唯品会Noah云平台实现内幕披露

1. 唯品会Noah云平台的构建历程

Noah云平台从2017年初开始调研,3月份确定选型和架构,7月份已经开始接入业务,到现在已经研发了1年半时间,现在部署了5个IDC,共9个Kubernetes集群(有些IDC部署了两套Kubernetes集群),其中两套Kubernetes集群供AI使用。
1.2 云平台的目标
这里讲些我们建设云平台的目标,主要从资源利用率提升,开发测试运维一致性和对DevOps的进化三个目标,其实就是提高人效和机器效率。
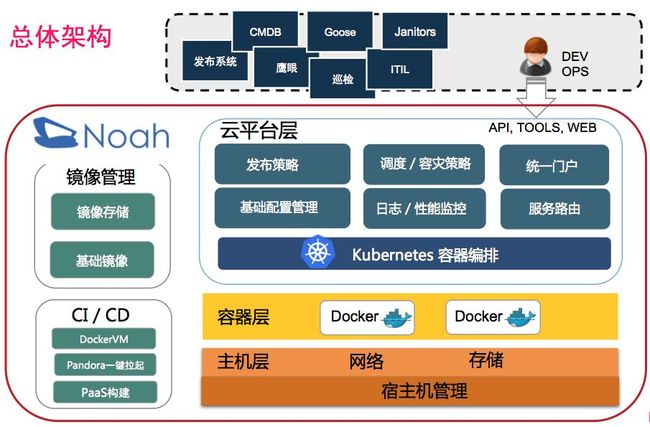
Noah云平台整体架构按架构层次,分为主机层、容器层、云平台层(后面说的Noah Server),其中容器调度使用了业界开源的Kubernetes 1.9.8版本,容器层使用Docker 1.13.1版本,容器网络使用Contiv+Netplugin方案。
Noah云平台层(Noah Server),后面会说到,它是整个Noah云平台的粘合层,对外提供容器Lifecycle管理和集群管理,网络管理等API和UI。
Noah云平台也包括了CI/CD流水线,负责业务镜像的构建,提供功能联调环境(Pandora)测试,它支持业务开发快速创建自己的测试环境,把依赖的服务快速拉起。目的是提高业务测试的效率。
Noah云平台也提供了基础镜像和镜像存储。
运维的发布系统、CMDB、ITIL(变更系统),都会对接Noah云平台相关API或UI做集群和容器的相关操作。
Noah云平台也部署了一套跟生产完全一样的Noah Staging环境,只是规模不一样而已。它提供了业务镜像上线前的集成测试。
Noah云平台是基于Kubernetes+Docker技术框架构造的,虽Kubernetes已经成为容器编排的胜出者,但真正使用过程中,还是需要结合公司的实际情况使用。比如:
过于Cloud Native化
Kubernetes,包括CNCF下的开源项目,都是以Cloud Native为方向,而对于企业来说,都有历史包袱,比如物理机/VM 和容器混布一段时间,比如有自己的服务化框架和日志监控系统,容器化必须与公司的基础设施打通
功能复杂,偏分布式应用开发者
提供基于yaml文件的声明式API,运维和开发使用起来比较复杂,容易出错
Kubernetes提供丰富的功能,但都需要深入了解才能用好,对运维和开发要求高
功能很完美,但现实很骨感
Kubernetes Deployment的rolling upgrade策略不适用唯品会的发布流程
多集群管理Federation还不完善,Federation现在还处于Alpha阶段,不太稳定。依赖CoreDNS和ETCD,增加系统部署的复杂度。不支持Pod信息的聚合,不方便做watch
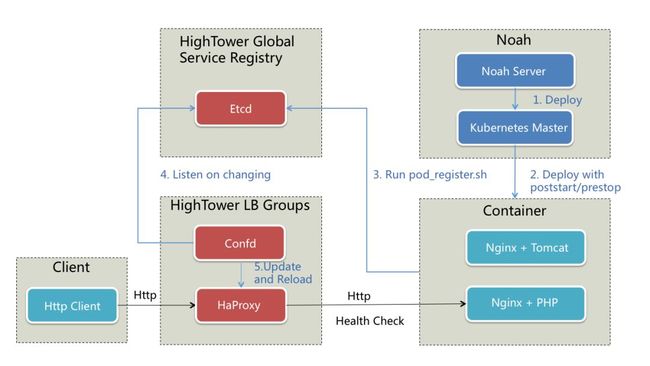
3.2 Noah Server的定位
摆在我们面前两条路,一个是修改Kubernetes源码支持我们的需求,但这会跟社区分岔路会走得越来越远,享受不了开源社区给我们带来的好处。因此我们在Kubernetes上构建一套Noah Server,来标准化和简化Kubernetes的使用。我们定义它为Noah云平台的粘合层。我们的思路,跟来自张磊的《Kubernetes项⽬目与基础设施“⺠民主化”的探索》workshop结语说的有点像,走扩展,组合机制,而不是硬改代码的机制。Noah Server主要解决以下问题:
UI支持,标准化使用流程
多机房多集群管理,同机房两套集群
灰度分批分部署池发布(每套Kubernetes集群相当于一个部署池,为了减少新版本发布导致的问题,使用分批发布分批验证)
与公司的发布系统和变更系统深度集成,提高运维操作的效率
容器生命周期管理(摘流量、隔离、Debug)
提供统一的注册发现机制,对业务透明
支持多种应用类型的Health Check
支持容器部署的高可用
支持一键容灾迁移(若某个集群不可用,可快速把该机房的容器迁移到其他机房)
3.3.1 基础镜像
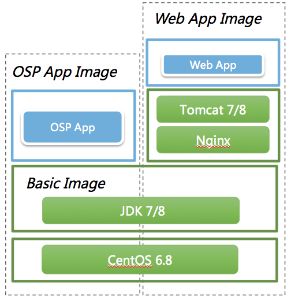
Noah云平台提供了唯品会所有应用类型的基础镜像、OSP(唯品会服务化框架)应用、Tomcat应用、PHP应用等,云平台提供CI流水线让业务自己构建镜像,CI流水线自动根据应用类型选择最新发布的基础镜像来构建。
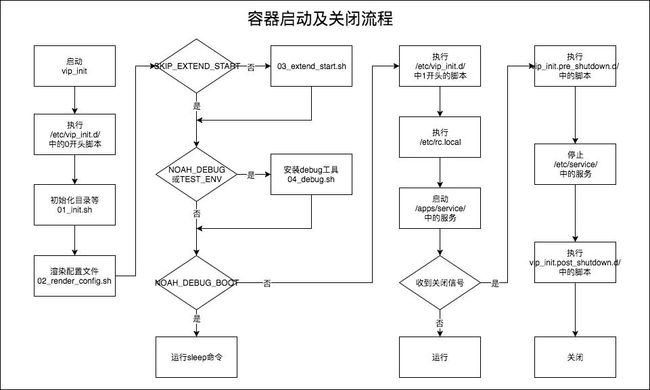
基础镜像的初始化脚步基于my_init开发了vip_init脚本,来管理基础镜像运行的Service。以下是容器启动和销毁的流程。包括了容器启动和关闭的关键步骤。
Noah镜像都是按照Docker的镜像分层来构建,基础镜像+业务镜像+配置 = 业务容器,Noah云平台调用唯品会运维的crab系统获取容器的运行时配置信息[环境变量配置]。
下图简单介绍了基础镜像层的分层结构:
3.3.2 镜像仓库
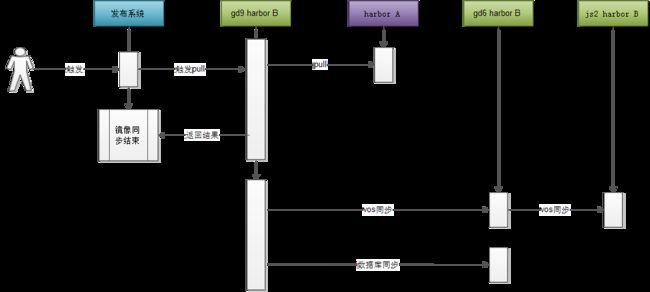
我们在开源的Harbor上做了二次开发,支持多机房同步,支持唯品会的分布式存储VOS存储镜像,支持镜像同步监控等功能。
镜像发布流程是这样的:
测试环境部署Harbor A,准备release的镜像发布到Harbor A,Harbor A也会存储测试的镜像
