【魏先生搞定Python系列】一文搞定SQLAlchemy学习与使用
读书要先读厚,再读薄。编程也是一样,随着学习深入,发现要学的东西越来越多:语言本身、数据库、网络编程、html、界面设计等等,突然有一天发现,自己天天啃的东西万变不离其宗,不过如此而已。现在利用Python做项目,就像是在搭积木,先设计出大致的框架,细分需要的积木,再一块块的获取积木,最后搭成自己想要的样子,其中的欢乐只有搭积木的人能够体会吧。
上面感慨了一通,还是尽快回到正题。饭要一口一口吃,骨头要一点一点啃,本文说的就是其中一块积木——SQLAlchemy,一个python与数据库连接的大杀器,掌握了它,可以说利用python进行数据库相关操作可以说就是得心应手了。在介绍前,需要具备的知识有:
- 掌握Python编程语言
- 了解SQL基础知识
本文参考文章:
Alex的Python之路:https://www.cnblogs.com/alex3714/articles/5978329.html
战争热诚的PythonSQLAlchemy的学习与使用:https://www.cnblogs.com/wj-1314/p/10627828.html
俊采星驰的SQLAlchemy中文技术文档:https://www.jianshu.com/p/0ad18fdd7eed
https://www.cnblogs.com/iwangzc/p/4112078.html
1. 何为ORM
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。

简而言之,ORM就是将非对象模式的程序映射为一个个对象,从而实现便捷的操作。具体到SQLAlchemy,就是将数据库这种指令化的操作转变为对对象的操作。
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的,这从使用SQLAlchemy的公司列表就可以看出来。
2. SQLAlchemy简介
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行,是Python领域里最有名的数据库ORM框架。

2.1 SQLAlchemy的安装
直接使用pip安装:
pip install sqlalchemy
这里要特别提一句,由于pypi被墙的原因,因此建议使用国内镜像站点下载,具体设置方式可参见我的pip无法连接或连接超时解决方案一文。
2.2 驱动的安装
SQLAlchemy不能直接操作数据库,其必须通过pymysql等第三方插件。上图中Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。下文使用pymysql来连接数据库
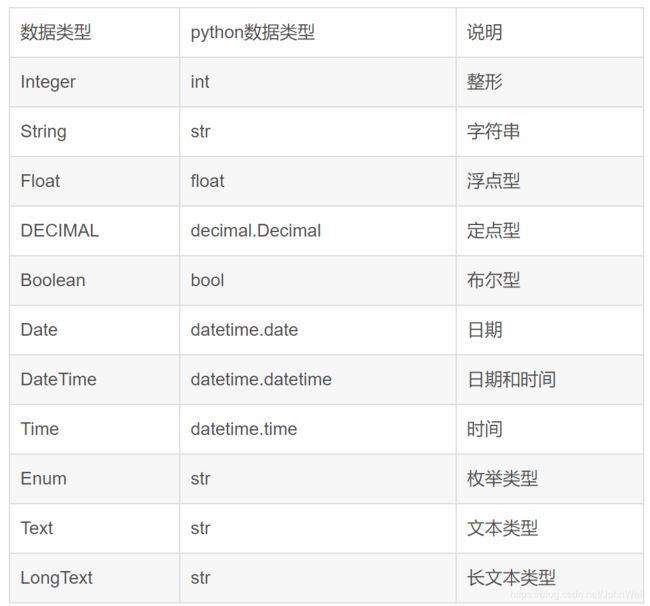
2.3 常用数据类型与类的介绍
2.3.1 常用数据类型
SQLAlchemy自己在内部定义了很多数据类型,具体如下:
2.3.2 Column类
其构造函数为:
Column.__init__(self, name, type_, *args, **kwargs)-
name 列名
-
type_ 类型,更多类型 sqlalchemy.types
-
*args Constraint(约束), ForeignKey(外键), ColumnDefault(默认), Sequenceobjects(序列)定义
-
key 列名的别名,默认None
-
下面是可变参数 **kwargs
(1)primary_key 如果为True,则是主键
(2)nullable 是否可为Null,默认是True
(3)default 默认值,默认是None
(4)index 是否是索引,默认是True
(5)unique 是否唯一键,默认是False
(6)onupdate 指定一个更新时候的值,这个操作是定义在SQLAlchemy中,不是在数据库里的,当更新一条数据时设置,大部分用于updateTime这类字段
(7)autoincrement 设置为整型自动增长,只有没有默认值,并且是Integer类型,默认是True
(8)quote 如果列明是关键字,则强制转义,默认False
3. SQLAlchemy的初阶操作——增删改查
3.1 连接数据库并生成表
#首先创建一个SQLAlchemyTest的数据库
#使用SQLAlchemy创建表
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String #这三种类型都是sqlachemy自己定义的
#engin = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest")
#engine里面需要用双引号,且字符串内不能有空格,否则会报错
#echo参数默认为False,设为True可以打印创建数据库的情况
engine = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest", encoding='utf-8', echo=True)
Base = declarative_base()#生成ORM基类
#创建一个User类,与数据库中的表一一对应
class User(Base):
__tablename__ = 'user' #关联数据库中的表名称
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64))
#creat_all 会将上面定义的表格类全部在数据库中进行关联
#如果在数据库中已经创建了表,再次执行编译不会新建表格
Base.metadata.create_all(engine)3.2 新增记录
首先看代码:
#新增记录
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String #这三种类型都是sqlachemy自己定义的
