爬虫学习(一)
先来复习复习字符串的编码方式
字符串复习
字符串符合两种类型
bytes:二进制
互联网上数据的都是以二进制的方式传输的str:unicode的呈现方式
两者是可以相互转换的,但必须编码解码方式一样,否则就会出错
str使用encode方法转化为bytes
bytes通过decode转化成str
a = '你好,爬虫'
print(type(a))
b = a.encode()
print(type(b))
print(b)

还可以加上编码解码方式
b = a.encode("UTF-8")
后续如果爬虫网页源代码出现乱码,可能就是编码方式不一致
那么正题要开始了
requests使用入门
如何请求页面,并获取页面的内容
import requests
# 请求网页
r = requests.get("http://www.baidu.com")
# r是一个response对象,我们想到得到的信息都可以从它获取
print(r)
# 得到r的内容
print(r.text)
如果打印r.text出现乱码,则可以先指定编码方式,再打印看看
# 指定编码方式
r.encoding = 'utf-8'
print(r.text)
还有一种方法可以获取网页的内容
那就是r.content
但它是二进制形式打印出来
需要解码,可以指定编码方式(默认是utf-8),例如gbk,gb2312
r.content.decode()
更推荐这种方式获取网页内容
动动手-保存图片到本地
不仅图片,mp4,gif,pdf等常见的格式文件都可以这样做
import requests
# 图片地址
page_url = 'https://i0.hdslb.com/bfs/archive/cb110cffbf66ae37169e1b8bca68d138a9de97e5.png@880w_440h.png'
# 发送get请求
r = requests.get(page_url)
# 保存,写入二进制文件
with open('a.png','wb') as f:
f.write(r.content)
获取更多的数据
- response.status_code 状态码,当为200的时候请求某一个url成功,并不一定是访问我们想要的url成功,因为登入的时候网页有重定向
- response.request.url 请求的url
发送带headers的请求
为什么要发送带headers的请求?
发送带headers的请求的目的就为了模仿浏览器访问网页,欺骗服务器,获取和浏览器一致的内容
那headers从何而来呢?
在浏览器上面,按F12,点击network
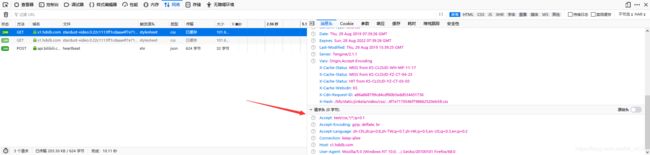
最常用的是User-Agent
import requests
# 请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"
}
# 发送get请求,带请求头
r = requests.get("http://www.baidu.com",headers=headers)
# 打印内容
print(r.content.decode())
发送带参数的请求
什么是参数?
比如这个url
https://www.baidu.com/s?wd=python&c=b
?后面以 & 分开的都是参数
那么这个?可不可以去掉呢?