各机房部署Harbor B,但网络安全只开通gd9机房的Harbor B与测试环境的Harbor A相通
其他机房通过分布式存储VOS做镜像同步
3.3.3 灰度分批发布
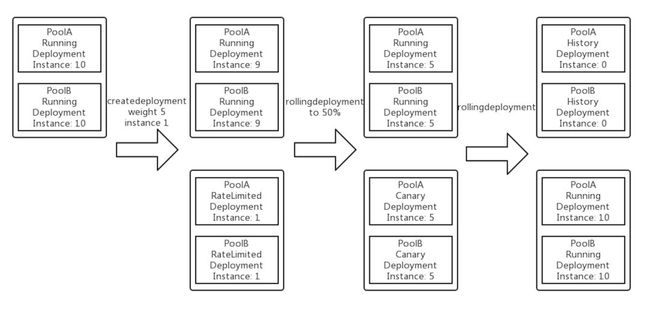
灰度发布是减少发布故障的主要手段,Kubernetes管理的资源对象,如Deployment,StatefulSet等都提供了滚动升级的策略,但Kubernetes暂时不支持分批的滚动,因为每发布批次都需要验收测试。举个例子,比如说某个域有10个容器,我们希望能够分3批来发布,第一批发布容器个数为1,第二批为4,第三批为5,每批次都需要业务方确认没问题,再继续执行下一批操作。
我们也从京东了解过,他们修改了Kubernetes代码,增加了group controller来支持这种分批暂停的验证。但我们考虑以后Merge代码的复杂性,所以对于这个功能没有修改Kubernetes的代码,而是使用了下面介绍的方式。
下面我们介绍下我们灰度分批的方案,其实很简单,就是两个Deployment,一个Running Deployment,一个新版本Cannary Deployment。Running Deployment做scale down,Cannary Deployment做scale up,最后发布完成,删除旧的Running Deployment。若在发布中发现有问题,需要回滚,那做反操作即可。
灰度分批发布流程:
3.3.4 容器Auto Scaling
使用容器后的另一个好处是容器可以很方便的做伸缩,但其实有更高级的实现是Auto Scaling。
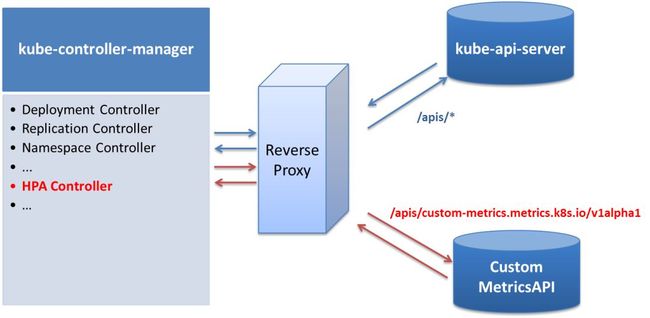
Kubernetes提供了HPA功能,是Kubernetes Controller Manager的一个组件,但使用HPA有些Limitation:
HPA依赖Heapster服务来获取容器的资源使用情况,而我们已经有自己的监控系统
提供Custom Metric的接入方式,但引入了Custom Metric Server后,需要在Kubernetes Controller Manager和Kubernetes API Server直接部署kube-aggregator(Reserve Proxy)组件, 对 /apis/* 请求,转发到 API Server 上。对于apis/custom-metrics.metrics.k8s.io/v1alpha1 请求, 转发到后端的 Custom Metric Server,这样增加了部署的复杂度
由于HPA有以上的Limitation,然后调研Kubernetes的HPA算法,我们决定自己做容器的HPA。
Noah云平台的HPA实现:
支持多种策略(CPU、IO)
多种策略同时计算,选最优的策略执行
支持多种因子
Cold down window(扩容冷却时间为3分钟,缩容为5分钟)
Tolerable factor(容忍Metric值上下波动5%)
Frustrated level(以Target值的1.4倍作为警戒线,若超出警戒线,忽略Cold down window继续扩容)
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) ,Target为HPA规则设置的目标触发值。比如cpu usage > 50%
集群管理很多节点,所有操作多为批量操作:
Node Label自动同步
每台节点都需要打上node label,如rack信息,machine-type等。云平台从CMDB系统同步信息自动打上rack,machine-type等node label
批量查询/调整 节点上所有容器的流量权重
批量上/下线节点
3.3.6 多集群事件监控
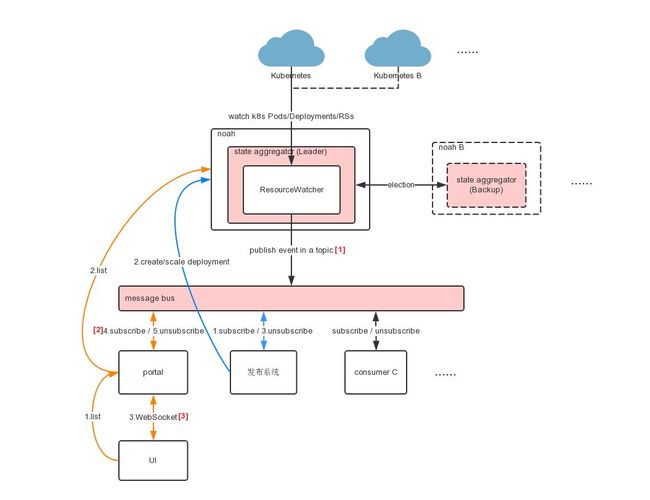
Noah云平台管理了多套Kubernetes集群,因此需要watch每个集群的Kubernetes事件,监控这些事件做什么?因为唯品会的其他运维系统需要容器的实时信息,比如容器的IP、容器个数等。
我们参考了Kubernetes Informer的实现,自研了多集群watch的机制。只有Leader角色的Noah Server才做事件监控。Leader watch多个Kubernetes集群的事件,然后publish到唯品会的消息系统平台,其他系统统一到消息系统消费这些事件。
比如Noah Server会上报容器的新增或删除的IP到CMDB系统,容器IP冲突会告警等。
3.3.7 容器Web Console
唯品会业务在使用Noah云平台前,代码都是部署到物理机或者VM上,业务人员需要通过堡垒机登陆到机器上查询日志等信息。但容器后,就没有固定的机器了,业务人员怎样办,因此Noah云平台必须实现容器的Web Console,直接登录到业务容器。
Kubernetes提供了exec接口, 允许用户登录容器执行命令。 exec接口底层是通过调用docker exec来执行的, 网络协议是使用web socket, 能支持客户端和容器之间双向推送消息。基于此,我们开发了登陆容器Web Console功能。
