Kaggle比赛记录和总结
Kaggle比赛
这个比赛我觉得是半年来收获最大的
过程
开始做这个比赛的时候,还有两个月的时间,花了一些时间看相关论文,当时看的是PVNet和CDPN,最后决定用CDPN试一下
CDPN
CDPN的预测需要mask信息和每个物体的3D模型的。
Mask:
比赛数据集没提供mask信息,就想着试试不用mask的话,CDPN效果如何:
还试了不同的scale参数,其中不用Mask最好的效果:

使用Mask最好的效果:

事实证明,还是需要Mask的,不然效果连Baseline都赶不上。
所以,对于Mask信息的获取进行了以下尝试:
1.一开始尝试将所有的3D点云射影到2D图像上来获取Mask,但是失败了,这种质量的Mask是不能用的:

2.想用其他数据集来训练一个实例分割器,后来找了数据集之后觉得没有必要
3.使用Hybrid Task Cascade算法在COCO上训练的权重试了下,效果很不错,就打算先用这个来获取Mask信息了:

3D Model:
CDPN的要求是每个物体和自己所属的模型对应上,我当时觉得这么多车型不好做分类,用车的尺度的平均值做映射的模型,用2D图像的像素预测对应的3D点
比赛结束后看6DVNet和RoI: 10D这两个论文,前者对汽车进行了车型分类(奥迪、宝马)这样的,后者提出了一个方法,能处理同类的模型
然后对这个CDPN的方法坐在了初步规划:
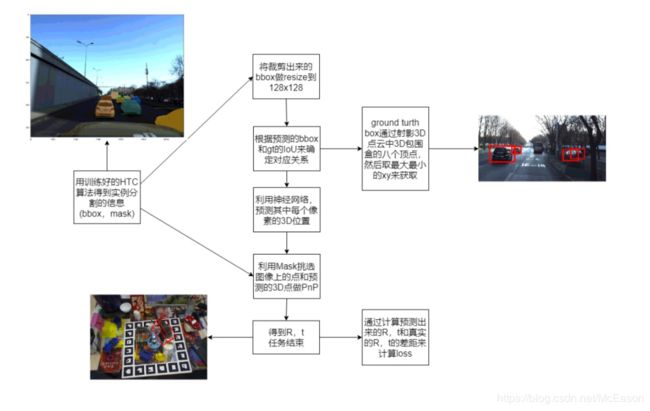
写完代码之后进行训练,训完之后发现效果很不好,框都上天了

后来发现是有两个错误:
- 我用的2D逆射影到3D空间,但是这样少了个z信息,是无法得出正确的3D空间坐标的。
- 我是用的输入信息是经过resize的,这样的话做pnp不经过处理的话是得不到正确的RT信息的。
修改之后又继续进行训练了。
2D与3D坐标的拟合:
后来想将R和T分开处理,尝试用多项式来函数化图像中的xy和空间中的XYZ的关系,将X、Y、Z分别用x、y来拟合,发现效果并不好,所以还是要用深度学习的方法。
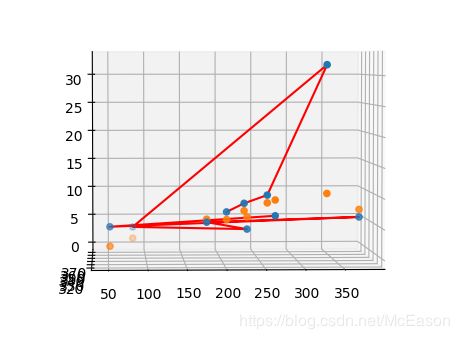



虽然我多项式拟合失败了,但是我觉得X、Y、Z和xy之间应该有一种对应函数,可直接算出,因为车都在路面上,就是说不会有车完全在另一个车的后面,也不会有深度位置的问题,如图所示:
后来经过老师的指点,用3D空间的数据拟合一个平面,因为车都是在地上走的,必然都在路面这个平面上,使用的代码如下:
回学校了再加上
这是参考的方法:
平面拟合 SVD版本
求交点
拟合出的平面如图:

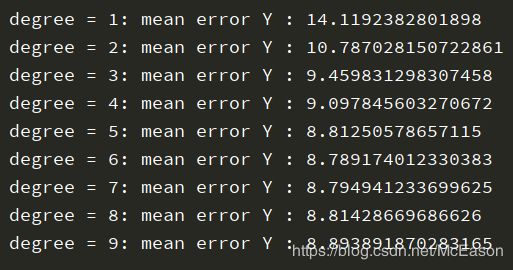
计算的误差如下:

误差还是大到不能用,比赛完了回家后发现,我的方法是有错误的:
我把成像平面放到了焦距处,而成像平面应该在 z z z处,具体信息可以看看这个:针孔摄像机模型和透镜
但是效果还是不行,loss也降不下去,感觉还是车的模型那里有问题,之后就放弃了CDPN的方法,使用其他参赛者提供的kernel,进行一些改动,毕竟参加的初衷就是练手,提不出新方法,学学别人的也是一种进步
CenterNet
这个方法其实没什么东西,就是直接回归
尝试的方法:
-
用bin的操作来获取角度roll,CenterNet源码就是用的这个操作
这方法有时候有效,有时候没用,我感觉可能是网络结构的原因?在下面的实验中是无效的
-
对pitch也做了角度bin预测,降分 18行
-
将不同的信息用不同的branch来预测,loss比例设置为0.1:0.7:0.3,这是我的唯一有效的改动
后来在其他论文里也看到这样的描述。Attention is all you need 里面也提到了,RoI10D也提到了,同多头预测多种信息,只用一个头会造成能力”挥发“
-
使用训练了十个epoch的权重,将backbone固定住,只让旋转和位移头训练,再训练3个epoch,结果见13 14 15行实验
不知道为什么没有提升,这种做法论文里常用,但是我用了却没效果,要么是官方的test有问题,要么是两个head已经学习的差不多了
-
backbone、loss、bin中角度的调整,统统没用
b2换b0,试了focal loss,应该是哪里操作错了
-
input size的调参,结果见5 6 9
其中的2048是有效果的,但是在平时的提交中显示不出来,在最后使用全部test的时候,分挺好的
-
对权重比例的调整,0.1:0.7:0.3 和 0.2:0.8:0.2 结果见 13 16 降分
-
对pitch用softmax来预测,因为数据的分布只有三个, π , 0 , − π \pi,0,-\pi π,0,−π,就想直接用分类,但是结果也不好
消融实验
| backbone | epoch | size | weight | process | score | line |
|---|---|---|---|---|---|---|
| resnet | 10 | 1600,700 | None | None | 0.038 | 1 |
| resnet | 10 | 1024,320 | None | None | 0.033 | 2 |
| resnet | 10 | 1600,700 | 0.1 :0.9 | None | 0.047 | 3 |
| RB | 10 | 1024,480 | 0.1 :0.9 | None | 0.050 | 4 |
| RB | 10 | 1024,480 | 0.1:0.9 | branch | 0.057 | 5 |
| RB | 10 | 1600,700 | 0.1:0.9 | branch | 0.063 | 6 |
| RB | 10 | 1600,700 | 0.1:0.9 | branch、change | 0.063 | 7 |
| RB | 8 | 1600,700 | 0.1:0.9 | branch | 0.052 | 8 |
| RB | 10 | 2048,512 | 0.1:0.9 | branch | 0.060 | 9 |
| RB | 20 | 1024,480 | 0.1:0.9 | branch 、depth | 0.044 | 10 |
| RB | 10 | 1024,480 | 0.1:0.9 | branch、fix+3 | 0.050 | 11 |
| RB | 10 | 1024,480 | 0.1:0.7:0.3 | roll、2/3pi | 0.035 | 12 |
| RB | 10 | 1024,480 | 0.1:0.7:0.3 | branch 、roll、2/3pi | 0.048 | 13 |
| RB | 13 | 1024,480 | 0.1:0.7:0.3 | branch、roll、fix+3、2/3pi | 0.047 | 14 |
| RB | 20 | 1024,480 | 0.1:0.7:0.3 | branch、roll、fix+10、2/3pi | 0.047 | 15 |
| RB | 10 | 1024,480 | 0.2:0.8:0.3 | branch、roll、2/3pi | 0.039 | 16 |
| RB | 10 | 1024,480 | 0.2:0.8:0.3 | branch、roll、pi | 0.039 | 17 |
| RB | 10 | 1024,480 | 0.1:0.7:0.3 | branch、pitch | 0.032 | 18 |
