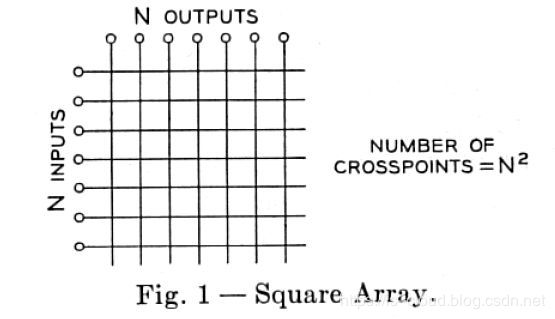
随着电话用户数量急剧增加,网络规模快速扩大,交换机的端口数量逐渐增多。基于 Crossbar 模型的交换机的开关密度,随着交换机端口数量 N 呈 O(N^2) 增长。相应的功耗,尺寸,成本也急剧增长。在高密度端口的交换机上,继续采用 Crossbar 模型性价比越来越低。
1953 年,Charles Clos 发表了一篇名为《A Study of Non-blocking Switching Networks》的文章,介绍了一种用多级设备来实现无阻塞电话交换的方法,这是 CLOS 网络的起源。
- Charles Clos 曾经是贝尔实验室的研究员(右一)

CLOS 交换模型的核心思想是:用多个小规模、低成本的单元,构建复杂、大规模的网络。简单的 CLOS 网络是一个三级互连架构,包含了输入级,中间级,输出级。下图中的矩形都是规模小得多的转发单元,相应的成本也很低。简单来说,CLOS 就是一种多级交换架构,目的是为了在输入输出增长的情况下尽可能减少中间的交叉点数。

下图中,m 是每个子模块的输入端口数,n 是每个子模块的输出端口数,r 是每一级的子模块数,经过合理的重排,只要满足公式: r2≥max(m1,n3),那么,对于任意的输入到输出,总是能找到一条无阻塞的通路。
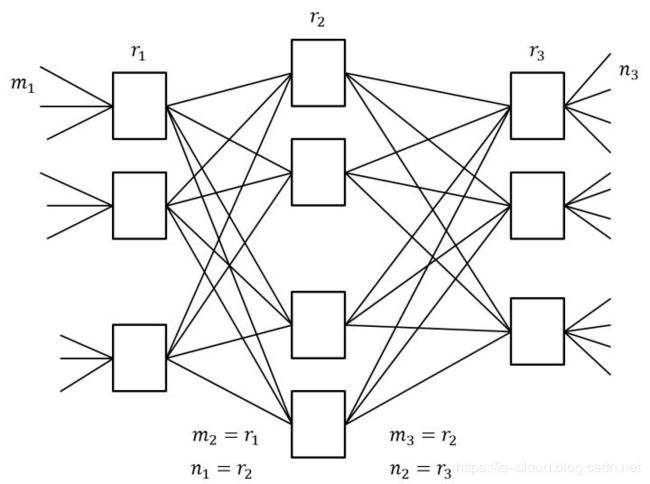
直到 1990 年代,CLOS 架构被应用到 Switch Fabric。应用 CLOS 架构的交换机的开关密度,与交换机端口数量 N 的关系是 O(N^(3/2)),所以在 N 较大时,CLOS 模型能降低交换机内部的开关密度。
>>> N = 100
>>> N**2
10000
>>> N**(3/2)
100
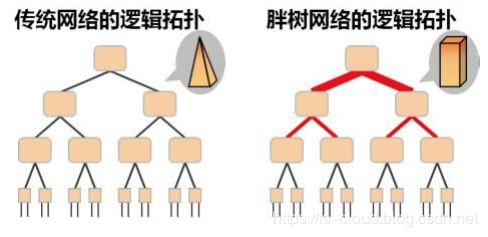
到了 80 年代,随着计算机网络的兴起,开始出现了各种网络拓扑结构,例如星型、链型、环型、树型,树型网络逐渐成为主流。
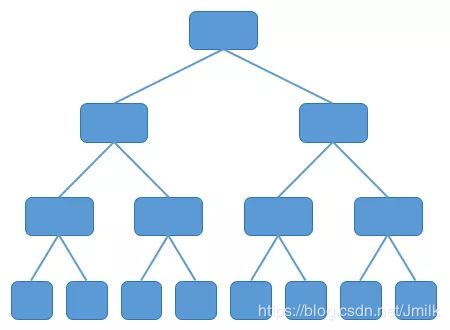
传统的树型网络,带宽是逐级收敛的:物理端口带宽一致,二进一出,所以就 1:2 的收敛了。关于传统三层树状网络结构的带宽收敛问题,我们在前面已经讨论过了,这里不再赘述。
胖树(Fat-Tree)型网络架构
在 2008 年由美国加利福尼亚计算机科学与工程的几位教授发表的一篇论文《A scalable, commodity data center network architecture》中,明确的提出了一种三级的,被称之为胖树(Fat-Tree)的 CLOS 网络架构,标志着 CLOS 正式进入数据中心网络架构领域,这是 CLOS 网络模型的第三次应用。
当前,Fat-Tree 是业界普遍认可的实现无阻塞网络的技术。其基本理念正是来自于 CLOS 网络模型:使用大量低性能的交换机,构建出大规模的无阻塞网络,对于任意的通信模式,总有路径让他们的通信带宽达到网卡带宽。