但Kubernetes的exec接口只能针对单个Pod进行操作, 这对于运维人员来说是不足够的。 在日常的工作中,他们经常要对多个容器批量下发命令, 例如他们需要同时查看deployment下所有Pod的某个文件的状态。
为了满足这方面的需求, 我们提供了对多个Pod批量执行命令的功能。 这个功能的实现可以归纳为2个部分:
使用websocket分别连接多个Pod下发命令
Noah Server对命令的输出,按容器名称进行聚合并返回
4. 服务注册发现
容器化后,必须要支持动态的服务注册与发现。Kubernetes提供了Service机制来实现,但Service 刚开始使用iptables,但iptables的规则匹配是线性的,匹配的时间复杂度是O(N),规则更新是非增量式的,哪怕增加/删除一条规则,也是整体修改 Netfilter 规则表。另外一个问题是性能问题,当iptables数据量很大的时候,更新会非常慢。
由于Kubernetes Service存在的一些问题,加上唯品会大部分业务都服务化了,Noah云平台考虑支持HTTP服务就可以,因此Noah云平台暂时没有使用Kubernetes Service。
4.1 OSP 服务
唯品会也有自研的服务化框架OSP(Open Service Platform),所有核心业务,在16年就做了大重构--服务化。因此对OSP应用,服务注册发现已经支持,从物理机迁移到容器是非常简单的。
如果大家对OSP有兴趣的话,请移步江南白衣的blog:《 唯品会的Service Mesh三年进化史》。
4.1.1 OSP Proxy容器化
其实OSP是类似现在一直在推崇的Service Mesh,也就是有一个OSP Proxy,如果用Sidecar模式,由于OSP Proxy是Java的,堆内和堆外内存吃得有点多,而且OSP Proxy升级,必须依赖业务域发布。
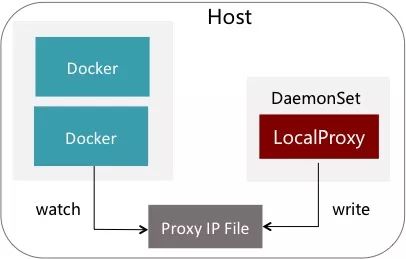
所以,我们选择了DaemonSet的形式,每台宿主机上只运行一个Proxy,Proxy启动时把自己的IP写在一个共享文件里,这个文件也Mount进各个容器里面,各个客户端会监听这个文件的变化。
大家可能会想到,一台OSP Proxy顶多个业务容器的请求转发,会不会某个业务域的bug,把OSP Proxy压死啊?其实在做这方案前我们也考虑到,所以OSP Proxy做了些改造。Proxy加了个来源IP的限流,效果就是单个容器的调用高于2万QPS时,第二万零一个请求开始就把它临时重定向到Remote Proxy集群。 十秒钟后再重试本地Proxy,如果还是高,又继续转到Remote Proxy集群。
4.2 HTTP服务
其他非OSP服务(http服务)怎么办?其实业界上有很多解决方案,比如Confd,Bamboo动态更新HAProxy或Nginx等。唯品会选择了etcd + Confd+HAProxy。
何时注册/销毁:
我们使用了Kubernetes的poststart和prestop的钩子
容器启动时,会调用我们定义的poststart脚本,该脚本定期检查容器Health Check,若通过后,就通过Confd更新HaProxy和reload,上线容器
容器销毁时,会调用prestop脚本,该脚本通过Confd更新HAProxy和reload,下线容器
Kubernetes在容器调度是最核心的一个功能,Kubernetes的scheduler是通过Plugin的方式编写,我们可以很灵活编写自己的调度算法,而对Kubernetes源码没有侵入性,其中调度算法分为两个阶段,Predicate(过滤)和 Priorities(优选),Noah云平台使用了Kubernetes的Node Selector、Node Affinity/anti-affinity、Pod Affinity/anti-affinity来对容器进行调度,使用request和limit对容器资源进行资源限定。
但实际运行过程中,资源并没有达到充分利用,我们需要更高效的利用率。因此我们考虑应用画像的调度算法。
5.1 应用画像
大家对用户画像并不陌生,其实应用画像也是类似,实现原理是分析应用N天的性能数据,计算出两个维度的数据。
两个应用画像维度:
一个维度是计算应用属于计算密集型、内存密集型、IO密集型,这一维度的数据是供我们做容器与节点(Node Selector)调度使用
另一个维度是应用跟应用直接的亲和度,这里举个例子,A,B两个应用都属于计算密集型应用,理论上它们应该部署到不同的节点,但A应用是白天忙,B应用是晚上忙,那其实它们是可以部署在一起,这样资源的使用率会更高
计算应用属于哪种类型
云平台从唯品会容器监控系统获取容器的不同Metric,然后使用正态分布算法,计算得出应用的类型
使用Kubernetes的Node Affinity来完成最后的容器调度
计算应用与应用间的亲和度
-
通过欧式距离(常用于机器学习中聚类算法的相似性度量)计算应用与应用间的相似度,越相似的应用越不能部署在一起
使用Kubernetes的Pod affinity和anti-affinity来完成最后的容器调度
Pod Affinity实现上有性能瓶颈,因此在设置Pod affinity的value值的时候只取排名靠前N个域名。e.g.