| RB | 10 | 1024,480 | 0.1:0.9 | branch、b2、focal | 0.000 | 19 |
| RB | 10 | 1024,480 | 0.1:0.9 | branch、b2 | 0.038 | 20 |
| RB | 10 | 1600,700 | 0.1:0.9 | branch、more aug | 0.059 | 21 |
| RB | 30 | 1600,700 | 0.1:0.9 | branch、aug | 0.058 | 22 |
| RB | 8 | 1600,700 | 0.1:0.3:0.3 | branch、patch | 0.040 | 23 |
安排记录
写出来的计划不是当天要完成的,是后面要做的,还有一些是碎碎念
12.12
- 搜集mask数据集
找了个apollor 不好用,要c++ render - 找好的实例分割算法
12.13
- 把CDPN的mask改了
结果:不用mask效果真的很差
12.14
- 配置好mmdetection
- 写训练代码
- 测试mmdetection的mask效果
测了detection效果,一般
使用inference中的shwo_result来得到数据 - 检测器调试
https://zhuanlan.zhihu.com/p/75171514
还搞不懂就看看这个
好像是版本不匹配问题 - 写CDPN的训练代码
12.15
- 复习矩阵分析
- 把mask详细信息搞出来
- 写训练代码
- 写mask与后面网络相融合的代码
12.16
- Mask获取代码
有了,输出成npy文件保存起来,或许也可以保存到一个文件里
处理之前应该注意的,人家的大小是640x480,而我直接用的全部进行计算 - Maks相关resize
获取crop的mask图,并resize成128x128 - IoU选择crop
得到真实image的所有bbox,保存到一个文件中,选中的crop才会进行训练 - 写训练代码
- 写mask与后面网络相融合的代码
- 复习矩阵分析
12.17
- 写新数据集读取代码
- IoU选择crop
得到真实image的所有bbox,保存到一个文件中,选中的crop才会进行训练 - 写训练代码
- 写mask与后面网络相融合的代码
12.28
- 训练效果很差,排查原因
- 修改代码,重新训练
- 详读CenterNet Baseline
- 尝试其他方法,比如中心点预测scale,固定框架预测 Δ x , Δ y , Δ z \varDelta x,\varDelta y,\varDelta z Δx,Δy,Δz。
- 想想有没有办法写个拟合器,直接从像素位置估计xyz,这个位置要是中心点
12.29
- 看CenterNet Baseline
- 写多项式拟合器
效果很一般 - 试着尝试其他方法
- 在看看kaggle的讨论
- 数据增强还没做
- 或许可以试试复现分开计算过程
1.2
- 学习centernet论文
- 学习centernet代码
1.3
- 按照论文的方法修改loss
- 尝试修改bin来预测 θ \theta θ
- 结合CDPN
尝试了修改mask loss和depth loss,MaskTrain,input=1536,得到的分数为0.013
1.4
- 消融实验
- 学习CenterNet中的多bin操作
- 学习CenterNet中的loss计算
- 结合CenterNet和CDPN
- 写一个结果可视化,好不好先看一眼
- 尝试了修改mask loss和depth loss,MaksTrain,input=1024,得到的分数为0.010
1.5
- 学bin操作
- 看demo代码
- 看训练代码
尝试了MaskTrain和maskloss的改动,input=1024 batch=2,得到的分数为0.008
只改动mask loss,得分0.010 看来这个loss很垃圾
input改成2048 得分 0.011
1.6
- 复现方法
- 先不改backbone,只改输出
1.8
- 算pitch角度
1.9
- dropout还能用
- 改bin的代码错误
- 换成pi
1.10
- 换成2/3 π \pi π
mask depth 都是0.039
都是0.004的提升
loss往上跑了基本不行
1.11
- 复习政治第一轮结束
- 复习英语单词结束,加一些翻译
- 找bin代码的错误
- 看mask和depth loss的结果
发现了问题所在,还是sorted这一块,没对应上
1.12
权重有用
1.16
10次,bin 全部的训练数据 0.039
不对啊,不应该是0.048 最高的这种吗
先看看这两个的结果,然后看看在哪改动
现在也就是换了个backbone
重头戏还在softmax
这个交叉熵还有weight,那我岂不是可以根据数量比例来设置这个weight了