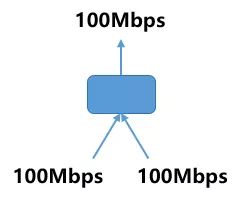
Fat-Tree 的另一个好处是,它用到的所有交换机都是相同的,这让我们能够在整个数据中心网络架构中采用廉价的交换机。同时,Fat-Tree 也是无带宽收敛的。传统的树形网络拓扑中,带宽是逐层收敛的,树根处的网络带宽要远小于各个叶子处所有带宽的总和。而 Fat-Tree 则更像是真实的树,越到树根,枝干越粗,即:从叶子到树根,网络带宽不收敛。这是 Fat-Tree 能够支撑无阻塞网络的基础。
如上图所示,为了实现网络带宽的无收敛,Fat-Tree 中的每个节点(根节点除外)都需要保证上行带宽和下行带宽相等,并且每个节点都要提供对接入带宽的线速转发的能力。
下图是一个 2 元 4 层 Fat-Tree 的物理结构示例(2 元:每个叶子交换机接入 2 台终端;4 层:网络中的交换机分为 4 层),其使用的所有物理交换机都是完全相同的。
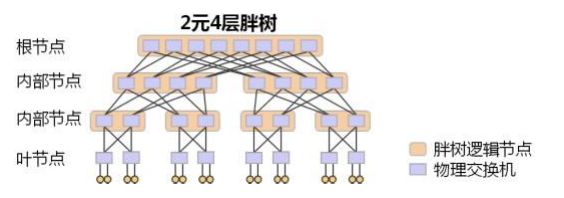
从图中可以看到,每个叶子节点就是一台物理交换机,接入 2 台终端;上面一层的内部节点,则是每个逻辑节点由 2 台物理交换机组成;再往上面一层则每个逻辑节点由 4 台物理交换机组成;根节点一共有 8 台物理交换机。这样,任意一个逻辑节点,下行带宽和上行带宽是完全一致的。这保证了整个网络带宽是无收敛的。同时我们还可以看到,对于根节点,有一半的带宽并没有被用于下行接入,这是 Fat-Tree 为了支持弹性扩展,而为根节点预留的上行带宽,通过把 Fat-Tree 向根部继续延伸,即可实现网络规模的弹性扩展。
Fat-Tree 拓扑
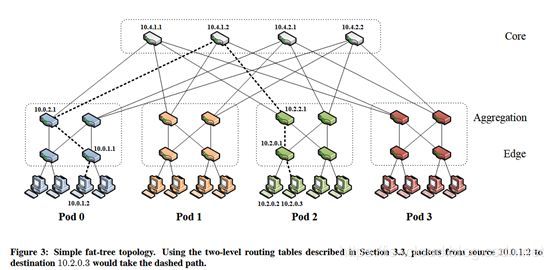
假设一个 k-ary(每个节点有不超过 k 个子节点)的三层 Fat-Tree 拓扑:
- 核心交换机个数 (k/2)^2
- POD 个数 k
- 每个 POD 汇聚交换机 k/2
- 每个 POD 接口交换机 k/2
- 每个接入交换机连接的终端服务器 k/2
- 每个接入交换机剩余 k/2 个口连接 POD 内 k/2 个汇聚交换机,每台核心交换机的第 i 个端口连接到第 i 个 POD,所有交换机均采用 k-port switch。
可以计算出,支持的服务器个数为 k * (k/2) * (k/2) = (k^3)/4,不同 POD 下服务器间等价路径数 (k/2) * (k/2) = (k^2)/4。上图为最简单的 k=4 时的 Fat-Tree 拓扑,连在同一个接入交换机下的服务器处于同一个子网,他们之间的通信走二层报文交换。不同接入交换机下的服务器通信,需要走路由。
Fat-Tree 的缺陷
- Fat-Tree 的扩展规模在理论上受限于核心层交换机的端口数目,不利于数据中心的长期发展要求;