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: business_domain
operator: In
values:
- b.api.vip.com
- c.api.vip.com
topologyKey: kubernetes.io/hostname5.2 超配
我们根据线上运行的数据,发现机器的CPU使用率只有30%,经过分析因为Noah云平台采用核心域与非核心域混布的方式,也就是说一台物理机上会部署多个非核心域和核心域。这样部署的目的是想核心域能瞬时使用非核心域的资源,所以核心域的limit cpu是request cpu的1.5倍。但这样还不能达到资源使用率的提升。
根据下面的公式,我们推算出超配系数为3,也就是每台机器可以超配3倍。我们修改了kubelet,增加了--cpu-overcommit-times 启动参数,kubelet 上报cpu核数会乘以超卖系数。
如果大家有Cgroup的知识背景,了解cpu share和cpu quota的区别,就会懂的配置超配系数后,如果不是极端情况(机器上跑的所有容器都100% cpu usage),业务域容器承诺的limit cpu是可以保证的。
数据定义:
M:非核心域的CPU数
N:核心域的CPU数
Q:总CPU数
Tm:非核心域CPU利用率
Tn:核心域CPU利用率
T:整个集群的CPU利用率
资源分配公式:M+N=Q
利用率公式:Tm*M+Tn*N=Q*T
如果:Tm=0.1,Tn=0.7,M=2N(同一台机器,非核心域是核心域的两倍)
计算:
3N=Q
0.1*2N+0.7*N=Q*T
0.9N=Q*T,
0.9=3*T,T=0.3
说明,不超配情况下,集群CPU利用率只能达到30%,与实际情况一样
引入超配系数k
则公式为:
M+N=Q*k
Tm*M+Tn*N=Q*T
其他条件不变的情况下计算
0.9N=3N/k*T
k=3/0.9*T,如果目标全集群利用率0.9,则k=3
BTW,我们还在尝试使用应用画像,计算业务容器的request cpu,这样比超配方案更精确。因为超配方案是针对所有域的容器,粗粒度,应变快,而应用画像是根据历史数据计算,细粒度,但需要业务重新发布。
5.3 资源优化助手
为了更快捷更频繁的优化我们的容器云资源,我们提供了6种操作建议给运维。
垂直扩容是增大容器的资源规格,垂直缩容是减少容器的资源规格,垂直或水平扩缩容由运维与业务方协定。
垂直/水平扩容容器CPU规格,一周内CPU最高使用超过70%的域
垂直/水平缩容CPU规格,一周内CPU最高使用低于10%的域,按总闲置CPU排序,总闲置CPU=(CPU核数*(free百分比-70%)*容器数量)
垂直扩容容器内存规格,一周内CPU最高使用超过70%的域
垂直缩容容器内存规格,一周内CPU最高使用低于60%的域,按总闲置内存排序,总闲置内存=(内存规格*(free百分比-20%)*容器数量)
容器的磁盘和网络隔离是大家最头疼的一个问题,暂时只能限制使用量,防止某些业务容器有bug,导致狂写磁盘或打满网卡,影响同一台机器的其他容器。
Noah云平台是这样做的:
使用Kubernetes ConfigMap 配置docker IO options和 network options,docker options在Kubernetes启动Docker容器的时候传递参数,network options在Kubernetes调用CNI接口时传递
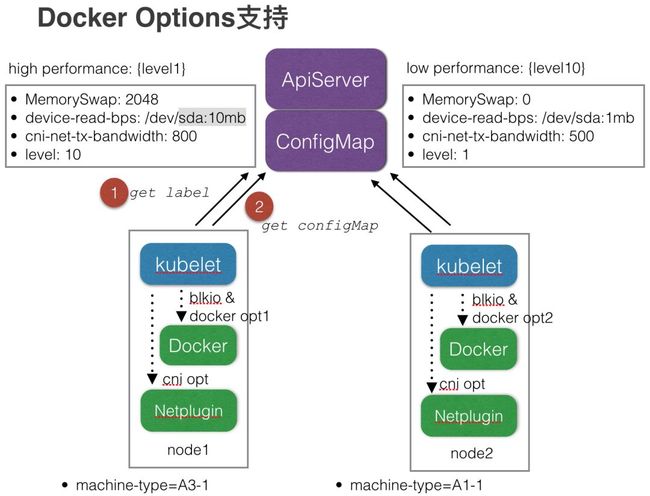
支持全局/按机器类型/按应用类型/按域 四种级别的配置。e.g. 不同机器类型,docker IO options不一样
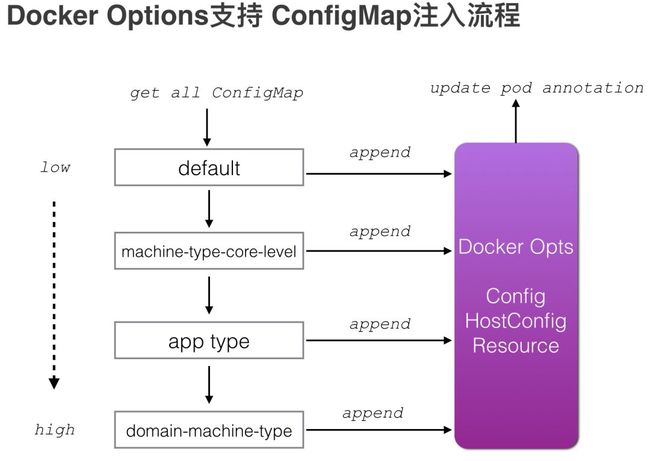
修改Kubernetes代码支持从ConfigMap读取配置并传递Options参数
该方案的限制:
只能限制单个容器最大值,肯定是超卖的
Disk IO 只能限制Direct IO,不能限制Buffer IO
日志采集方案在业界大部分都是考虑先写文件,然后通过Agent收集到中央,这样应用可以解耦。但这种方式,花费了Disk IO和网络IO,而且容器化后,日志量比物理机/VM的时代多了很多,对IO造成了一定的压力。因此业界也开始使用Log Appender直接发送的方式。
业界阿里云的例子:
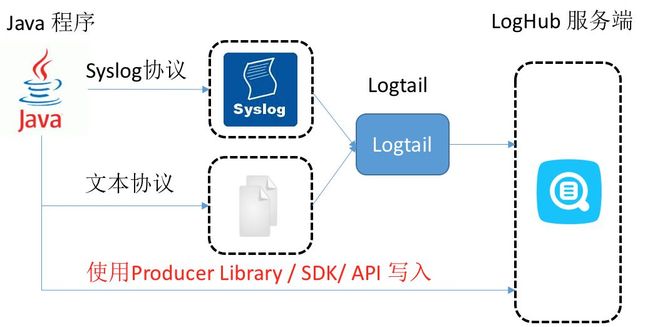
| 接入方式 | 优点/缺点 | 针对场景 |
|---|---|---|
| 日志落盘+Logtail | 日志收集与打日志解耦,无需修改代码 | 常用场景 |
| Syslog + Logtail | 性能较好(80MB/S),日志不落盘,需支持syslog协议 | Syslog场景 |
| Producer Library | 不落盘,异步合并发送服务端,吞吐量较好 | 日志不落盘,客户端QPS高 |
Noah云平台使用了类似的方式,开发日志不落盘的Log Appender,支持logback、log4j和log4j2三种log框架,支持两种模式,模式1是先落盘,超过rate limit(限流)后才发送到kafka,模式2:是先发送到kafka,超过rate limit后再落盘,默认使用模式2。
为啥发到Kafka,这跟唯品会的日志收集框架有关,请参考<<日志与监控>>。