我们来尝试尝试
先不去掉,试试看
import requests
# 请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"
}
# 参数
p = {"wd":"python"}
# 发送get请求,带请求头, 带参数
r = requests.get("http://www.baidu.com/s?",headers=headers,params=p)
# 打印状态码
print(r.status_code)
# 打印请求的url
print(r.request.url)
可以请求成功

把?去掉看看
import requests
# 请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"
}
# 参数
p = {"wd":"python"}
# 发送get请求,带请求头, 带参数
r = requests.get("http://www.baidu.com/s",headers=headers,params=p)
# 打印状态码
print(r.status_code)
# 打印请求的url
print(r.request.url)
发现是一样的

如果不确定的话,可以用字符串拼接
# 发送get请求,带请求头, 带参数
url = "http://www.baidu.com/s?wd={}".format("python")
r = requests.get(url,headers=headers,params=p)
动动手-任意贴吧的爬虫
想要实现任意贴吧的爬取,就要分析url的规律
例如 https://tieba.baidu.com/f?kw=李毅
kw后面的值为什么,就是什么吧
然后我们想爬取这个贴吧的1000页页面的内容
1000页!这也得要找出规律
当我们点击下一页的时候,url发生了这样的变化
https://tieba.baidu.com/f?kw=李毅&pn=50,后面多了个pn=50
继续点击下一页,发现每点击下一页,pn就多加50
那pn=0,当令它为0,发现就为第一页,于是就是这么个规律
我们定义一个贴吧类
import requests
class TiebaSpider:
def __init__(self,tieba_name):
self.tieba_name = tieba_name
self.url = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"}
def get_url_list(self):
url_list = []
for i in range(1000):
url_list.append(self.url.format(i*50))
return url_list
def parse_url(self,url): #发送请求,获取响应
print(url)
r = requests.get(url,headers=self.headers)
return r.content.decode()
def save_html(self,html_str,page_num): # 保存html字符串
file_path = "{}-第{}页.html".format(self.tieba_name,page_num)
with open(file_path,"w") as f:
f.write(html_str)
def run(self): #实现主要逻辑
# 1.构造url列表
url_list = self.get_url_list()
# 2.遍历,发送请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
# 3.保存
page_num = url_list.index(url) + 1
self.save_html(html_str,page_num)
if __name__ == '__main__':
tieba_spider = TiebaSpider("李毅")
tieba_spider.run()
当我们运行的时候却出错了
看看提示什么错误

似乎是编码问题
其实是写入文件的编码方式不对
改改这里就行了,加一个编码方式写入文件
def save_html(self,html_str,page_num): # 保存html字符串
file_path = "{}-第{}页.html".format(self.tieba_name,page_num)
with open(file_path,"w",encoding="utf-8") as f:
f.write(html_str)
在来运行运行,发现可以用了
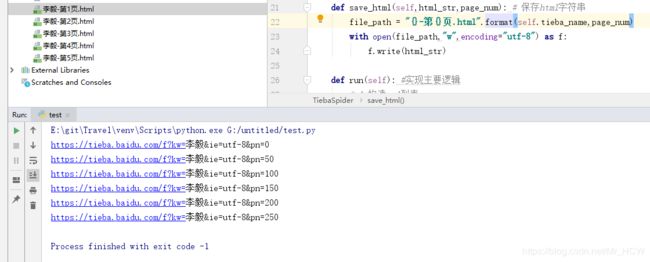
既然是任意贴吧的爬虫,我们来试试爬取别的,看看能不能看到效果
比如爬取lol的页面
只要实例化时传入相应的参数就行
if __name__ == '__main__':
tieba_spider = TiebaSpider("lol")
tieba_spider.run()
来看看结果
发现是可以用的
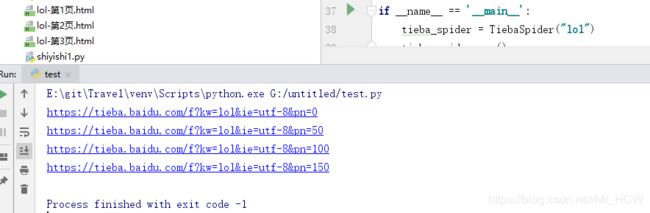
那么程序就写完了
这段程序里面的run方法主要实现逻辑,更好的可以方便观察,提高编程技巧
其实有个地方可以写的更简单
def get_url_list(self):
url_list = []
for i in range(1000):
url_list.append(self.url.format(i*50))