- 对于 POD 内部,Fat-Tree 容错性能差,对底层交换设备故障非常敏感,当底层交换设备故障时,难以保证服务质量;
- Fat-Tree 拓扑结构的特点决定了网络不能很好的支持 One-to-All及 All-to-All 网络通信模式,不利于部署 MapReduce、Dryad 等高性能分布式应用;
- Fat-Tree 网络中交换机与服务器的比值较大,在一定程度上使得网络设备成本依然很高,不利于企业的经济发展。
- 因为要防止出现 TCP 报文乱序的问题,难以达到 1:1 的超分比。
叶脊(Spine-Leaf)网络架构
Spine-Leaf 网络架构,也称为分布式核心网络,与胖树架构一样同属于 CLOS 网络模型。事实已经证明,Spine-Leaf 网络架构可以提供高带宽、低延迟、非阻塞的服务器到服务器连接。
前面说过 CLOS 网络是三级交换架构,而 Leaf Spine 却只有两层,这是因为:网络架构中的设备基本都是双向流量,输入设备同时也是输出设备,因此三级 CLOS 沿着中间层对折,就得到了两层的网络架构。可以看出传统的三层网络架构是垂直的结构,而 Spine-Leaf 网络架构是扁平的结构,从结构上看,Spine-Leaf 架构更易于水平扩展。
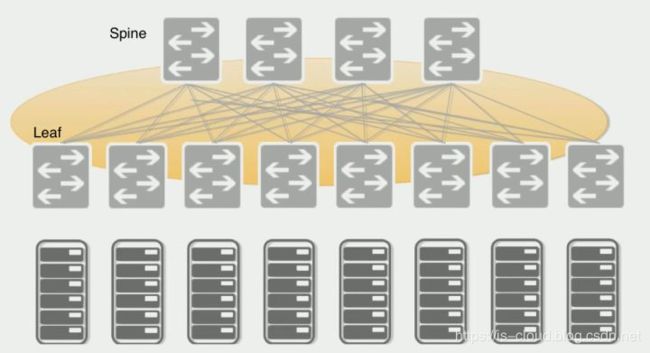
从拓扑结构上看,Spine-Leaf 二层架构视乎要比传统三层网络架构简单得多,但为什么 Spine-Leaf 直到近些年才能得到普及呢?笔者认为,技术成熟度固然是因素之一,再一个就是数据中心网络发展过程中无法回避的成本问题。传统三层网络架构只有核心交换机是昂贵的 L3 交换机,但 Spine-Leaf 却要求所有节点都应该是 L3 交换机。因此,Spine-Leaf 也只能在设备价格下降了的这些年才得以被推广。
Spine-Leaf 拓扑
- Leaf Switch:相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。与接入交换机的区别在于 L2/L3 网络的分界点现在在 Leaf 交换机上了。Leaf 交换机之上是三层网络,Leaf 交换机之下都是个独立的 L2 广播域,这就解决了大二层网络的 BUM 问题。如果说两个 Leaf 交换机下的服务器需要通讯,需要通过 L3 路由,经由 Spine 交换机进行转发。
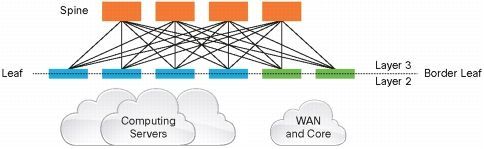
- Spine Switch:相当于核心交换机。Spine 和 Leaf 交换机之间通过 ECMP(Equal Cost Multi Path)动态选择多条路径。区别在于,Spine 交换机现在只是为 Leaf 交换机提供一个弹性的 L3 路由网络,数据中心的南北流量可以不用直接从 Spine 交换机发出,一般来说,南北流量可以从与 Leaf 交换机并行的交换机(edge switch)再接到 WAN router 出去。