因为日志不落盘Log Appender是以jar包形式给业务域使用,因此如何动态变更Log Appender是必须要做的,我们通过watch yaml格式的配置文件[容器通过mount物理机上的这个yaml文件],动态调整参数,比如rate limit值、kafka地址、kafka topic名称、message压缩算法,partition key等参数。
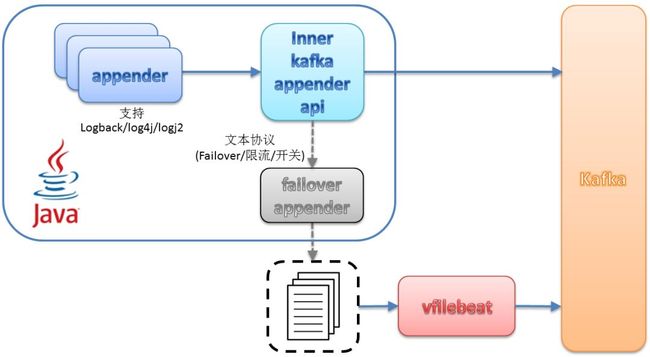
7. 容器高可用
Noah云平台在容器部署的时候,Kubernetes的Pod Anti-Affinity来实现同一个域的机架反亲和。避免同一个业务域的容器都部署到同一个机架上,防止由于机架网络问题或者掉电,导致服务不可用。
如何实现:
自动对节点打上rack的Node Label
在调度中使用Pod Anti-Affinity来对同域容器做反亲和
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: business_domain
operator: In
values:
- osp-noah-demo.jdk17.com
topologyKey: rack
weight: 100
7.2 单机房多集群
为了实现集群的高可用,Noah云平台提供多个IDC部署,业务可以同时部署到不同的IDC的Kubernetes集群,但核心业务对延时要求非常敏感,业务容器依赖的第三方服务还没有做到MHA,如数据库MySQL、Redis。这样容器多机房部署后,容器调用就变成跨机房调用。
为了提高集群的高可用,同时也防止跨机房调用,Noah云平台把一个IDC的大集群,拆成两个小集群,业务容器只需部署到同机房的两个集群,这样不单可以解决跨机房调用问题,也可以防止Kubernetes集群过大导致的调度性能问题。
聪明的你也会问,如果整个IDC都不可用怎么办?Noah云平台其实也提供了解决办法:
多IDC网络形成环路,避免光纤被挖断的尴尬
提供一键容灾迁移功能,快速迁移业务域的容器到其他机房(有几分钟的服务不可用)
8. 容器网络
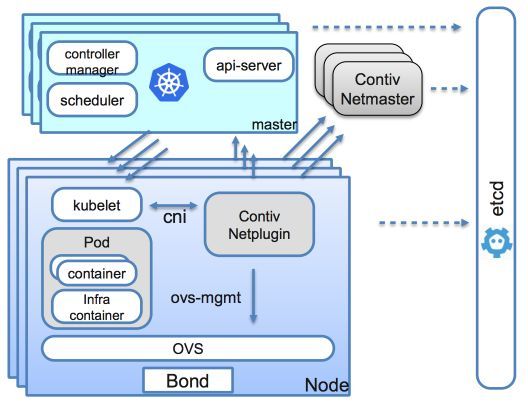
容器网络也是Noah云平台最重要的一环了,容器网络的互通性,性能是保证容器化推进顺利催化剂。因此我们的网络方案也做了很多调研和优化。容器网络方案使用Kubernetes CNI模型。
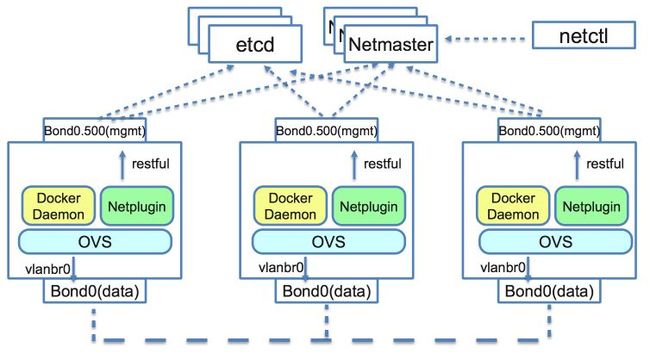
对比不同的容器网络类型:隧道方案 vs VLAN方案 vs 路由方案,我们最后选型的是Contiv Netplugin。
Contiv Netplugin:
这里说下我们网络方案优化的地方,为了让新增容器业务不增加现有核心ARP表压力,网关下移至TOR交换机,核心/汇聚交换机无需承载ARP,仅需运行路由协议或静态路由,可增加核心可靠性。
网关下移到TOR:
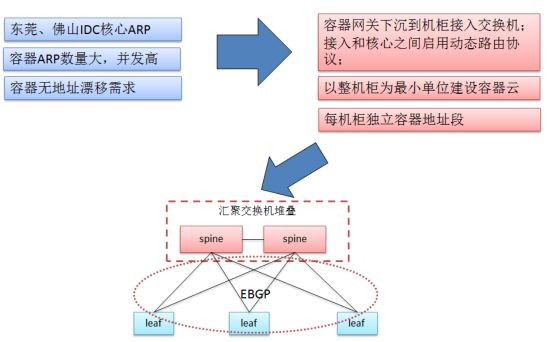
各组件的职责:
Netmaster
统一分配,管理子网与IP地址池,管理Docker网络,配置数据同步更新etcd
Netplugin
-
通过CNI接口与kubelet交互向netmaster申请IP、MAC等网络资源
创建veth pair ,为容器设置nic、ip addr、ip路由信息
管理OVS端,设置port\vlan\qos\流规则等信息
监听etcd,实时更新网络信息缓存
Endpoint 和 IP 地址池清理
OpenvSwitch
-
桥接容器与物理网口,承载来自容器业务流量转发
ACL访问控制和QoS限流
etcd
-
存储Contiv网络数据模型,包括网络名、Endpoint、IP地址池等信息,传递网络状态更新事件
9. 日志与监控
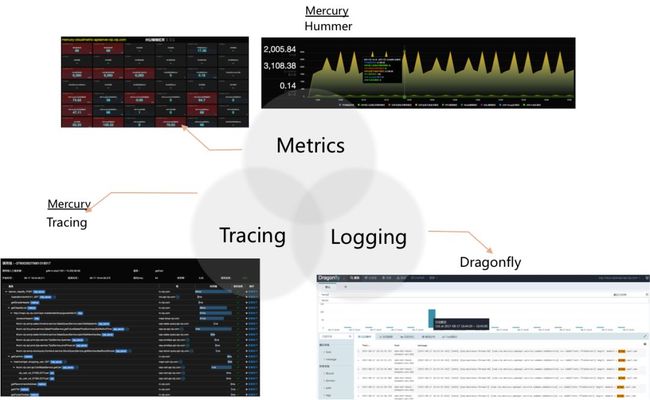
唯品会早就已经有自己的日志监控(Dragonfly)、业务监控(Mercury)和物理机监控(Falcon)系统。但它们也需要监控容器,因此也做不少工作。
我们在filebeat的基础上,开发了vfilebeat agent,日志采集性能比Logstash提高5倍。因为vfilebeat部署在宿主机上收集多个容器的日志,Logstash不能满足日志采集性能需求。vfilebeat把日志上报到kafka集群,Elasticsearch做日志索引,最后在dragonfly UI上供业务查询。
容器指标,我们开发了smart agent,它除了收集业务的trace log日志外,还收集业务自定义的metric指标,容器性能指标等。同时它也会触发告警,我们在告警时增加了命令执行钩子,这样可以在发生告警时做一些action,比如收集当时的dstat,收集容器进程的vjdump和火焰图等。
由于本文关注的是Noah云平台,因此这里就不详细展开日志和监控系统的架构了。
完整的监控体系指标:
10. 一些小技巧
Kubernetes提供了Liveness Prob,如果Health Check不过,容器会自动重启,但这样就没有现场了,业务就比较困难定位问题,所以Noah云平台在容器Health Check不过导致的容器重启,会自动执行唯品会开源的vjtools工具的vjdump命令,抓取当前的snapshot。
如何实现:
还是使用prestop的钩子,在prestop的脚本检查下容器的Health Check接口,如果不过,则执行vjdump