from sqlalchemy.orm import sessionmaker #载入sessionmaker
engine = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest", encoding='utf-8', echo=True)
Base = declarative_base()#生成ORM基类
#创建一个User类,与数据库中的表一一对应
class User(Base):
__tablename__ = 'user' #关联数据库中的表名称
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64))
#使用sessionmaker创建与数据库的连接
Session_class = sessionmaker(bind=engine)
Session = Session_class()
#创建需要新增的记录实例
user_obj = User(name = 'john',password = '123')
print(user_obj.name,user_obj.id) # 此时有name,但是没有id信息,因为还没有和数据库绑定
Session.add(user_obj) #将实加入session里,但是此时还是没有写入数据库,因此还是没有id信息
Session.commit() #sql自动开启一个事务,只有commit后数据才能生效
Session.close() #关闭Session这里要注意一点,新增记录与创建表不同,在创建表时,如果表已经存在则不会再新增,且不会报错;而新增一条记录,只要主键不同(例如主键值自增),运行一次,就会新增一条记录。
3.3 查询记录
查询的方式有很多,比如查询一条数据,查询多条数据,有筛选查询等等,但是万变不离其宗。
3.3.1 查询一条数据
具体代码如下:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String #这三种类型都是sqlachemy自己定义的
from sqlalchemy.orm import sessionmaker #载入sessionmaker
engine = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest", encoding='utf-8', echo=True)
Base = declarative_base()#生成ORM基类
#创建一个User类,与数据库中的表一一对应
class User(Base):
__tablename__ = 'user' #关联数据库中的表名称
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64))
#使用sessionmaker创建与数据库的连接
Session_class = sessionmaker(bind=engine)
Session = Session_class()
#从User类关联的表中查找,其中first()是必须要加上的
my_user = Session.query(User).filter_by(name = 'john').first()
print(my_user.id,my_user.name,my_user.password)使用query()进行查询,除了可以像上面直接查询一整条记录外,还可以对某一个或几个字段进行查询,这也是和SQL中的SELECT类似的。比如:
my_user_id,my_user_name = Session.query(User.id,User.name).first()
print(my_user_id,my_user_name)
3.3.2查询多条数据
使用query查询有多条语句时,返回的是一个list,里面是查询到的所有记录的对象,通过循环,可以读出所有数据。
#从User类关联的表中查找出所有记录
my_users = Session.query(User)
for tmp_user in my_users:
print(tmp_user.id,tmp_user.name)其实,查询一条数据为query(*).filter_by(*).first(), 查询全部数据应为query(*).filter_by(*).all(),我测试了下,加all()与不加暂时没发现区别呢,都能得到结果。又看了下,还是需要all,不写的话返回是一条sql语句。
3.3.3 带筛选查询
在SQLAlchemy中,与SQL语句WHERE相对应的是filter()和filter_by()方法,两个方法使用区别总结如下:
- filter在筛选时,必须带上类名,如User.id,而filter_by则不需要带(带了会出错)
- filter可以使用>,<等逻辑运算符进行判断,而filter_by不能直接用
- 在进行逻辑判断相等时,filler用的是==(说白了就是逻辑运算符),而filter_by用的是=
- filter和filter_by都可以多次使用,实现多条件筛选
- filter不支持组合查询,只能连续调用filter来变相实现;filter_by的参数是**kwargs,直接支持组合查询。
我们看个例子:
#使用filter_by进行筛选
my_users= Session.query(User).filter_by(id=1).all()
for tmp_user in my_users:
print(tmp_user.id,tmp_user.name)
#使用filter进行筛选
my_users= Session.query(User).filter(User.id==1).all()
for tmp_user in my_users:
print(tmp_user.id,tmp_user.name)再看个组合查询的例子:
#filter_by可以输入多个参数实现
my_users= Session.query(User).filter_by(id=1 , name ='魏巍').all()