Spine Switch 下行端口数量,决定了 Leaf Switch 的数量。而 Leaf Switch 上行端口数量,决定了 Spine Switch 的数量。它们共同决定了叶脊网络的规模。
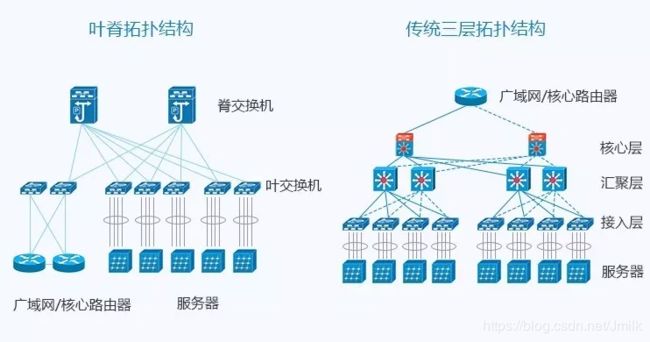
Fabric 中的 Leaf 层由接入交换机组成,用于接入服务器,Spine 层是网络的骨干(Backbone),负责将所有的 Leaf 连接起来。每个低层级的 Leaf 交换机都会连接到每个高层级的 Spine 交换机上,即每个 Leaf 交换机的上行链路数等于 Spine 交换机数量,同样,每个 Spine 交换机的下行链路数等于 Leaf 交换机的数量,形成一个 Full-Mesh 拓扑。当 Leaf 层的接入端口和上行链路都没有瓶颈时,这个架构就实现了无阻塞(Nonblocking)。并且,因为任意跨 Leaf 的两台服务器的连接,都会经过相同数量的设备,所以保证了延迟是可预测的,因为一个包只需要经过一个 Spine 和另一个 Leaf 就可以到达目的端。
因为 Fabric 中的每个 Leaf 都会连接到每个 Spine,所以,如果一个 Spine 挂了,数据中心的吞吐性能只会有轻微的下降(Slightly Degrade)。如果某个链路的流量被打满了,Spline-Leaf 的扩容过程也很简单:添加一个 Spine 交换机就可以扩展每个 Leaf 的上行链路,增大了 Leaf 和 Spine 之间的带宽,缓解了链路被打爆的问题。如果接入层的端口数量成为了瓶颈,那就直接添加一个新的 Leaf,然后将其连接到每个 Spine 并做相应的配置即可。这种易于扩展(Ease of Expansion)的特性优化了 IT 部门扩展网络的过程。
假设一个这样的资源条件:
- 脊交换机数量:16台
- 每个脊交换机的上联端口:8 × 100G
- 每个脊交换机的下联端口:48 × 25G
- 叶交换机数量:48台
- 每个叶交换机的上联端口:16 × 25G
- 每个叶交换机的下联端口:64 × 10G
在理想情况下,这样的叶脊网络总共可支持的服务器数量为:48×64=3072台。
NOTE:叶脊交换机北向总带宽一般不会和南向总带宽一致,通常大于1:3即可。上例为400:640,有点奢侈了。
Spine-Leaf 与光模块
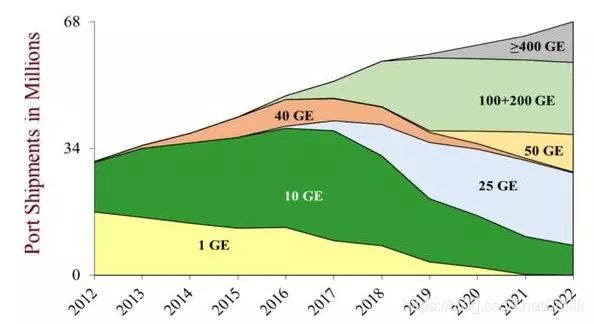
叶脊网络带来了一个趋势,那就是对光模块的数量需求大幅增加。下图就是传统三层架构和叶脊架构所使用光模块数量的对比案例,差别可能达到15-30倍之多。
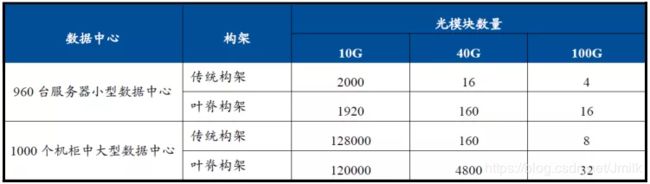
正因为如此,资本市场对叶脊网络非常关注,希望借此带动光模块市场的增长,尤其是 100G、400G 这样的高速率光模块。
- 2018 年的光模块出货量及生命周期预测
Spine-Leaf 的优势