感觉restnet的x不对劲
复现的173 10epoch只有0.036 ???哪里出问题了?
多个头怎么做?
Rb 里面有两种移除方法
预训练 可以先训练5个epoch,我一开始直接用两个分支,训完5个之后,再
那些分类的,必然有两个值,一个是置信度,一个是values
多一些分支和卷积层,来让各自的分类更准确?
试试锁或不锁
只有depth的时候对应的是7个预测量
test_rolll 的车太少了,看着挺准的
bin_roll错一般就是没对应好
还有 直接复制很多容易出问题,threshold就出现了问题
1.18
试试固定base
感觉没啥用啊,训十个再看看
旋转loss好像降不下去了
感觉depth确实对z有提升
不,没有,人家原版的效果也不错
再试试原来的branch在多寻3个什么结果
更差了?????
想法
当时的一些乱七八糟的想法,随便一记:
如果效果好,给roll也整个分类?
不好
现在epoch加深已经什么效果了,但倒是dropout的原因?
试试把dropout关掉后再训练几个epoch,
把原来的0.058去mask试试,用的RB的方法
我现在是不是应该好好看看这个阈值处理? 但也就那么点东西
阈值的选择, 就是根据实际的图中的车的数量,寻找一个阈值,来让预测出来的车和实际的车的数量相似
多模融合,取平均值?
训练次数问题,没加dropout更好?
我还可以再把z单独拎出来
或者直接试试分支的roll?
像个方法让车的大小成比例?
热图?
中心点+位置,多层预测?
上采样?
这个能进行一定的分类,不如,利用一下,根据分类决定维度?
这样就要在数据集上下功夫了
全部看一看车型
突出的标记出来
看看能检测到什么样的车
卡车,吉普这样的,给另外的minxyz
这个比例也是跟z相关的
训练的时候或许并不能处理好这种工作?如果size差很多,那么预测的loss就高
是不是可以分成两阶段训练,根据有无大型车?
很想试试预测偏差bin
想到一个计算R,t的损失的方法,用预测出来的3D点的信息,和真实的Rt做射影,然后计算原版的2D坐标和摄影出来的2D坐标的差别
作者的方法是,用真实的RT来生成真实3D位置,然后计算和预测出来的差
世界坐标系中的XYZ会相互影响,这个用来调整?先用x,y预测差不多的XYZ,再用XYZ之间的关系微调XYZ
还有个问题,是在resize上做的预测,预测出来的RT不会不同吗?
这个尺度缩放问题一直有坑
训练的时候尺度变成原来的
可以总结一下, 什么样的input能检测出什么样的车
总结
这次比赛的结果并不好,只有20%,菜是真的菜,菜的点有很多。
工程能力:
- CDPN只给了测试代码,按理讲对着测试写训练也不是什么难事,但是那会连pytorch的反向传播机制都不清楚,有梯度的才能求导
- 对结果的可视化很垃圾,只是用的3D bbox,而6DVnet中直接把模型映射到了2D图像中,很ground truth pose的差别一目了然
- bin方法的实现还是依赖别人写的代码
执行力:
有些改动我想到了,在后面看的论文里也看到了,但是当时也没有去实现,比起论文中的也过于简单稚嫩
论文量:
在做比赛之前读的这一块的论文确实是少,之间看的都是检测的论文,对这个任务来说用处不大。比完了之后看了不少论文,其中有不少都能对这个比赛带来提升,而我之前根本不知道,比如注意力机制,以前光听说也没看这块的论文,更不知道怎么用,后来看了[ Attention is all you need ]、[ Non-local Neural Networks ]、[ Dual Attention Network for Scene Segmentation ] 这三篇跟注意力机制相关的论文,用了之后必然是有提升的,而且6DVNet中也用了;还看了后处理操作的论文 [ DeepIM: Deep Iterative Matching for 6D Pose Estimation ] 这个也必然能优化pose估计的结果,可视化的时候看到有些路口转角的车的角度预测确实不好,有了这个方法就能对那些进行校正;而且对于汽车的子类,[ 6DVNet ] 使用再分类的方法,[ RoI10D ] 提出新的方法来处理同范畴形状显示的物体,而有了这些信息那就有好多方法可以尝试,CDPN和PVNet都可以尝试。问题就在于之前的论文读的不够,脑子里的方法太少,没有成绩也是应该的
其他:
对于3D几何这块的知识确实不够了解,之前只是看了,但是没有应用,不知道怎么用,也很快就忘了,这次结束后回去补了补几何的知识。
还有就是真的觉得要是有个人带带就好了,如果有个有比赛经验的人能指点一下,那就少走很多弯路,自己搁着搞费时又低效
通过这次比赛也看清了很多问题,对于神经网络的能力有了一点了解,而且对于以后该干什么也比较清楚了:多看论文,多做实验,论文才是王道。读论文该注意哪些点,尤其是实验部分,还有实验代码的具体操作,都很重要。