#使用filter的等效形式
my_users= Session.query(User).filter(User.id==1).filter( User.name =='魏巍' ).all()
这里还要提一下,filter里的逻辑判断,类似于SQL语句的 WHERE ...IN...,有一个in_()方法的使用如下:
my_users= Session.query(User).filter(User.name.in_(['魏巍','john'])).all()
for tmp_user in my_users:
print(tmp_user.id,tmp_user.name)经过测试,在filter里直接用python里的关键字无效,会产生错误。
除此之外,还有and_ or_ ,在使用之前需要加载相关函数,具体例子如下:
from sqlalchemy import and_
my_users= Session.query(User).filter(and_(User.name=='john',User.id== 1) ).all()
3.4修改记录
修改的逻辑就比较简单了,首先要像3.2查到该数据并生成类,再对改类对应字段进行修改,最后commit即可。
#修改记录
my_user.name = 'weii'
Session.commit()
这里只是示例,但既然是类与实例,我们就知道直接这么修改虽然可以,但是不建议这么做。规范的做法是在类里写一个修改的方法,调用方法对属性进行修改。
3.5 数据删除
my_user= Session.query(User).filter(User.id==2).first()
#删除my_user
Session.delete(my_user)
Session.commit()这里要注意的是,在delete之后要commit才能将操作更新到数据库中。
3.6 回滚ROLL BACK
初学数据库时,一直有个疑问,为什么要ROLLBACK,如果发现数据错误直接把那行代买删掉就可以了啊。。。实际上,ROLLBACK恰恰是为了编程才出现的一种机制。
举例而言:现需要输入用户名与密码,同时规定密码只能是0-9的数字,而不能出现其他字符;首先输入用户名为‘john’,再输入密码为‘john123’,这种输入显然不符合我们定的规范,如果没有rollback,那么在输入密码前就已经将用户名john录入数据库了,此时就只有一个密码为NULL的记录,显然不是我们想要的结果。我们想要的效果是:当密码输入错误时,这条记录不写入数据库,也就是说当录入数据有问题,抛出异常或不满足某种判断时,前期的操作全部ROLLBACK为初始状态。这算是对ROLLBACK对直白的解释了吧:)
下面我们看看使用SQLAlchemy来实现ROLLBACK:
#创建一个fake_user记录,并加入到Session中
fake_user = User(name='jack',password='jack123')
Session.add(fake_user)
#将id为2的记录,name值变更为’wei‘
my_user= Session.query(User).filter(User.id==2).first()
my_user.name ='wei'
#通过查询发现刚才的新增与变更均已在Session中
#此时查询数据库,还没有任何变化,因为没有commit
all_my_users = Session.query(User).all()
for tmp_user in all_my_users:
print(tmp_user.id,tmp_user.name)
Session.rollback()
#rollback后再查询,上面做的变更均已清除
all_my_users = Session.query(User).all()
for tmp_user in all_my_users:
print(tmp_user.id,tmp_user.name)
3.7 统计和分组
3.7.1 统计
在做统计和分组实验前,我们首先向数据库内新增3条记录,代码如下:
#首先在数据库增加3列数据
user1 = User(id=2,name='wei',password= '123')
user2 = User(id=3,name='wei',password= '132')
user3 = User(id=5,name='wei',password= '123')
user_list = [user1,user2,user3]
Session.add_all(user_list)
Session.commit()在增加后查询数据库内数据,发现现有5条数据如下:

下面首先统计name为wei的数量,结果为3,代码如下:
my_user_count = Session.query(User).filter(User.name=='wei').count()
print(my_user_count)3.7.2 分组及聚合函数
与SQL类似,在GROUP BY 之后,可以进行相关统计,这里首先需要介绍下常用的聚合函数:
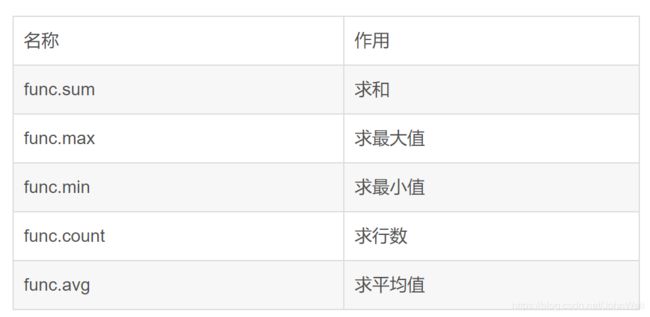
使用前需要先导入func,实例如下:
from sqlalchemy import func
my_user_union= Session.query(func.count(User.name),User.name).group_by(User.name).all()
print(my_user_union)这里只是举个例子,具体的group by等统计,可以用pandas实现,没必要如此实现吧。
4. 高阶应用
在这部分,我们将介绍关于外键、表的连接等方面的知识。
4.1 外键关联
在测试代码前,我们先来整理下现有的数据库,首先,前面的代买已经建立了一个user表,有三个字段,分别为
- id :主键
- name: 用来记录用户名
- password:用来记录用户的密码