return url_list
可以改成这样的,一句就可以解决
def get_url_list(self):
# url_list = []
# for i in range(1000):
# url_list.append(self.url.format(i*50))
# return url_list
return [self.url.formate(i*50) for i in range(1000)]
发送post请求-实现百度翻译
一些地方我们会使用post请求
- 登入注册(
post比get更安全) - 需要传输大文本内容的时候(post请求对数据长度没有要求)
相对与get请求多了一个data
r = requests.pot(url,data=data,headers=headers)
百度翻译就是一个典型的post请求,因为翻译时候往往是输入很多内容,我们来抓包,来获取百度翻译的posturl和postdata
这很简单,一个一个往下找就是了 ~ _ ~
我们需要找到post的url,和需要post的数据
需要点击翻译按钮,然后进行抓包,点击翻译按钮相当于发送了一次post请求
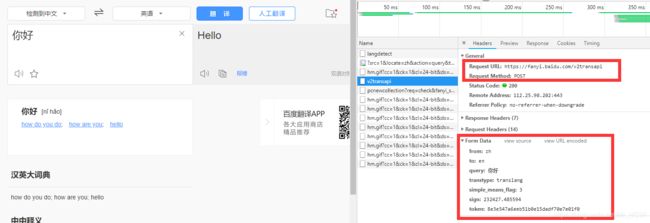
虽然这data里面的内容后面几个还不清楚是什么意思,我们可以写如下程序,来检测一下
import requests
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0"}
data={
"from": "zh",
"to": "en",
"query": "你好",
"transtype": "translang",
"simple_means_flag": "3",
"sign": "232427.485594",
"token": "8e3e547a6eeb51b0e15dadf70e7e01f0"
}
post_url = "https://fanyi.baidu.com/v2transapi"
r = requests.post(post_url,data=data,headers=headers)
print(r)

打印后发现状态码是200,但是200只是意味着我们请求某一个url成功,并不代表请求我们想要的url成功,因为可能网页有跳转
我们再打印内容看看
print(r.content.decode())

发现并没有得到我们想要得数据
到底是什么原因导致我们拿不到我们想要得数据?
有两点问题
-
第一,
headers不全,可能需要加入更多得键值对 -
第二,是
data里面得键值对,是不是都需要,还是要不要某个键值对要变,不是固定值
其实问题是出在第二点,主要是sign它不是固定的,是根据翻译的内容不同而不同
现在的问题就是,怎么根据翻译的内容来获取sign
参考了一些别人的博客,主要就是怎么计算sign的
下面是参考别人程序编出来的代码,还只能从中文翻译成应为,先把代码放这里,Cookie填自己的
import js2py
import requests
import re
import json
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
"Cookie":"xxx"
}
session.headers = headers
response = session.get("http://fanyi.baidu.com/")
# print(response.content.decode())
gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0]
# print(gtk)
context = js2py.EvalJs()
js = r'''
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = 'null !== i ? i : (i = window[l] || "") || ""';
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
'''
# js中添加一行gtk
js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', gtk)
# print(js)
# 执行js
context.execute(js)
# 翻译的内容
# word = '今天吃了吗'
word = input("请输入翻译的内容:")
# 调用函数得到sign
sign = context.e(word)
# print(sign) # 232427.485594
data = {
"from": "zh",
"to": "en",
"query": word,
"transtype": "translang",
"simple_means_flag": "3",
"sign": sign,
"token": "8e3e547a6eeb51b0e15dadf70e7e01f0"
}
r = requests.post("https://fanyi.baidu.com/v2transapi",data=data,headers=headers)
# print(r.content.decode())
# 把json格式编程字典
dic_ret = json.loads(r.content.decode())
ret = dic_ret["trans_result"]["data"][0]["dst"]
print(ret)

将上面的程序改善一下,自动检测语言,可以翻译成指定的语言