唯品会有日志收集系统Dragonfly,在物理机/VM的时代,Dragonfly的vfilebeat agent会收集业务域目录下指定文件,如/apps/logs/log_receiver/{domain-name}/xxxx.log,但容器化后,同一个业务容器可能跑到同一台宿主机上,如果按照原来的log路径mount到宿主机的话,会导致两个容器同时写同一个日志问题,导致log错乱等问题。
如何实现:
容器日志mount到宿主机上,增加PodName做为Path的一部分,如: /apps/logs/logreceiver/{domain-name}/{pod_name}/trace/trace.out
在容器初始化脚本通过软链接的方式,把容器/apps/logs目录link到/docker/logs/${PODNAME}, 其中PODNAME环境变量是kubernetes设置到容器里面的,是唯一的名称
if [[ ! "${!SKIP_LOG_SETUP[@]}" && -e /docker/logs ]]; then
mkdir -p /docker/logs/${POD_NAME}
chown xxx:xxx -R /docker/logs
if [ -e /apps/logs ]; then
rm -rf /apps/logs
fi
ln -s /docker/logs/${POD_NAME} /apps/logs
fi
容器发布的时候,把容器里面的/docker/logs目录mount到宿主机的/apps/logs目录
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
volumeMounts:
- mountPath: /docker/logs/
name: smartgagent
volumes:
- hostPath:
path: /apps/logs/
name: smartagent
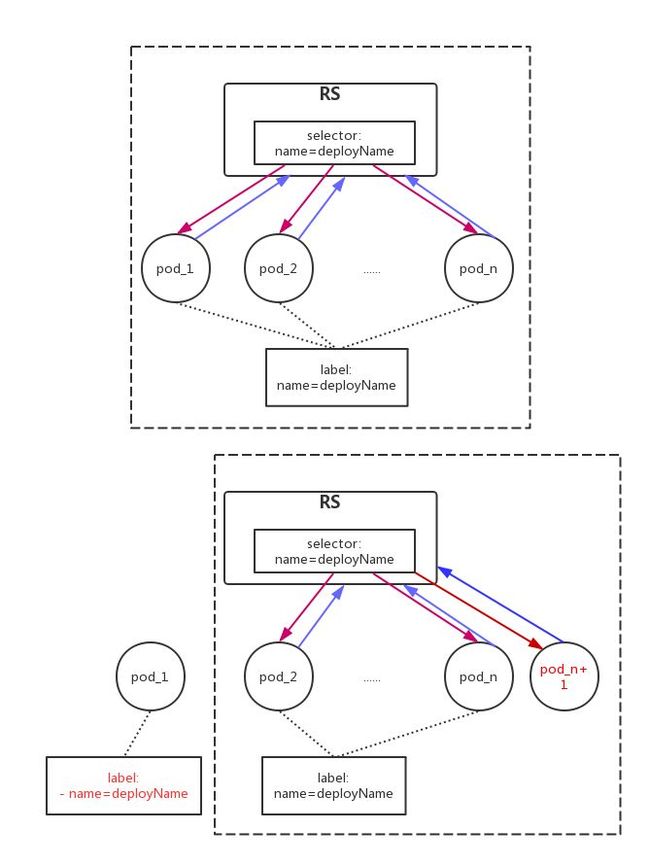
如果业务需要线上容器来定位问题,可以先把某个容器的流量摘掉就可以了,但若想保证容器的instance数量,怎么做呢?Noah云平台使用了Kubernetes ReplicaSet Selctor的特性,如RS有selector:[a=b, c=d],则含有且不限于label:[a=b, c=d]的Pod,且Pod的metadata.ownerReferences有指向此RS的引用,那么这个Pod就被视为被RS管理。
鉴于此特性,如果想将某个容器隔离出当前的RS,只需要修改此容器的label即可,为了能够方便查询被隔离的容器,Noah云平台把label修改为[name-bk=deployName,pod-status=isolate]的方式。以下是隔离的过程图。
 10.4 巧用Pod中断预算(Pod Disruption Budget)
10.4 巧用Pod中断预算(Pod Disruption Budget)
Pod中断预算是Kubernetes用来保证应用的高可用的,对那些Voluntary(自愿的)Disruption做好Budgets(预算方案),这里说到PDB是解决Voluntary Disruption,不解决Involuntary的场景。
官方文档已经有说什么叫Voluntary和Involuntary场景,我这里就不在多说了:Kubernetes Pod Disruption Budget。
我这里说下Noah云平台怎样巧用PDB。在我们做集群机器的内核升级过程中(需重启机器),为了保证升级过程不中断业务,运维必须按机柜来重启机器,因为如果多机柜同时操作的话,如果某个业务域的容器刚好都在这批重启的机柜上,那这服务就中断了。
这时,我们使用PDB。在升级前,为Kubernetes集群中每个Deployment创建PDB[一个脚本搞定],然后运维升级内核重启机器就不需要按机柜逐个做了,就把大集群的机器分多批来做,在执行kubectl drain命令的时候,PDB会产生效果,保证业务容器的最低Running Instance个数,如果少于最低Running Instance,则drain命令会block,直到符合PDB要求,才继续。
我们使用这种方式,以前几百台机器都要升级一个下午,现在基本1小时能够完成上千台机器的内核升级重启。当然这是我们使用PDB的例子,但其实也有很多地方可以使用的,比如ZooKeeper、etcd要保证最少容器数等。
PDB例子:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: $deploymentname-pdb
spec:
maxUnavailable: 50%
selector:
matchLabels:
name: $deploymentname
11.1.1 CPU开启Performance模式
生产服务器默认都调整为Performance模式的,但在CPU是E5-2630 v4这个型号的华为机器不生效。这里分享下我们的经验:
系统交付时,检查/proc/cpuinfo的CPU主频是否跟硬件主频一致
监控容器的cpu throttled number和cpu throttled time指标,如发生throttling,要double check一下机器的CPU主频
在系统高IO的情况下,如果不设置dirtybackgroundbytes,默认使用dirtybackgroundratio的设置,默认是10,在现在动不动几十G内存的机器,值非常大,当把这么大量的page cache数据刷到磁盘上的时候会超过普通磁盘的iops。因此我们设置这个参数,满100M就刷盘。