我们这里需要再创建一个address表与user表相关联,具体字段有:
-
id:主键
-
email_address : 电邮地址
-
user_id : 外键 用户id,对应user表的id
使用SQLAlchemy创建方式如下:
#首先创建一个SQLAlchemyTest的数据库
#使用SQLAlchemy创建表
#加载创建表的头文件
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String #这三种类型都是sqlachemy自己定义的
#下面两个是创建外键时需要载入的
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
#engin = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest")
#engine里面需要用双引号,且字符串内不能有空格,否则会报错
#echo参数默认为False,设为True可以打印创建数据库的情况
engine = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest", encoding='utf-8', echo=True)
Base = declarative_base()#生成ORM基类
class Address(Base):
__tablename__='address'
id = Column(Integer, primary_key=True)
email_address = Column(String(32)) #本来增加了nullable参数,但是报错!!
user_id = Column(Integer,ForeignKey('user.id')) #这里的user.id是数据库中表的名字与字段
#下面定义了个relationship,可以实现两个表间互相调用
user = relationship('User',backref ='addresses')
def __repr__(self):
return "Address(%s)" % self.email_address
#creat_all 会将上面定义的表格类全部在数据库中进行关联
#如果在数据库中已经创建了表,再次执行编译不会新建表格
Base.metadata.create_all(engine)这里在定义Address类里user_id时,本身想加一个nullable参数,但是运行报错,报错信息为:
Additional arguments should be named
_ , got 'nullabe'
这个需要后续再研究下为什么会这样
创建好address表格后,我们在里面写入两条数据:
Session_class = sessionmaker(bind=engine)
Session = Session_class()
addr1 = Address(id= 1,email_address ='[email protected]',user_id=1)
addr2 = Address(id = 2,email_address = '[email protected]',user_id = 3)
Session.add_all([addr1,addr2])
Session.commit()至此,我们外键关联的两张表就已经完成了。
4.2 单个外键查询
在4.1节中,我们创建了两张表,user和address,并且在两张表之间建立了1个外键,此时进行查询操作如下:
#使用relationship在两表间互相调取
my_user = Session.query(User).filter(User.id==1).first()
print(my_user.addresses)通过查询,输出结果为:
[Address([email protected])]
除了上面4.1传统的创建方式外,我们可以通过relationship的相互调用来创建表格关联,如:
my_user = Session.query(User).filter(User.id==2).first()
my_user.addresses = [Address(email_address ='[email protected]')]
Session.add(my_user)
Session.commit()此时,在数据库中查询,发现address表多了一条记录:

不难发现,它的user_id已经自动关联为2了。
这里还要注意一点,就是query()返回的是一个list,因此即使只有一个值,在赋值时也要使用list的范式,否则会报错。
4.3 多外键查询
在4.2节我们已经讨论了单个外键的定义及使用方式,现在我们更进一步,讨论两表之间存在多个外键的情况。首先,我们再新增一个customer表,其中的账单地址与送货地址均与address表外键关联,具体构造结构如下:
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key = True)
name = Column(String(32))
billing_address_id = Column(Integer, ForeignKey('address.id'))
shipping_address_id = Column(Integer, ForeignKey('address.id'))
#需要注意下面relationship多了外键的备注,否则分辨不出对应哪个外键
billing_address = relationship('Address', foreign_keys = [billing_address_id])
shipping_address = relationship('Address', foreign_keys=[shipping_address_id])这里要注意,多外键关联的时候,在relationship中要注明是哪一个外键,否则在录入address表的数据时会报错。这里我没有论证到底是因为加了relationship才变成这样还是多外键本身是这样,但是按照这个模式写肯定是没错的。。。