import js2py
import requests
import re
import json
class Fanyi:
def __init__(self,word,to_lan=None):
'''
:param word: 翻译的内容
:param to_lan: 翻译后的语言
"zh":中文,"en":英文,"jp":日语,"kor":韩语,"de":德语,"fra":法语,"ru":俄语
'''
self.word = word
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
"Cookie":"xxx"
}
self.post_url = "https://fanyi.baidu.com/v2transapi"
self.sign = None
self.to_lan = to_lan
def get_sign(self, word): # 计算sign值
session = requests.Session()
session.headers=self.headers
response = session.get("http://fanyi.baidu.com/")
gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0]
context = js2py.EvalJs()
js = r'''
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = 'null !== i ? i : (i = window[l] || "") || ""';
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
'''
# js中添加一行gtk
js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', gtk)
# 执行js
context.execute(js)
sign = context.e(word)
return sign
def parse_url(self): # 发送post请求
data = {
"from": None,
"to": self.to_lan,
"query": self.word,
"transtype": "translang",
"simple_means_flag": "3",
"sign": self.sign,
"token": "8e3e547a6eeb51b0e15dadf70e7e01f0"
}
r = requests.post(self.post_url, data=data, headers=self.headers)
# 把json格式编程字典
return json.loads(r.content.decode())
def get_result(self,text): # 分析数据
ret = text["trans_result"]["data"][0]["dst"]
print(ret)
def run(self): # 实现主要逻辑
# 1.通过翻译的内容计算sign值
self.sign = self.get_sign(self.word)
# 2.发送post请求,获取相应后的内容
text = self.parse_url()
# 3.获取翻译后的内容
self.get_result(text)
if __name__ == '__main__':
ret = Fanyi("안녕하세요.")
ret.run()
使用代理
使用代理请求网页,可以更安全,防止服务器获取自己的ip,用大量不同的代理ip频繁访问同一个服务器,不易被发现为爬虫
import requests
proxies = {
"http":"http://xxx.xxx.xxx.xxx:xxx"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
r = requests.get("http://www.baidu.com",proxies=proxies,headers=headers)
# 查看该代理ip是否可用,返回200可用
print(r.status_code)
如果是https类型的ip
应改为
proxies = {
"https":"https://xxx.xxx.xxx.xxx:xxx"
}
实现模拟登入
cookie和session的区别
- cookie数据存放在客户的
浏览器上面,session存放在服务器上 - cookie不是很安全,别人可以分析存放在本地的cookie并进行 cookie欺骗
- session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie
带上cookie、session的好处就是
可以请求到登入之后的页面
坏处就是,一套cookie、session往往对应一个用户,请求太快,次数太多,容易被服务器认为爬虫,但可以准备好多的cookie
有些网站不需要登入也能访问相应的页面,所以不需要cookie的时候尽量不用
方法一:通过session实现
session保持客户端与服务器的会话
这个方法的原理的,当我们发送post请求的时候,对方服务器会在我们本地设置一个cookie
首先是通过post请求将账号密码发送到服务器上(通过抓包可以找到posturl)
然后发送get请求页面,因为本地已经有了cookie,就可以直接访问,得到登入后的页面
那么账号密码以怎样的行式发送呢?