vm.dirtybackgroundbytes = 104857600
高IO的场景,也会影响JVM进入Stop the world的时间,因为JVM经常会默默的在/tmp/hperf 目录写上一点statistics数据,如果刚好遇到PageCache刷盘,把文件阻塞了,就不能结束这个Stop the World的安全点了。因此我们在JVM启动参数增加了-XX:+PerfDisableSharedMem。
高IO的场景,也会Block GC Log打印,从而Block Stop the World的过程,因为打印GC log是用VM Thread来做的,JVM虚拟机只有一条VM Thread,所以当这条线程在安全点内被BLOCK住,Stop the World问题就比较严重。因此我们把JVM的gc log打印到/dev/shm/ 目录下,如果进程重启,stop脚本会把ram disk的gc log move到磁盘保存。
11.1.3 设置swapniess
操作系统OS的swapniess默认是60,这是Linux在很久的时候设置的默认值,可能当时内存容量没现在这么大吧,但现在这个默认值已经不合适了。如果不修改,那内存剩下很多就开始用swap了,用了swap,各种超时就出来了。因为容器的内存是根据JVM Heap计算出来的,通常都比JVM Heap要大,因此我们把swapiness修改为0。
vm.swappiness = 0
11.1.4 设置fs.inotify
Kubernetes kubelet会watch一些文件,如果不设置该值,当节点容器数量比较多的情况下,会报no space left on device。
当然我们的节点不但只有kubelet,还有一些agent,比如日志收集agent,监控agent都会watch 文件,也会用到inotify的watch数量。
fs.inotify.maxuserwatches = 24576
11.2 容器线程数过多的问题
业务容器化后,运行时线程数暴涨,后来分析后,根本原因是很多框架或第三方库,都是通过Runtime.getRuntime().availableProcessors()获取CPU核数来计算线程数,很悲剧的是,JDK 1.9以下版本都只能获取物理机的核数,这样导致线程数超多,由于容器的CPU资源受限,因此这么多线程数,导致Context Switch增大,从而消耗CPU和影响性能。
发现JDK已经有个bug跟进JDK-6515172。但业务大部分都是JDK 7和 JDK 8的。我们使用了libsysconfcpus去拦截_SC_NPROCESSORSCONF和 _SC_NPROCESSORSONLN 系统调用,返回容器分配的CPU值。
在容器启动脚本export LDPRELOAD="/usr/local/lib/libsysconfcpus.so:$LDPRELOAD",CONTAINERCORELIMIT是Noah云平台上每个容器都有设置的容器CPU Limit值。
if [ "x$CONTAINER_CORE_LIMIT" != "x" ]; then
LIBSYSCONFCPUS="$CONTAINER_CORE_LIMIT"
export LIBSYSCONFCPUS
fi
export LD_PRELOAD="/usr/local/lib/libsysconfcpus.so:$LD_PRELOAD"
系统调用:
| Key | Description |
|---|---|
| _SC_NPROCESSORS_CONF | The number of processors configured |
| _SC_NPROCESSORS_ONLN | The number of processors currently online (available) |
11.3 从Kubernetes 1.6.4 升级到1.9.8版本后遇到的问题
我们用的CentOS的内核版本是3.10.0-862.9.1。 但升级到1.9.8后,容器销毁会导致cgroup memory没有释放,最终导致启动新容器时报“no space left on device”。
根本原因是1.9.8默认打开了OS的Kernel Memory,而我们用的内核版本的Kernel Memory是不稳定的。回想起问题定位过程,真的非常艰巨,连续几天披星戴月啊……当然我们也总结了踩坑过程:Kubernetes 1.9与CentOS 7.3内核兼容问题(http://www.linuxfly.org/kubernetes-19-conflict-with-centos7/)。
解决方法:
升级内核到4.x版本风险大,最后折衷,通过修改了Kubernetes一行代码,暂时关闭Kernel Memory功能,暂时解决这个问题。
我们在Kubernetes GitHub上提的issue 61937(https://github.com/kubernetes/kubernetes/issues/61937),然后发现很多人都遇到相同的问题。
12. On The Way
这里说说我们正在做和准备做的一些事情,希望能引起一些大家的讨论。
12.1 CRD/Operator的应用
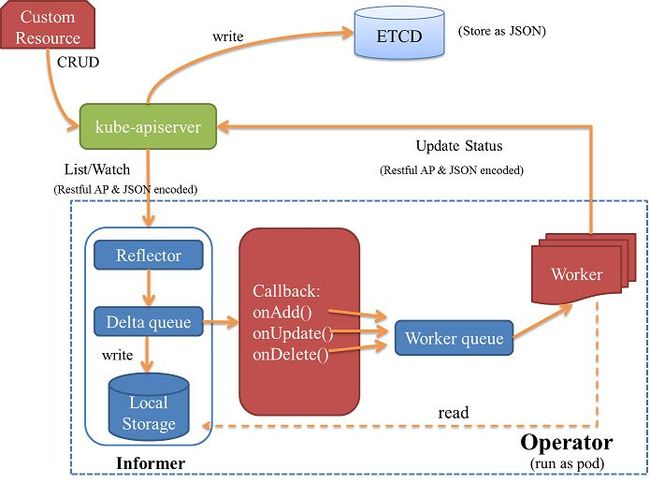