之后,再写入三条数据:
customer1 = Customer(id=1,name='wei',billing_address_id = 1, shipping_address_id = 2)
customer2 = Customer(name='john',billing_address_id = 2, shipping_address_id = 2)
customer3 = Customer(name='ke',billing_address_id = 3, shipping_address_id = 2)
Session.add_all([customer1,customer2,customer3])
Session.commit()此时,就可以实现多个外键的查询了:
my_customer = Session.query(Customer).filter(Customer.id ==2).first()
print(my_customer.billing_address.email_address)
print(my_customer.shipping_address.email_address)4.4 多对多外键关联
在4.3节中,我们已经实现了一个表格多个外键,相当于一对多,在本节我们再深入一步,讨论多对多的外键关联,我们来讨论一种场景:
我们在记录书与作者的关系时,一本书可能有多个作者,而一个作者也写了不止一本书,那么就不能简单的用前面学习的外键关联关系来做了。

如果笨一点的办法,就是原来一行的,现在变成多行,但是效率太低,不是我们想要的:

最可行的办法,是再建立一张中间表格,来体现这种关系:

首先,我们创建3张表:
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:Wei123@localhost/sqlalchemytest", encoding='utf-8', echo=True)
Base = declarative_base()
#建立一个中间表格,并注明外键
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
#这里的relationship要注意下,中间secondary的定义
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
Base.metadata.create_all(engine)下面我们创建几个author和book的实例,并再他们间建立外键关联:
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(engine)
Session = Session_class()
b1 = Book(name="跟Alex学Python")
b2 = Book(name="跟Alex学把妹")
b3 = Book(name="跟Alex学装逼")
b4 = Book(name="跟Alex学开车")
a1 = Author(name="Alex")
a2 = Author(name="Jack")
a3 = Author(name="Rain")
b1.authors = [a1,a2]
b2.authors =[a1,a2,a3]
Session.add_all([a1,a2,a3,b1,b2,b3,b4])
Session.commit()此时进行查询,则有:
my_book = Session.query(Book).filter_by(id=2).first()
print(my_book.authors)
my_author = Session.query(Author).filter_by(id=1).first()
print(my_author.books)此时可以查到相应的数据。
最后,我们再看一下多对多的删除,在录入数据后,中间表格book_m2m_author就不再需要人工维护了,而是由sqlalchemy维护,删除数据时,从一个表中删除,其与另一个表的关系也会跟着被删掉。
author_obj =s.query(Author).filter_by(name="Jack").first()
book_obj = s.query(Book).filter_by(name="跟Alex学把妹").first()
book_obj.authors.remove(author_obj) #从一本书里删除一个作者
s.commit()author_obj =s.query(Author).filter_by(name="Alex").first()
# print(author_obj.name , author_obj.books)
s.delete(author_obj)
s.commit()5、相关问题QA:
Q1:mysql 连接出现 ’cryptography is required for sha256_password or caching_sha2_password‘
报错原因:MySQL8.0版本以后采用caching_sha2_password作为默认的身份验证插件。
A1:
安装cryptography即可
pip install cryptographyQ2: 在新增记录时,例如上文中的user表,采用 user1 = User(1,'wei','123')的形式,会报错,错误为:
__init__() takes 1 positional argument but 4 were given
A2:之所以出现这个问题,是因为虽然认为定义了很多变量,但是在构造函数中不知道你的表会有几个字段,因此使用的是*args,因此在实例化时,应该将变量都写出来:
user1 = User(id=1, name = 'wei',password = '123')