- 扁平化:扁平化设计缩短服务器之间的通信路径,从而降低延迟,可以显著提高应用程序和服务性能。
- 带宽利用率高:每个叶交换机的上行链路,以负载均衡方式工作,充分的利用了带宽。
- 网络延迟可预测:在以上模型中,叶交换机之间的连通路径的条数可确定,均只需经过一个脊交换机,东西向网络延时可预测。
- 扩展性好:当带宽不足时,增加脊交换机数量,可水平扩展带宽。当服务器数量增加时,增加脊交换机数量,也可以扩大数据中心规模。总之,规划和扩容非常方便。
- 降低对交换机的要求:南北向流量,可以从叶节点出去,也可从脊节点出去。东西向流量,分布在多条路径上。这样一来,不需要昂贵的高性能高带宽交换机。
- 安全性和可用性高:传统网络采用 STP 协议,当一台设备故障时就会重新收敛,影响网络性能甚至发生故障。叶脊架构中,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。
- 低收敛比:容易实现 1:X 甚至是无阻塞的 1:1 的收敛比,而且通过增加 Spine 和 Leaf 设备间的链路带宽也可以降低链路收敛比。
- 简化管理:叶脊结构可以在无环路环境中使用全网格中的每个链路并进行负载平衡,这种等价多路径设计在使用 SDN 等集中式网络管理平台时处于最佳状态。SDN 允许在发生堵塞或链路故障时简化流量的配置,管理和重新分配路由,使得智能负载均衡的全网状拓扑成为一个相对简单的配置和管理方式。
- 边缘流量处理:随着物联网(IoT)等业务的兴起,接入层压力剧增,可能有数千个传感器和设备在网络边缘连接并产生大量流量。Leaf 可以在接入层处理连接,Spine 保证节点内的任意两个端口之间提供延迟非常低的无阻塞性能,从而实现从接入到云平台的敏捷服务。
- 多云管理:数据中心或云之间通过 Leaf Spine 架构仍可以实现高性能、高容错等优势,而多云管理策略也逐渐成为企业的必选项。
Spine-Leaf 的缺陷
但是,Fabric 架构并非完美。叶子节点网络设备无论是性能要求还是功能要求,均高于传统架构下的接入设备,其作为各种类型的网关(二三层间、VLAN/VxLAN 间、VxLAN/NVGRE 间、FC/IP 间等等),芯片处理能力要求较高,目前尚无满足所有协议间互通的商用芯片;由于不存在相关的标准,为了实现各种类型网络的接入,其骨干节点与叶子节点间的转发各个厂商均采用了私有封装,这也为将来的互通设置了难题。除此之外,还有:
- 独立的 L2 Domain 限制了依赖 L2 Domain 应用程序的部署。要求部署在一个二层网络的应用程序,现在只能部署下一个机架下了。
- 独立的 L2 Domain 限制了服务器的迁移。迁移到不同机架之后,网关和 IP 地址都要变。
- 子网数量大大增加了。每个子网对应数据中心一条路由,现在相当于每个机架都有一个子网,对应于整个数据中心的路由条数大大增加,并且这些路由信息要怎么传递到每个 Leaf 上,也是一个复杂的问题。