Operator是由CoreOS开发的,用来扩展Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用。有些集群需要一些特殊操作才能构建起来,如etcd、Redis Cluster、Kubernetes提供的StatefulSet不能满足这些需求。因此Kubernetes提供了CRD(自定义控制器)的方式,让我们可以扩展,其中Operator就是一系列应用程序特定的自定义控制器。
Noah云平台使用Operator技术,构建了Redis cluster、MySQL cluster供测试环境使用。
Operator构建方式:
使用Kubebuilder来构建Operator framework。
Operator与其他controller manager工作原理一样,以leader模式运行。(建议每个Kubernetes集群部署3个Operator)。
Operator使用Informer组件,监听资源状态。当资源发生变化时,根据事件类型调用对应的callback函数。
Operator的任务是使Custom Resource的状态,和Spec定义保持一致。 Custom Resource以json的格式保存在Kubernetes etcd中。
12.2 基于Local Storage的容器调度
MySQL Operator的存储是使用了分布式Ceph存储,性能方面不能满足生产需求,DBA希望MySQL容器可以使用本地的SSD,因此我们需要基于Local Stroage的容器调度。
Kubernetes 1.9提供了VolumeScheduling,就是基于Local Storage的调度。
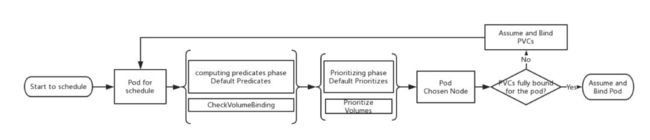
CheckVolumnBinding的逻辑:
已绑定PVC:对应PV.NodeAffinity需匹配候选Node,否则排除该节点
未绑定PVC:该PVC是否需要延时绑定,如需要,遍历未绑定PV,其NodeAffinity是否匹配候选Node,如满足,记录PVC和PV的映射关系到缓存bindingInfo中,留待节点最终选出来之后进行最终的绑定
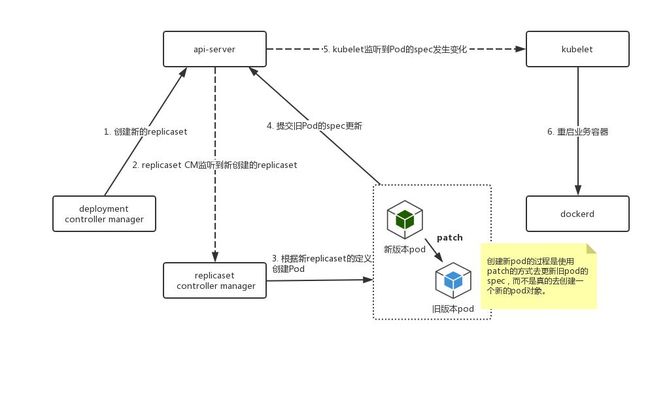
有些业务希望容器能够在本地做patch重启,比如第一次发布根据调度规则把容器部署到不同的节点上,后面的新版本发布,他们希望新容器能够在以前的节点上重启容器。该需求的目的是容器与物理机相对固定,业务就可以做一些事情,比如一些降级文件可以只下载一次,不需要每次发布都下载一次降级文件(降级文件比较大),还有一些目的是加快容器启动速度,锁定容器资源,重用数据卷等。
当然容器本地rebuild会丧失容器调度的能力,因此只会对某些域开放。
容器本地rebuild实现后,容器的IP相对就固定了,因为patch容器的时候,Kubernetes pause容器没有被重启,只重启业务容器,因此容器的IP是不变的。我们在此基础上,结合我们容器网络拓扑的特殊性(因为网关下沉到机柜上,所以容器IP与机架必须对应),开发了容器固定IP。
我们也是使用Operator框架,开发了ReusableSet Controller。
容器本地rebuild:
 13. 结束语
13. 结束语
14. Q&A
Q:灰度发布时,两个应用前要加负载均衡吗?A:我在服务注册发现章节提到唯品会有自研的服务化框架,是通过服务化框架的Proxy做LB的,LB是服务治理的一个重要功能。对于HTTP服务,最后还是注册到HAProxy的,因此还是通过它做LB的。
Q: 有状态的服务比如IP固定,不知道你们有没有这种服务,是怎么解决的?A:我们是有写有状态的服务,如Redis和MySQL,是通过CentOS Operator框架,自己编写Operator解决的。固定IP我们正在开发中,因为要结合唯品会的网络拓扑,实现起来稍微复杂点。还有,我们在做的rebuild方案,IP也是相对固定的,如果没有触发Kubernetes的scheduler调度的话,比如node evict。
Q:请问,外部请求如何路由到Kubernetes集群内,是使用的Ingress吗?A:外部流量的接入,唯品会有VGW的Gateway,通过APP上的智能路由找到最优机房的VGW,然后一层一层到容器。
Q:超配的情况下,如果各个pod load都增大,驱逐策略是怎样的?A:这里我没有讲细,你的问题很仔细啊,赞,我们开发了热点迁移容器的API,监控系统如果收到告警(比如CPU过高,IO过高),会调用我们API,我们API获取实时的监控数据,根据某个算法,迁移走部分热点容器。
Q:自动缩容的时候是如何选择Pod,如何保证数据不丢失呢?A:自动缩容之针对无状态应用的,而且我们要求所有上云平台的应用,都支持Graceful Shutdown,由业务保证。
Q:Tomcat类应用容器Xmx内存分配多少比例合适,就是Xmx使用百分多少容器内存合适?A:JVM内存的计算包括了Heap+Permgen+线程数的stack(1M/per线程)+堆外内存,所以我们监控容器的RSS数据,这是容器真实的内存占用。
Q:集群空闲率多少合适?我们的集群超过60%上面的容器就不稳定了。A:我们为了提高资源利用率,做了很多事情,上面有说到,你说的60%就不稳定,需要具体分析下,因为我们也踩过一些Kubernetes和Docker的坑,同时也需要优化好系统参数,有时候问题也跟内核版本有关。