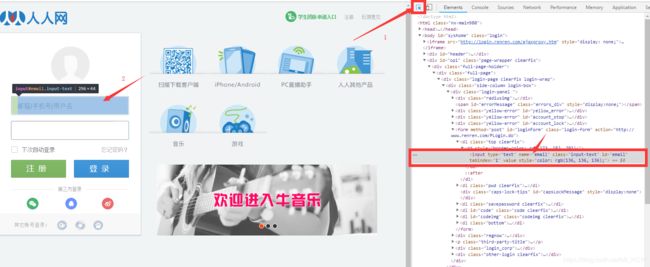
这是一个表单,我们取name里面的值,就是email,有的网站是username
同样的方式,我们看看密码框里面的键是password
再来获取posturl,先输入好自己的账号密码,点击图中上面的那个Preserve log,然后点击登入,进行抓包获取url
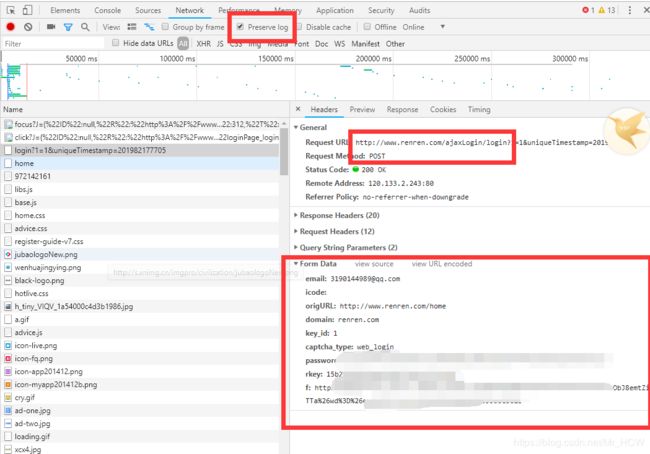
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
# 填自己的登入账号密码, key因网站而异
post_data={
"email":"xxx",
"password":"xxx"
}
# 实例session对象
session = requests.session()
# 发送post请求
session.post("http://www.renren.com/ajaxLogin/login",data=post_data,headers=headers)
# 登入后的url发送get请求
r = session.get("http://www.renren.com/972142161/profile",headers=headers)
print(r.content.decode())
方法二:通过cookie实现
在headers里面带入cookie就行了,比如进入到自己学校的教务系统里面,对照打印出来的html和网页上面的html查看是否请求成功
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
"Cookie":"xxx"
}
r = requests.get("http://jwcas.cczu.edu.cn/login;jsessionid=406EE69527EC0B4B8E5068830F117FEC",headers=headers)
print(r.content.decode("gb2312"))
寻找登入post地址
-
在form表单中寻找action对应的url地址
- post的数据是input标签中name的值作为键,真正的用户名密码作为值得字典
- post得url地址就是action对应得url地址
-
抓包,寻找登陆得url地址
- 勾选perserve log按钮,防止页面跳转找不到url
- 寻找post数据,确实参数
- 参数不会变,直接用
- 参数会变
- 参数在当前得响应中
- 通过js生成
寻找js和分析js
- 定位想要的js
- 选择会触发js事件的按钮,点击event listener,找到js的位置
- 通过chrome中的search all file来搜索url中的关键字
- 添加断点的方式来查看js的操作
requests小技巧
- url编码
requests.utils.unquote("url地址")
import requests
t = requests.utils.unquote("https://tieba.baidu.com/f?ie=utf-8&kw=%E6%9D%8E%E6%AF%85&fr=search")
print(t)

- 请求SSL
r = requests.get(url,verify=False)
- 请求超时
比如超过10s会报错,可以捕获异常,使程序继续运行
r = requests.get(url,timeout=10)
可以将一些容易出错的地方编成一个方法,下次发送请求的时候可以导入自己写的这个函数
import requests
from retrying import retry
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
}
# 这个函数容易报错,所以加一个修饰器,最多可以报错3次
@retry(stop_max_attempt_number=3)
def _parse_url(url,method,data,proxies):
# print("*"*20)
if method=="POST":
response = requests.post(url,data=data,headers=headers,proxies=proxies)
else:
response = requests.get(url,headers=headers,timeout=3,proxies=proxies)
assert response.status_code == 200
return response.content.decode()
def parse_url(url,method='GET',data=None,proxies=None):
try:
html_str = _parse_url(url,method,data,proxies)
except:
html_str = None
return html_str
if __name__ == '__main__':
url = "www.baidu.com"
print(parse_url(url))
json数据处理
json,xml等数据是结构化数据,对这类数据处理可以直接转化成python数据类型
而一些html是非结构数据,需要用到正则匹配,来筛选自己想要的数据
那么哪里能找到返回的json的url呢?
- 使用chrome切换到手机模式
- 抓包手机app的软件
我们先来学习学习json数据如何转化成python数据类型的字典
json数据 -------> json.loads() --------> python的字典